Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
Die Datenvisualisierung in Python ist heute vielleicht eine der am häufigsten verwendeten Funktionen für Data Science mit Python. Bibliotheken in Python verfügen über viele verschiedene Funktionen, mit denen Benutzer hochgradig benutzerdefinierte Grafiken erstellen können, elegant und interaktiv.
In diesem Artikel, Wir werden die Verwendung von Matplotlib behandeln, Seaborn, sowie eine Einführung in andere alternative Pakete, die in der Python-Visualisierung verwendet werden können.
In Matplotlib und Seaborn, Wir werden einige der am häufigsten verwendeten Diagramme in der Data Science-Welt behandeln, um eine einfache Visualisierung zu ermöglichen.
Später im Artikel, Wir werden eine weitere leistungsstarke Funktion in Python-Visualisierungen durchgehen, la subtrama, und wir haben ein grundlegendes Tutorial zum Erstellen von Subplots behandelt.
Nützliche Pakete für Visualisierungen in Python
Matplotlib
Matplotlib ist eine Python-Anzeigebibliothek für 2D-Array-Diagramme. Matplotlib ist in Python geschrieben und verwendet die NumPy-Bibliothek. Kann in Python- und IPython-Shells verwendet werden, Jupyter-Laptops und Webanwendungsserver. Matplotlib enthält eine Vielzahl von Diagrammen wie line, Bar, Dispersion, Histogramm, etc. die uns helfen können, unser Verständnis von Trends zu vertiefen, Muster und Zusammenhänge. Es wurde von John Hunter in . eingeführt 2002.
Seaborn
Seaborn ist eine datensatzorientierte Bibliothek zur Durchführung statistischer Darstellungen in Python. Es wird auf Matplotlib entwickelt und um verschiedene Visualisierungen zu erstellen. Es ist in Pandas-Datenstrukturen integriert. Die Bibliothek führt das Mapping und die Aggregation intern durch, um informative Visuals zu erstellen. Es wird empfohlen, eine Jupyter-Schnittstelle zu verwenden / IPython und modo matplotlib.
Bokeh
Bokeh ist eine interaktive Displaybibliothek für moderne Webbrowser. Es eignet sich für Streaming oder große Datenbestände und kann zur Entwicklung interaktiver Diagramme und Dashboards verwendet werden. Die Bibliothek bietet eine Vielzahl intuitiver Grafiken, die zur Entwicklung von Lösungen genutzt werden können. Arbeitet eng mit PyData-Tools zusammen. Die Bibliothek eignet sich zum Erstellen benutzerdefinierter Images gemäß den erforderlichen Anwendungsfällen. Bilder können auch interaktiv gemacht werden, um als hypothetisches Szenariomodell zu dienen. Der gesamte Code ist Open Source und auf GitHub verfügbar.
Altair
Altair ist eine deklarative statistische Anzeigebibliothek für Python. Altair API ist einfach zu bedienen und konsistent, und basiert auf der Vega-Lite JSON-Spezifikation. Die deklarative Bibliothek gibt an, dass beim Erstellen eines visuellen Objekts, wir müssen die Verknüpfungen zwischen den Datenspalten und den Kanälen definieren (X-Achse, Achse y, Größe, Farbe). Mit Hilfe von Altair, informative Bilder können mit minimalem Code erstellt werden. Altair hat eine deklarative Grammatik sowohl der Visualisierung als auch der Interaktion.
Tramadamente
plotly.py ist eine interaktive Display-Bibliothek, Open Source, hohes Level, deklarativ und browserbasiert für Python. Enthält eine Vielzahl nützlicher Visualisierungen, einschließlich wissenschaftlicher Diagramme, 3D-Grafik, statistische Grafiken, Finanzdiagramme, unter anderen. Plotgrafiken können in Jupyter-Notebooks angezeigt werden, eigenständige HTML-Dateien oder online gehostet. Die Plotly-Bibliothek bietet Möglichkeiten zur Interaktion und Bearbeitung. Die robuste API funktioniert perfekt im Web- und lokalen Browsermodus.
ggplot
ggplot ist eine Python-Implementierung der grafischen Grammatik. Grafikgrammatik bezieht sich auf die Zuordnung von Daten zu ästhetischen Attributen (Farbe, gestalten, Größe) und geometrische Objekte (Punkte, Linien, Riegel). Die Grundbausteine der Graphengrammatik sind Daten, geom (geometrische Objekte), Statistiken (statistische Transformationen), Skala, Koordinatensystem und Facette.
