Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Datenbereinigung ist der Prozess der Datenanalyse, um falsche Werte zu finden, beschädigt und fehlen und entfernen Sie sie, um sie für die Eingabe in die Datenanalyse und verschiedene maschinelle Lernalgorithmen geeignet zu machen.
Dies ist der wichtigste und grundlegende Schritt, der durchgeführt wird, bevor eine Analyse der Daten durchgeführt werden kann.. Es gibt keine festgelegten Regeln für die Datenbereinigung. Es hängt ganz von der Qualität des Datensatzes und der zu erreichenden Genauigkeit ab.
Gründe für Datenkorruption:
- Daten werden aus verschiedenen strukturierten und unstrukturierten Quellen gesammelt und dann kombiniert, führt zu doppelten und falsch gekennzeichneten Werten.
- Verschiedene Data Dictionary-Definitionen für Daten, die an mehreren Orten gespeichert sind.
- Fehler bei manueller Eingabe / Schreibfehler.
- Falsche Groß-/Kleinschreibung.
- Kategorie: / falsch gekennzeichnete Klassen.
Datenqualität
Datenqualität ist für die Analyse von größter Bedeutung. Es gibt mehrere Qualitätskriterien, die überprüft werden müssen:

Datenqualitätsattribute

- Ich vervollständige es: Definiert als Prozentsatz der Einträge, die im Datensatz abgeschlossen sind. Der Prozentsatz fehlender Werte im Datensatz ist ein guter Indikator für die Qualität des Datensatzes..
- Präzision: Es ist definiert als das Ausmaß, in dem die Eingaben im Datensatz nahe an ihren tatsächlichen Werten liegen.
- Gleichmäßigkeit: Definiert als das Ausmaß, in dem Daten mit derselben Maßeinheit angegeben werden.
- Konsistenz: Es ist definiert als das Ausmaß, in dem Daten innerhalb desselben Datensatzes und über mehrere Datensätze hinweg konsistent sind.
- Gültigkeit: Es ist definiert als das Ausmaß, in dem die Daten den Beschränkungen entsprechen, die von Geschäftsregeln angewendet werden. Es gibt mehrere Einschränkungen:

Datenprofilbericht
Datenprofilierung ist der Prozess, unsere Daten zu untersuchen und Informationen daraus zu finden. Pandas Profiling Report ist der schnellste Weg, um umfassende Informationen über Ihren Datensatz zu extrahieren. Der erste Schritt zur Datenbereinigung ist die Durchführung einer explorativen Datenanalyse.
So verwenden Sie Pandas-Profiling:
Paso 1: Der erste Schritt besteht darin, das Pandas-Profiling-Paket mit dem Befehl pip zu installieren:
pip install pandas-profilingPaso 2: Laden Sie den Datensatz mit Pandas:
import pandas as pddf = pd.read_csv(r"C:UsersDellDesktopDatasethousing.csv")
Paso 3: Lesen Sie die ersten fünf Zeilen:
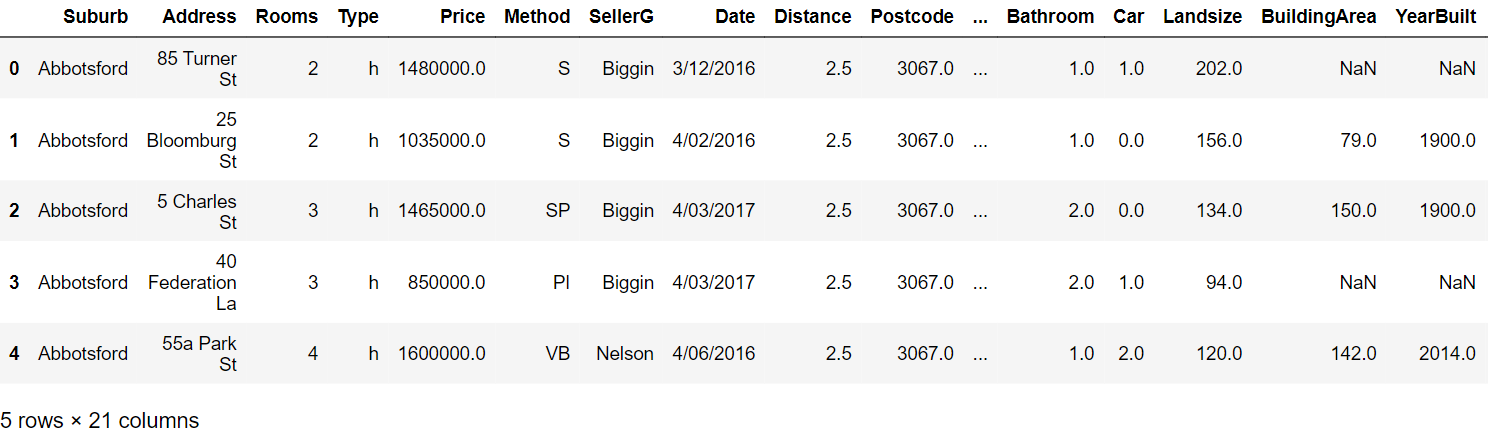
Paso 4: Erstellen Sie den Profiling-Bericht mit den folgenden Befehlen:
from pandas_profiling Profilbericht importierenprof = ProfileReport(df)prof.to_file(output_file="output.html")
Profiling-Bericht:
Der Profiling-Bericht besteht aus fünf Teilen: allgemeine Beschreibung, Variablen, Interaktionen, Korrelation und fehlende Werte.
