Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Python ist eine vielseitige Sprache. Wird für allgemeine Programmier- und Entwicklungszwecke verwendet, und auch für komplexe Aufgaben wie Machine Learning, Datenwissenschaft und Datenanalyse. Es ist nicht nur leicht zu lernen, Es hat auch einige wundervolle Bibliotheken, was es für viele Menschen zur Programmiersprache der ersten Wahl macht.
In diesem Artikel, Wir werden einen dieser Python-Anwendungsfälle sehen. Wir werden Python verwenden, um die Leistung des indischen Cricketspielers MS Dhoni . zu analysieren in Ihrer One Day International-Karriere (ODI).

Datensatz
Wenn Sie mit dem Konzept des Web-Scrapings vertraut sind, Sie können die Daten daraus extrahieren ESPN-Cricinfo-Link. Wenn Sie sich mit Web-Scraping nicht auskennen, mach dir keine Sorgen! Sie können die Daten direkt herunterladen von hier. Die Daten stehen als Excel-Datei zum Download zur Verfügung.
Sobald Sie den Datensatz bei sich haben, Sie müssen es in Python laden. Sie können das folgende Code-Snippet verwenden, um das Dataset in Python zu laden:
# Importieren wichtiger Bibliotheken und Pakete
Pandas als pd importieren
numpy als np importieren
Datum/Uhrzeit importieren
import matplotlib.pyplot als plt
Seegeboren als sns importieren
# den Datensatz lesen
df = pd.read_excel('MS_Dhoni_ODI_record.xlsx')
Nachdem der Datensatz gelesen wurde, wir müssen uns den Anfang und das Ende des Datensatzes ansehen, um sicherzustellen, dass er korrekt importiert wird. Der Datensatz-Header sollte so aussehen:
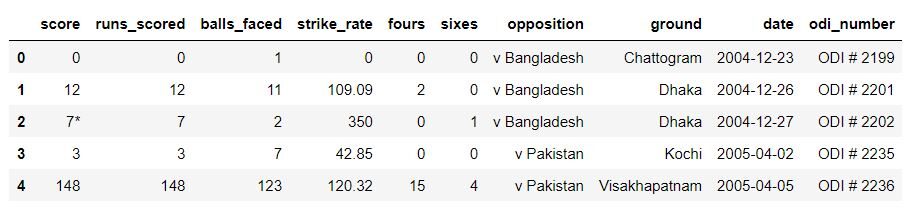
Wenn die Daten richtig geladen werden, wir können zum nächsten schritt gehen, Datenbereinigung und -aufbereitung.
Datenbereinigung und -aufbereitung
Diese Daten wurden von einer Webseite extrahiert, Sie sind also nicht sehr sauber. Wir beginnen mit dem Entfernen des ersten 2 Zeichen aus der Oppositionszeichenfolge, da dies nicht erforderlich ist.
# das erste entfernen 2 Zeichen in der Oppositionszeichenfolge df['Opposition'] = df['Opposition'].anwenden(Lambda x: x[2:])
Dann, Wir werden eine Kolumne für das Jahr erstellen, in dem das Spiel gespielt wurde. Stellen Sie sicher, dass die Datumsspalte in Ihrem DataFrame im DateTime-Format vorhanden ist. Andererseits, Dienstprogramm pd.to_datetime () um es in das DateTime-Format zu konvertieren.
# Erstellen einer Funktion für das Spieljahr df['Jahr'] = df['Datum'].dt.Jahr.astype(int)
Wir werden auch eine Spalte erstellen, die anzeigt, ob Dhoni in diesem Eintrag nicht enthalten war oder nicht.
# Erstellen einer Funktion, um nicht draußen zu sein
df['Spielstand'] = df['Spielstand'].anwenden(str)
df['nicht_aus'] = np.wo(df['Spielstand'].str.endetmit('*'), 1, 0)
Jetzt werden wir die Spalte der ODI-Nummer entfernen, da sie nicht notwendig ist.
# das odi_number-Feature fallen lassen, weil es der Analyse keinen Wert hinzufügt df.drop(Spalten="odi_nummer", inplace=Wahr)
Wir werden auch alle Übereinstimmungen aus unseren Aufzeichnungen entfernen, bei denen Dhoni nicht getroffen hat, und diese Informationen in einem neuen DataFrame speichern.
