Einführung
R ist eine der bekanntesten Programmiersprachen für statistische Analyse und Berechnung. Weil es viele Funktionen bietet, Forscher und Data Scientists nutzen es für Data Science und Machine Learning. Einige dieser Funktionen umfassen interaktive Anzeigebibliotheken, schnell und Open Source, Ausführen von Code ohne Compiler, gute Gemeinschaft und vieles mehr.
Einer der Hauptgründe, warum es sehr berühmt wird, ist die große Anzahl von R-Paketen für Data-Science-Projekte., maschinelles Lernen und künstliche Intelligenz. Bei Verwendung dieser Pakete, Vorhersagemodelle können einfach und effizient entwickelt werden. Dieser Blog listet die 10 Top-R-Pakete, die Sie kennen sollten 2021 für Data Science und Machine Learning.

Inhaltsverzeichnis
- dplyr
- ggplot2
- KernLab
- Datenexplorer
- Kollatierungszeichen
- zufälligWald
- Hell
- mboost
- Handlung
- SuperML
dplyr
Es ist eines der am weitesten verbreiteten R-Pakete für Data Science- und Machine Learning-Aufgaben. Dieses Paket wurde geschrieben von Hadley Wickham. Wird verwendet, um Datenmanipulationsaufgaben zu lösen. Hat eine Reihe von Funktionen für die Datenmanipulation. Auch Datenmanipulationsgrammatik genannt. Es hat eine Reihe von Verben, die uns helfen, die schwierigsten Datenmanipulationsaufgaben wie Mutation zu lösen. (), zur Auswahl (), Filter (), zusammenfassen (), organisieren ().
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete("dplyr")


Für mehr Informationen, siehe den Link unten: Einführung in dplyr
ggplot2
Eines der beliebtesten und am weitesten verbreiteten R-Pakete für die Datenvisualisierung und explorative Datenanalyse. Mit diesem Paket können Sie interaktive Datenvisualisierungen erstellen. Es bietet eine große Auswahl an schönen Grundstücken, die sich um winzige Details kümmern und Legenden zeichnen. Dieses Paket funktioniert unter einer tiefen Grammatik namens “Grammatikdiagramme”. Bietet eine breite Palette von Diagrammen, z. B. Punktdiagramme und Blasendiagramme. Fluktuationsdiagramme sind Diagramme, Histogramme, Dichtediagramme, Boxplots, Geigendiagramme, Dendrogramme und viele mehr.
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete('gglpot2')
Im Folgenden finden Sie einige Beispiele für Pakete, die dieses Paket verwenden:
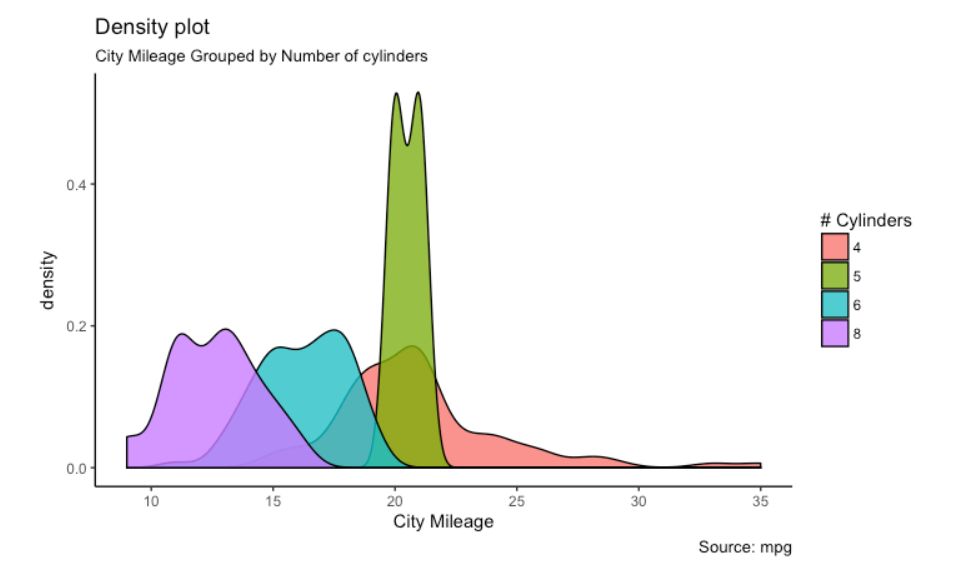

Für mehr Informationen, siehe den Link unten: ggplot2
KernLab
Dieses Paket wird auch als kernelbasiertes Machine Learning Lab bezeichnet.. Dieses Paket wird für die Regression verwendet, Einstufung, Dimensionsreduktion, Anomalieerkennung, Gruppierung. Wenn Sie Algorithmen verwenden möchten, die einen kernelbasierten Ansatz beinhalten, kann es als SVM verwenden, Klassifizierungsalgorithmus, Kernel-Feature-Analyse und vieles mehr. Es wird häufig für SVM-Implementierungen verwendet. Hat eine breite Palette von Kernel-Funktionen, wie für die polynomiale Kernfunktion, Wir können Polydot verwenden (), Die hyperbolische Tangentenkernfunktion für Tanhdot (), etc.