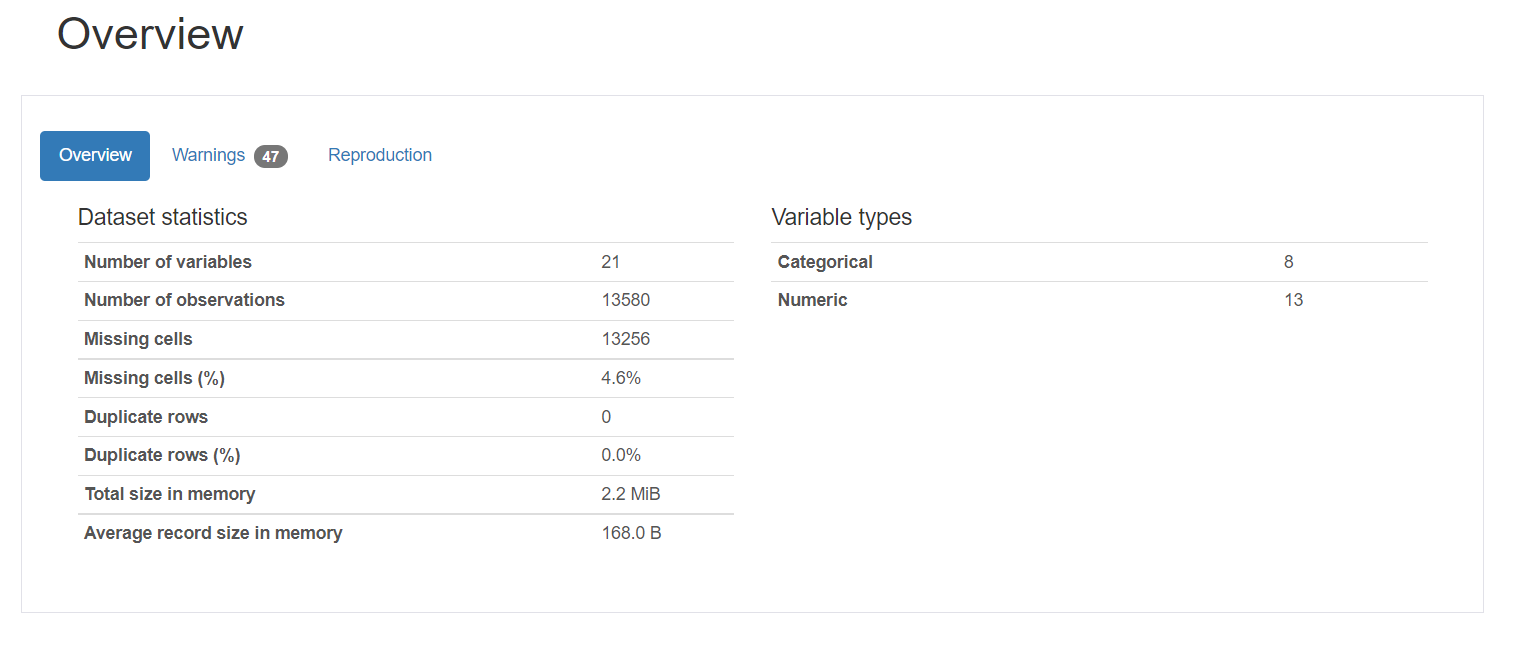
1. Übersicht bietet allgemeine Statistiken zur Anzahl der Variablen, die Anzahl der Beobachtungen, die fehlenden Werte, Duplikate und die Anzahl der kategorialen und numerischen Variablen.