Die Verwendung von ggplot in Python ermöglicht es Ihnen, inkrementelle informative Visualisierungen zu entwickeln, zuerst die Nuancen der Daten verstehen und dann die Komponenten anpassen, um die visuellen Darstellungen zu verbessern.
So verwenden Sie die richtige Visualisierung?
Um die erforderlichen Informationen aus den verschiedenen visuellen Elementen zu extrahieren, die wir erstellen, Es ist wichtig, dass wir die richtige Darstellung basierend auf der Art der Daten und den Fragen verwenden, die wir zu verstehen versuchen. Dann, Wir werden uns eine Reihe der am häufigsten verwendeten Darstellungen ansehen und wie wir sie am effektivsten verwenden können.
Balkengrafik
Ein Balkendiagramm wird verwendet, wenn wir Metrikwerte in verschiedenen Untergruppen von Daten vergleichen möchten. Wenn wir eine größere Anzahl von Gruppen haben, ein Balkendiagramm wird einem Säulendiagramm vorgezogen.
Balkendiagramm mit Matplotlib
#Erstellen des Datensatzes
df = sns.load_dataset('titanisch')
df=df.groupby('Wer')['Fahrpreis'].Summe().einrahmen().reset_index()
#Erstellen des Balkendiagramms
plt.barh(df['Wer'],df['Fahrpreis'],Farbe = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Balkendiagramm mit Seaborn
#Balkendiagramm erstellen
sns.barplot(x = 'Fahrpreis',j = 'wer',data = titanic_dataset,Palette = "Blues")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Säulendiagramm
Säulendiagramme werden hauptsächlich verwendet, wenn wir eine einzelne Datenkategorie zwischen einzelnen Unterelementen vergleichen müssen, zum Beispiel, beim Vergleich des Einkommens zwischen den Regionen.
Säulendiagramm mit Matplotlib
#Erstellen des Datensatzes
df = sns.load_dataset('titanisch')
df=df.groupby('Wer')['Fahrpreis'].Summe().einrahmen().reset_index()
#Erstellen des Säulendiagramms
plt.bar(df['Wer'],df['Fahrpreis'],Farbe = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Säulendiagramm mit Seaborn
#Auslesen des Datensatzes
titanic_dataset = sns.load_dataset('titanisch')
#Säulendiagramm erstellen
sns.barplot(x = 'wer',j = 'tun',data = titanic_dataset,Palette = "Blues")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Gruppiertes Balkendiagramm
Ein geclustertes Balkendiagramm wird verwendet, wenn wir die Werte in bestimmten Gruppen und Untergruppen vergleichen möchten.
Gruppiertes Balkendiagramm mit Matplotlib
#Erstellen des Datensatzes
df = sns.load_dataset('titanisch')
df_pivot = pd.pivot_table(df, Werte="Fahrpreis",index="Wer",Spalten="Klasse", aggfunc=np.mean)
#Erstellen eines gruppierten Balkendiagramms
ax = df_pivot.plot(Art="Bar",Alpha=0,5)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
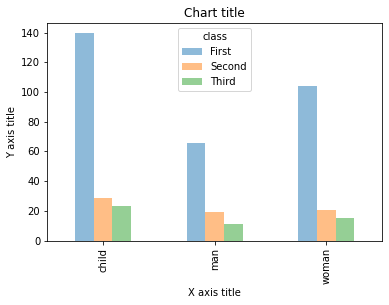
Balkendiagramm gruppiert mit Seaborn
#Auslesen des Datensatzes
titanic_dataset = sns.load_dataset('titanisch')
#Erstellen des nach Klassen gruppierten Balkendiagramms
sns.barplot(x = 'wer',j = 'tun',Farbton="Klasse",data = titanic_dataset, Palette = "Blues")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
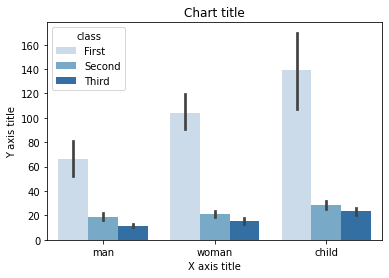
Gestapeltes Balkendiagramm
Ein gestapeltes Balkendiagramm wird verwendet, wenn wir die Gesamtgröße der verfügbaren Gruppen und die Zusammensetzung der verschiedenen Untergruppen vergleichen möchten.
