Dieser Artikel wurde im Rahmen der Data Science Blogathon
Die Abschnitte deiner Hauptmelodie sind eine Art Kratzer im Spinnennetz!! Ungeachtet, Wörter „Web-Scratching“ beinhalten im Allgemeinen eine Verbindung, die die Computerisierung beinhaltet. Einige Ziele könnten es umgehen, wenn benutzerdefinierte Debugger Ihre Daten sammeln, während es anderen egal wäre.
Ich hoffe, Sie kratzen absichtlich auf einer Seite nach Informationselementen, vermutlich hast du kein problem. Alles berücksichtigen, Es ist eine gute Idee, eine isolierte Bewertung durchzuführen und sicherzustellen, dass Sie die Nutzungsbedingungen nicht ignorieren, bevor Sie ein gigantisches Abschlussprojekt starten. Um sich mit den legalen Teilen des Web-Scrapings vertraut zu machen, Werfen Sie einen Blick auf Legal Insights zum Daten-Scraping aus dem modernen Web.
Warum Web-Scraping?
Gerade wenn wir das Web kratzen, Wir erstellen einen Code, der eine Anfrage sendet, die mit der von uns ausgewählten Seite funktioniert. Der Spezialist gibt den Quellcode zurück – HTML, hauptsächlich – der Seite (o Seiten) auf die wir verwiesen haben.
Bis vor kurzem, im Grunde machen wir mehr als ein Webprogramm: Senden Sie Interesse mit einer bestimmten URL und erwähnen Sie, dass der Spezialist den Code für diese Seite zurückgibt.
Auf jeden Fall, im Gegensatz zu einem Webprogramm, Unser Web-Scratching-Code übersetzt den Quellcode der Seite nicht und zeigt die Seite angeblich an. Alles berücksichtigen, Wir werden uns einen benutzerdefinierten Code vorstellen, der durch den Quellcode der Seite geleitet wird, um nach Expressteilen zu suchen, die wir demonstriert haben, und alle Substanzen zu entfernen, deren Entfernung wir ihm beigebracht haben.
Zum Beispiel, für den Fall, dass wir erwartet haben, die Gesamtdaten aus einer Tabelle zu erhalten, die auf einer Site-Seite angezeigt wurde, unser Code wäre so aufgebaut, dass er diesen Methoden beim Sammeln folgt:
1 Stoffanwendung (Quellcode) von einer arbeiterspezifischen URL
2 Entladen Sie die zurückgegebene Substanz.
3 Unterscheiden Sie die Segmente der Seite, die für die benötigte Tabelle von grundlegender Bedeutung sind.
4 Konzentrieren Sie sich und (wenn es entscheidend ist) Formatieren Sie diese Segmente in einen Datensatz, den wir auseinandernehmen oder beliebig verwenden können.
Wenn das alles besonders kompliziert klingt, Nicht drängen! Python und Beautiful Soup haben natürliche Eigenschaften vorgeschlagen, um dies größtenteils sofort zu machen.
Eine Sache, die Sie unbedingt beachten sollten: aus fachlicher Sicht, Das Verweisen auf eine Seite durch Web-Scratching ist vergleichbar mit dem Stapeln in einem Webprogramm. Genau dann, wenn wir Code verwenden, um diese Anfragen einzugeben, wir könnten sein „Stapeln“ Seiten deutlich schneller als ein Standard-Client, und verbrauchen auf diese Weise schnell die Arbeitsressourcen des Site-Eigentümers.
Web-Scraping von Daten für maschinelles Lernen:
Falls Sie die Daten für AI kratzen, versprechen Sie, dass Sie niedrige Konzentrationen überprüft haben, bevor Sie sich der Datenextraktion nähern.
Datei Format:
Simulierte Intelligenzmodelle können die Popularität von Daten, die in einer einfachen oder tabellenartigen Assoziation stehen, einfach abrupt erhöhen. In diesem Sinne, das Scrapen unstrukturierter Daten erfordert, Hier entlang, größere Freiheit bei der Pflege von Daten, bevor sie verwendet werden können.
Datenliste:
Da das Hauptziel die künstliche Intelligenz ist, wenn Sie die Standorte oder Seiten der Webseite haben, die Sie löschen möchten, Sie sollten eine Übersicht über die Rechenzentren oder Datenquellen erstellen, die Sie von jeder Seite der Site entfernen möchten. Wenn der Fall das Endziel ist, eine große Anzahl von Rechenzentren für jede Seite der Site zu verpassen, dann muss man abbauen und die üblicherweise vorhandenen Rechenzentren auswählen. Der Grund dafür ist, dass so viele NA- oder leere Funktionen die Darstellung und Genauigkeit des KI-Modells verringern. (ML) wer trainiert und testet mit den Daten.