# die Innings fallen lassen, bei denen Dhoni nicht geschlagen hat, und in einem neuen DataFrame speichern df_new = df.loc[((df['Spielstand'] != 'DNB') & (df['Spielstand'] != 'TDNB')), 'runs_score':]
Schließlich, Wir werden die Datentypen aller Spalten in unserem neuen DataFrame korrigieren.
# Festlegen der Datentypen von numerischen Spalten df_neu['runs_score'] = df_neu['runs_score'].astyp(int) df_neu['balls_faced'] = df_neu['balls_faced'].astyp(int) df_neu['Trefferquote'] = df_neu['Trefferquote'].astyp(schweben) df_neu['Vierer'] = df_neu['Vierer'].astyp(int) df_neu['Sechser'] = df_neu['Sechser'].astyp(int)
Rennstatistiken
Wir werden uns das anschauen beschreibende Statistiken über die ODI-Karriere von MS Dhoni. Sie können dafür den folgenden Code verwenden:
first_match_date = df['Datum'].dt.datum.min().strftime('%B %d, %UND') # erstes Spiel
drucken('Erstes Spiel:', first_match_date)
letztes_match_date = df['Datum'].dt.Datum.max().strftime('%B %d, %UND') # letztes Spiel
drucken('nLetztes Spiel:', letztes_match_date)
number_of_matches = df.shape[0] # Anzahl der in der Karriere gespielten Mathe
drucken('nAnzahl der gespielten Spiele:', Anzahl_der_Übereinstimmungen)
number_of_inns = df_new.shape[0] # Anzahl der Innings
drucken('nAnzahl der gespielten Innings:', number_of_inns)
not_outs = df_new['nicht_aus'].Summe() # Anzahl der Nicht-Outs in der Karriere
drucken('nNicht outs:', not_outs)
run_scored = df_new['runs_score'].Summe() # Läufe in der Karriere erzielt
drucken('nRuns punktete in der Karriere:', läuft_score)
balls_faced = df_new['balls_faced'].Summe() # Bälle konfrontiert in der Karriere
drucken('nBalls in der Karriere konfrontiert:', balls_faced)
karriere_sr = (läuft_score / balls_faced)*100 # Berufsstreikquote
drucken('nKarriere-Streikrate: {:.2F}'.Format(karriere_sr))
karriere_avg = (läuft_score / (number_of_inns - not_outs)) # Karrieredurchschnitt
drucken('nKarrieredurchschnitt: {:.2F}'.Format(karriere_avg))
höchstes_score_date = df_new.loc[df_new.runs_scored == df_new.runs_scored.max(), 'Datum'].Werte[0]
höchste_punktzahl = df.loc[df.date == höchstes_score_date, 'Spielstand'].Werte[0] # höchste Punktzahl
drucken('nHöchste Punktzahl in der Karriere:', höchste Punktzahl)
Hunderte = df_new.loc[df_neu['runs_score'] >= 100].Form[0] # Anzahl von 100s
drucken('nAnzahl von 100s:', Hunderte)
fünfziger Jahre = df_new.loc[(df_neu['runs_score']>=50)&(df_neu['runs_score']<100)].Form[0] #Anzahl der 50er
drucken('nAnzahl 50er:', fünfziger Jahre)
Vierer = df_neu['Vierer'].Summe() # Nummer vier in der Karriere
drucken('nAnzahl von 4s:', Vierer)
Sechsen = df_new['Sechser'].Summe() # Anzahl von Sechsen in der Karriere
drucken('nAnzahl von 6s:', Sechser)
Die Ausgabe sollte so aussehen:
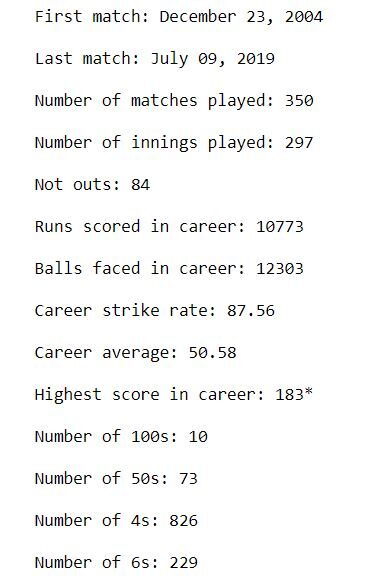
Dies gibt uns einen guten Überblick über den gesamten Werdegang von MS Dhoni. Begann zu spielen in 2004, und zuletzt ein ODI gespielt in 2019. In einer Karriere von mehr als 15 Jahre, hat 10 Hundert und eine erstaunliche Menge von 73 fünfzig. Hat mehr erzielt als 10,000 Karrieren in seiner Karriere mit einem Durchschnitt von 50.6 und eine Strike-Rate von 87.6. Ihre höchste Punktzahl ist 183 *.
