Inhaltsverzeichnis
-
Einführung
-
Reibungsloser Überblick
-
Nachteile der Verwendung von PCA
-
Praxisbeispiel
-
Fazit
Einführung
„Künstliche Intelligenz ist die neueste Erfindung, die die Menschheit machen muss”. Das Zitat macht definitiv klar, dass Machine Learning die Zukunft und große Chancen und Vorteile für alle ist. Lassen Sie dies einen Neuanfang für Sie sein, um einen wirklich coolen Algorithmus im maschinellen Lernen zu lernen.
Wie jeder weiß, Wir stoßen bei Machine-Learning-Aufgaben oft auf die Probleme beim Speichern und Verarbeiten von Big Data, da es ein zeitaufwändiger Prozess ist und auch beim Dolmetschen Schwierigkeiten auftreten. Nicht alle Datenfunktionen sind für Vorhersagen erforderlich. Diese verrauschten Daten können zu schlechter Leistung und Modellüberanpassung führen.. Durch diesen Artikel, Lassen Sie mich Ihnen eine PCA-Technik des unbeaufsichtigten Lernens vorstellen (Hauptkomponentenanalyse) was Ihnen helfen kann, diese Probleme bis zu einem gewissen Grad effektiv zu lösen und genauere Vorhersageergebnisse zu liefern.
Das PCA wurde Anfang des 20. Jahrhunderts von Karl Pearson erfunden, analog zu Hauptachsensatz in der Mechanik und ist weit verbreitet. Durch diese Methode, Wir transformieren die Daten tatsächlich in eine neue Koordinate, wobei diejenige mit der höchsten Varianz die Haupthauptkomponente ist. So erhalten wir die bestmöglichen Datendarstellungen.
Weiche Abstraktion
Funktionsreiche Daten können Korrelationen und Duplikate enthalten. Dann, sobald du die daten hast, Der Hauptschritt besteht darin, sie zu bereinigen, indem irrelevante Features entfernt und Feature-Engineering-Techniken angewendet werden, die sogar bessere Ergebnisse als die ursprünglichen Features liefern können. Hauptkomponentenanalyse (PCA) ist eine dieser Techniken, mit denen eine Dimensionsreduktion möglich ist (lineare Transformation bestehender Attribute) und multivariate Analyse. Es hat mehrere Vorteile, inklusive Reduzierung der Datengröße (Daher, schnellere Ausführung), bessere Visualisierungen mit weniger Dimensionen, Varianz maximieren, reduziert Überanpassung, etc.
Die Hauptkomponente bedeutet eigentlich die Richtungsvektorfolgen, die sich basierend auf den Linien der besten Anpassung unterscheiden. Man kann auch sagen, dass diese Komponenten Eigenvektoren der Kovarianzmatrix sind. Wir werden dieses Konzept im Folgenden untersuchen..
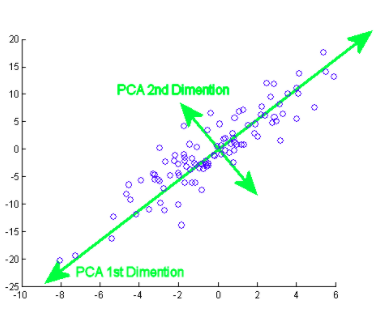
Wie machst Du das? Anfänglich, necesitas encontrar los componentes principales desde diferentes puntos de vista durante la fase de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen...., von denen, die Sie die wichtigen und am wenigsten korrelierten Komponenten aufheben und den Rest ignorieren, dadurch Komplexität reduzieren. Die Anzahl der Hauptkomponenten kann kleiner oder gleich der Gesamtanzahl der Attribute sein.
