Einführung
Algorithmen des maschinellen Lernens werden in drei Typen eingeteilt: überwachtes Lernen, unüberwachtes Lernen und verstärktes Lernen. K-Means-Clustering ist eine unbeaufsichtigte maschinelle Lerntechnik. Wenn die Ausgangs- oder Antwortvariable nicht bereitgestellt wird, Dieser Algorithmus wird verwendet, um die Daten in verschiedene Gruppen zu kategorisieren, um sie besser zu verstehen. Auch als datengesteuerter maschineller Lernansatz bekannt, da es Daten basierend auf versteckten Mustern gruppiert, Wissen und Ähnlichkeiten in Daten.
Betrachten Sie das folgende Diagramm: wenn Sie aufgefordert werden, die Personen auf dem Bild in verschiedene Gruppen oder Gruppen zu gruppieren und Sie nichts darüber wissen, werde sicherlich versuchen, die Qualitäten zu lokalisieren, Eigenschaften oder körperliche Eigenschaften, die diese Menschen teilen. Nachdem ich diese Leute beobachtet habe, Daraus wird geschlossen, dass sie aufgrund ihrer Höhe und Breite getrennt werden können; da Sie keine Vorkenntnisse über diese Personen haben. K-Means-Clustering leistet ungefähr äquivalente Arbeit. Versuchen Sie, die Daten anhand von Ähnlichkeiten und versteckten Mustern in Gruppen zu klassifizieren. “K” beim Clustering von K-Means bezieht sich auf die Anzahl der Cluster, die der Algorithmus in den Daten erzeugt.
K-Means-Gruppierung: Wie funktioniert es?
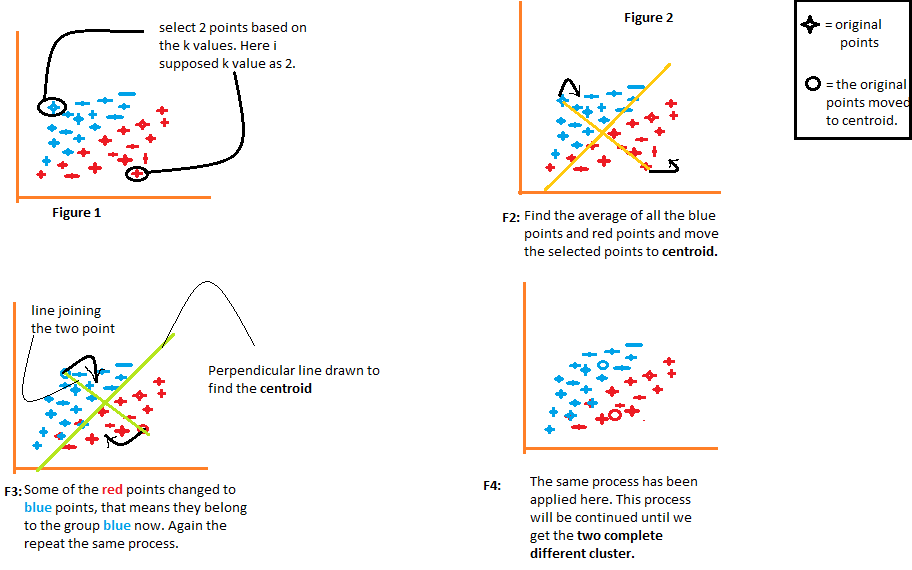
1) Der Algorithmus wählt willkürlich die Anzahl k der Schwerpunkte, wie in der Abbildung angegeben 1 aus dem folgenden Diagramm. Wobei k die Anzahl der Cluster ist, die der Algorithmus erzeugen würde. Nehmen wir an, wir möchten, dass der Algorithmus zwei Gruppen aus den Daten erstellt, also setzen wir den Wert von k auf 2.