Jetzt werden wir eine umfassendere Analyse ihrer Leistung gegen verschiedene Teams durchführen. Wir werden auch ihre Leistung Jahr für Jahr sehen. Dazu nehmen wir die Hilfe von Visualisierungen in Anspruch.
Analyse
Zuerst, wir werden sehen wie viele Spiele, die Sie gegen verschiedene Gegner gespielt haben. Dazu können Sie folgenden Code verwenden:
# Anzahl der Spiele gegen verschiedene Gegner df['Opposition'].value_counts().Handlung(kind='bar', Titel="Anzahl der Spiele gegen verschiedene Gegner", Feigengröße=(8, 5));
Die Ausgabe sollte so aussehen:
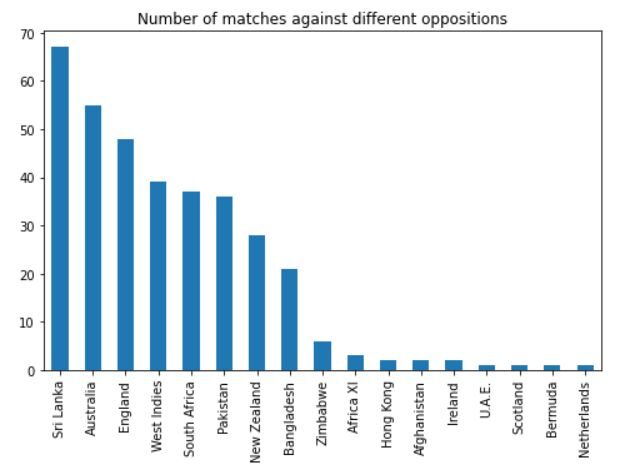
Wir können sehen, dass er die meisten seiner Spiele gegen Sri Lanka bestritten hat, Australien, England, Westindische Inseln, Südafrika und Pakistan.
Mal sehen wie viele Karrieren, die Sie gegen verschiedene Gegner erzielt haben. Sie können das folgende Code-Snippet verwenden, um das Ergebnis zu generieren:
run_scored_by_opposition = pd.DataFrame(df_new.groupby('Opposition')['runs_score'].Summe())
run_scored_by_opposition.plot(kind='bar', Titel="Läufe, die gegen verschiedene Gegner erzielt wurden", Feigengröße=(8, 5))
plt.xlabel(Keiner);
Die Ausgabe sieht so aus:
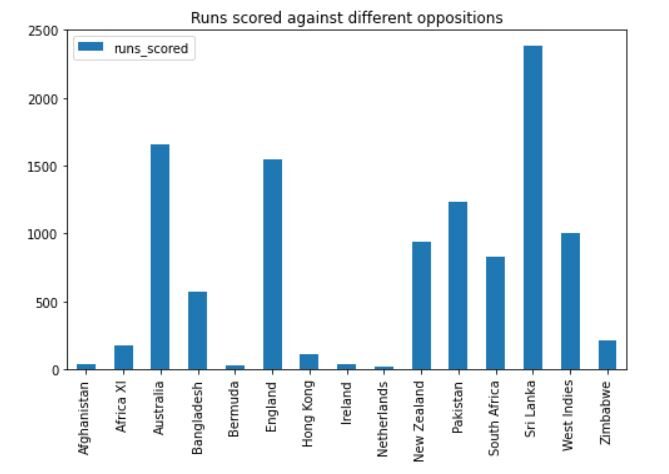
Wir können sehen, dass Dhoni gegen Sri Lanka die meisten Runs erzielt hat, gefolgt von Australien, England und Pakistan. Er hat auch viele Spiele gegen diese Teams bestritten, also macht es sinn.