Angenommen, zwei Spalten X und Y sind die 2 Merkmale,
XY
1 4
2 3
3 4
4 6
5 8
Meinen
x ‚= 3, Ja‘ = 5
Covarianza
das (x, Ja) = (Xi – x ‚) (Ja – Ja‘) / n – 1, wo ich = 1 ein
C = [ das(x,x) das (x,Ja) ]
[das(Ja,x) das(Ja,Ja) ]
Ähnlich, für mehr Funktionen, wir finden die komplette Kovarianzmatrix mit mehr Dimensionen. Durch die weitere Berechnung der Eigenwerte, Vektor, etc., Wir können die Hauptkomponenten finden. Der Import von Algorithmen und die Verwendung exakter Bibliotheken machen es einfach, Komponenten ohne Berechnungen zu identifizieren / manuelle Operationen. Beachten Sie, dass die Anzahl der Eigenwerte / Eigenvektoren geben Ihnen die Anzahl der Dimensionen und die mit diesen Komponenten verbundene Varianz an.
jedoch, denn Big Data besteht aus zahlreichen Hauptkomponenten, wird in erster Linie danach ausgewählt, was die größtmögliche Variation darstellt. Infolge, die folgenden Komponenten werden ebenfalls in absteigender Varianzreihenfolge der vorherigen Komponenten durch die Reihenfolge der Eigenwerte entschieden, solange diese auch keine Korrelation mit den bisherigen Hauptkomponenten haben. Dann verwerfen wir die Komponenten mit weniger Eigenwerten / Vektor (weniger bedeutend).
Im letzten Schritt, Wir verwenden Merkmalsvektoren, um die Daten an denen auszurichten, die durch die Hauptkomponenten dargestellt werden (Hauptkomponentenanalyse). Dies geschieht durch Multiplikation der Transponierten des Originaldatensatzes mit der Transponierten des Merkmalsvektors.
Nachteile der Verwendung von PCA / Nachteile
Sie sollten sich bewusst sein, dass die Datenstandardisierung (Dazu gehört auch die Umwandlung kategorialer Variablen in numerische) ist ein Muss vor der Verwendung von PCA. Bei der Anwendung von PCA, unabhängige Merkmale werden weniger interpretierbar, da diese Hauptkomponenten auch nicht lesbar oder interpretierbar sind. Es besteht auch die Möglichkeit, dass Sie während der PCA Informationen verlieren.
Praxisbeispiel
Jetzt, Sehen wir uns an, wie ein Algorithmus in einem Datensatz implementiert wird. Ich werde Sie Schritt für Schritt durch jeden Teil des Codes führen.
Schaut mal rein dieser Datensatz. Dies ist der berühmte IRIS-Blumendatensatz, mit Merkmalen wie Kelchblattlänge, Blütenblattlänge, die Breite des Kelchblattes und die Breite des Blütenblattes, und das VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... objetivo es la especie. Was Sie mit Zielvariable meinen, ist der Wert / Klasse musst du vorhersagen, zu welcher Art die Blume in diesem Fall gehört.
Quelle: Wikipedia
Importieren von Datensätzen und Basisbibliotheken
Zuerst, Beginnen wir mit dem Importieren der erforderlichen Bibliotheken,
numpy als np importieren Pandas als pd importieren import matplotlib.pyplot als plt aus sklearn.datasets import load_iris
Laden Sie die Daten und zeigen Sie die Namen der Merkmale und Klassen zum Verständnis an,
iris = load_iris() #Featurenamen und Kodierung von Zielvariablen drucken(iris.feature_names) drucken(iris.target_names) data = pd.DataFrame(iris.daten) data.columns = iris.feature_names Daten['KLASSE'] = iris.ziel daten.kopf()
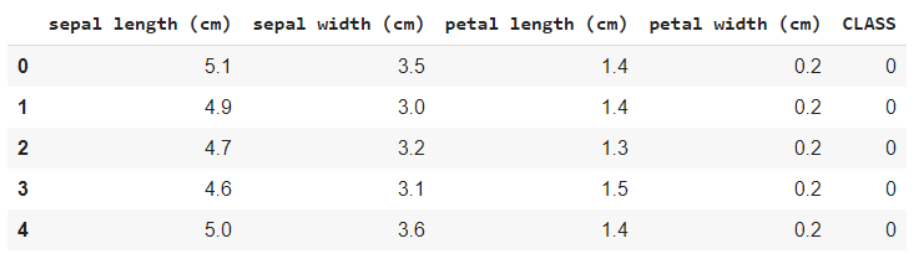
Das folgende Code-Snippet hilft Ihnen bei der Analyse der Daten, nämlich wie viele Variablen kategorial und wie viele numerisch sind. Was ist mehr, Unten ist klar, dass nicht alle Zeilen null sind, bei Nullobjekten, wir bekommen die anzahl und reihen / Spalten, in denen sie vorhanden sind. Dies hilft uns, die Vorverarbeitungsschritte zum Bereinigen der Daten durchzuführen.
daten.info()
Die data.describe-Funktion () liefert im Allgemeinen eine statistische Beschreibung des Datensatzes. Diese können in vielerlei Hinsicht von Vorteil sein, Sie können diese Daten verwenden, um fehlende Werte zu ergänzen oder ein neues Merkmal anzulegen, und viele mehr.
