Überblick
- Beim Feature Engineering im NLP geht es darum, den Kontext des Textes zu verstehen.
- In diesem Blog, Wir werden uns einige der allgemeinen Engineering-Funktionen in NLP ansehen.
- Wir vergleichen die Ergebnisse einer Klassifikationsaufgabe mit und ohne Feature-Engineering.
Inhaltsverzeichnis
- Einführung
- Übersicht über NLP-Aufgaben
- Liste der Funktionen mit Code
- Implementierung
- Vergleich der Ergebnisse mit und ohne Funktionsengineering
- Fazit
Einführung
“Wenn er 80 Prozent unserer Arbeit ist die Datenaufbereitung, Die Sicherstellung der Datenqualität ist die wichtige Aufgabe eines Machine-Learning-Teams”. – Andrew Ng

Function Engineering ist einer der wichtigsten Schritte beim maschinellen Lernen. Es ist der Prozess, bei dem das Domänenwissen der Daten verwendet wird, um Eigenschaften zu erstellen, die maschinelle Lernalgorithmen zum Funktionieren bringen.. Stellen Sie sich den maschinellen Lernalgorithmus wie ein lernendes Kind vor; desto genauer sind die von Ihnen gemachten Angaben, desto besser können sie die Informationen interpretieren. Wenn wir uns zuerst auf unsere Daten konzentrieren, werden wir bessere Ergebnisse erzielen, als wenn wir uns nur auf Modelle konzentrieren. Feature Engineering hilft uns, bessere Daten zu erstellen, die dem Modell helfen, sie gut zu verstehen und vernünftige Ergebnisse zu liefern.
NLP ist ein Teilgebiet der künstlichen Intelligenz, in dem wir die menschliche Interaktion mit Maschinen mithilfe natürlicher Sprachen verstehen. Eine natürliche Sprache verstehen, es ist notwendig zu verstehen, wie wir einen Satz schreiben, wie wir unsere Gedanken mit verschiedenen Worten ausdrücken, Zeichen, spezielle Charaktere, etc., Grundsätzlich müssen wir den Kontext des Satzes verstehen, um seine Bedeutung zu interpretieren.
Wenn wir diese Kontexte als Merkmale verwenden und in unser Modell einspeisen können, dann kann das Modell den Satz besser verstehen. Einige der gemeinsamen Merkmale, die wir aus einem Satz extrahieren können, sind die Anzahl der Wörter, die Anzahl der Großbuchstaben, die Punktezahl, die Anzahl der einzigartigen Wörter, die Anzahl der leeren Wörter, die durchschnittliche Satzlänge, etc. Wir können diese Merkmale basierend auf unserem Datensatz definieren, den wir verwenden. In diesem Blog, Wir verwenden einen Twitter-Datensatz, damit wir einige andere Merkmale wie die Anzahl der Hashtags hinzufügen können, die Anzahl der Erwähnungen, etc. Wir werden sie in den nächsten Abschnitten ausführlich besprechen..
Übersicht über NLP-Aufgaben
Die Aufgabe des Function Engineering im NLP verstehen, wir werden es in einen Twitter-Datensatz implementieren. Wir werden verwenden COVID-19 Fake-News-Datensatz. Die Aufgabe besteht darin, den Tweet zu klassifizieren als Gefälscht Ö Wahr. Der Datensatz ist unterteilt in Zug, Validierungs- und Testset. Unten ist die Verteilung,
| Auseinander brechen | Wahr | Gefälscht | Gesamt |
| Bahn | 3360 | 3060 | 6420 |
| Validierung | 1120 | 1020 | 2140 |
| Prüfen | 1120 | 1020 | 2140 |
Liste der Funktionen
Ich werde insgesamt auflisten 15 Funktionen, die wir für den obigen Datensatz verwenden können, Die Anzahl der Funktionen hängt vollständig von der Art des verwendeten Datasets ab..