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete('kernlab')
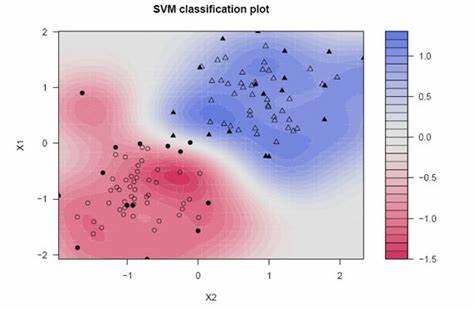
Für mehr Informationen, siehe den Link unten: Kernlab-Paket
Datenexplorer
Dieses R-Paket ist eines der am einfachsten zu verwendenden für Data Science und maschinelles Lernen. Dieses Paket konzentriert sich hauptsächlich auf drei Ziele.:
- Explorative Datenanalyse
- Funktionsengineering
- Datenreport
Dieses Paket automatisiert die explorative Datenanalyse für prädiktive Modellierungs- und Analyseaufgaben, indem jedes in unserem Datensatz vorhandene Feature visualisiert wird..
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete('DataExplorer')
Um einen umfassenden Überblick über unseren Datensatz zu erhalten, Wir können den folgenden Code verwenden:
Führt(Daten)
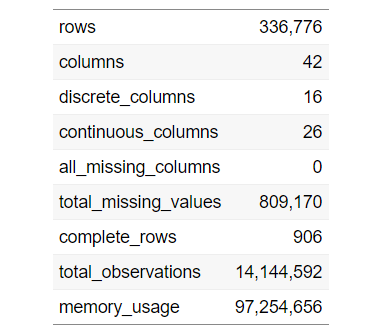
So zeigen Sie die obige Tabelle an, Verwenden Sie den folgenden Code:
plot_intro(Daten)
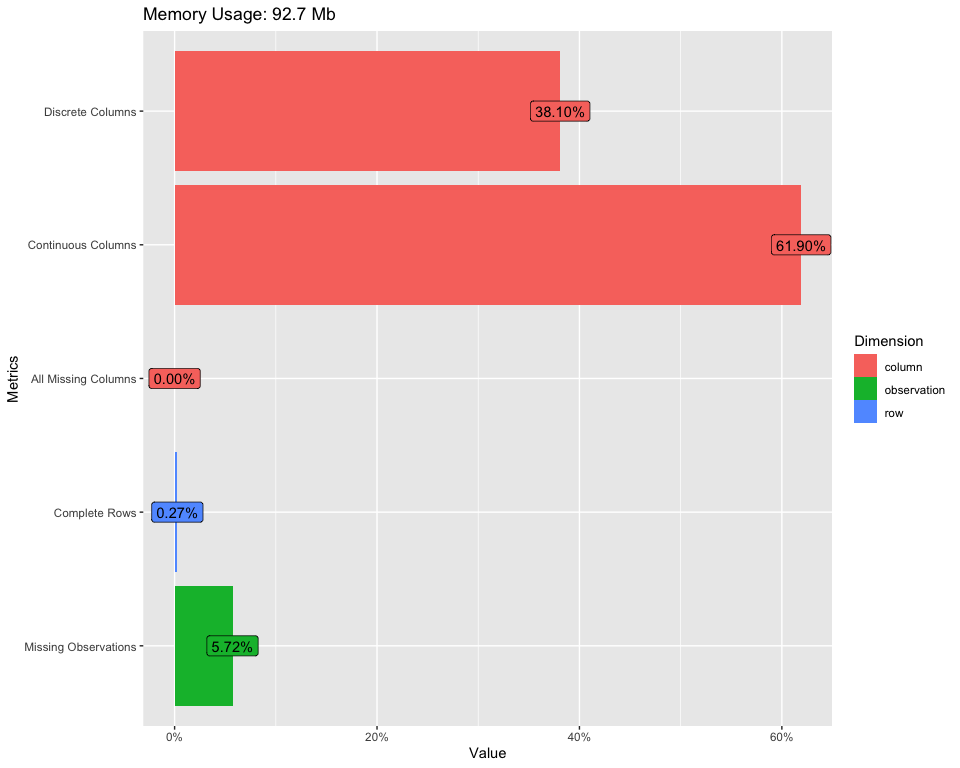
Für mehr Informationen, siehe den Link unten: Einführung in DataExplorer
Kollatierungszeichen
Dies wird auch als Klassifizierungs- und Regressionstraining bezeichnet.. Es ist eines der besten Pakete für Data Science- und Machine Learning-Aufgaben. Enthält eine Reihe von Funktionen, die zum Erstellen von Vorhersagemodellen verwendet werden.. Es hat andere Funktionalitäten, sowie Feature-Auswahl, Datenabteilung, Datenvorverarbeitung, Modell-Tuning, Wichtigkeit von Features und vieles mehr.