2) Gruppieren Sie dann die Daten in zwei Teile, indem Sie die von beiden Schwerpunkten berechneten Abstände verwenden., wie in Abbildung dargestellt 2. Der Abstand jedes Punktes von beiden Schwerpunkten wird einzeln berechnet und später zu der Gruppe desjenigen Schwerpunkts hinzugefügt, mit dem der Abstand berechnet wird. kürzer.
Der Algorithmus zeichnet auch eine Linie, die die Schwerpunkte verbindet, und eine senkrechte Linie, die versucht, die Daten in zwei Gruppen zu gruppieren.
3) Sobald alle Datenpunkte basierend auf ihren Mindestabständen von den entsprechenden Schwerpunkten gruppiert sind, der Algorithmus berechnet den Mittelwert jeder Gruppe. Dann werden die Mittel- und Schwerpunktwerte jeder Gruppe verglichen. Wenn der Schwerpunktwert vom Mittelwert abweicht, dann verschiebt sich der Schwerpunkt zum Mittelwert der Gruppe. Sowohl der Schwerpunkt “rot” Als die “Blau” werden in den Mittelwert der Gruppe in der Abbildung verschoben 3 aus dem folgenden Diagramm.
Gruppieren Sie die Daten erneut mit diesen aktualisierten Schwerpunkten. Aufgrund der Positionsänderung der Schwerpunkte, einige Datenpunkte können nun in die andere Gruppe verschoben werden.
4) Nochmal, berechnet den Mittelwert und vergleicht ihn mit dem Schwerpunkt der neu generierten Gruppen. Wenn beide unterschiedlich sind, der Schwerpunkt wird zurück in den Gruppenmittelwert verschoben. Dieser Vorgang der Mittelwertberechnung und des Vergleichs mit dem Schwerpunkt wird wiederholt, bis die Werte des Schwerpunkts und des Mittelwerts gleich sind. (Schwerpunktwert = Gruppenmittelwert). Dies ist der Punkt, an dem der Algorithmus die Daten in "K Gruppen" segmentiert hat’ (2 in diesem Fall).
So finden Sie den optimalen Wert von k . heraus?
Der erste Schritt besteht darin, einen Wert für k . anzugeben. Jeder nachfolgende Schritt, der vom Algorithmus ausgeführt wird, hängt vollständig vom angegebenen Wert von k . ab. Dieser Wert von k hilft dem Algorithmus, die Anzahl der zu generierenden Cluster zu bestimmen. Dies unterstreicht, wie wichtig es ist, den genauen Wert von k . anzugeben. Hier, eine Methode bekannt als die “Ellenbogenmethode” um den richtigen Wert von k . zu bestimmen. Dies ist ein Graph von ‘Anzahl der Cluster K’ gegen “Summe innerhalb der Summe des Quadrats”. Auf der x-Achse sind diskrete Werte von k aufgetragen, während die Quadratsummen der Gruppen auf der y-Achse aufgetragen sind.
