Quelle: https://www.serokell.io
Im Bild oben, Sie können sehen, dass E-Mails als Spam eingestuft werden oder nicht. Dann, ist ein Beispiel für die Klassifizierung (binäre Klassifikation).
1. Logistische Regression
2. Bayes ingenuo
3. K-Nächste Nachbarn
5. Entscheidungsbaum
Wir werden alle Algorithmen mit einem kleinen Code sehen, der im Iris-Datensatz angewendet wird, der für Klassifizierungsaufgaben verwendet wird. Der Datensatz hat 150 Instanzen (Reihen), 4 Merkmale (Säulen) und enthält keinen Nullwert. Es gibt 3 Klassen im Iris-Datensatz:
– Seidige Iris
– Iris Versicolor
– Iris Virginica
Es ist ein sehr grundlegender, aber wichtiger Klassifikationsalgorithmus im maschinellen Lernen, der eine oder mehrere unabhängige Variablen verwendet, um ein Ergebnis zu ermitteln. Die logistische Regression versucht, die Verbindung zu finden, die am besten zwischen der abhängigen Variablen und einer Menge unabhängiger Variablen passt. Die am besten passende Linie in diesem Algorithmus sieht aus wie die S-Form, wie das bild zeigt.
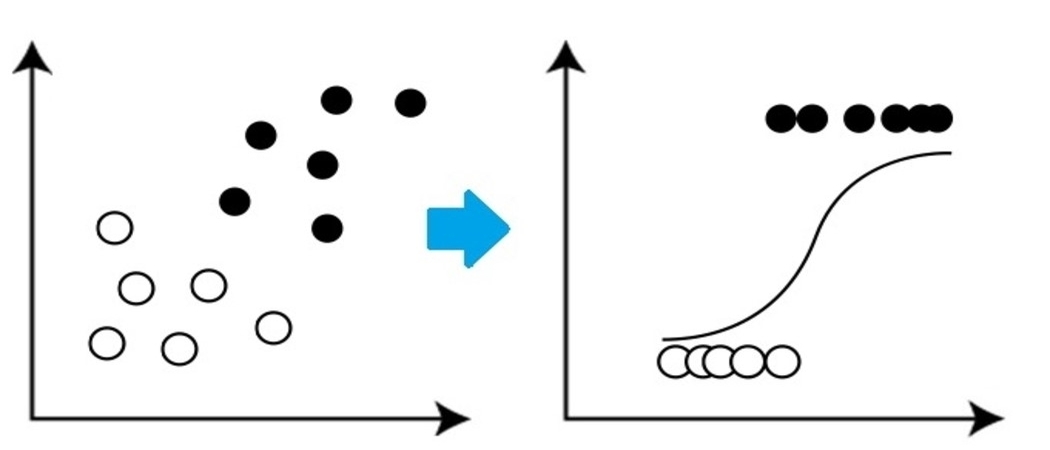
Quelle: https://www.equiskill.com
Vorteile:
- Es ist ein sehr einfacher und effizienter Algorithmus.
- Geringe Varianz.
- Bietet Wahrscheinlichkeit Beobachtungsergebnis.
Nachteile:
- Schlechtes Fahren ein großer Anzahl kategorialer Merkmale.
- Angenommen, die Daten sind frei von fehlenden Werten und die Prädiktoren sind unabhängig voneinander.
Beispiel:
aus sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression x, y = load_iris() LR_classifier = LogisticRegression(random_state=0) LR_classifier.fit(x, Ja) LR_classifier.predict(x[:3, :])
Produktion:
Array([0, 0, 0]) Es hat vorhergesagt 0 Klasse für alle 3 Tests zur Vorhersage der Funktion.
2. Bayes ingenuo
Naive Bayes se basa en Teorema de bayes was eine Annahme der Unabhängigkeit zwischen Prädiktoren ergibt. Dieser Klassifikator geht davon aus, dass das Vorhandensein eines bestimmten Merkmals in einer Klasse nicht mit dem Vorhandensein einer anderen zusammenhängt
charakteristisch / Variable.
Es gibt drei Typen von Naive Bayes-Klassifikatoren: Multinomial Naive Bayes, Bernoulli Naive Bayes, Gaussian Naive Bayes.
Vorteile:
- Dieser Algorithmus arbeitet sehr schnell.
- Es kann auch verwendet werden, um Vorhersageprobleme mit mehreren Klassen zu lösen., da es bei ihnen ganz nützlich ist.
