Überblick
- Hier ist eine Liste der 10 Top-Artikel, die dieses Jahr von DataPeaker veröffentlicht wurden
- Artikel wurden in absteigender Reihenfolge sortiert, basierend auf deiner meinung.
- Fühlen Sie sich frei, weitere Artikel im Kommentarbereich hinzuzufügen, die Ihrer Meinung nach von der Community gelesen werden sollten..
Einführung
Schreiben ist der beste Weg, um die Bindung zu verbessern. Deine Erkenntnisse in eigene Worte umzuwandeln führt nicht nur zu einem besseren Verständnis, es führt auch zu einer angeborenen Beobachtung, was wiederum die Neugier steigert.
Zusammenfassend, Schreiben hebt deinen Lernprozess auf ein unergründliches Niveau.
Schreiben ist der Kern der DataPeaker-Prinzipien. Wir haben immer versucht, den bestmöglichen Inhalt anzubieten und 2020 bei uns war es nicht anders. Mehr als 500 in diesem Jahr veröffentlichte Artikel, die schreibreise hört für uns nie auf.
In diesem Artikel, wir heben die hervor 10 Von der Data Science-Community am häufigsten gelesene Artikel in unserem Blog, dieses Jahr erschienen.
Also lass uns den Ball ins Rollen bringen!
Der Artikel mit der besten Leistung in unserem Blog basiert auf den grundlegendsten Fragen, die Sie einem Datenwissenschaftler oder Datenanalysten in einem Interview stellen.
“Wie viele Data-Science-Projekte haben Sie bisher abgeschlossen?”

Die Antwort macht den Unterschied. Data Science ist kein Feld, in dem theoretisches Verständnis Ihnen den Einstieg erleichtert. Es sind die Projekte, die Sie durchführen und die Praxis, die Sie haben, die Ihre Erfolgswahrscheinlichkeit bestimmen.
Es reicht nicht, einfach nur Kurse zu belegen oder Zertifizierungen zu erhalten. Fast jeder, den wir kennen, ist in verschiedenen Aspekten der Datenwissenschaft zertifiziert. Du wertest deinen Lebenslauf nicht auf, wenn du ihn nicht mit praktischer Erfahrung verbindest.
Aber, Welches Data Science Projekt soll ich wählen? Bei DataPeaker sammeln wir jeden Monat gerne die besten Data Science-Projekte und, In diesem Artikel, Wir haben die besten Open-Source-Data-Science-Projekte für den Monat Juni zusammengestellt 2020.
Sie können es hier überprüfen.
Die Merkmalsskala hilft Ihnen, mehrere Variablen mit unzähligen Maßeinheiten umzurechnen, als Kilogramm, Rupien, Jahre, etc., in einheitenlosen Messungen. Aber die Frage ist, welche Skalierungsmethode verwendet werden soll?
Eines der Hindernisse, mit denen jeder Datenwissenschaftler konfrontiert ist, ist das Dilemma, zwischen Normalisierung und Standardisierung zu wählen.. Die meisten Kurse konzentrieren sich nicht auf dieses Thema. Die Merkmalsskala ist einer der wichtigsten Vorverarbeitungsschritte und das Herumspielen mit diesem Konzept ohne entsprechende Kenntnisse kann zu einem ungenauen oder verzerrten Modell führen..
Der Artikel spricht auch darüber, warum sich einige Modelle des maschinellen Lernens mit der Funktionsskalierung dramatisch verbessern, während andere sich nicht einmal ein bisschen bewegen.
Hier könnt ihr den Artikel lesen.
„Was sind die besten Tools, um Data-Science-Aufgaben auszuführen?? Und welches Werkzeug sollte Sie abholen als Newcomer in Data Science? “