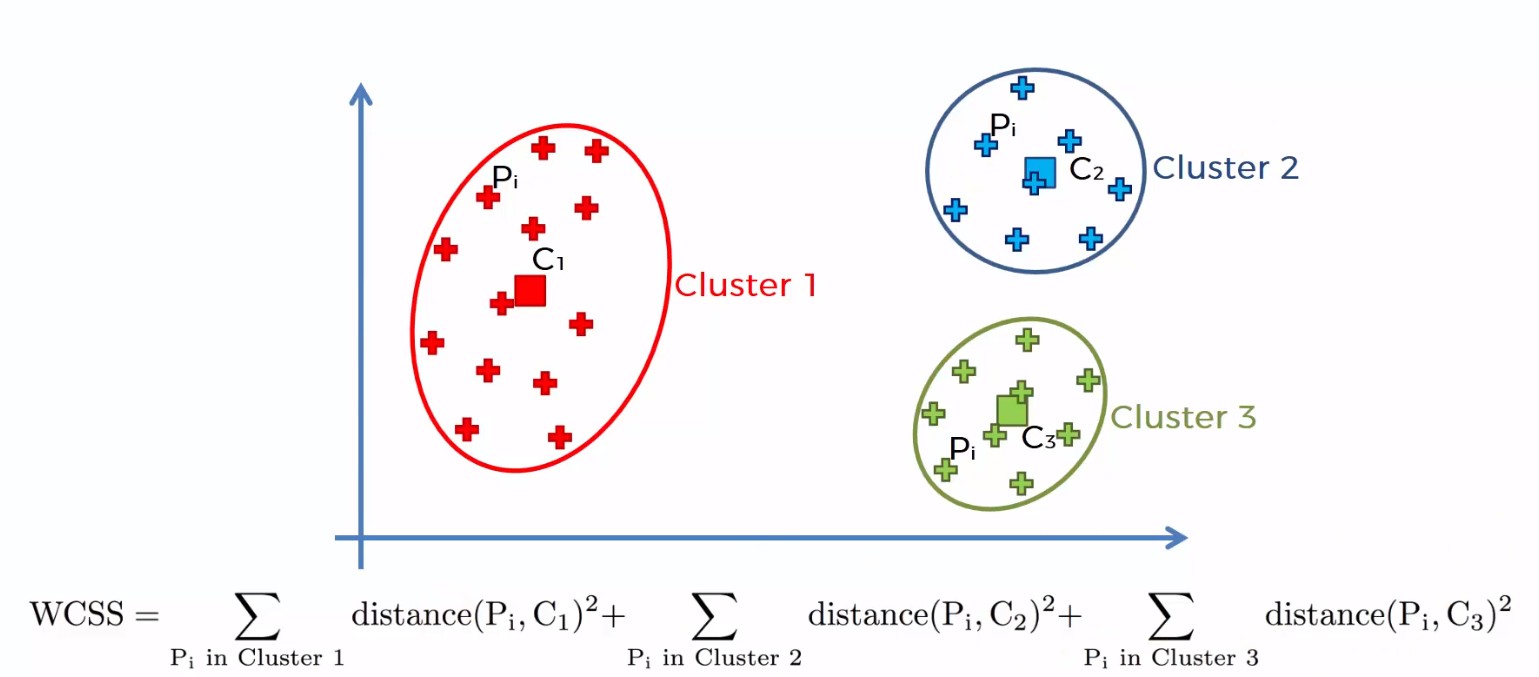
Die Summe der quadrierten Abstände zwischen den einzelnen Punkten und dem Schwerpunkt in jeder Gruppe, gefolgt von der Summe der quadrierten Distanzen für alle Cluster, Es heißt "Summe der Quadrate innerhalb des Clusters". Sie werden dies mit Hilfe der folgenden Schritte verstehen können.
1) Berechnen Sie den Abstand zwischen dem Schwerpunkt und jedem Punkt in der Gruppe, quadrieren und dann die quadrierten Distanzen für alle Punkte in der Gruppe addieren.
2) Berechnen Sie die Summe der quadrierten Distanzen der verbleibenden Gruppen auf die gleiche Weise.
3) Schließlich, addieren Sie alle Summen der Gruppen, um den Wert der "Summe des Quadrats innerhalb der Gruppe" zu erhalten, wie in der folgenden Abbildung gezeigt.
Das “Summe innerhalb der Summe des Quadrats” beginnt mit steigendem Wert von k abzunehmen. Der Graph zwischen der Anzahl der Cluster und der Summe innerhalb der Summe der Quadrate ist in der folgenden Abbildung dargestellt. Die optimale Anzahl von Clustern, oder der richtige Wert von k, ist der Punkt, an dem der Wert langsam zu sinken beginnt; das ist bekannt als “Ellbogenpunkt”, und der Ellbogenpunkt in der folgenden Grafik ist k = 4. Das “Ellbogenmethode” es ist nach der Ähnlichkeit des Graphen mit dem Ellenbogen benannt, und der Sweetspot für “k” ist der Ellenbogenpunkt .