1. Anzahl von Charakteren
Zählen Sie die Anzahl der Zeichen in einem Tweet.
def count_chars(Text):
zurück len(Text)
2. Anzahl der Wörter
Zählen Sie die Anzahl der Wörter in einem Tweet.
def count_words(Text):
zurück len(text.split())
3. Großbuchstaben Zahl
Zählen Sie die Anzahl der Großbuchstaben in einem Tweet.
def count_capital_chars(Text):
zählen=0
für ich im text:
wenn i.isupper():
zählen+=1
Rücklaufzahl
4. Anzahl der Wörter in Großbuchstaben
Zählen Sie die Anzahl der Wörter in Großbuchstaben in einem Tweet.
def count_capital_words(Text):
Rücksendesumme(Karte(str.isupper,text.split()))
5. Zählen Sie die Anzahl der Punkte
In dieser Funktion, wir geben ein Wörterbuch von . zurück 32 Satzzeichen mit Zählung, die als eigenständige Funktionen verwendet werden können, die ich im nächsten Abschnitt besprechen werde.
def count_punctuations(Text):
Satzzeichen="!"#$%&"()*+,-./:;<=>[E-Mail geschützt][]^_`{|}~'
d=dict()
für ich in Satzzeichen:
D[str(ich)+' zählen']=text.count(ich)
zurück d
6. Anzahl der Wörter in Anführungszeichen
Die Anzahl der Wörter zwischen einfachen und doppelten Anführungszeichen.
def count_words_in_quotes(Text):
x = wiederfinden("'.'|"."", Text)
zählen=0
wenn x Keine ist:
Rückkehr 0
anders:
für ich in x:
t=i[1:-1]
count+=count_words
Rücklaufzahl
7. Anzahl der Sätze
Zähle die Anzahl der Sätze in einem Tweet.
def count_sent(Text):
zurück len(nltk.sent_tokenize(Text))
8. Zählen Sie die Anzahl der eindeutigen Wörter.
Zählen Sie die Anzahl der eindeutigen Wörter in einem Tweet.
def count_unique_words(Text):
zurück len(einstellen(text.split()))
9. Hashtag-Anzahl
Da wir den Twitter-Datensatz verwenden, Wir können zählen, wie oft Benutzer den Hashtag verwendet haben.
def count_htags(Text):
x = wiederfinden(R'(#w[A-Za-z0-9]*)', Text)
zurück len(x)
10. Anzahl der Erwähnungen
Und Twitter, meistens antworten die Leute oder erwähnen jemanden in ihrem Tweet, das Zählen der Anzahl der Nennungen kann auch als Merkmal behandelt werden.
def count_mentions(Text):
x = wiederfinden(R'(@w[A-Za-z0-9]*)', Text)
zurück len(x)
11. Anzahl der leeren Wörter
Hier werden wir die Anzahl der Stoppwörter zählen, die in einem Tweet verwendet werden.
def count_stopwords(Text):
stop_words = gesetzt(Stoppwörter.Wörter('Englisch'))
word_tokens = word_tokenize(Text)
stopwords_x = [w für w in word_tokens wenn w in stop_words]
zurück len(Stoppwörter_x)
12. Berechnen Sie die durchschnittliche Länge von Wörtern
Dies kann berechnet werden, indem die Anzahl der Zeichen durch die Anzahl der Wörter geteilt wird.
df['avg_wordlength'] = df['char_count']/df['Wortzahl']
13. Berechnung der durchschnittlichen Länge von Sätzen
Dies kann berechnet werden, indem die Wortzahl durch die Satzzahl geteilt wird.
df['avg_sentlength'] = df['Wortzahl']/df['sent_count']
14. einzigartige Wörter vs. Wortzählfunktion
Dieses Merkmal ist im Grunde das Verhältnis von eindeutigen Wörtern zu einer Gesamtzahl von Wörtern.
df['unique_vs_words'] = df['unique_word_count']/df['Wortzahl']
15. Wortzählfunktion stoppen vs. Wortzählfunktion
Dieses Merkmal ist auch das Verhältnis zwischen der Anzahl der Stoppwörter und der Gesamtzahl der Wörter.
df['stopwords_vs_words'] = df['stopword_count']/df['Wortzahl']
Implementierung
Sie können den Datensatz herunterladen von hier. Nach dem Download, wir können mit der Implementierung aller oben definierten Funktionen beginnen. Wir werden uns mehr auf das Funktions-Engineering konzentrieren, dafür halten wir den Ansatz einfach, mit TF-IDF und einfacher Vorverarbeitung. Der gesamte Code wird in meinem GitHub-Repository verfügbar sein https://github.com/ahmadkhan242/Feature-Engineering-in-NLP.