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete("Caret")
Für mehr Informationen, siehe den Link unten: Paket Caret
zufälligWald
Random Forest ist eines der beliebtesten R-Pakete für maschinelles Lernen. Dieses Paket wird verwendet, um Random Forests in R zu erstellen. Kann sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden. Wir können es auch verwenden, um verlorene Werte und Ausreißer zu trainieren. Dieses Paket verwendet den Random-Forest-Algorithmus von Breiman, um Entscheidungsbäume zu erstellen.
Um einen umfassenden Überblick über unseren Datensatz zu erhalten, Wir können den folgenden Code verwenden:
install.pakete('randomForest')
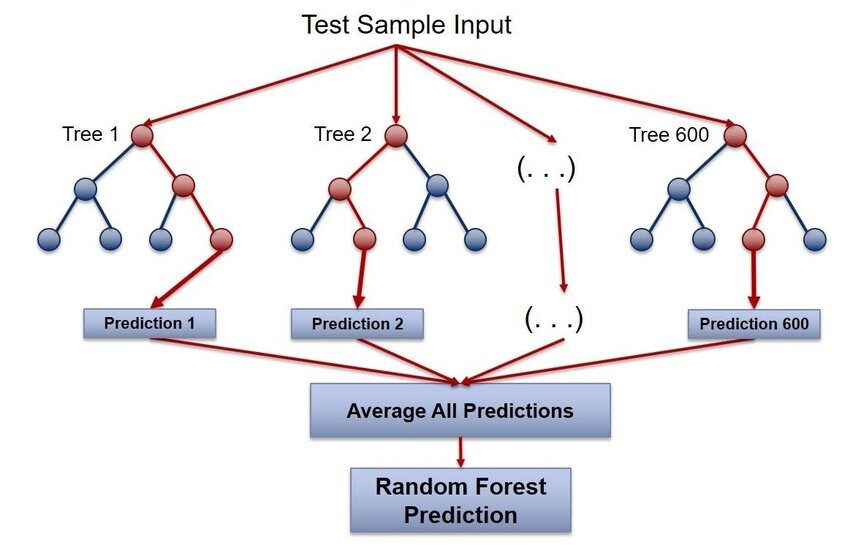
Für mehr Informationen, siehe den Link unten: Zufälliger Wald
Hell

Es ist ein R-Paket, das verwendet wird, um eine interaktive Webanwendung für Data Science zu erstellen. Hilft uns, R-Web-Apps ohne großen Aufwand zu erstellen. Shiny erstellt Webanwendungen, die im Web mit seinem Server oder R Shiny-Hosting-Services bereitgestellt werden. Zu den glänzenden Funktionen gehört das Erstellen einer App mit weniger Kenntnissen über Web-Tools, Bietet Live-Ansichten, Rendering-Funktionen und vieles mehr.
