Einführung:
Unstrukturierte Daten in einem strukturierten Format? Hier kommt Web Scraping ins Spiel.
Was ist Web-Scraping??
Im Klartext, Web-Scraping, Web-Ernte, Ö Web-Datenextraktion ist ein automatisierter Big-Data-Erfassungsprozess (unstrukturiert) von Websites. Der Benutzer kann alle Daten auf bestimmten Websites oder spezifische Daten je nach Anforderung extrahieren. Die gesammelten Daten können in einem strukturierten Format zur weiteren Analyse gespeichert werden.
Verwendung von Web Scraping:
In der realen Welt, Web Scraping hat viel Aufmerksamkeit erregt und hat ein breites Anwendungsspektrum.. Einige davon sind unten aufgeführt:
- Social Media Sentiment Analyse
- Leadgenerierung im Marketingbereich
- Marktanalyse, Online-Preisvergleich auf der E-Commerce-Domain
- Sammeln von Trainings- und Testdaten in Machine Learning-Anwendungen
Schritte beim Web-Scraping:
- Suchen Sie die URL der Webseite, die Sie scratchen möchten
- Auswählen bestimmter Elemente durch Überprüfen
- Schreiben des Codes, um den Inhalt der ausgewählten Elemente abzurufen
- Speichern von Daten im erforderlichen Format
Einfach so! .. !!
Bibliotheken / Beliebte Tools für das Web-Scraping sind:
- Selen: Ein Framework zum Testen von Webanwendungen
- SchöneSuppe: Python-Bibliothek zum Abrufen von HTML-Daten, XML und andere Auszeichnungssprachen
- Pandas: Python-Bibliothek zur Datenmanipulation und -analyse
In diesem Artikel, Wir erstellen unseren eigenen Datensatz, indem wir Domino's Pizza-Bewertungen von der Website abrufen. consumeraffairs.com/food.
Wir werden verwenden Anfragen Ja Schöne Suppe von Scraping und Analyse die Daten.
Paso 1: Suchen Sie die URL der Webseite, die Sie scratchen möchten
Öffnen Sie die URL “consumeraffairs.com/food"Suchen Sie in der Suchleiste nach Domino's Pizza und drücken Sie die Eingabetaste.
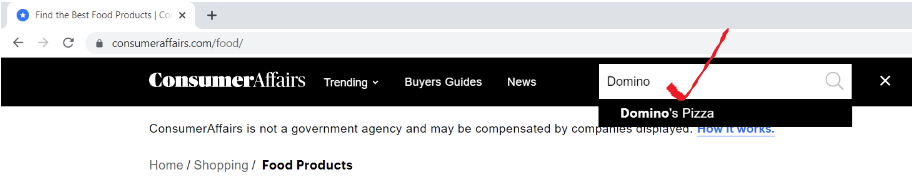
So sieht unsere Bewertungsseite aus.