- Dieser Klassifikator funktioniert besser als andere Modelle mit weniger Trainingsdaten, wenn die Annahme der Unabhängigkeit der Merkmale beibehalten wird..
Nachteile:
- Geht davon aus
dass alle Funktionen unabhängig sind. Obwohl es großartig klingen mag in
Theorie, Aber im wirklichen Leben, niemand kann eine Reihe unabhängiger Merkmale finden.
Beispiel:
aus sklearn.datasets import load_iris aus sklearn.model_selection import train_test_split von sklearn.naive_bayes importieren GaussianNB x, y = load_iris(return_X_y=Wahr) X_Zug, X_test, y_train, y_test = train_test_split(x, Ja, test_size=0,25, random_state=142) Naive_Bayes = GaussianNB() Naive_Bayes.fit(X_Zug, y_train) vorhersage_results = Naive_Bayes.predict(X_test) drucken(vorhersage_results)
Produktion:
Array([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
Dies sind die Klassen, die von unserem naiven Bayes-Modell für X_test-Daten vorhergesagt werden.
3. Nächster Nachbar-Algorithmus K
Sie müssen von einem beliebten Sprichwort gehört haben:
“Gleich und gleich gesellt sich gern.”
KNN arbeitet nach dem gleichen Prinzip. Klassifizieren Sie die neuen Datenpunkte basierend auf der Klasse der meisten Datenpunkte zwischen benachbarten K, wobei K die Anzahl der zu berücksichtigenden Nachbarn ist. KNN fängt die Idee der Ähnlichkeit ein (manchmal Distanz genannt,
Nähe oder Nähe) mit einigen grundlegenden mathematischen Distanzformeln wie der euklidischen Distanz, Entfernung von Manhattan, etc.

Quelle: https://www.javatpoint.com
Wählen Sie den richtigen Wert für K
So wählen Sie das geeignete K für die Daten aus, die Sie trainieren möchten, Führen Sie den KNN-Algorithmus mehrmals mit verschiedenen K-Werten aus und wählen Sie den K-Wert, der die Fehlermenge in den unsichtbaren Daten reduziert.
Vorteile:
- KNN ist einfach und leicht zu implementieren.
- Keine Notwendigkeit, ein Modell zu erstellen, verschiedene Parameter anpassen oder zusätzliche Annahmen treffen, wie einige der anderen Klassifikationsalgorithmen.
- Kann zur Klassifizierung verwendet werden, Regression und Suche. Dann, es ist flexibel.
- Der Algorithmus wird mit zunehmender Anzahl von Beispielen deutlich langsamer und / oder Prädiktoren / unabhängige Variablen.
von sklearn.neighbors importieren KNeighborsClassifier X_Zug, X_test, y_train, y_test = train_test_split(x, Ja, test_size=0,25, random_state=142) knn = KNeighborsClassifier(n_nachbarn=3) knn.fit(X_Zug, y_train) vorhersage_results = knn.vorhersage(X_test[:5,:) drucken(vorhersage_results)
Produktion:
Array([0, 1, 1, 2, 1]) Wir haben unsere Ergebnisse vorhergesagt für 5 Beispielreihen. Daher haben wir 5 ergibt ein Array.
4. SVM
SVM steht für Support Vector Machine. Dies ist ein überwachter maschineller Lernalgorithmus, der sehr häufig für Klassifikations- und Regressionsherausforderungen verwendet wird. Trotz dieses, hauptsächlich bei Klassifikationsproblemen verwendet. Das Grundkonzept der Support Vector Machine und ihre Funktionsweise lässt sich anhand dieses einfachen Beispiels besser verstehen. Dann, stell dir vor du hast zwei etiketten: grün und Blau, und unsere Daten haben zwei Eigenschaften: x Ja Ja. Wir wollen einen Klassifikator, der, ein paar gegeben (x, Ja) Koordinaten, gibt aus, wenn es so ist verde Ö Blau. Zeichnen Sie die beschrifteten Trainingsdaten auf einem Flugzeug und versuchen Sie dann, ein Flugzeug zu finden (die Hyperebene der Dimensionen nimmt zu) die die Datenpunkte beider Farben sehr klar trennt.

Quelle: https://www.javatpoint.com
Dies ist jedoch bei linearen Daten der Fall. Aber, Was ist, wenn die Daten nicht linear sind?, dann benutze den Kernel-Trick? Dann, damit umgehen, wir vergrößern die dimension, Dies bringt Daten in den Weltraum und jetzt werden die Daten linear in zwei Gruppen trennbar.