Gestapeltes Balkendiagramm mit Matplotlib
# Gestapeltes Balkendiagramm
#Erstellen des Datensatzes
df = pd.DataFrame(Spalten=["EIN","B", "C","D"],
Daten=[["E",0,1,1],
["F",1,1,0],
["g",0,1,0]])
df.plot.bar(x='A', y =["B", "C","D"], gestapelt=Wahr, Breite = 0,4, Alpha = 0,5)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
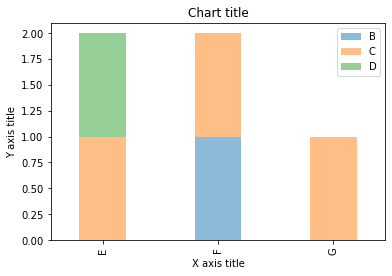
Gestapeltes Balkendiagramm mit Seaborn
dataframe = pd.DataFrame(Spalten=["EIN","B", "C","D"],
Daten=[["E",0,1,1],
["F",1,1,0],
["g",0,1,0]])
dataframe.set_index('EIN').T.plot(kind='bar', gestapelt=Wahr)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
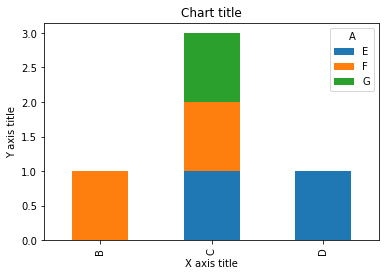
Liniendiagramm
Ein Liniendiagramm wird verwendet, um kontinuierliche Datenpunkte darzustellen. Dieses visuelle Element kann effektiv verwendet werden, wenn wir den Trend im Laufe der Zeit verstehen möchten..
Liniendiagramm mit Matplotlib
#Erstellen des Datensatzes
df = sns.load_dataset("Iris")
df=df.groupby('Sepal_Länge')['sepal_width'].Summe().einrahmen().reset_index()
#Erstellen des Liniendiagramms
plt.plot(df['Sepal_Länge'], df['sepal_width'])
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Linienkarte mit Seaborn
#Erstellen des Datensatzes
Autos = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
Daten = [20, 15, 15, 14, 16, 20]
#Tortendiagramm erstellen
plt.pie(Daten, Etiketten = Autos,Farben = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
#Zeig die Handlung
plt.zeigen()
Kuchendiagramm
Kreisdiagramme können verwendet werden, um die Anteile der verschiedenen Komponenten in einem bestimmten Ganzen zu identifizieren..
Kreisdiagramm mit Matplotlib
#Erstellen des Datensatzes
Autos = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
Daten = [20, 15, 15, 14, 16, 20]
#Tortendiagramm erstellen
plt.pie(Daten, Etiketten = Autos,Farben = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
#Zeig die Handlung
plt.zeigen()
Flächendiagramm
Flächendiagramme werden verwendet, um Änderungen im Laufe der Zeit für eine oder mehrere Gruppen zu verfolgen. Flächendiagramme werden gegenüber Liniendiagrammen bevorzugt, wenn wir Veränderungen im Laufe der Zeit für mehr als eine Gruppe erfassen möchten.