Vorteile von k-Means-Clustering
1) Getaggte Daten sind nicht obligatorisch. Da viele Daten aus der realen Welt nicht gekennzeichnet sind, infolge, werden häufig in einer Vielzahl von realen Problemstellungen verwendet.
2) Es ist einfach zu implementieren.
3) Kann mit riesigen Datenmengen umgehen.
4) Wenn die Daten groß sind, schneller arbeiten als hierarchische Gruppierungen (für k kleine).
Nachteile von K-Means-Clustering
1) Der Wert von K muss manuell über die gewählt werden “Ellenbogenmethode”.
2) Das Vorhandensein von Ausreißern würde sich nachteilig auf die Gruppierung auswirken. Infolge, Ausreißer müssen entfernt werden, bevor die K-Means-Gruppierung verwendet wird.
3) Gruppen überschneiden sich nicht; ein Punkt kann immer nur einer Gruppe angehören. Aufgrund fehlender Überschneidungen, bestimmte Punkte werden in falsche Gruppen eingeordnet.
Gruppierung von K-Mitteln mit R
- Wir werden die folgenden Bibliotheken in unsere Arbeit importieren.
Bücherei (Interkalation)
Bücherei (ggplot2)
Bücherei (dplyr)
- Wir werden mit den Irisdaten arbeiten, bestehend aus drei Klassen: “Iris-seidig”, “Iris-Versicolor” e “Iris-Virginica”.
Daten <- lesen.csv ("iris.csv", Kopfzeile = T)
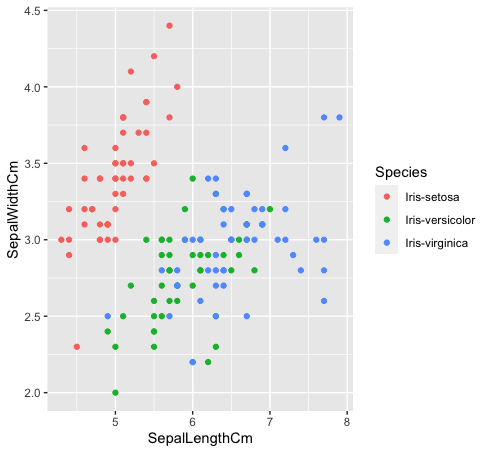
- Mal sehen, wie diese drei Klassen miteinander zusammenhängen. Die Arten “Iris-Versicolor” (verde) e “Iris-Verginica” (Blau) sind nicht linear trennbar. Wie Sie in der Grafik unten sehen können, sie vermischen sich.
Daten%>% ggplot (aes (KelchlängeCm, KelchblattBreiteCm, Farbe = Spezies)) +
geom_point ()
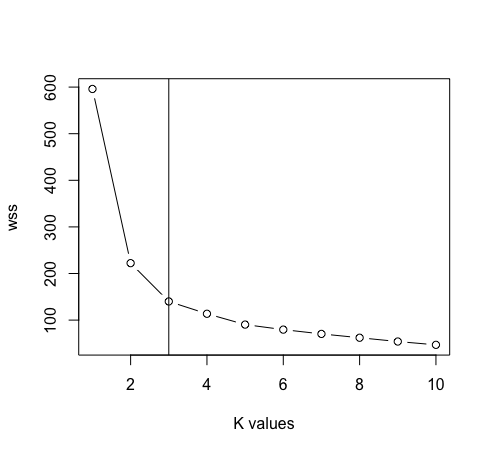
- Nachdem Sie die Artenspalte aus den Daten entfernt haben. Jetzt verwenden wir den Graphen der Ellbogenmethode zwischen “Summe der Quadrate innerhalb des Clusters” Ja “K-Werte” um den geeigneten Wert von k . zu bestimmen. K = 3 ist in diesem Fall der beste Wert für k (Notiz: Es gibt 3 Klassen in den Original-Irisdaten, was die Genauigkeit des Wertes von k . garantiert).