Beispiel für eine glänzende Webanwendung:
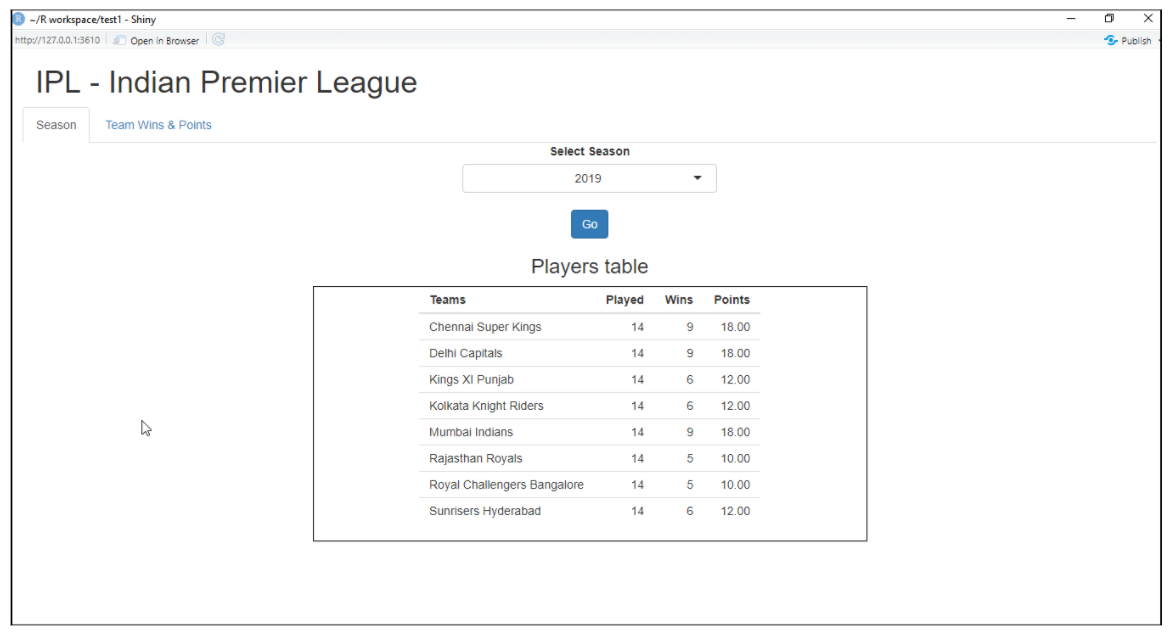
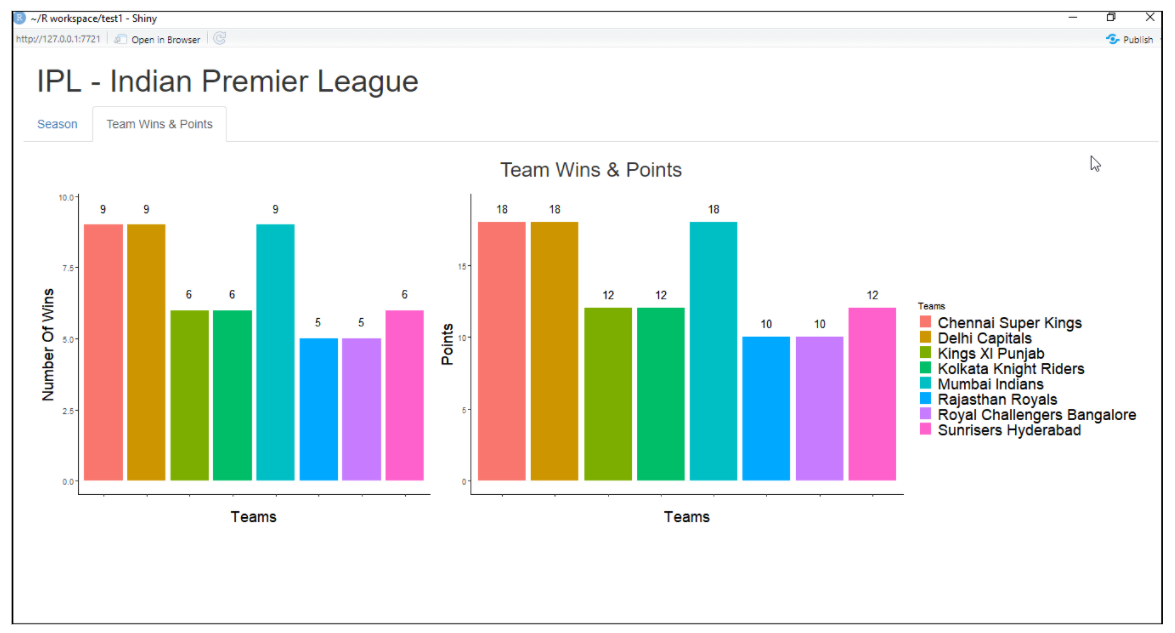
Für mehr Informationen, siehe den Link unten: Hell
mboost
Dieses Paket wird in der Datenwissenschaft für modellbasierte Impulspakete verwendet und verfügt über einen funktionalen Gradientenabstiegsalgorithmus zur Optimierung von Entscheidungsbäumen.. Es bietet auch ein Interaktionsmodell für potenziell hochdimensionale Daten.