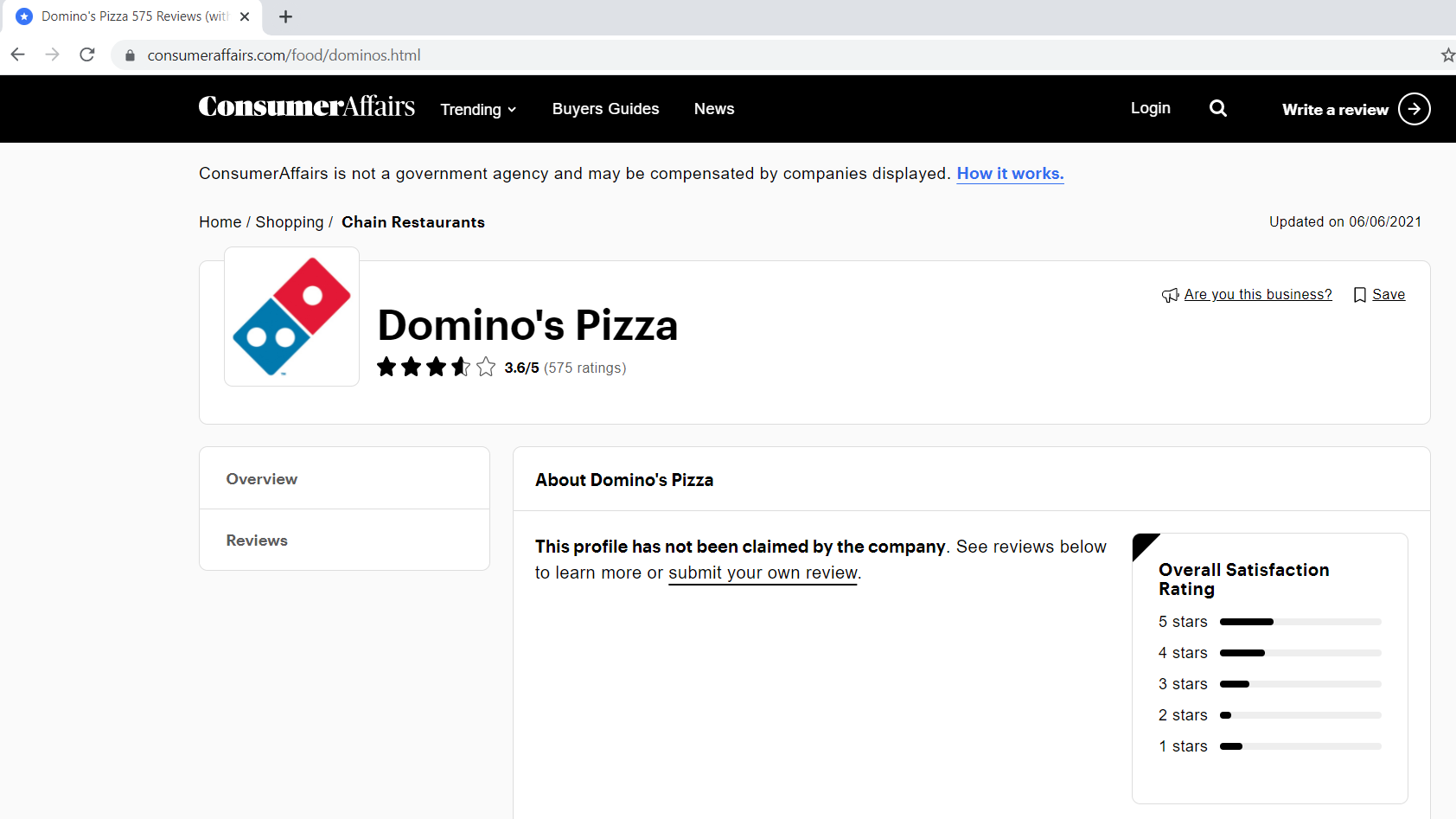
Paso 1.1: Definieren der Basis-URL, Abfrageparameter
Die Basis-URL ist der konsistente Teil Ihrer Webadresse und stellt den Pfad zur Suchfunktion der Website dar.
base_url = "https://www.consumeraffairs.com/food/dominos.html?Seite="
Abfrageparameter stellen zusätzliche Werte dar, die auf der Seite deklariert werden können.
query_parameter = "?Seite="+str(ich) # i steht für die Seitenzahl
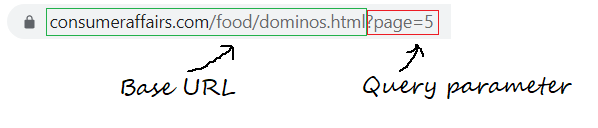
Paso 2: Auswählen bestimmter Elemente durch Überprüfen
Unten ist ein Bild einer Beispielüberprüfung. Jede Bewertung hat viele Elemente: die vom Nutzer abgegebene Bewertung, der Nutzername, das Datum der Bewertung und den Text der Bewertung zusammen mit einigen Informationen darüber, wie viele Personen Sie mochten.

