Einführung
Ich bin dieser strategischen Tugend von Sun Tzu kürzlich begegnet:

Was hat das mit einem Data-Science-Blog zu tun?? Dies ist die Essenz dessen, wie Wettbewerbe gewonnen werden und Hackaton. Sie kommen besser vorbereitet zum Wettbewerb als Mitbewerber, Sie laufen schnell, Sie lernen und iterieren, um das Beste aus Ihnen herauszuholen.
Letzte Woche, Wir veröffentlichen "Perfect way to build a predictive model in less than 10 Minuten mit R". Jeder kann ein schnelles Follow-up dieses Beitrags erraten. Angesichts des Aufstiegs von Python in den letzten Jahren und seiner Einfachheit, Es ist sinnvoll, dieses Toolkit für Pythonisten in der Welt der Datenwissenschaft bereit zu haben. Ich werde einer Struktur ähnlich der des vorherigen Beitrags mit meinen zusätzlichen Beiträgen in verschiedenen Phasen der Konstruktion des Modells folgen. Diese beiden Beiträge helfen Ihnen, Ihr erstes Vorhersagemodell schneller und mit besserer Leistung zu erstellen. Die meisten Top-Datenwissenschaftler und Kaggler erstellen ihr erstes effektives Modell schnell und liefern es aus. Dies hilft ihnen nicht nur, einen Vorteil auf der Bestenliste zu haben., bietet ihnen aber auch eine Referenzlösung, die es zu überwinden gilt.

Aufschlüsselung des prädiktiven Modellierungsverfahrens
Ich konzentriere mich immer darauf, Qualitätszeit in der Anfangsphase des Modellbaus zu investieren, als Generierung von Hypothesen / Brainstorming-Sitzungen / Diskussion (S) oder die Domäne verstehen. All diese Aktivitäten helfen mir, mich auf das Problem zu beziehen., was mich schließlich dazu bringt, leistungsfähigere Geschäftslösungen zu entwerfen. Es gibt gute Gründe, warum Sie diese Zeit am Anfang verbringen sollten:
- Sie haben genug Zeit zu investieren und sind frisch (hat Wirkung)
- Nicht voreingenommen mit anderen Datenpunkten oder Gedanken (Ich schlage immer vor, dass Sie Hypothesen generieren, bevor Sie sich mit den Daten befassen)
- Zu einem späteren Zeitpunkt, Sie würden es eilig haben, das Projekt abzuschließen, und wären nicht in der Lage, Qualitätszeit aufzuwenden.
Diese Phase wird Qualitätszeit benötigen, also erwähne ich die Zeitleiste hier nicht, Ich würde empfehlen, dass Sie es als Standardpraxis tun. Es wird Ihnen helfen, bessere Vorhersagemodelle zu erstellen und in späteren Phasen zu weniger Iterationen der Arbeit zu führen.. Schauen wir uns die verbleibenden Phasen in der ersten Zusammenstellung des Modells mit Zeitleisten an:
- Deskriptive Analyse der Daten: 50% Wetter
- Datenverarbeitung (fehlender Wert und Ausreißerkorrektur): 40% Wetter
- Datenmodellierung: 4% Wetter
- Leistungseinschätzung: 6% Wetter
PD: Dies ist die Aufteilung der Zeit, die nur für die erste Konstruktion des Modells aufgewendet wird
Lassen Sie uns das Verfahren Schritt für Schritt überprüfen (mit Schätzungen der Zeit, die für jeden Schritt aufgewendet wurde):
Bühne 1: Beschreibende Analyse / Datenexploration:
In meinen Anfängen als Data Scientist, Früher hat mich die Datenexploration lange gekostet. Im Laufe der Zeit, Ich habe viele Operationen mit den Daten automatisiert. Da die Datenaufbereitung die 50% der Arbeiten am Bau eines ersten Modells, Die Vorteile der Automatisierung liegen auf der Hand. Sie können die “7 Schritte zur Datenexploration” So zeigen Sie die gängigsten Datenexplorationsvorgänge an.
Tavish hat bereits in seinem Beitrag erwähnt, dass mit fortschrittlichen maschinellen Lernwerkzeugen im Rennen, Der Zeitaufwand für die Ausführung dieser Aufgabe wurde erheblich verkürzt. Da dies unser erstes Referenzmodell ist, Wir eliminieren jede Art von Feature-Engineering. Deswegen, die Zeit, die Sie möglicherweise für eine deskriptive Analyse benötigen, beschränkt sich auf das Wissen um fehlende Werte und große Merkmale, die direkt sichtbar sind. In meiner Methodik, muss 2 Protokoll um diesen Schritt abzuschließen (Annahme, 100.000 Beobachtungen im Datensatz).