Um ein klareres Bild zu haben, lass uns einen Blick auf deine werfen Schlagdurchschnitt gegen jedes Team. Der folgende Code-Schnipsel hilft uns, das gewünschte Ergebnis zu erzielen:
innings_by_opposition = pd.DataFrame(df_new.groupby('Opposition')['Datum'].zählen())
not_outs_by_opposition = pd.DataFrame(df_new.groupby('Opposition')['nicht_aus'].Summe())
temp = run_scored_by_opposition.merge(innings_by_opposition, left_index=Wahr, right_index=Wahr)
Average_by_opposition = temp.merge(not_outs_by_opposition, left_index=Wahr, right_index=Wahr)
Average_by_opposition.rename(Spalten = {'Datum': 'Innings'}, inplace=Wahr)
Average_by_Opposition['eff_num_of_inns'] = Average_by_Opposition['Innings'] - Average_by_Opposition['nicht_aus']
Average_by_Opposition['Durchschnitt'] = Average_by_Opposition['runs_score'] / Average_by_Opposition['eff_num_of_inns']
Average_by_opposition.replace(z.B. inf, np.nan, inplace=Wahr)
major_nations = ['Australien', 'England', 'Neuseeland', 'Pakistan', 'Südafrika', 'Sri Lanka', 'Westindische Inseln']
Um den Graphen zu generieren, Verwenden Sie das folgende Code-Snippet:
plt.figur(Feigengröße = (8, 5))
plt.plot(Average_by_opposition.loc[große_nationen, 'Durchschnitt'].Werte, Markierung="Ö")
plt.plot([karriere_avg]*len(große_nationen), '--')
plt.titel("Durchschnitt gegen große Teams")
plt.xticks(Bereich(0, 7), große_nationen)
plt.ylim(20, 70)
plt.legende(['Durchschn. gegen Opposition', "Berufsdurchschnitt"]);
Die Ausgabe sieht so aus:
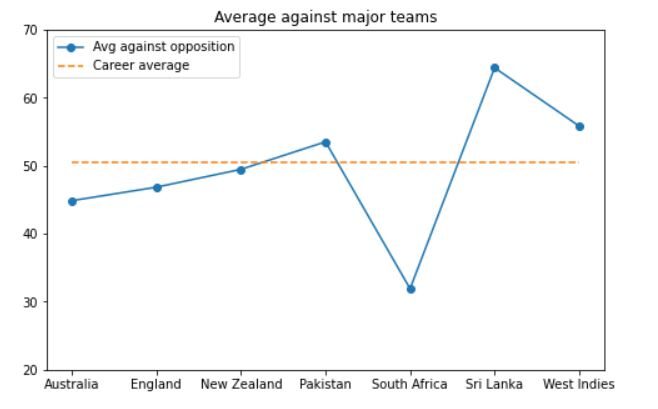
Wie wir sehen können, Dhoni hat gegen starke Teams wie Australien bemerkenswerte Leistungen gezeigt, England und Sri Lanka. Sein Durchschnitt gegen diese Teams liegt nahe seinem Karrieredurchschnitt oder etwas darüber.. Das einzige Team, gegen das er keine gute Leistung gezeigt hat, ist Südafrika.
Sehen wir uns nun ihre Jahresstatistiken an. Wir beginnen mit der Suche Wie viele Spiele hast du jedes Jahr gespielt? nach seinem Debüt. Der Code dafür wird sein:
df['Jahr'].value_counts().sort_index().Handlung(kind='bar', Titel="Gespielte Spiele nach Jahr", Feigengröße=(8, 5)) plt.xticks(Drehung=0);
Die Handlung wird so aussehen:
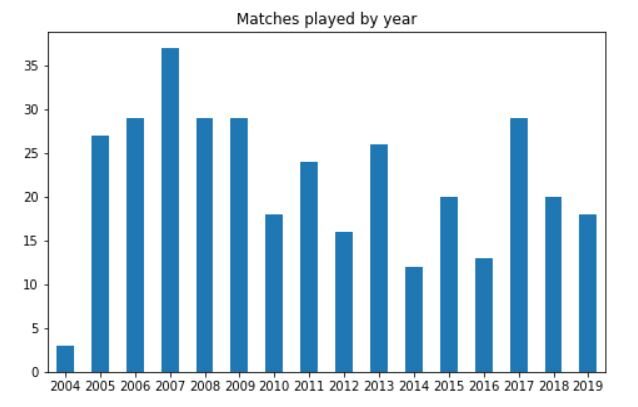
Das können wir sehen in 2012, 2014 Ja 2016, Dhoni spielte nur sehr wenige ODI-Spiele für Indien. Allgemein, nach 2005-2009, die durchschnittliche Anzahl der gespielten Spiele hat leicht abgenommen.