Das Wesentliche des Artikels wird in der obigen Frage behandelt. Sobald wir identifiziert haben, was auf persönlicher Ebene zu lernen ist, oder professionell mit den Daten umgehen, Wir müssen die Werkzeuge identifizieren, die am besten für die Aufgabe geeignet sind. In diesem Artikel geht es darum, das beste Tuning-Tool zu identifizieren.
Data Science ist ein sehr breites Thema und jedes Spektrum erfordert eine einzigartige Behandlung von Daten.. Und da ihre Modelle tendenziell einen großen Einfluss auf die Entscheidungen der Organisation haben, Es ist wirklich wichtig, die zu verwendenden Tools zu identifizieren.
Der Artikel ist unterteilt in 2 Teile, der erste konzentriert sich auf die Tools zur Handhabung von Big Data in Bezug auf das Volumen, Abwechslung und Geschwindigkeit. Im nächsten Teil geht es um Tools für Data Science in Bezug auf: Reporting und Business Intelligence, prädiktive Modellierung und maschinelles Lernen, künstliche Intelligenz.
Hier könnt ihr den Artikel lesen.
2020 wird in die Geschichtsbücher eingehen als das Jahr, das die ganze Menschheit verändert hat. Jede Facette des Lebens war vom Coronavirus betroffen und es war zwingend erforderlich, dass Menschen aus allen Bereichen zusammenkommen und zur Lösung dieses Problems beitragen..
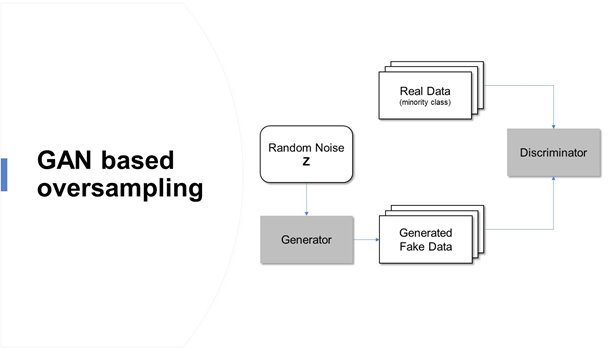
Der Artikel behandelt die Verwendung von Generative Adversarial Networks (GAN), eine Technik der Oversampling von real-wortverzerrten Covid-19-Daten, um das Sterblichkeitsrisiko vorherzusagen. Diese Geschichte gibt uns ein besseres Verständnis dafür, wie die Datenaufbereitungsschritte durchgeführt werden, wie der Umgang mit unausgeglichenen Daten, verbessert die Leistung unseres Modells.
Die Daten und das zentrale Modell dieses Artikels stammen aus der aktuellen Studie (juli 2020) Über “COVID-19-Gesundheitsvorhersage von Patienten mit getriebenem Random-Forest-Algorithmus” von Celestine Iwendi, Ali Kashif Bashir, Atharva Peshkar. et al. Diese Studie verwendete den Random-Forest-Algorithmus, der auf dem AdaBoost-Modell basiert, und prognostizierte die Mortalität einzelner Patienten mit a 94% Präzision. In diesem Artikel, das gleiche Modell und die gleichen Modellparameter wurden berücksichtigt, um die Verbesserung der Präzision des bestehenden Modells durch die Verwendung der GAN-basierten Oversampling-Technik klar zu analysieren.
Hier könnt ihr den Artikel lesen.
Warum Deep Learning??
Das ist eine perfekte Frage. Wir werden mit Algorithmen des maschinellen Lernens überflutet. Es gibt keinen Mangel an Zählen und jede Art von Daten kann mit jedem dieser Algorithmen gelöst werden.

Was ist mehr, Deep-Learning-Algorithmen erfordern große Rechenleistung. Dann, Ist es notwendig, diese Algorithmen zu verwenden??
Dieser Artikel ist ein Beweis für all die Abfragen, die die Notwendigkeit von Deep Learning und seinen neuronalen Netzen in Frage stellen, wie konvolutionelle neuronale Netze (CNN), wiederkehrende neuronale Netze (RNN), künstliche neurale Netzwerke (ANN), etc. Deep Learning ersetzt maschinelles Lernen in Bezug auf Entscheidungsgrenzen und Feature Engineering.
Hier könnt ihr den Artikel lesen.
Viele von uns kennen die verschiedenen Domänen der Datenindustrie noch nicht. Wir verwenden diese Begriffe immer noch synonym und es verursacht viel Verwirrung während der Kommunikation.