Flächendiagramm mit Matplotlib
#Auslesen des Datensatzes
x=Bereich(1,6)
y =[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ]
#Erstellen des Flächendiagramms
ax = plt.gca()
ax.stackplot(x, Ja, Etiketten=['EIN','B','C'],Alpha=0,5)
#Ästhetik hinzufügen
plt.legende(loc ="Oben links")
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Flächendiagramm mit Seaborn
# Daten
Jahre_der_Erfahrung =[1,2,3]
Gehalt=[ [6,8,10], [4,5,9], [3,5,7] ]
# Parzelle
plt.stackplot(langjährige Erfahrung,Gehalt, Etiketten=['Unternehmen A','Unternehmen B','Unternehmen C'])
plt.legende(loc ="Oben links")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Spaltenhistogramm
Spaltenhistogramme werden verwendet, um die Verteilung einer einzelnen Variablen mit wenigen Datenpunkten zu beobachten.
Säulendiagramm mit Matplotlib
#Erstellen des Datensatzes
Pinguine = sns.load_dataset("Pinguine")
#Erstellen des Spaltenhistogramms
ax = plt.gca()
ax.hist(Pinguine['flipper_length_mm'], Farbe="Blau",Alpha=0,5, Behälter=10)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
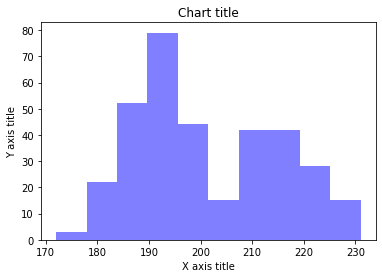
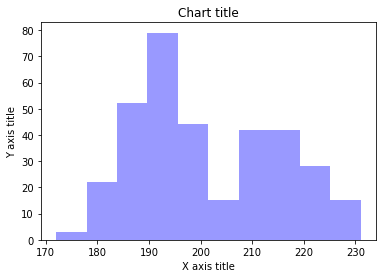
Säulendiagramm mit Seaborn
#Auslesen des Datensatzes
pinguins_dataframe = sns.load_dataset("Pinguine")
#Balkenhistogramm zeichnen
sns.distplot(pinguins_dataframe['flipper_length_mm'], kde = Falsch, Farbe="Blau", Behälter=10)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
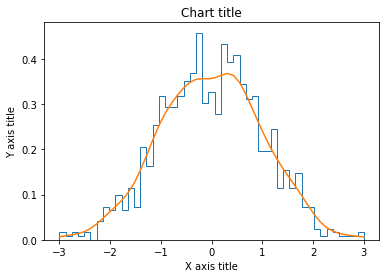
Linienhistogramm
Linienhistogramme werden verwendet, um die Verteilung einer einzelnen Variablen mit vielen Datenpunkten zu beobachten.
Linien-Histogramm-Plot mit Matplotlib
#Erstellen des Datensatzes
df_1 = np.zufällig.normal(0, 1, (1000, ))
Dichte = stats.gaussian_kde(df_1)
#Erstellen des Linienhistogramms
n, x, _ = plt.hist(df_1, bins=np.linspace(-3, 3, 50), histtype=u'Schritt', Dichte=Wahr)
plt.plot(x, Dichte(x))
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
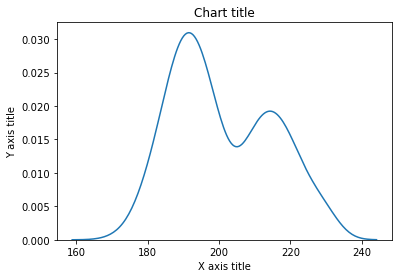
Linien-Histogramm-Diagramm mit Seaborn
#Auslesen des Datensatzes
pinguins_dataframe = sns.load_dataset("Pinguine")
#Linienhistogramm zeichnen
sns.distplot(pinguins_dataframe['flipper_length_mm'], hist = Falsch, wobei = wahr, Etikett="Afrika")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Streudiagramm
Streudiagramme können verwendet werden, um Beziehungen zwischen zwei Variablen zu identifizieren. Kann unter Umständen effektiv verwendet werden, in denen die abhängige Variable mehrere Werte für die unabhängige Variable haben kann.