-
Zug lesen, Validierungs- und Testsuite mit Pandas.
train = pd.read_csv("zug.csv") val = pd.read_csv("Validierung.csv") test = pd.read_csv(testWithLabel.csv") # Für diese Aufgabe kombinieren wir den Zug- und Validierungsdatensatz und verwenden dann # einfacher Zugtest Split von sklern. df = pd.concat([Bahn, val]) df.kopf()
-
Anwenden einer zuvor definierten Merkmalsextraktion auf den Zug- und Testsatz.
df['char_count'] = df["twittern"].anwenden(Lambda x:count_chars(x)) df['Wortzahl'] = df["twittern"].anwenden(Lambda x:count_words(x)) df['sent_count'] = df["twittern"].anwenden(Lambda x:count_sent(x)) df['capital_char_count'] = df["twittern"].anwenden(Lambda x:count_capital_chars(x)) df['capital_word_count'] = df["twittern"].anwenden(Lambda x:count_capital_words(x)) df['quoted_word_count'] = df["twittern"].anwenden(Lambda x:count_words_in_quotes(x)) df['stopword_count'] = df["twittern"].anwenden(Lambda x:count_stopwords(x)) df['unique_word_count'] = df["twittern"].anwenden(Lambda x:count_unique_words(x)) df['htag_count'] = df["twittern"].anwenden(Lambda x:count_htags(x)) df['Erwähnung_Anzahl'] = df["twittern"].anwenden(Lambda x:Anzahl_Erwähnungen(x)) df['punct_count'] = df["twittern"].anwenden(Lambda x:count_punctuations(x)) df['avg_wordlength'] = df['char_count']/df['Wortzahl'] df['avg_sentlength'] = df['Wortzahl']/df['sent_count'] df['unique_vs_words'] = df['unique_word_count']/df['Wortzahl'] df['stopwords_vs_words'] = df['stopword_count']/df['Wortzahl'] # GLEICHER KÖNNEN SIE SIE AUF TEST SET ANWENDEN
-
Hinzufügen einiger zusätzlicher Funktionen mithilfe der Punktzahl
Wir erstellen einen DataFrame aus dem von der Funktion "punct_count" zurückgegebenen Wörterbuch und führen ihn dann mit dem Hauptdatensatz zusammen.
df_punct = pd.DataFrame(aufführen(df.punct_count)) test_punct = pd.DataFrame(aufführen(test.punct_count)) # Verbindungs-DataFrame mit dem Haupt-DataFrame zusammenführen df = pd.merge(df, df_punct, left_index=Wahr, right_index=Wahr) test = pd.merge(Prüfung, test_punct,left_index=Wahr, right_index=Wahr)
# Wir können fallen "punt_count" Spalte aus df und test DataFrame df.drop(Spalten=['punct_count'],inplace=Wahr) test.drop(Spalten=['punct_count'],inplace=Wahr) df.spalten
-
Wiederaufbereitung
Wir führen einen einfachen Schritt vor der Verarbeitung durch, So entfernen Sie Links, Benutzername entfernen, Zahlen, Doppelter Raum, Interpunktion, Kleinbuchstaben, etc.