Vorteile:
- SVM funktioniert relativ gut, wenn es einen klaren Abstand zwischen den Klassen gibt.
- SVM ist in großen Räumen effektiver.
Nachteile:
- SVM ist nicht für große Datensätze geeignet.
- SVM funktioniert nicht sehr gut, wenn der Datensatz mehr Rauschen aufweist, Mit anderen Worten, wenn sich Zielklassen überschneiden. Dann, muss gehandhabt werden.
Beispiel:
von sklearn import svm svm_clf = svm.SVC() X_Zug, X_test, y_train, y_test = train_test_split(x, Ja, test_size=0,25, random_state=142) svm_clf.fit(X_Zug, y_train) vorhersage_results = svm_clf.predict(X_test[:7,:]) drucken(vorhersage_results)
Produktion:
Array([0, 1, 1, 2, 1, 1, 0])
5.Entscheidungsbaum
Der Entscheidungsbaum ist einer der am weitesten verbreiteten Algorithmen für maschinelles Lernen. Sie werden für Klassifikations- und Regressionsprobleme verwendet. Entscheidungsbäume imitieren das Denken auf menschlicher Ebene, so ist es sehr einfach, die Daten zu verstehen und gute Intuitionen und Interpretationen zu machen. In Wirklichkeit, lassen Sie die Logik der Daten erkennen, um sie zu interpretieren. Entscheidungsbäume sind nicht wie Black-Box-Algorithmen wie SVM, Neuronale Netze, etc.
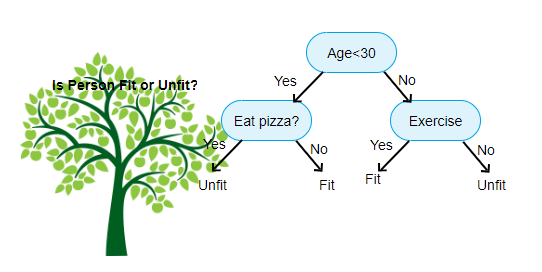
Quelle: https://www.aitimejournal.com
Als Beispiel, wenn wir eine Person als geeignet oder ungeeignet einstufen, der Entscheidungsbaum sieht auf dem Bild ein bisschen so aus.
Dann, Zusammenfassend, Ein Entscheidungsbaum ist ein Baum, in dem jeder Knoten a
charakteristisch / Attribut, jeder Zweig steht für eine Entscheidung, ein Lineal und jedes Blatt stellt ein Ergebnis dar. Dieses Ergebnis kann von kategorialem oder kontinuierlichem Wert sein. Kategorisch bei Klassifikation und kontinuierlich bei Regressionsanwendungen.
Vorteile:
- Im Vergleich zu anderen Algorithmen, Entscheidungsbäume erfordern weniger Aufwand für die Datenaufbereitung während der gesamten Vorverarbeitung.
- Sie erfordern auch keine Datennormalisierung oder -skalierung.
- Das im Entscheidungsbaum entwickelte Modell ist sehr intuitiv und sowohl für technische Teams als auch für Stakeholder leicht zu erklären..
Nachteile:
- Wenn auch nur eine kleine Änderung an den Daten vorgenommen wird, Dies kann zu einer großen Änderung in der Entscheidungsbaumstruktur führen, die zu Instabilität führt.
- Manchmal, Berechnung kann im Vergleich zu anderen Algorithmen viel komplexer sein.
- Entscheidungsbäume brauchen normalerweise länger, um das Modell zu trainieren.
Beispiel:
aus dem sklearn-Importbaum dtc = tree.DecisionTreeClassifier() X_Zug, X_test, y_train, y_test = train_test_split(x, Ja, test_size=0,25, random_state=142) dtc.fit(X_Zug, y_train) vorhersage_results = dtc.predict(X_test[:7,:]) drucken(vorhersage_results)
Produktion:
Array([0, 1, 1, 2, 1, 1, 0])
Abschließende Anmerkungen
Dies sind die 5 beliebtesten Ranking-Algorithmen, es gibt noch viel mehr und auch fortgeschrittene Algorithmen. Entdecken Sie sie weiter. Lass uns verbinden LinkedIn
Danke fürs Lesen, wenn du hier bist 🙂
Die in diesem Beitrag gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