Datenkennzeichnung:
Faktencheck kann Gehirnqual sein. Auf jeden Fall, wenn Sie die notwendigen Metadaten sammeln können, während die Daten gekratzt werden, und sie als alternativen Datenpunkt speichern, wird den entsprechenden Phasen im Datenlebenszyklus zugute kommen.
Aufräumen, Daten vorbereiten und speichern
Auch wenn dieser Schritt grundlegend erscheinen mag, ist normalerweise vielleicht der verworrenste und traurigste Fortschritt. Dies ist das direkte Ergebnis einer klaren Klärung: es gibt keine Einheitsverbindung. Es hängt davon ab, welche Daten Sie gelöscht haben und wo Sie sie gelöscht haben. Sie benötigen schnelle Strategien, um die Daten zu bereinigen.
Am wichtigsten ist, dass Sie die Daten überprüfen müssen, um zu verstehen, welche Verschlechterungen in den Datenquellen vorliegen. Sie können dies mit einer Bibliothek wie Pandas tun (verfügbar in Python). Zum Zeitpunkt Ihrer Bewertung, Sie müssen eine Substanz erstellen, um Deformitäten in Datenquellen zu beseitigen und Rechenzentren zu normalisieren, die nicht wie die anderen sind. Später, würde große Überprüfungen durchführen, um zu überprüfen, ob die Rechenzentren alle Daten in einem einzigen Datentyp haben. Ein Fragment, das Zahlen enthalten soll, darf keine Datenzeile haben. Zum Beispiel, eine, die Daten in der dd-Konfiguration enthalten sollte / mm / yyyy darf keine Daten in einer anderen Assoziation enthalten. Abgesehen von diesen Planprüfungen, fehlende Funktionen, die ungültigen Merkmale und alles andere, was die Datenverarbeitung beeinträchtigen könnte, muss wahrgenommen und korrigiert werden.
Warum Python für Web Scraping??
Python ist ein bekanntes Gerät zum Ausführen von Web-Scratching. Die Programmiersprache Python wird auch für andere wertvolle Aktivitäten verwendet, die mit der Netzwerksicherheit identifiziert werden, Eingangstests sowie fortgeschrittene messbare Anwendungen. Verwenden der grundlegenden Python-Programmierung, Web-Scraping kann ohne Verwendung eines anderen externen Geräts durchgeführt werden.
Die Programmiersprache Python gewinnt immens an Bedeutung und die Gründe, die Python zu einem soliden Partner für Web-Scratching-Projekte machen, sind die folgenden::
Scoring Einfachheit
Python hat im Vergleich zu anderen Programmierdialekten den einfachsten Aufbau. Dieses Python-Element vereinfacht das Testen und ein Ingenieur kann sich auf zusätzliche Programmierung konzentrieren.
Eingebaute Module
Eine weitere Rechtfertigung für die Verwendung von Python zum Scratchen im Web ist die Einbindung der wertvollen externen Bibliotheken, die es hat. Wir können zahlreiche Ausführungen ausführen, die mit Web Scratching identifiziert wurden, mit Python als Grundlage für die Programmierung.
Open-Source-Programmiersprache
Python hat große Hilfe aus der Umgebung, da es eine Open-Source-Programmiersprache ist.
Breites Anwendungsspektrum
Python kann für verschiedene Programmieraufgaben verwendet werden, von kleinen Shell-Inhalten bis hin zu großen Unternehmens-Webanwendungen.
Python-Module für Web-Scraping
Web Scraping ist der Weg, um einen Spezialisten zu entwickeln, der extrahieren kann, analysieren, entsprechend wertvolle Daten aus dem Web herunterladen und koordinieren. Am Ende des Tages, anstatt die Informationen der Sites physisch zu speichern, Die Web-Scratching-Programmierung lädt und konzentriert Informationen von verschiedenen Seiten gemäß unserer Voraussetzung.
Anwendung
Es ist eine einfache Python-Web-Scratch-Bibliothek. Es ist eine leistungsstarke HTTP-Bibliothek für den Zugriff auf Seiten. Mit Hilfe von Anfragen, Wir können den rohen HTML-Code von den Site-Seiten abrufen, der dann geparst werden könnte, um die Informationen abzurufen.