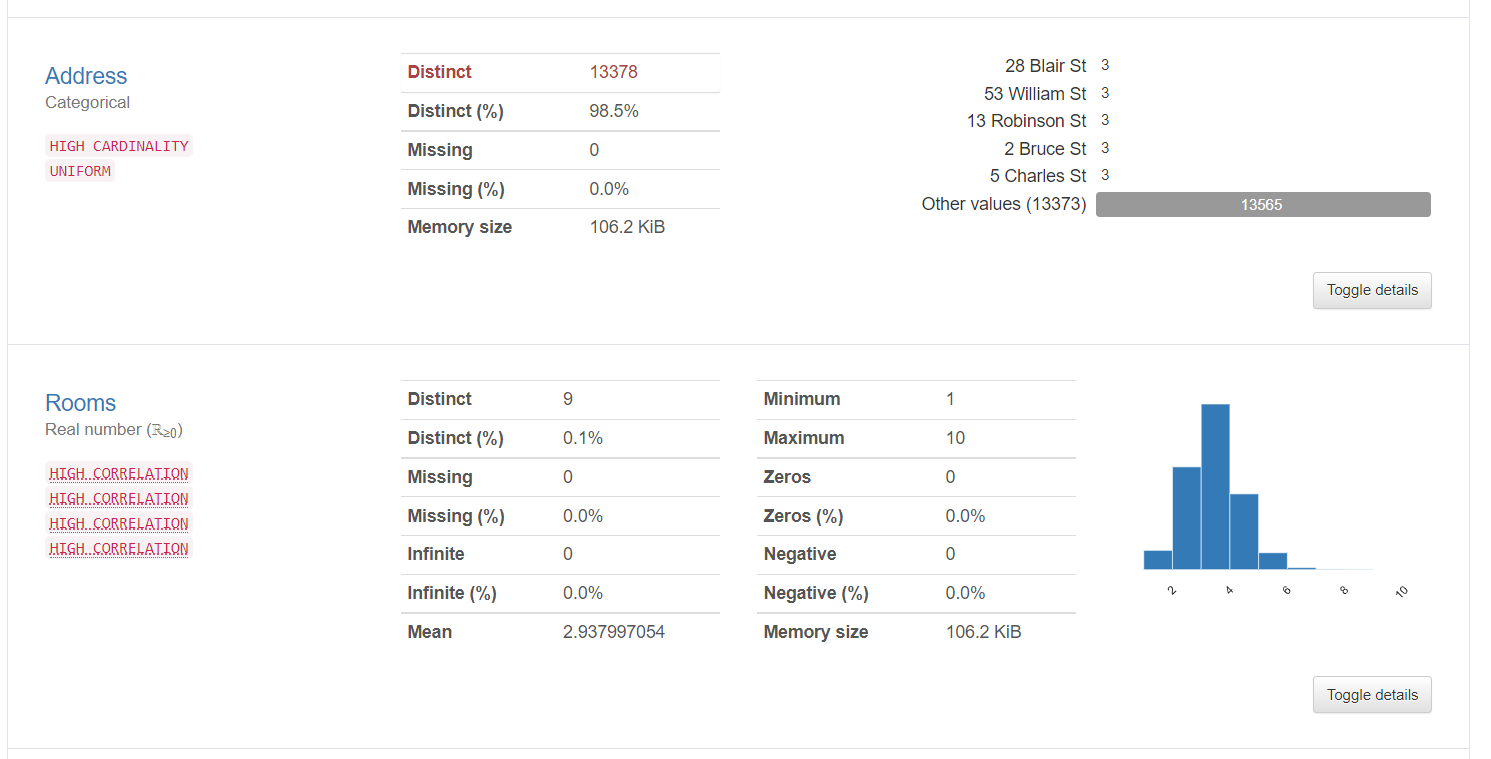
2. Variableninformationen liefern detaillierte Informationen zu eindeutigen Werten, die fehlenden Werte, Durchschnitt, der Median, etc. Hier sind die Statistiken über eine kategoriale Variable und eine numerische Variable:
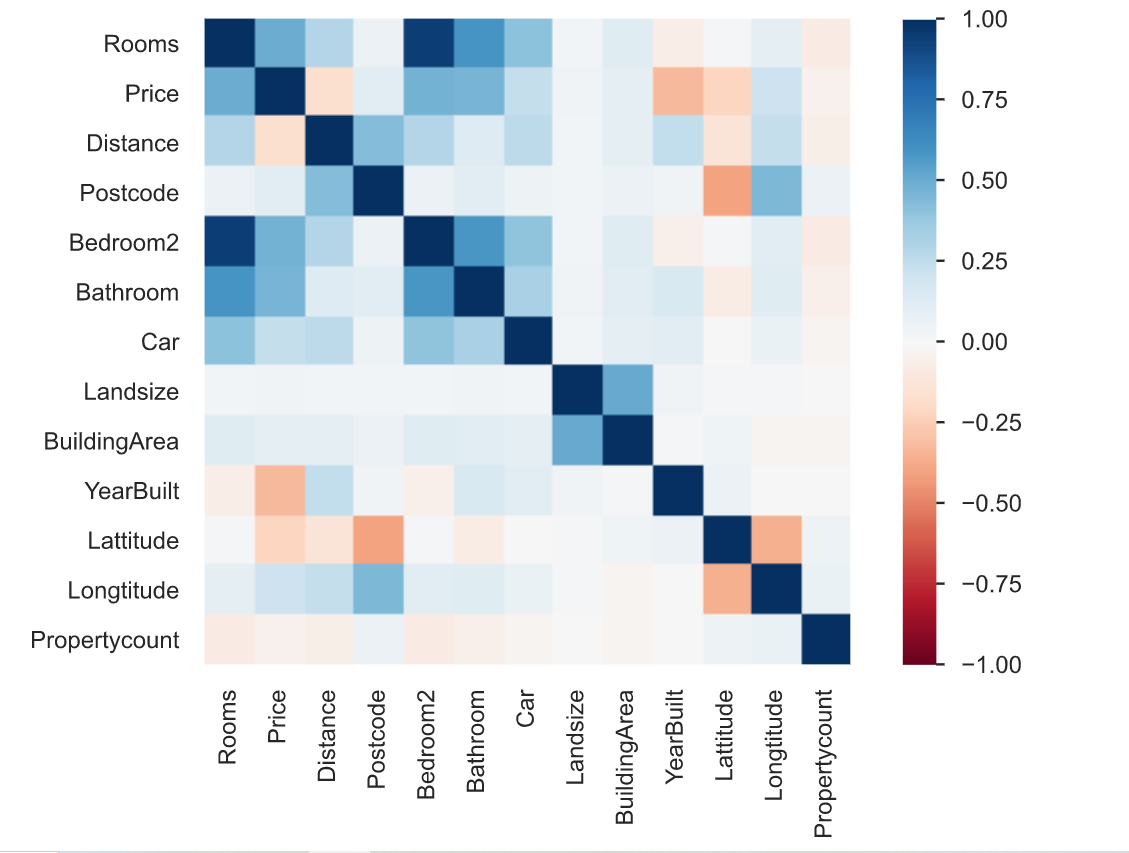
3. Korrelation ist definiert als der Grad, in dem zwei Variablen miteinander in Beziehung stehen. Der Profiling-Report beschreibt die Korrelation verschiedener Variablen untereinander in Form einer Heatmap.