Sowohl Business Analytics als auch Data Science sind gefragter denn je. Es wird erwartet, dass die Größe des Marktes erreicht wird $ 100 Milliarden und $ 140 Milliarde, beziehungsweise, zu 2025. Deswegen, es macht nur Sinn zu verstehen, was beide Domänen wirklich bedeuten, Ihre Verantwortlichkeiten und was sind die Gemeinsamkeiten, die dazu führen, dass diese Begriffe austauschbar verwendet werden?.
Ein DataPeaker, Wir sind auf viele aufstrebende Analytics-Profis gestoßen, die sich entscheiden möchten “Geschäftsanalysen” Ö “Datenwissenschaft” als Karriere, aber sie sind sich nicht einmal des Unterschieds zwischen diesen beiden Rollen sicher. Bevor Sie in Ihre eigene Wahl eintauchen, Sie müssen sich klar sein, welchen Weg Sie einschlagen möchten, Wahrheit? Es könnte eine karrierebestimmende Entscheidung sein!!
Dieser Artikel untersucht die Gemeinsamkeiten und Unterschiede zwischen Business Analytics und Data Science und versucht, Ihnen ein besseres Bild zu geben.
Hier könnt ihr den Artikel lesen.
Einige der einfachsten Aufgaben, wie man Tabellen verbindet, kann in Python kompliziert erscheinen. Dieser Artikel ist eine einfache Anleitung zum Kleben 2 Tabellen mit Pandas-Bibliothek ohne Probleme.
Unser Artikel mit der siebtbesten Leistung wird Ihnen helfen, die verschiedenen Arten von Kombinationen in Pandas zu verstehen:
- Inneres beitreten in Pandas
- Mach mit bei Pandas
- Union Linke in Pandas
- Treten Sie dem Recht in Pandas bei
Hier könnt ihr den Artikel lesen.

Dies ist der zweite Artikel aus einem Open-Source-Data-Science-Projekt, der auf dieser Liste erscheint. Wir werten dies als klares Zeichen dafür, dass das Lernen in Bezug auf die aufstrebende Data Science nicht in den Hintergrund getreten ist..
Dieser Artikel enthält die wichtigsten Open-Source-Data-Science-Projekte für den Monat April. Die Liste enthält-
- Konvertieren Sie ein beliebiges Bild in ein 3D-Foto
- Verwandeln Sie ein Bild in eine Cartoon-Illustration
- Single-Shot-Tracking mit mehreren Objekten
- OpenAI Jukebox: ein generatives Modell für Musik
- ShyNet: Cookie-freie, datenschutzfreundliche Webanalyse
- Handbuch zur Fußballanalyse
Hier könnt ihr den Artikel lesen.

Codieren ist eine sehr persönliche Erfahrung für jeden Data Scientist, Business Analyst, Datenanalyst oder Programmierer.
Wir alle haben auf unserer Codierungsreise einen Punkt erreicht, an dem wir der Meinung sind, dass ein bestimmtes Tool unserer Effizienz abträglich ist.. Der Grund kann von Ihrem Codierungsstil abweichen, Ihre Position auf dem Lernpfad oder andere Gründe, die das Tool für Sie inkompatibel machen.
Hier kommt die Identifizierung der richtigen IDE ins Spiel.. Eine IDE hilft uns beim Schreiben und Ausführen von Python-Code zur Analyse, Datenwissenschaft, Softwareentwicklung und viele andere Aufgaben. Es gibt derzeit mehrere IDEs auf dem Markt, mit eigenem Funktionsumfang, Vorteile und Nachteile.
Hier könnt ihr den Artikel lesen.
Wie stellen wir diese Daten so dar, dass unser Führungsteam oder unsere Entscheidungsträger schnell zu einem Konsens gelangen??
Die Antwort auf die obige Frage ist eine prägnante Visualisierung. Sie können kein Modell in Excel oder Python erstellen und nur hoffen, dass die Beteiligten die Auswirkungen verstehen.

Excel ist seit mehr als einem Jahr Marktführer bei EDA- und Visualisierungsaufgaben 35 Jahre. Die meisten Unternehmen vertrauen ihm, vor allem die kleinen aufgrund ihrer Eigenschaften.
In diesem Artikel, Wir analysieren die folgenden Panels:
- Online-Verkaufsverfolgung
- Marketinganalyse
- Projektmanagement
- Einkommensverfolgung
- Personalmanagement
Hier könnt ihr den Artikel lesen.
Abschließende Anmerkungen
Jahr 2020 Es war ein Sprung für die Machine-Learning-Community. Ich hoffe, diese Artikel zum Thema Data Science sind für Sie auf Ihrem Lernweg hilfreich.. Teilen Sie uns Ihre Gedanken in den Kommentaren unten mit..
Lerne weiter! Und hör nie auf zu schreiben!