Zu den Operationen, die ich für mein erstes Modell ausführe, gehören:
- Identifizieren von identifizierenden Merkmalen, Einreise und Ziel
- Identifizierung kategorialer und numerischer Merkmale
- Identifizieren von Spalten mit verlorenen Werten
Bühne 2: Datenverarbeitung (Umgang mit verlorenen Werten):
Es gibt mehrere Alternativen, um sich dem zu stellen. Für unser erstes Modell, Wir konzentrieren uns auf intelligente und schnelle Techniken, um Ihr erstes effektives Modell zu erstellen (diese wurden bereits von Tavish in seinem Beitrag diskutiert, Ich füge einige Methoden hinzu)
- Erstellen von Dummy-Indikatoren für fehlende Werte: Es klappt, Manchmal enthalten die fehlenden Werte selbst eine gute Menge an Informationen.
- Unterstellen Sie den fehlenden Wert mit dem Durchschnitt / Median / jede andere einfachere Methode: Die Imputation des Mittelwerts und des Medians funktioniert gut, Die meisten Menschen ziehen es vor, mit dem Durchschnittswert zu unterstellen, aber im Falle einer verzerrten Verteilung, Ich schlage vor, dass Sie den Median wählen. Andere intelligente Methoden sind die Imputation von Werten durch ähnliche Fälle und die mediane Imputation unter Verwendung anderer relevanter Merkmale oder der Aufbau eines Modells.. Als Beispiel: in der Titanic Survival Challenge, Sie können fehlende Alterswerte mit der Begrüßung des Passagiernamens als “Herr.”, “Fräulein”, “Frau.”, “Maestro” und andere, Dies hat sich positiv auf die Modellleistung ausgewirkt.. .
- Unterstellen des fehlenden Werts der kategorialen Variablen: Erstellen Sie eine neue Ebene, um die kategoriale Variable zu imputieren, sodass alle fehlenden Werte als einzelner Wert codiert werden, Sag es “New_Cat” Oder Sie können sich den Frequenzmix ansehen und den fehlenden Wert dem Wert mit einer höheren Frequenz unterstellen.
Mit so einfachen Datenverarbeitungsmethoden, kann die Datenverarbeitungszeit für 3-4 Protokoll.
Bühne 3. Datenmodellierung:
Ich empfehle, eine der GBM-Techniken zu verwenden / Zufälliger Wald, je nach Geschäftsproblem. Diese beiden Techniken sind äußerst effektiv bei der Erstellung einer Referenzlösung. Ich habe gesehen, dass Datenwissenschaftler diese beiden Methoden oft als ihr erstes Modell verwenden und, in manchen Fällen, fungiert auch als endgültiges Modell. Dies wird die maximale Zeit in Anspruch nehmen (~ 4-5 Protokoll).
Bühne 4. Leistungseinschätzung:
Es gibt mehrere Methoden, um die Leistung Ihres Modells zu überprüfen, Ich schlage vor, dass Sie den Datensatz Ihres Zuges in Zug aufteilen und validieren (im Idealfall 70:30) und erstellen Sie ein Modell basierend auf dem 70% des Zugdatensatzes. Jetzt, Kreuzvalidierung mit dem Befehl 30% des validierten Datensatzes und Bewertung der Leistung mithilfe der Bewertungsmetrik. Dies nimmt zum Schluss 1-2 Protokoll ausführen und dokumentieren.
Die Absicht dieses Beitrags ist es nicht, den Wettbewerb zu gewinnen, sondern um einen Anhaltspunkt für uns selbst zu bestimmen. Schauen wir uns Python-Codes an, um die oben genannten Schritte auszuführen und Ihr erstes Modell mit größerer Wirkung zu erstellen.
Fangen wir an, das in die Tat umzusetzen
Ich ging davon aus, dass er zuerst die gesamte Hypothesengenerierung durchgeführt hat und mit grundlegender Datenwissenschaft mit Python gut ist.. Ich illustriere dies mit einem Beispiel für eine Data Science-Herausforderung.. Schauen wir uns die Struktur an:
Paso 1 : Importieren Sie die unverzichtbaren Bibliotheken und lesen Sie das Test- und Trainingsdataset. Beides anhängen.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
import random
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
Zug=pd.read_csv('C:/Benutzer/DataPeaker/Desktop/Herausforderung/Train.csv')
test=pd.read_csv('C:/Benutzer/DataPeaker/Desktop/Herausforderung/Test.csv')
Bahn['Typ']='Train' #Create a flag for Train and Test Data set
test['Typ']='Test'
fullData = pd.concat([Bahn,Prüfung],Achse=0) #Kombinierter Zug- und Testdatensatz
Paso 2: Schritt 2 del marco no es necesario en Python. Pasamos al siguiente paso.