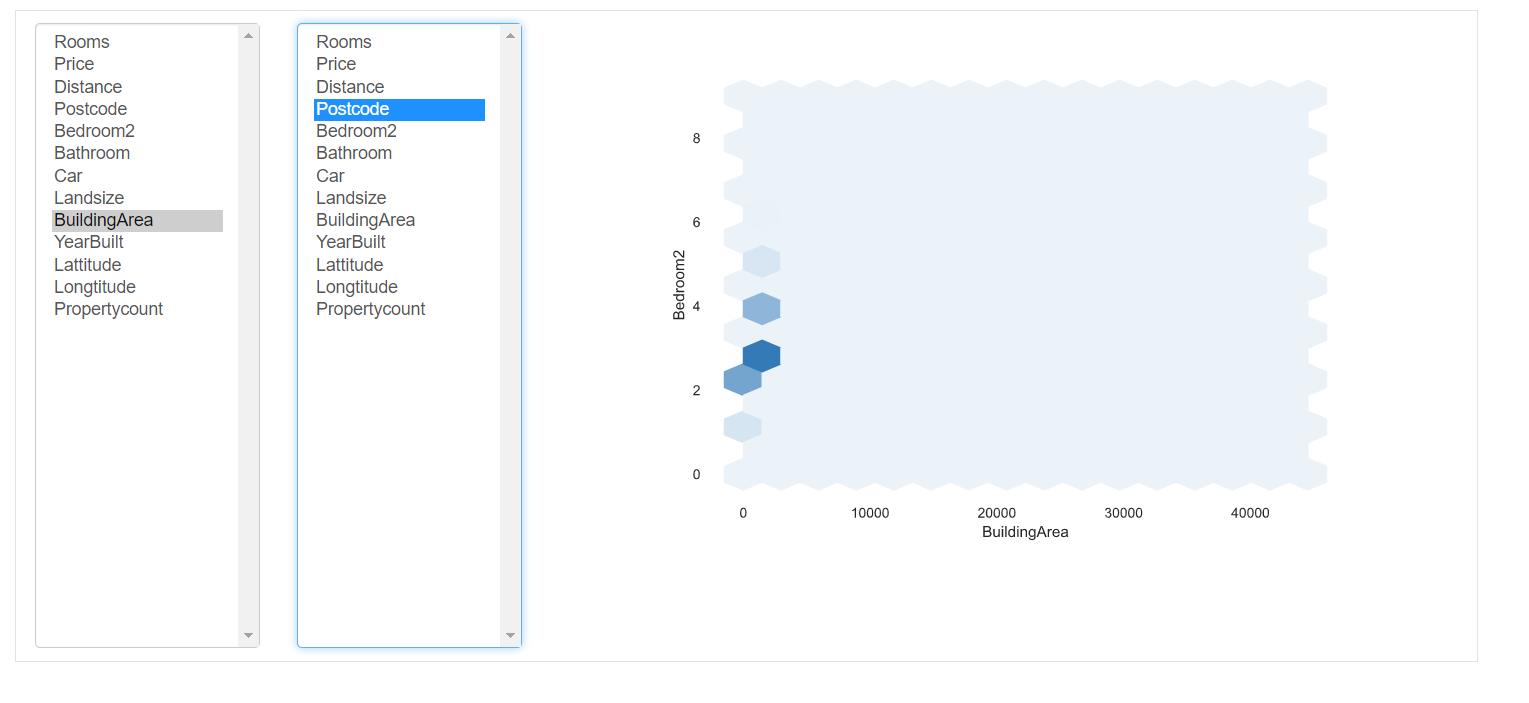
Interaktionen: Dieser Teil des Berichts zeigt die Wechselwirkungen der Variablen untereinander. Sie können jede Variable auf den jeweiligen Achsen auswählen.
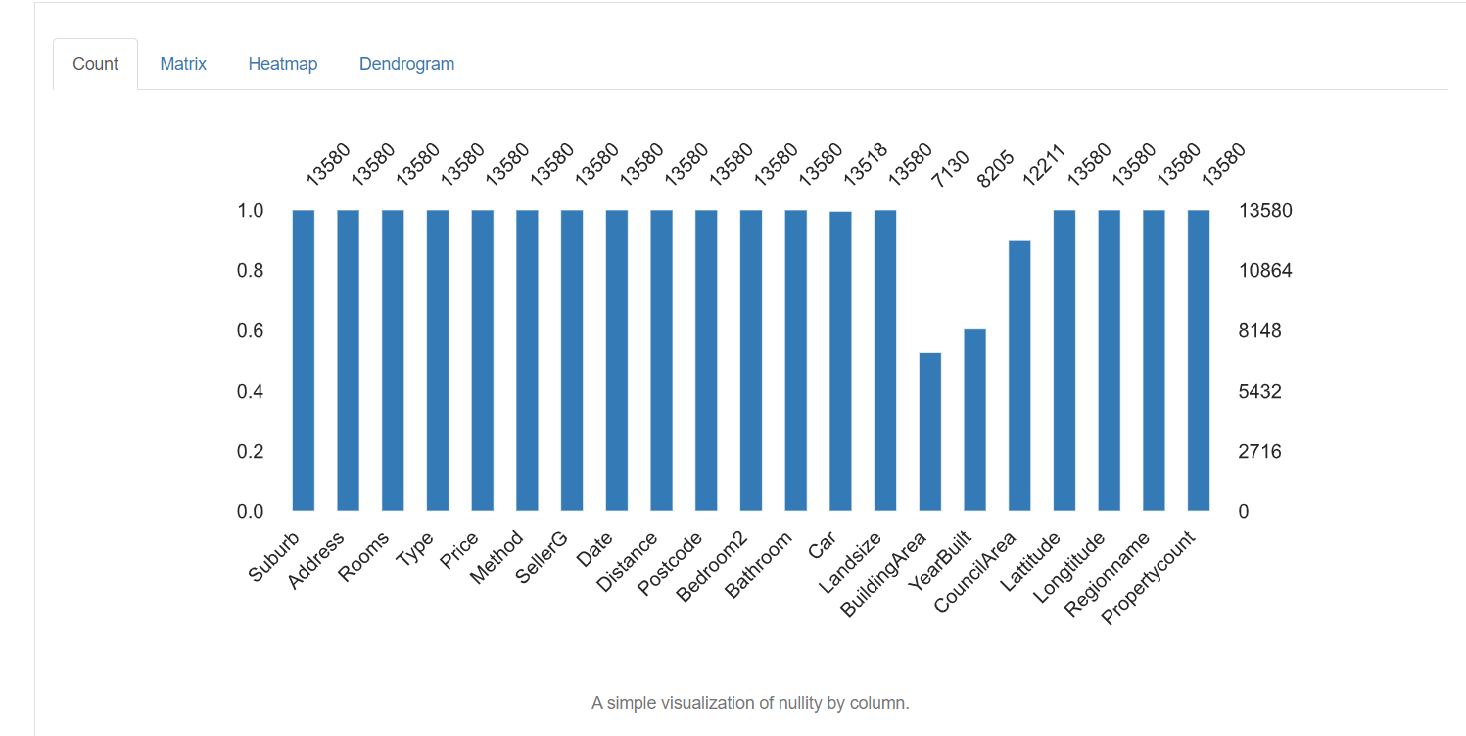
5. Fehlende Werte: stellt die Anzahl der fehlenden Werte in jeder Spalte dar.
Techniken zur Datenbereinigung
Jetzt haben wir detailliertes Wissen über die fehlenden Daten, falsche Werte und falsch gekennzeichnete Kategorien im Datensatz. Jetzt werden wir einige der Techniken sehen, die zum Bereinigen von Daten verwendet werden. Es hängt ganz von der Qualität des Datensatzes ab, die Ergebnisse aus Ihrem Umgang mit Ihren Daten. Einige der Techniken sind wie folgt:
Umgang mit fehlenden Werten:
Der Umgang mit fehlenden Werten ist der wichtigste Schritt bei der Datenbereinigung. Die erste Frage, die Sie sich stellen sollten, ist, warum fehlen die Daten?? Fehlt nur, weil der Dateneingabeoperator es nicht aufgezeichnet hat oder es absichtlich leer gelassen wurde? Sie können auch die Dokumentation überprüfen, um den Grund dafür zu finden.
Es gibt verschiedene Möglichkeiten, mit diesen fehlenden Werten umzugehen:
1. Eliminieren Sie fehlende Werte: Der einfachste Weg, sie zu handhaben, besteht darin, einfach alle Zeilen zu entfernen, die fehlende Werte enthalten. Wenn Sie nicht herausfinden möchten, warum die Werte fehlen und Sie nur einen kleinen Prozentsatz an fehlenden Werten haben, Sie können sie mit dem folgenden Befehl entfernen:
Aber trotzdem, es ist nicht ratsam, da alle Daten wichtig sind und große Bedeutung für das Gesamtergebnis haben. Wie gewöhnlich, der Prozentsatz der fehlenden Einträge in einer bestimmten Spalte ist hoch. Aufhören ist also keine gute Option.