Daten <- Daten[, -5]
maximal <- 10
schuppen <- Skala (Daten)
wss <- sapple (1: maximal, Funktion (k) {kmeans (schuppen, k, nstart = 50, iter.max = 15) $ tot.withinss})
Handlung (1: max, wss, Typ = “B”, xlab = “k-Werte”)
abline (v = 3)
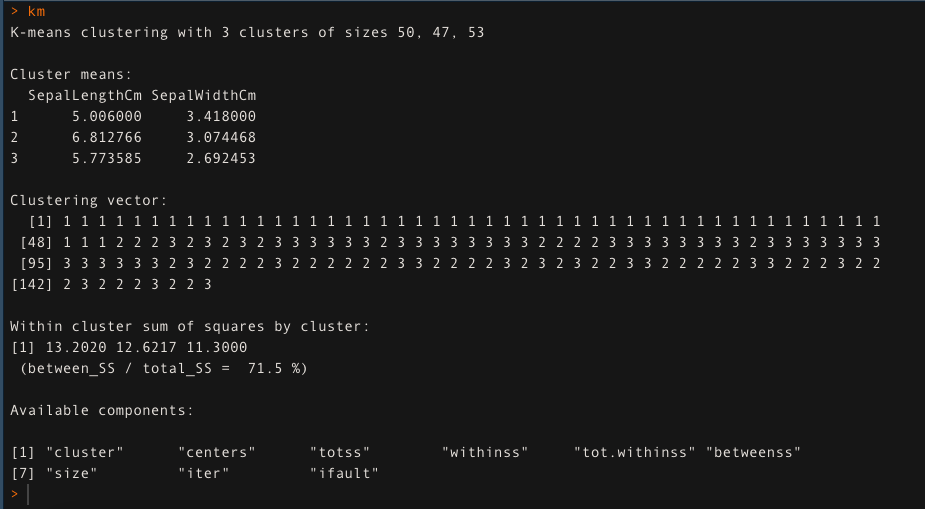
- Für k = 3, Wenden Sie den K-Means-Clustering-Algorithmus an. Der K-Means-Clustering-Ansatz erklärt die 71,5% der Variabilität der Daten in diesem Fall.
km <- Kmedias (Daten[,1:2], k = 3, iter.max = 50)
km
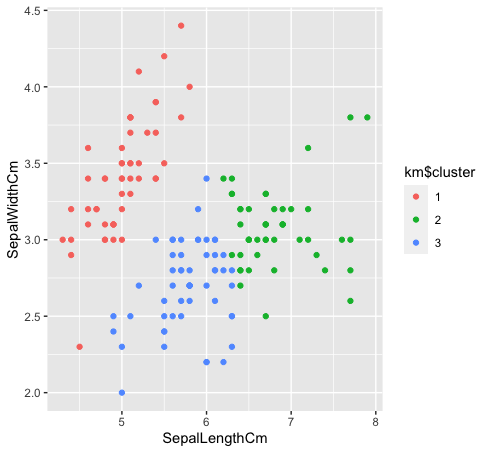
- Sehen wir uns an, wie die drei Klassen durch Clustering von k-means gruppiert werden. K-Means-Clustering erzeugt keine überlappenden Cluster, wie wir alle wissen. Da die Arten “verde” Ja “Blau” sind in den Originaldaten nicht linear trennbar, die Gruppierung von k-Means konnte es nicht erfassen, da es reduzierte Gruppen hat.
km $ Cluster <- as.faktor (km $ Cluster)
Daten%>% ggplot (aes (KelchlängeCm, KelchblattBreiteCm, Farbe = km $ Cluster)) +
geom_point ()
Ein Artikel von ~
Shivam Sharma.
Die in diesem Artikel über den K-Means-Gruppierungsalgorithmus gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





