Überblick
- Schritt-für-Schritt-Anleitung zum Entwickeln von Fähigkeiten, um ein Data Scientist zu werden
- Funktionen wie MOOC, YouTube-Kanäle, Blog-Seiten, Websites der Data-Science-Community, um verschiedene Fähigkeiten zu erlernen
- Websites der Data-Science-Community wie Kaggle, Gesteuerte Daten, Analytics Vidhya für praktische Erfahrungen mit Datensätzen und
andere nützliche maschinelle Lerntechniken
Was ist Datenwissenschaft??
Bei Data Science geht es um “Mit verschiedenen Techniken, Algorithmen zur Analyse großer Datenmengen (sowohl strukturiert als auch unstrukturiert), um nützliche Informationen über die Daten zu extrahieren, sie so in mehreren kommerziellen Bereichen anzuwenden”.
Warum gibt es einen Bedarf an Data Scientists?
Daten wird Tag für Tag massiv erzeugt und solche riesigen Datensätze zu verarbeiten, große Unternehmen suchen gute Data Scientists, um aus diesen Datensätzen wertvolle Informationen zu extrahieren und für verschiedene Strategien zu nutzen, Geschäftsmodelle und Pläne.
Inhaltsverzeichnis
- Python lernen
- Statistiken lernen
- Datensammlung
- Datenbereinigung
- EDA-Kenntnisse (explorative Datenanalyse)
- Maschinelles Lernen und Deep Learning
- Weitere Informationen zur Implementierung des ML-Modells
- Tests aus der realen Welt
- Erkunden und Üben von Datensätzen in Kaggle, Analytics-Vidhya
- Analytische Neugier
- Nicht-technische Fähigkeiten

1. Python lernen
Der erste und wichtigste Schritt in Richtung Data Science sollte eine Programmiersprache sein (nämlich, Python). Python ist die gebräuchlichste Programmiersprache, von den meisten Datenwissenschaftlern verwendet, wegen seiner Einfachheit, Vielseitigkeit und Vorrüstung mit leistungsstarken Bibliotheken (wie NumPy, SciPy und Pandas) nützlich bei der Datenanalyse und anderen Aspekten in Data Sciences. Python ist eine Open-Source-Sprache und unterstützt verschiedene Bibliotheken.
Ressource:
MOOC: Udacity Python-Kurs, Coursera Python-Kurs
Youtube Kanal: Krish Naik, Codegrundlagen
Blogs: Analytics-Vidhya, Nuggets von KD
2. Statistiken lernen

Und Data Science ist eine Sprache, dann ist Statistik im Grunde Grammatik. Statistik ist im Grunde die Methode zur Analyse und Interpretation großer Datensätze. Wenn es um Datenanalyse und Informationsbeschaffung geht, die Statistiken sind für uns so bemerkenswert wie Luft. Statistiken helfen uns, die versteckten Details großer Datensätze zu verstehen
Ressource:
MOOC: Coursera Statistikkurs
Youtube Kanal: Krish Naik, Codegrundlagen
Blogs: Analytics-Vidhya, Nuggets von KD
3. Datensammlung
Dies ist einer der wichtigsten und wichtigsten Schritte im Bereich Data Science.. Diese Fertigkeit setzt die Kenntnis verschiedener Tools zum Importieren von Daten aus beiden lokalen Systemen voraus., als CSV-Dateien, und Daten von Websites extrahieren, mit schöne Suppe Python-Bibliothek. Verschrottung kann auch API-basiert sein. Die Datensammlung kann mit Kenntnissen der Abfragesprache oder ETL-Pipelines in Python verwaltet werden
Ressource:
MOOC: Erfassen von Coursera-Daten mit Python
4. Datenbereinigung
Dies ist der Schritt, den Sie als Data Scientist die meiste Zeit verbringen. Bei der Datenbereinigung geht es darum, die Daten zu erhalten, geeignet für Arbeit und Analyse, durch Entfernen unerwünschter Werte, fehlende Werte, kategoriale Werte, Ausreißer und falsch übermittelte Datensätze, aus der Rohform der Daten.. Die Datenbereinigung ist sehr wichtig, da reale Daten von Natur aus unordentlich sind und dies mit Hilfe verschiedener Python-Bibliotheken zu erreichen (Pandas und NumPy) ist für einen angehenden Datenwissenschaftler wirklich wichtig.