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete('mboost')
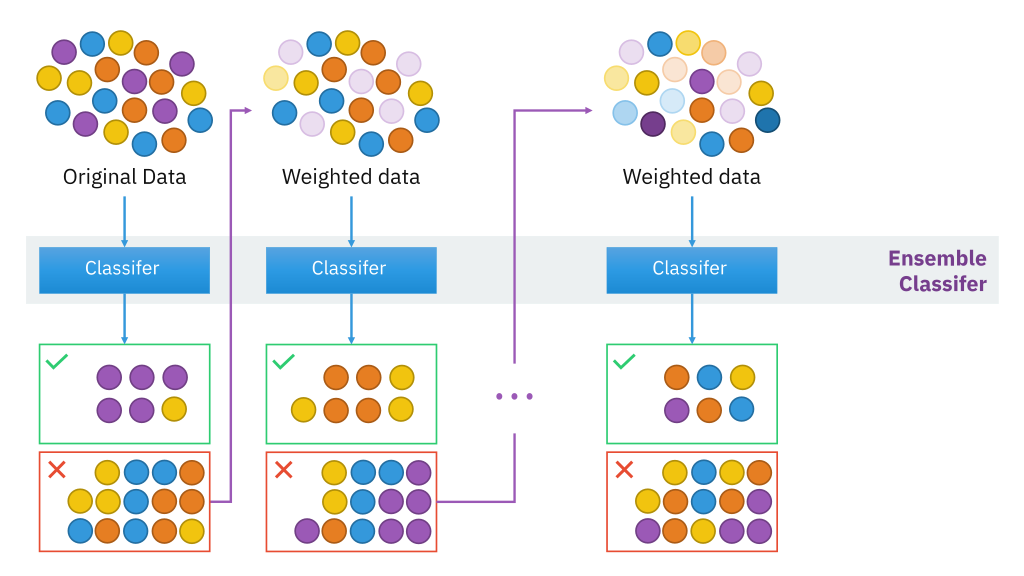
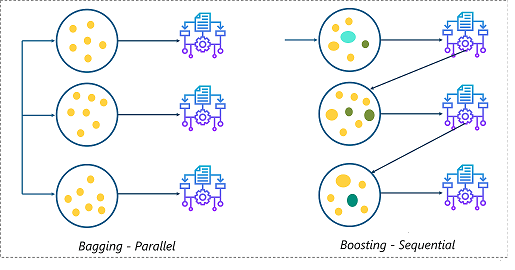
Für mehr Informationen, siehe den Link unten: mboost
Handlung
Es ist eine Grafikbibliothek, die interaktive Diagramme erstellt. Es ist eine High-Level-Schnittstelle für Plotly.js, Basierend auf D3.js. Bietet eine benutzerfreundliche Benutzeroberfläche zur Generierung eleganter interaktiver D3-Grafiken. Diese interaktiven Diagramme bieten viele Funktionalitäten, z. B. die Möglichkeit, Grafiken zu vergrößern und zu verkleinern, Bewegen Sie den Mauszeiger über einen Punkt, um weitere Informationen zu erhalten, Filtern von Daten und vielem mehr.

Enthält ein Beispiel für Diagramme als Streudiagramme., Liniendiagramme, Balkendiagramme, Rundwagen, Blasendiagramme, Boxplots, Histogramme, Fehlerindikatoren, Geigendiagramme und vieles mehr.
Für mehr Informationen, siehe den Link unten: Handlung
SuperML
Superml ist eines der bekanntesten R-Pakete für KI, das eine Standardschnittstelle für Kunden bereitstellt, die Python- und R-Programmierdialekte zum Erstellen von KI-Modellen verwenden.. Dieses Paket bietet im Wesentlichen die Highlights von Scikit Learn und prognostiziert die Schnittstelle für die Vorbereitung von KI-Modellen in R. Neben der Erstellung von KI-Modellen, Es gibt komfortable Funktionalitäten, um Funktionstechnik durchzuführen.
So installieren Sie dieses Paket, Verwenden Sie den folgenden Code:
install.pakete('SuperML')
Für mehr Informationen, siehe den Link unten: SuperML
Vielen Dank für das Lesen dieses Artikels und für Ihre Geduld.. Lassen Sie mich im Kommentarbereich über Kommentare. Teile diesen Artikel, es wird mir die Motivation geben, mehr Blogs für die Data Science Community zu schreiben.
Danke, dass du das gelesen hast. Wenn dir dieser Artikel gefällt, Teile es mit deinen Freunden. Bei Anregungen / Zweifel, kommentiere unten.
E-Mail-Identifikation: [E-Mail geschützt]
Folgen Sie mir auf LinkedIn: LinkedIn
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