Streudiagramm mit Matplotlib
#Erstellen des Datensatzes
df = sns.load_dataset("Tipps")
#Erstellen des Streudiagramms
plt.streuung(df['gesamte Rechnung'],df['Spitze'],Alpha=0,5 )
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Streudiagramm mit Seaborn
#Auslesen des Datensatzes
bill_dataframe = sns.load_dataset("Tipps")
#Streudiagramm erstellen
sns.streudiagramm(data=bill_dataframe, x="gesamte Rechnung", y ="Spitze")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Blasendiagramm
Streudiagramme können verwendet werden, um Beziehungen zwischen drei Variablen darzustellen und darzustellen.
Blasendiagramm mit Matplotlib
#Erstellen des Datensatzes
np.random.seed(42)
N = 100
x = np.zufällig.normal(170, 20, n)
y = x + np.zufällig.normal(5, 25, n)
Farben = np.random.rand(n)
Bereich = (25 * np.random.rand(n))**2
df = pd.DataFrame({
'X': x,
'UND': Ja,
'Farben': Farben,
"Blasengröße":Bereich})
#Erstellen des Blasendiagramms
plt.streuung('X', 'UND', s="Blasengröße",Alpha=0,5, Daten=df)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
Blasendiagramm mit Seaborn
#Auslesen des Datensatzes
bill_dataframe = sns.load_dataset("Tipps")
#Blasendiagramm erstellen
sns.streudiagramm(data=bill_dataframe, x="gesamte Rechnung", y ="Spitze", Farbton="Größe", Größe="Größe")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Box-Plot
Ein Boxplot wird verwendet, um die Form der Verteilung zu zeigen, sein zentraler Wert und seine Variabilität.
Boxplot mit Matplotlib
aus past.builtins importieren xrange
#Erstellen des Datensatzes
df_1 = [[1,2,5], [5,7,2,2,5], [7,2,5]]
df_2 = [[6,4,2], [1,2,5,3,2], [2,3,5,1]]
#Erstellen des Boxplots
Zecken = ['EIN', 'B', 'C']
plt.figur()
bpl = plt.boxplot(df_1, positionen=np.array(xrange(len(df_1)))*2.0-0.4, sym = '', Breiten=0,6)
bpr = plt.boxplot(df_2, positionen=np.array(xrange(len(df_2)))*2.0+0.4, sym = '', Breiten=0,6)
plt.plot([], c="#D7191C", Etikett="Etikett 1")
plt.plot([], c="#2C7BB6", Etikett="Etikett 2")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
plt.legende()
plt.xticks(xrange(0, len(Zecken) * 2, 2), Zecken)
plt.xlim(-2, len(Zecken)*2)
plt.ylim(0, 8)
plt.tight_layout()
#Zeig die Handlung
plt.zeigen()
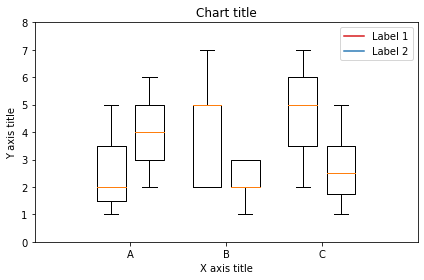
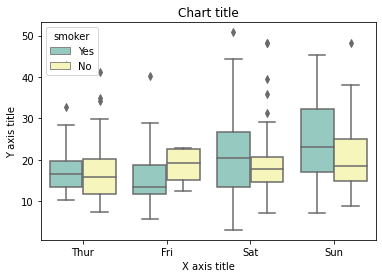
Boxplot mit Seaborn
#Auslesen des Datensatzes
bill_dataframe = sns.load_dataset("Tipps")
#Boxplots erstellen
ax = sns.boxplot(x="Tag", y ="gesamte Rechnung", Farbton="Raucher", data=bill_dataframe, Palette="Set3")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
Wasserfalldiagramm
Ein Wasserfalldiagramm kann verwendet werden, um den allmählichen Übergang des Wertes einer Variablen zu erklären, der zu- oder abnimmt.