Unser Interesse ist es, nur den Text der Rezension zu extrahieren. Dafür, Wir müssen die Seite überprüfen und die HTML-Tags abrufen, Die Attributnamen des Zielelements.
So überprüfen Sie eine Webseite, Klicken Sie mit der rechten Maustaste auf die Seite, Wählen Sie Überprüfen oder verwenden Sie die Tastenkombination Strg + Verschiebung + ich.
In unserem Fall, Revisionstext wird im HTML-Tag gespeichert
des div mit dem Klassennamen "RVW-BD“
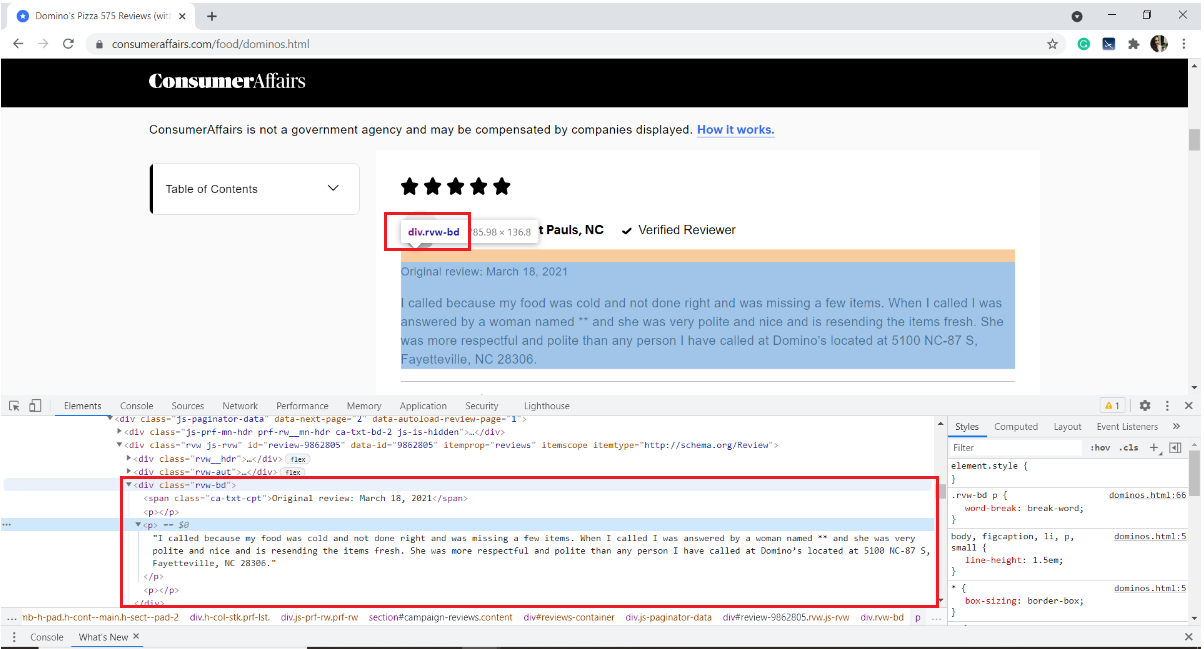
Mit diesem, Wir machen uns mit der Website vertraut. Springen wir schnell zum Scraping.
Paso 3: Schreiben des Codes, um den Inhalt der ausgewählten Elemente abzurufen
Beginnen Sie mit der Installation der Module / Erforderliche Pakete
pip installieren pandas anfragen BeautifulSoup4
Importieren Sie erforderliche Bibliotheken
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
Pandas – So erstellen Sie einen Datenrahmen
Anfragen: So senden Sie HTTP-Anforderungen und greifen von der Zielwebseite auf HTML-Inhalte zu
SchöneSuppe: ist eine Python-Bibliothek zur Analyse strukturierter HTML-Daten
Erstellen Sie eine leere Liste, um alle extrahierten Bewertungen zu speichern
all_pages_reviews = []
Definieren eines Scraper-Features
Def Scraper():
Innerhalb der Schaberfunktion, Typ a so dass die Schleife die Anzahl der Seiten durchläuft, die Sie scrapen möchten. Ich möchte die fünfseitigen Rezensionen kratzen.