Ressource:
Blog: Python-Blog zur Datenbereinigung

5. EDA-Kenntnisse (explorative Datenanalyse)
EDA (explorative Datenanalyse) ist der wichtigste Aspekt im weiten Feld der Data Science. Beinhaltet die Analyse verschiedener Daten, Variablen, verschiedene Datenmuster, Trends und extrahieren daraus nützliche Informationen mit Hilfe verschiedener grafischer und statistischer Methoden. EDA identifiziert mehrere Muster, die der Algorithmus für maschinelles Lernen möglicherweise nicht erkennt. Inklusive aller Handhabung, Datenanalyse und Visualisierung.
Ressource:
Data-Science-Communitys: Kaggle, Vidhya-Analytik
Blog: EDA im Iris-Datensatz
Youtube Kanal: EDA-Videos in Krish Naik, Codegrundlagen
MOOC: Coursera-Kurs auf EDA, Statistiken, Wahrscheinlichkeit
6. Maschinelles Lernen und Deep Learning
Maschinelles Lernen ist die wichtigste Fähigkeit, die ein Data Scientist benötigt.. Maschinelles Lernen wird verwendet, um verschiedene Vorhersagemodelle zu erstellen, Klassifizierungsmodelle, etc., und große Unternehmen, die Unternehmen, verwenden Sie es, um ihre Planung basierend auf Vorhersagen zu optimieren. Zum Beispiel, Autopreisvorhersage
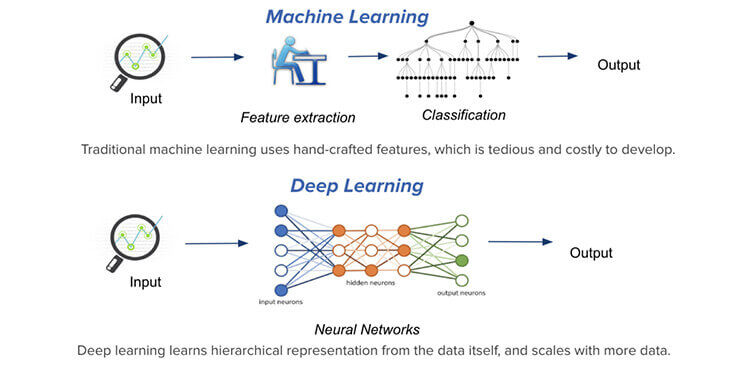
Tiefes Lernen, Zweitens, ist eine erweiterte Version von Machine Learning, die die Verwendung von neuronalen Netzwerken implementiert, ein Framework, das mehrere Algorithmen für maschinelles Lernen kombiniert, um verschiedene Aufgaben zu lösen, Daten trainieren. Mehrere neuronale Netze sind ein wiederkehrendes neuronales Netz (RNN) oder ein neuronales Faltungsnetz (CNN), etc.