Schöne Suppe
Beautiful Soup ist eine Python-Bibliothek zum Extrahieren von Informationen aus HTML- und XML-Datensätzen. Neigt dazu, mit Anforderungen verwendet zu werden, da brauchst du eine information (Melde die URL) ein Suppenobjekt machen, da Sie ohne die Hilfe anderer keine Seite von der Site abrufen können. Sie können angehängte Python-Inhalte verwenden, um den Seitentitel und die Hyperlinks zusammenzustellen.
Code –
urllib.request importieren von urllib.request urlopen importieren, Anfrage aus bs4 importieren BeautifulSoup wiki= "https://www.thestar.com.my/search/?q=HIV&qsort=älteste&qrec=10&qstockcode =&pgno = 1" html=urlopen(Wiki) bs= SchöneSuppe(html,'lxml') bs Beautiful Soup wird verwendet, um die Website-Seite zu extrahieren
(Bildquelle: Jupyter-Notizbuch)
Code-
aus bs4 importieren BeautifulSoup
base_url="https://www.thestar.com.my/search/?q=HIV&qsort=älteste&qrec=10&qstockcode =&pgno ="
# Hinzufügen 1 weil Python-Bereich.
URL_Liste = ["{}{}".Format(base_url, str(Seite)) für Seite in Reichweite(1, 408)]
s=[]
für URL in url_list:
drucken (URL)
s.anhängen(URL)
Produktion-
Der obige Code listet die Anzahl der Webseiten im Bereich von 1 ein 407.
(Bildquelle: Jupyter-Notizbuch)
Code –
Daten = []
Daten1= []
CSV-Datei importieren
von urllib.request urlopen importieren, HTTP Fehler
aus datetime importieren datetime, Zeitdelta
für pg in s:
# Abfrage der Website und Rückgabe des HTML-Codes an die Variable 'page'
page = urllib.request.urlopen(pg)
Versuchen:
search_response = urllib.request.urlopen(pg)
außer urllib.request.HTTPError:
passieren
# Parsen Sie den HTML-Code mit schöner Seife und speichern Sie ihn in der Variablen `suppe`
Suppe = SchöneSoup(Seite, 'html.parser')
# Nehmen Sie die <div> des Namens und erhalte seinen Wert
ls = [x.get_text(Streifen=Wahr) für x in der Suppe.find_all("h2", {"Klasse": "f18"})]
ls1 = [x.get_text(Streifen=Wahr) für x in der Suppe.find_all("Spanne", {"Klasse": "Datum"})]
# Speichern Sie die Daten in Tupel
Daten.anhängen((ls))
data1.append(ls1)
Produktion-
Der obige Code nimmt alle Daten mit Hilfe einer schönen Suppe und speichert sie im Tupel.
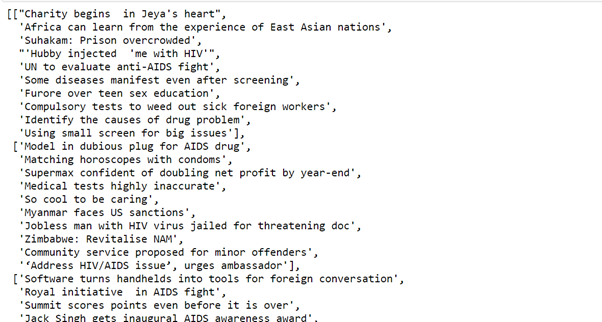
(Bildquelle: Jupyter-Notizbuch)
Code
Pandas als p . importieren df=p.DataFrame(F,Spalten=['Thema des Artikels']) df['Datum']= f1
Produktion-
Pandas
Pandas ist ein schnelles Open-Source-Informationsrecherche- und Kontrollinstrument, tolle, anpassungsfähig und einfach zu bedienen, basierend auf der Programmiersprache Python.
Der obige Code speichert den Wert im Datenrahmen.

(Bildquelle: Jupyter-Notizbuch)
Hoffe dir gefällt der Code.
Kleine Einführung
Mir, Sonia Singla, Ich habe einen Master in Bioinformatik von der University of Leicester gemacht, Vereinigtes Königreich. Ich habe auch einige Projekte zum Thema Data Science von CSIR-CDR durchgeführt. Derzeit ist er beratendes Mitglied der Redaktion von IJPBS.
Linkedin – https://www.linkedin.com/in/soniasinglabio/
Die in diesem Artikel gezeigten Medien zur Implementierung von Modellen für maschinelles Lernen, die CherryPy und Docker nutzen, sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet..