2. Zurechnung: Imputation ist der Prozess des Ersetzens von Nullwerten / für einen gewissen Wert verloren. Für numerische Spalten, Eine Möglichkeit besteht darin, jeden fehlenden Eintrag in der Spalte entweder durch den Mittelwert oder den Medianwert zu ersetzen. Eine andere Möglichkeit könnte darin bestehen, Zufallszahlen zwischen einem Bereich geeigneter Werte für die Spalte zu generieren. Der Bereich könnte zwischen dem Mittelwert und der Standardabweichung der Spalte liegen. Sie können einfach einen Imputer aus dem scikit-learn-Paket importieren und die Imputation wie folgt durchführen:
from sklearn.impute import SimpleImputer
#Imputation
my_imputer = SimpleImputer()
imputed_df = pd.DataFrame(my_imputer.fit_transform(df))Umgang mit Duplikaten:
Doppelte Zeilen treten im Allgemeinen auf, wenn Daten aus mehreren Quellen kombiniert werden. Manchmal repliziert es sich. Ein häufiges Problem ist, wenn Benutzer dieselbe ID-Nummer haben oder das Formular zweimal gesendet wurde.
Die Lösung für diese doppelten Tupel besteht darin, sie einfach zu entfernen. Sie können die einzigartige Funktion verwenden () um die in der Spalte vorhandenen eindeutigen Werte herauszufinden und dann zu entscheiden, welche Werte entfernt werden müssen.
Codierung:
Die Zeichencodierung ist definiert als der Satz von Regeln, der für die Eins-zu-Eins-Zuordnung von rohen binären Byte-Strings in für Menschen lesbare Text-Strings definiert ist. Verschiedene Kodierungen sind verfügbar: ASCII, utf-8, US-ASCII, utf-16, utf-32, etc.
Möglicherweise stellen Sie fest, dass einige der Textzeichenfelder unregelmäßige und nicht erkennbare Muster aufweisen. Dies liegt daran, dass utf-8 die Standard-Python-Codierung ist. Der gesamte Code ist in utf-8. Deswegen, wenn Daten aus mehreren strukturierten und unstrukturierten Quellen stammen und an einem gemeinsamen Ort aufbewahrt werden, unregelmäßige Muster werden im Text beobachtet.
Die Lösung des obigen Problems besteht darin, zunächst die Zeichenkodierung der Datei mit Hilfe des chardet-Moduls in Python wie folgt herauszufinden:
import chardetwith open("C:/Users/Desktop/Dataset/housing.csv",'rb') as rawdata:result = chardet.detect(rawdata.read(10000))# check what the character encoding might beprint(result)
Nachdem Sie den Kodierungstyp gefunden haben, falls abweichend von utf-8, Speichern Sie die Datei mit Kodierung “utf-8” mit dem folgenden Befehl.
df.to_csv("C:/Users/Desktop/Dataset/housing.csv")Skalierung und Normalisierung
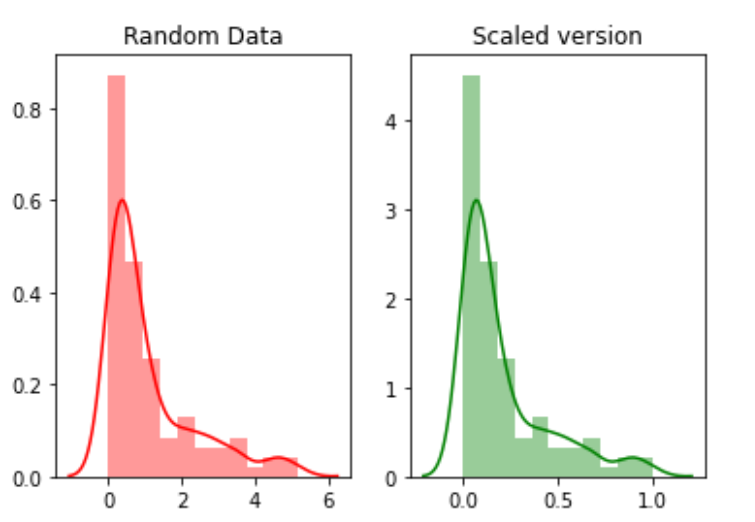
Skalierung bezieht sich auf das Transformieren des Datenbereichs und das Ändern in einen anderen Wertebereich. Dies ist von Vorteil, wenn wir verschiedene Attribute auf derselben Basis vergleichen möchten.. Ein nützliches Beispiel könnte die Währungsumrechnung sein.