auf jeden Fall entfernen_links(twittern): '''Nimmt einen String und entfernt Weblinks daraus''' tweet = re.sub(r'httpS+', '', twittern) # http-Links entfernen tweet = re.sub(r'bit.ly/S+', '', twittern) # rempve bitly links tweet = tweet.strip('https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/ ') # Löschen [Links] Tweet zurückgeben def remove_users(twittern): '''Nehmt eine Zeichenfolge und entfernt Retweet und @Benutzerinformationen''' tweet = re.sub('([E-Mail geschützt][A-Za-z]+[A-Za-z0-9-_]+)', '', twittern) # Retweet entfernen tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', twittern) # entfernt getwittert bei Tweet zurückgeben my_punctuation = '!"$%&'()*+,-./:;<=>?[]^_`{|}~•@' def Vorverarbeitung(gesendet): gesendet = remove_users(gesendet) gesendet = remove_links(gesendet) gesendet = gesendet.lower() # Kleinbuchstaben gesendet = re.sub('['+meine_Zeichensetzung + ']+', ' ', gesendet) # Satzzeichen streifen gesendet = re.sub('s+', ' ', gesendet) #doppelten Abstand entfernen gesendet = re.sub('([0-9]+)', '', gesendet) # Zahlen entfernen sent_token_list = [Wort für Wort in gesendet.split(' ')] gesendet=" ".beitreten(sent_token_list) zurück gesendet df['twittern'] = df['twittern'].anwenden(Lambda x: Vorverarbeitung(x)) Prüfung['twittern'] = testen['twittern'].anwenden(Lambda x: Vorverarbeitung(x))
-
Textentschlüsselung
Wir werden unsere Textdaten mit TF-IDF codieren. Wir passen zuerst transform an unsere Zug-Tweet-Spalte und unser Test-Set an und fügen sie dann mit allen Feature-Spalten zusammen.
Vektorisierer = TfidfVektorisierer() train_tf_idf_features = vectorizer.fit_transform(df['twittern']).toarray() test_tf_idf_features = vectorizer.transform(Prüfung['twittern']).toarray() # Konvertieren der obigen Liste in DataFrame train_tf_idf = pd.DataFrame(train_tf_idf_features) test_tf_idf = pd.DataFrame(test_tf_idf_features) # Trennen von Zug- und Prüfetiketten von allen Funktionen train_Y = df['Etikett'] test_Y = test['Etikett'] #Alle Funktionen auflisten Eigenschaften = ['char_count', 'Wortzahl', 'sent_count', 'capital_char_count', 'capital_word_count', 'quoted_word_count', 'stopword_count', 'unique_word_count', 'htag_count', 'Erwähnung_Anzahl', 'avg_wordlength', 'avg_sentlength', 'unique_vs_words', 'stopwords_vs_words', '! zählen', '" zählen', '# zählen', '$ zählen', '% zählen', '& zählen', '' zählen', '( zählen', ') zählen', '* zählen', '+ zählen', ', zählen', '- zählen', '. zählen', '/ zählen', ': zählen', '; zählen', '< zählen', '= zählen', '> zählen', '? zählen', '@ zählen', '[ zählen', ' zählen', '] zählen', '^ zählen', '_ zählen', ''zählen', '{ zählen', '| zählen', '} zählen', '~ zählen'] # Endlich alle Funktionen mit obigem TF-IDF zusammenführen. train = pd.merge(train_tf_idf,df[Merkmale],left_index=Wahr, right_index=Wahr) test = pd.merge(test_tf_idf,Prüfung[Merkmale],left_index=Wahr, right_index=Wahr) -
Ausbildung
Für das Training, Wir werden den Random Forest-Algorithmus aus der sci-kit-Lernbibliothek verwenden.
X_Zug, X_test, y_train, y_test = train_test_split(Bahn, train_Y, test_size=0.2, random_state = 42) # Zufälliger Waldklassifizierer clf_model = RandomForestClassifier(n_Schätzer = 1000, min_samples_split = 15, random_state = 42) clf_model.fit(X_Zug, y_train) _RandomForestClassifier_prediction = clf_model.predict(X_test) val_RandomForestClassifier_prediction = clf_model.predict(Prüfung)
Ergebnisvergleich
Zum Vergleich, Wir trainieren unser Modell zuerst mit dem obigen Datensatz mit Feature-Engineering-Techniken und dann ohne Feature-Engineering-Techniken. In beiden Ansätzen, Wir haben den Datensatz mit der gleichen Methode wie oben beschrieben vorverarbeitet und TF-IDF wurde in beiden Ansätzen verwendet, um die Textdaten zu codieren. Sie können jede beliebige Codierungstechnik verwenden, wie word2vec, Handschuh, etc.