#Auslesen des Datensatzes
test = pd.Serie(-1 + 2 * np.random.rand(10), index=liste('abcdefghij'))
#Funktion zum Erstellen eines Wasserfalldiagramms
Def Wasserfall(Serie):
df = pd.DataFrame({'pos':np.maximal(Serie,0),'neg':np.minimum(Serie,0)})
leer = serie.cumsum().Schicht(1).Fillna(0)
df.plot(kind='bar', gestapelt=Wahr, unten = leer, Farbe=['R','B'], Alpha=0,5)
Schritt = blank.reset_index(drop=wahr).wiederholen(3).Schicht(-1)
Schritt[1::3] = np.nan
plt.plot(Schritt.index, Schrittwerte,'k')
#Erstellen des Wasserfalldiagramms
Wasserfall(Prüfung)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
#Zeig die Handlung
plt.zeigen()
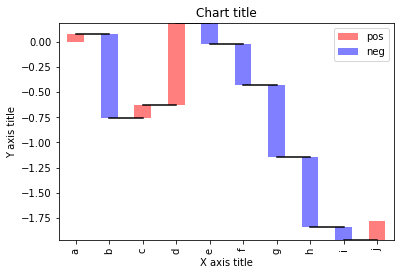
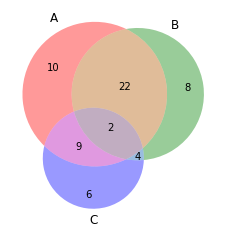
Diagramm von Venn
Venn-Diagramme werden verwendet, um die Beziehungen zwischen zwei oder drei Sätzen von Elementen zu sehen. Heben Sie die Gemeinsamkeiten und Unterschiede hervor
aus matplotlib_venn importieren venn3 #Freundschaftstabelle erstellen Freund3(Teilmengen = (10, 8, 22, 6,9,4,2)) plt.zeigen()
Baumkarte
Treemaps werden hauptsächlich verwendet, um Daten gruppiert und in einer hierarchischen Struktur verschachtelt anzuzeigen und den Beitrag jeder Komponente zu beobachten.
importieren
Größen = [40, 30, 5, 25, 10]
quadrieren.plot(Größen)
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
# Zeig die Handlung
plt.zeigen()
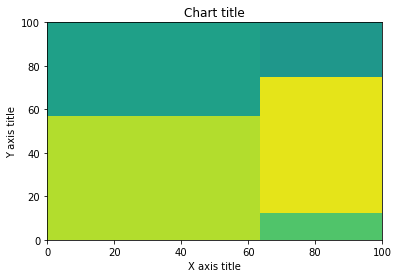
Balkengrafik 100% gestapelt
Sie können ein gestapeltes Balkendiagramm nutzen, indem Sie 100% wenn wir die relativen Unterschiede innerhalb jeder Gruppe für die verschiedenen verfügbaren Untergruppen anzeigen möchten.