Wir sollten uns auch anschauen, wie viele Karrieren, die er jedes Jahr geprägt hat. Der Code dafür wird sein:
df_new.groupby('Jahr')['runs_score'].Summe().Handlung(kind='line', Markierung="Ö", Titel="Läufe nach Jahr gezählt", Feigengröße=(8, 5))
Jahre = df['Jahr'].einzigartig().auflisten()
plt.xticks(Jahre)
plt.xlabel(Keiner);
Die Ausgabe sollte so aussehen:
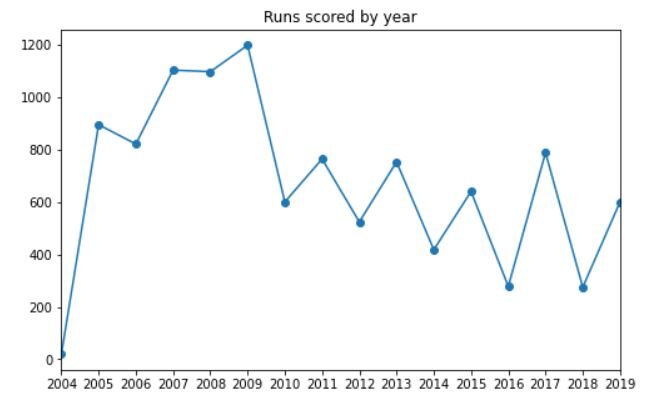
Man kann deutlich sehen, dass Dhoni die meisten Runs des Jahres erzielt hat 2009, gefolgt von 2007 Ja 2008. Die Anzahl der Läufe begann nach zu sinken 2010 (weil auch die Anzahl der gespielten Spiele abgenommen hat).
Schließlich, lass uns seine sehen Durchschnittlicher Karriere-Schlagfortschritt pro Inning. Dies sind Zeitreihendaten und wurden in einem Liniendiagramm aufgetragen. Der Code dafür wird sein:
df_new.reset_index(drop=wahr, inplace=Wahr) career_average = pd.DataFrame() Karrieredurchschnitt['runs_scored_in_career'] = df_neu['runs_score'].cumsum() Karrieredurchschnitt['Innings'] = df_new.index.tolist() Karrieredurchschnitt['Innings'] = Karriere_Durchschnitt['Innings'].anwenden(Lambda x: x+1) Karrieredurchschnitt['not_outs_in_career'] = df_neu['nicht_aus'].cumsum() Karrieredurchschnitt['eff_num_of_inns'] = Karriere_Durchschnitt['Innings'] - Karrieredurchschnitt['not_outs_in_career'] Karrieredurchschnitt['Durchschnitt'] = Karriere_Durchschnitt['runs_scored_in_career'] / Karrieredurchschnitt['eff_num_of_inns']
Das Code-Snippet für die Handlung ist:
plt.figur(Feigengröße = (8, 5))
plt.plot(Karrieredurchschnitt['Durchschnitt'])
plt.plot([karriere_avg]*karriere_durchschnittlich.shape[0], '--')
plt.titel('Durchschnittlicher Karriereverlauf nach Innings')
plt.xlabel('Anzahl der Innings')
plt.legende(['Durchschn. Progression', "Berufsdurchschnitt"]);
Das Ausgabediagramm sieht so aus:
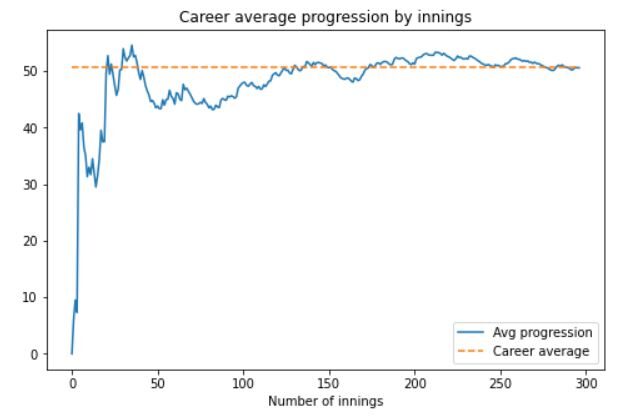
Wir können das nach einem langsamen Start und einem Leistungsabfall bei der Eingabenummer sehen 50, Dhonis Leistung erholte sich erheblich. Gegen Ende seiner Karriere, durchweg gemittelt oben 50.
EndNote
In diesem Artikel, wir analysieren die Schlagleistung des indischen Cricketspielers MS Dhoni. Wir schauen uns die allgemeinen Statistiken Ihrer Karriere an, deine Leistung gegen verschiedene Gegner und deine Leistung Jahr für Jahr.
Dieser Artikel wurde von Vishesh Arora . geschrieben. Du kannst dich mit mir verbinden unter LinkedIn.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