für mich in Reichweite(1,6):
Creando una lista vacía para almacenar las reseñas de cada página (von 1 ein 5)
pagewise_reviews = []
Construye la URL
url = base_url + query_parameter
Envíe la solicitud HTTP a la URL mediante solicitudes y almacene la respuesta
Antwort = Anfragen.get(URL)
Cree un objeto de sopa y analice la página HTML
soup = bs(antwort.inhalt, 'html.parser')
Encuentre todos los elementos div del nombre de clase “rvw-bd” y guárdelos en una variable
rev_div = soup.findAll("div",attrs={"Klasse","rvw-bd"})
Recorra todo el rev_div y agregue el texto de revisión a la lista pagewise
für j im Bereich(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].finden("P").Text)
Anexar todas las reseñas de páginas a una sola lista “all_pages about”
für k im Bereich(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k])
Al final de la función, devuelve la lista final de reseñas.
return all_pages_reviews
Call the function scraper() and store the output to a variable 'reviews'
# Driver code
reviews = scraper()
Paso 4: almacene los datos en el formato requerido
4.1 almacenamiento en un marco de datos de pandas
i = range(1, len(Bewertungen)+1) reviews_df = pd.DataFrame({'Rezension':Bewertungen}, index=i)
Now let us take a glance of our dataset
drucken(reviews_df)

4.2 Escribir el contenido del marco de datos en un archivo de texto
reviews_df.to_csv('rezensionen.txt', sep = 't')
Mit diesem, terminamos de extraer las reseñas y almacenarlas en un archivo de texto. Mmm, es bastante simple, Nein?
Código Python completo:
# !pip install pandas requests BeautifulSoup4
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
base_url = "https://www.consumeraffairs.com/food/dominos.html"
all_pages_reviews =[]
-
Def Scraper(): für mich in Reichweite(1,6): # fetching reviews from five pages pagewise_reviews = [] query_parameter = "?Seite="+str(ich) url = base_url + query_parameter response = requests.get(URL) soup = bs(antwort.inhalt, 'html.parser') rev_div = soup.findAll("div",attrs={"Klasse","rvw-bd"}) für j im Bereich(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].finden("P").Text) für k im Bereich(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k]) return all_pages_reviews # Driver code reviews = scraper() i = range(1, len(Bewertungen)+1) reviews_df = pd.DataFrame({'Rezension':Bewertungen}, index=i) reviews_df.to_csv('rezensionen.txt', sep = 't')
Abschließende Anmerkungen:
Am Ende dieses Artikels, Wir haben den schrittweisen Prozess des Extrahierens von Inhalten von jeder Webseite und deren Speicherung in einer Textdatei gelernt.
- Überprüfen des Zielelements mit den Entwicklungstools des Browsers
- Verwenden von Anforderungen zum Herunterladen von HTML-Inhalten
- HTML-Inhalte mit BeautifulSoup analysieren, um die erforderlichen Daten zu extrahieren
Wir können dieses Beispiel weiterentwickeln, indem wir Benutzernamen scrapen, Überprüfen von Text. Führen Sie eine Vektorisierung von sauberem Review-Text durch und gruppieren Sie Benutzer nach schriftlichen Bewertungen. Wir können Word2Vec oder CounterVectorizer verwenden, um Text in Vektoren zu konvertieren und jeden der Clustering-Algorithmen des maschinellen Lernens anzuwenden.
Verweise:
Biblioteca BeautifulSoup: Dokumentation, Video-Tutorial
GitHub-Repository-Link zum Herunterladen des Quellcodes
Ich hoffe, dieser Blog hilft Ihnen, Web-Scraping in Python mit der BeautifulSoup-Bibliothek zu verstehen. Viel Spaß beim Lernen !! 😊
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