Paso 3: Spaltennamen anzeigen / Datensatzzusammenfassung
fullData.columns # This will show all the column names fullData.head(10) # Zuerst anzeigen 10 records of dataframe fullData.describe() #Sie können die Zusammenfassung der numerischen Felder anzeigen, indem Sie describe() Funktion
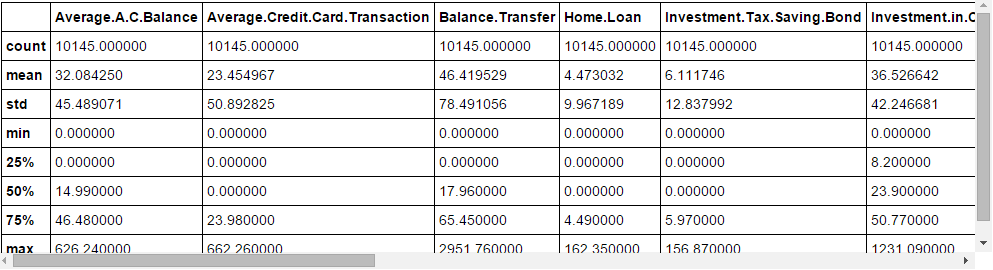
Paso 4: Identificar las a) Variables de identificación b) Variablen objetivo c) Variablen categóricas d) Variablen numéricas e) Otras-Variablen
ID_col = ["REF_NO"] target_col = ["Konto.Status"] cat_cols = ['Kinder',"age_band","Status","Beruf","occupation_partner","home_status","family_income","self_employed", "self_employed_partner","year_last_moved",'TVarea',"post_code","post_area",'Geschlecht','Region'] num_cols= Liste(einstellen(aufführen(fullData.columns))-einstellen(cat_cols)-einstellen(ID_col)-einstellen(target_col)-einstellen(data_col)) other_col=['Typ'] #Test- und Traindatensatz-ID
Paso 5 : Identifique las variables con valores perdidos y cree una bandera para esas
fullData.isnull().irgendein()#Gibt die Funktion mit True oder False zurück,True bedeutet, dass ein fehlender Wert vorhanden ist, andernfalls Falsenum_cat_cols = num_cols+cat_cols # Combined numerical and Categorical variables #Create a new variable for each variable having missing value with VariableName_NA # und kennzeichnen fehlenden Wert mit 1 und andere mit 0 für var in num_cat_cols: wenn fullData[wo].ist Null().irgendein()== Wahr: fullData[var+'_NA']=vollständige Daten[wo].ist Null()*1
Paso 6 : Fehlende Werte imputieren
#Impute numerical missing values with mean
fullData[num_cols] = fullData[num_cols].Fillna(fullData[num_cols].bedeuten(),inplace=Wahr)
#Kategorisch fehlende Werte mit -9999 fullData[cat_cols] = fullData[cat_cols].Fillna(Wert = -9999)
Paso 7 : Cree codificadores de etiquetas para variables categóricas y divida el conjunto de datos para entrenar y probar, Divida aún más el conjunto de datos del tren para entrenar y validar
#create label encoders for categorical features for var in cat_cols: number = LabelEncoder() fullData[wo] = number.fit_transform(fullData[wo].astyp('str')) #Target variable is also a categorical so convert it fullData["Konto.Status"] = number.fit_transform(fullData["Konto.Status"].astyp('str')) train=fullData[fullData['Typ']== "Zug"] test=vollständige Daten[fullData['Typ']== "Test"] Bahn["is_train"] = np.random.uniform(0, 1, len(Bahn)) <= .75 Bahn, Validieren = Zug[Bahn["is_train"]== Wahr], Bahn[Bahn["is_train"]== Falsch]
Paso 8 : Übergeben Sie die imputierten und fiktiven Variablen (Indikatoren für verlorene Werte) zum Modellierungsverfahren. Ich verwende eine Random Forest, um die Klasse vorherzusagen.
features=Liste(einstellen(aufführen(fullData.columns))-einstellen(ID_col)-einstellen(target_col)-einstellen(other_col))
x_train = Zug[aufführen(Merkmale)].values y_train = Train["Konto.Status"].values x_validate = Validate[aufführen(Merkmale)].values y_validate = Validate["Konto.Status"].values x_test=test[aufführen(Merkmale)].Werte
random.seed(100) rf = RandomForestClassifier(n_Schätzer = 1000) rf.fit(x_train, y_train)
Paso 9 : Überprüfen Sie die Leistung und treffen Sie Vorhersagen
Status = rf.predict_proba(x_validate)
fpr, tpr, _ = roc_curve(y_validate, Status[:,1])
roc_auc = auc(fpr, tpr)
print roc_auc
final_status = rf.predict_proba(x_test)
Prüfung["Konto.Status"]=final_status[:,1]
test.to_csv('C:/Benutzer/DataPeaker/Desktop/model_output.csv',Spalten=["REF_NO",'Account.Status'])
Und einreichen!
Abschließende Anmerkungen
Hoffentlich, In diesem Beitrag können Sie mit der Erstellung Ihres eigenen Scoring-Codes beginnen 10 Protokoll. Die meisten Lehrer von Kaggle und die besten Wissenschaftler in unserem Land Hackaton Halten Sie diese Codes bereit und feuern Sie Ihre erste Sendung ab, bevor Sie eine detaillierte Analyse durchführen. Sobald sie eine Schätzung des Referenzpunkts haben, sie fangen an mehr zu improvisieren. Teile deine vollständigen Codes im Kommentarfeld unten.
Hat dir dieser Beitrag geholfen? Teile deine Meinung / Gedanken im Kommentarbereich unten.