#Auslesen des Datensatzes
r = [0,1,2,3,4]
raw_data = {'grüne Balken': [20, 1.5, 7, 10, 5], 'orangeBars': [5, 15, 5, 10, 15],'blaue Balken': [2, 15, 18, 5, 10]}
df = pd.DataFrame(Rohdaten)
# Vom Rohwert zum Prozentsatz
Summen = [i+j+k für i,J,k in zip(df['grüne Balken'], df['orangeBars'], df['blaue Balken'])]
grüne Balken = [ich / J * 100 für ich,j in zip(df['grüne Balken'], Summen)]
orangeBars = [ich / J * 100 für ich,j in zip(df['orangeBars'], Summen)]
blueBars = [ich / J * 100 für ich,j in zip(df['blaue Balken'], Summen)]
# Handlung
barBreite = 0.85
Namen = ('EIN','B','C','D','E')
# Erstellen Sie grüne Balken
plt.bar(R, greenBars, Farbe="#b5ffb9", Kantenfarbe="Weiß", width=barWidth)
# Erstelle orangefarbene Balken
plt.bar(R, orangeBars, unten=grüne Balken, Farbe="#f9bc86", Kantenfarbe="Weiß", width=barWidth)
# Erstellen Sie blaue Balken
plt.bar(R, blueBars, unten=[i+j für i,j in zip(greenBars, orangeBars)], Farbe="#a3acff", Kantenfarbe="Weiß", width=barWidth)
# Benutzerdefinierte x-Achse
plt.xticks(R, Namen)
plt.xlabel("Gruppe")
#Ästhetik hinzufügen
plt.titel('Diagrammtitel')
plt.xlabel('X-Achsentitel')
plt.ylabel('Y-Achsentitel')
plt.zeigen()
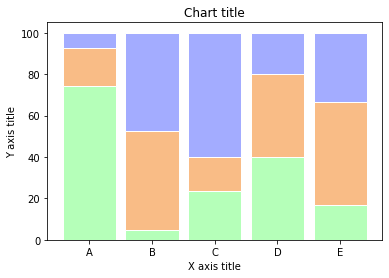
Randplots
Randdiagramme werden verwendet, um die Beziehung zwischen zwei Variablen zu bewerten und ihre Verteilungen zu untersuchen. Solche Streudiagramme mit Histogrammen, Boxplots oder Dotplots an den Rändern der jeweiligen x- und y-Achsen
#Auslesen des Datensatzes
iris_dataframe = sns.load_dataset('Iris')
#Erstellen von Randdiagrammen
sns.jointplot(x=iris_dataframe["sepal_length"], y = iris_dataframe["sepal_width"], kind='streuen')
# Zeig die Handlung
plt.zeigen()
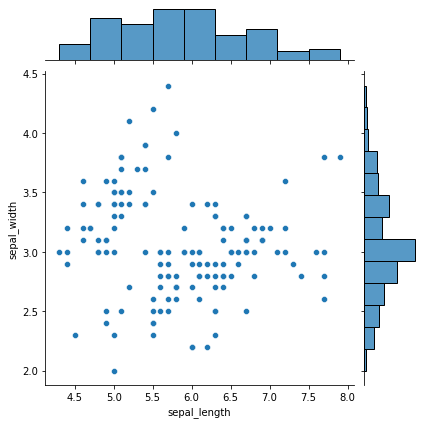
Unterpakete
Subframes sind leistungsstarke Displays, die Vergleiche zwischen Frames erleichtern
#Erstellen des Datensatzes
df = sns.load_dataset("Iris")
df=df.groupby('Sepal_Länge')['sepal_width'].Summe().einrahmen().reset_index()
#Erstellen der Nebenhandlung
Feige, Achsen = plt.subplots(Reihen = 2, ncols = 2)
ax=df.plot('Sepal_Länge', 'sepal_width',Axt=Achsen[0,0])
ax.get_legend().Löschen()
#Ästhetik hinzufügen
ax.set_title('Diagrammtitel')
ax.set_xlabel('X-Achsentitel')
ax.set_ylabel('Y-Achsentitel')
ax=df.plot('Sepal_Länge', 'sepal_width',Axt=Achsen[0,1])
ax.get_legend().Löschen()
ax=df.plot('Sepal_Länge', 'sepal_width',Axt=Achsen[1,0])
ax.get_legend().Löschen()
ax=df.plot('Sepal_Länge', 'sepal_width',Axt=Achsen[1,1])
ax.get_legend().Löschen()
#Zeig die Handlung
plt.zeigen()
Abschließend, Es gibt eine Vielzahl unterschiedlicher Bibliotheken, die ihr volles Potenzial nutzen können, indem sie den Anwendungsfall und die Anforderung verstehen. Syntax und Semantik variieren von Paket zu Paket und es ist wichtig, die Herausforderungen und Vorteile verschiedener Bibliotheken zu verstehen. Viel Spaß beim Anschauen!
Data Scientist und Analytics-Enthusiast
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.