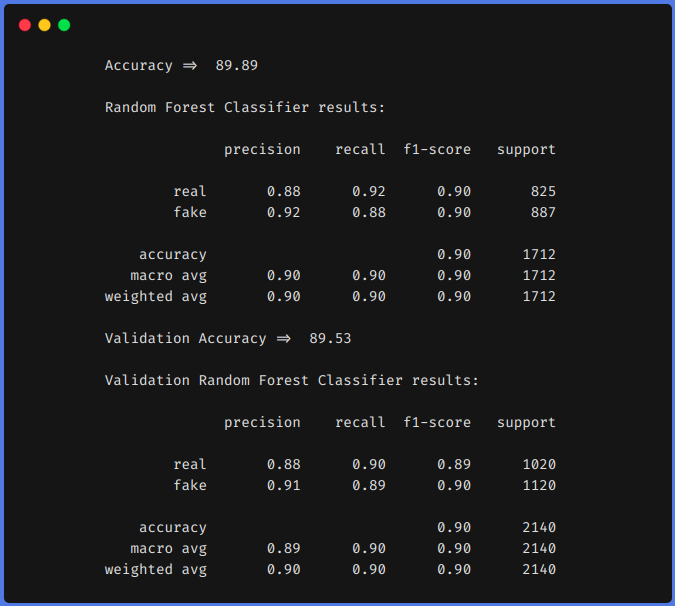
1. Ohne den Einsatz von Function-Engineering-Techniken
2. Einsatz von Function Engineering Techniken
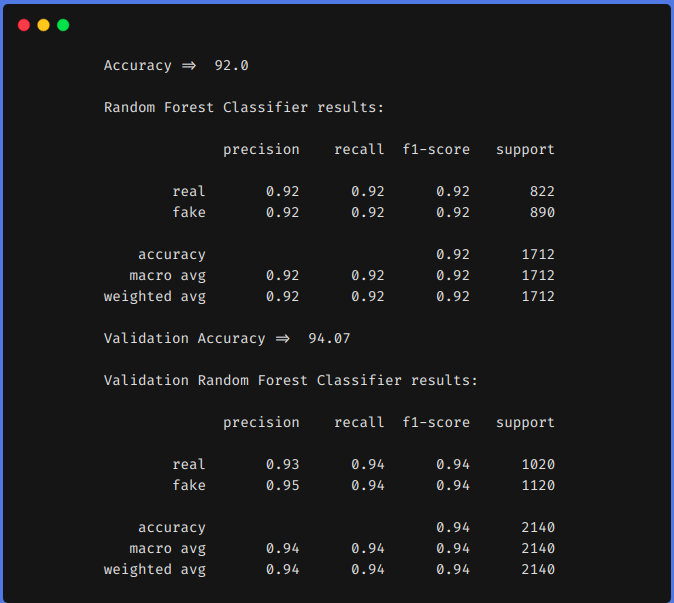
Aus den vorherigen Ergebnissen, Wir können sehen, dass Feature-Engineering-Techniken uns geholfen haben, unsere f1 von 0,90 bis um 0,92 im Zug und ab 0,90 bis um 0,94 im Testteam.
Fazit
Die obigen Ergebnisse zeigen, dass, wenn wir Function Engineering durchführen, Wir können mit klassischen Machine-Learning-Algorithmen eine höhere Präzision erreichen. Die Verwendung eines transformatorbasierten Modells ist ein zeit- und ressourcenintensiver Algorithmus. Wenn wir Function Engineering richtig betreiben, nämlich, nach der Analyse unseres Datensatzes, wir können vergleichbare Ergebnisse erzielen.
Wir können auch andere Feature-Engineerings durchführen, wie man die Anzahl der verwendeten Emojis zählt, die Art der verwendeten Emojis, welche Häufigkeiten von einzigartigen Wörtern, etc. Wir können unsere Eigenschaften definieren, indem wir den Datensatz analysieren. Ich hoffe, du hast etwas aus diesem Blog gelernt, teile es mit anderen. Schauen Sie sich meinen persönlichen Blog für maschinelles Lernen an (https://code-ml.com/) um neue und spannende Inhalte in verschiedenen Bereichen von ML und KI zu erhalten.
Über den Autor
Mohammad Ahmad (B.Tech) LinkedIn - https://www.linkedin.com/in/mohammad-ahmad-ai/ Persönlicher Blog - https://code-ml.com/ GitHub - https://github.com/ahmadkhan242 Twitter - https://twitter.com/ahmadkhan_242
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