Zum Beispiel: Gesichtserkennung
Meint:
Data-Science-Communitys: Kaggle, Vidhya-Analytik
Blog: Analytics-Vidhya, Nuggets von KD
Youtube Kanal: Videos in Krish Naik, Codegrundlagen
MOOC: Curso de Coursera Maschinelles Lernen, Coursera Deep Learning Spezialisierung
7. Erfahren Sie, wie Sie das ML-Modell implementieren
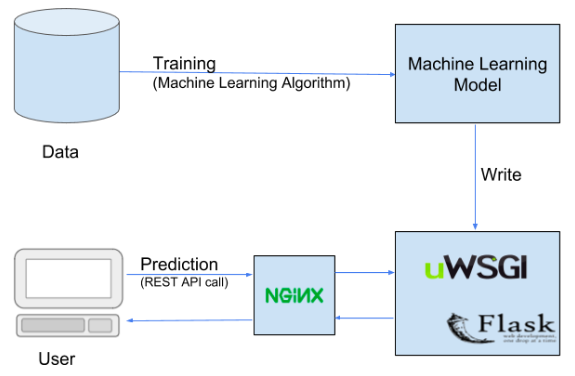
Die Bereitstellung ist im Wesentlichen der Prozess, bei dem Ihr Modell für maschinelles Lernen Endbenutzern zur Verwendung zur Verfügung gestellt wird.. Dies wird durch die Integration des Modells in verschiedene bestehende Produktionsumgebungen erreicht., Umsetzung des praktischen Einsatzes des ML-Modells für verschiedene Business-Lösungen.
Es gibt viele Dienste zur Implementierung Ihres ML-Modells wie Flask, Pythonüberall, MLOps, Microsoft Azure, Google Cloud, Heroku, etc.
Meint:
Youtube Kanal: AA-Implementierungsvideos unter Krish Naik, Codegrundlagen
Blogs: Analytics-Vidhya, Nuggets von KD
8. Tests aus der realen Welt
Tests und Validierung des Modells für maschinelles Lernen sollten nach der Implementierung durchgeführt werden, um seine Wirksamkeit und Genauigkeit zu überprüfen. Testen ist ein wichtiger Schritt in der Datenwissenschaft, um die Effizienz und Effektivität des ML-Modells in Schach zu halten.
Es gibt verschiedene Arten von Tests wie A / B, AAB-Tests, etc.
9. Erkunden und Üben von Datensätzen in Kaggle, Analytics-Vidhya

Die weltweit größten Data-Science-Communitys wie Kaggle, Analytics Vidhya ist sehr nützlich, um mit verschiedenen Datensätzen in Kontakt zu treten und, Daher, kann verwendet werden, um verschiedene Datenanalysetechniken zu üben, Algorithmen für maschinelles Lernen. Wettbewerbe, die in diesen Communities abgehalten werden, sind auch hilfreich, um die Data Science-Kenntnisse zu verbessern., hilft uns, unser Ziel zu erreichen, Data Science-Kompetenzen schneller zu erreichen..
10. Analytische Neugier
Der Bereich Data Science entwickelt sich schneller., Daher, erfordert eine angeborene Neugier, um mehr über das Gebiet zu erfahren, regelmäßige Aktualisierung und Erlernen verschiedener Fähigkeiten und Techniken.
Dies ist die wichtigste Fähigkeit, die uns immer helfen wird, zu bleiben, neue Fähigkeiten und Konzepte aktualisieren, So verhindern Sie, dass wir hinter mehreren technologischen Fortschritten in der Datenwissenschaft zurückbleiben.
11. Nicht-technische Fähigkeiten
Nicht-technisch beinhaltet Teamwork, Kommunikationsfähigkeit, Aufgabenmanagement, Geschäftsverständnis, etc
Zusammenarbeit spielt eine wichtige Rolle bei der Bereitstellung des Ergebnisses für Unternehmen, Unternehmen, in denen wir als Data Scientists arbeiten.
Kommunikationsfähigkeit erlauben uns, unsere technischen Ideen auszudrücken, Konzepte an verschiedene Beamte / nicht-technische Behörden der Firma.
Aufgabe Verwaltung beinhaltet eine angemessene Planung und Verwaltung für die Bereitstellung der Lösung.
Verstehen / Geschäftssinn o Verständnis für die Branche, in der wir tätig sind, ist sehr wichtig für verschiedene Analysen und effektive Lösungen für die Probleme in diesen Branchen.