Zum Beispiel, wir werden schaffen 100 zufällige Punkte aus einer Exponentialverteilung und dann werden wir sie darstellen. Schließlich, wir werden sie mit dem python mlxtend-Paket in eine skalierte Version konvertieren.
# for min_max scalingfrom mlxtend.preprocessing import minmax_scaling# plotting packagesimport seaborn as snsimport matplotlib.pyplot as plt
Jetzt die Werte skalieren:
random_data = np.random.exponential(size=100)# mix-max scale the data between 0 and 1scaled_version = minmax_scaling(random_data, columns=[0])
Schließlich, Plotten der beiden Versionen.
Die Normalisierung bezieht sich auf die Änderung der Verteilung der Daten, sodass sie eine Glockenkurve darstellen kann, bei der die Attributwerte im Mittel gleichmäßig verteilt sind. Der Wert von Mittelwert und Median ist gleich. Diese Art der Verteilung wird auch als Gaußsche Verteilung bezeichnet.. Dies ist für maschinelle Lernalgorithmen erforderlich, die davon ausgehen, dass die Daten normalverteilt sind.
Jetzt, Wir werden die Daten mit der Boxcox-Funktion normalisieren:
from scipy import statsnormalized_data = stats.boxcox(random_data)# plot both together to comparefig,ax=plt.subplots(1,2)sns.distplot(random_data, ax=ax[0],color="pink")ax[0].set_title("Random Data")sns.distplot(normalized_data[0], ax=ax[1],color="purple")ax[1].set_title("Normalized data")
Datumsbehandlung
Das Datumsfeld ist ein wichtiges Attribut, das während der Datenbereinigung behandelt werden muss. Es gibt verschiedene Formate, in denen Daten in den Datensatz eingegeben werden können. Deswegen, Die Standardisierung der Datumsspalte ist eine kritische Aufgabe. Einige Leute haben das Datum möglicherweise als Zeichenfolgenspalte behandelt, andere als DateTime-Spalte. Wenn der Datensatz aus verschiedenen Quellen kombiniert wird, Dies kann zu einem Analyseproblem führen.
Die Lösung besteht darin, zuerst den Datumsspaltentyp mit dem folgenden Befehl zu finden.
df['Datum'].dtyp
Wenn sich der Spaltentyp von DateTime unterscheidet, konvertieren Sie es in DateTime mit dem folgenden Befehl:
import datetimedf['Date_parsed'] = pd.to_datetime(df['Date'], format="%m/%d/%y")
Umgang mit inkonsistenten Dateneingabeproblemen
Es gibt eine Vielzahl von inkonsistenten Einträgen, die weder manuell noch durch direkte Berechnungen gefunden werden können. Zum Beispiel, ob der gleiche Eintrag in Groß- oder Kleinschreibung oder in einer Mischung aus Groß- und Kleinschreibung geschrieben wird. Dann, dieser Eintrag sollte über die gesamte Spalte vereinheitlicht werden.
Eine Lösung besteht darin, alle Einträge in einer Spalte in Kleinbuchstaben umzuwandeln und den zusätzlichen Platz von jedem Eintrag zu entfernen. Dies kann später nach Abschluss der Analyse rückgängig gemacht werden.
# convert to lower casedf['ReginonName'] = df['ReginonName'].str.lower()# remove trailing white spacesdf['ReginonName'] = df['ReginonName'].str.strip()
Eine andere Lösung besteht darin, Fuzzy-Matching zu verwenden, um herauszufinden, welche Zeichenfolgen in der Spalte am nächsten beieinander liegen, und dann alle diese Einträge mit einem bestimmten Schwellenwert durch den führenden Eintrag zu ersetzen.
Zuerst, Wir werden die einzigartigen Namen der Regionen entdecken:
region = df['Regionname'].unique()Dann berechnen wir die Scores mit der ungefähren Übereinstimmung:
import fuzzywuzzyfromfuzzywuzzy import processregions=fuzzywuzzy.process.extract("WesternVictoria",region,limit=10,scorer=fuzzywuzy.fuzz.token_sort_ratio)

Validierung des Prozesses.
Sobald der Datenbereinigungsprozess abgeschlossen ist, Es ist wichtig zu überprüfen und zu validieren, dass die von Ihnen vorgenommenen Änderungen die Einschränkungen des Datensatzes nicht behindert haben.
Und schlussendlich, … Keine Notwendigkeit zu sagen,
Danke fürs Lesen!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