Daten.beschreiben()
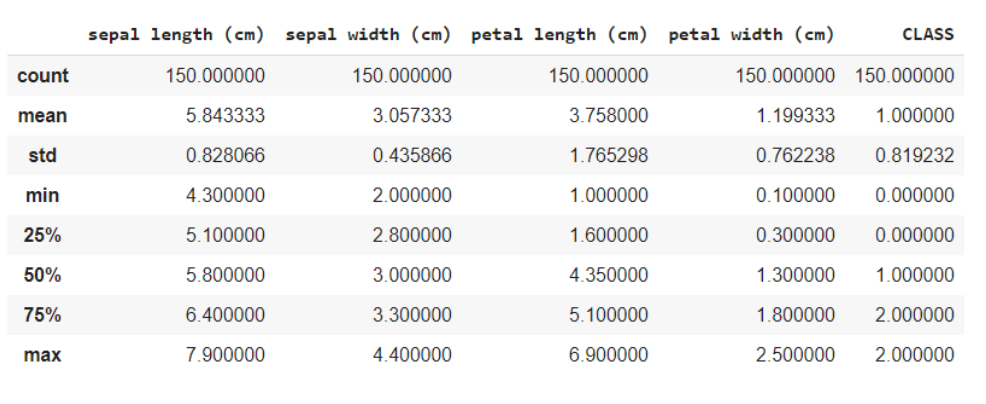
Hier unterteilen Sie die Daten in die Merkmale und die Zielvariablen als X bzw.. Und bei Verwendung der Formmethode, weiß, dass die Daten haben 150 Reihen und 5 Spalten insgesamt, von welchem 1 Spalte ist Ihre Zielvariable und andere 4 sind die Eigenschaften / Attribute.
x = data.iloc[:,:4] #Merkmale y = data.iloc[:,4] #Ziel x.form, y.form
Aus: ((150, 4), (150,))
Da alle Merkmale numerisch sind, es ist einfach für das Modell zum Training. Wenn die Daten kategoriale Variablen enthielten, wir müssen sie zuerst in numerisch umwandeln, da die maschinen / Computer können besser mit Zahlen umgehen.
PCA-Bibliotheksimport
aus sklearn.decomposition importieren PCA PCA = PCA() X = pca.fit_transform(x) pca.get_covariance()

erklärt_variance=pca.explained_variance_ratio_ erklärt_variance

Visualisierungen
mit plt.style.context('dunkler_hintergrund'):
plt.figur(Feigengröße=(6, 4))
plt.bar(Bereich(4), erklärt_variance, Alpha=0,5, ausrichten='zentrieren',
Etikett="individuell erklärter Varianz")Produktion
plt.ylabel('Erklärtes Varianzverhältnis')
plt.xlabel('Hauptkomponenten')
plt.legende(loc ="Beste")
plt.tight_layout()
Aus den Visualisierungen wird die Intuition gewonnen, dass es hauptsächlich nur 3 Komponenten mit erheblicher Varianz, Daher, die Anzahl der Hauptkomponenten wählen wir als 3.
PCA = PCA(n_Komponenten=3) X = pca.fit_transform(x)
Split-Zug-Test
Die Zugprüfungsabteilung ist eine gängige Trainings- und Bewertungsmethode. Wie gewöhnlich, Vorhersagen auf den trainierten Daten selbst können zu einer Überanpassung führen, Dies führt zu schlechten Ergebnissen für unbekannte Daten. In diesem Fall, durch Aufteilen der Daten in Trainings- und Testsätze, Sie trainieren und prognostizieren dann mit dem Modell in 2 verschiedene Sets, damit das Problem der Überanpassung gelöst.
aus sklearn.model_selection import train_test_split X_Zug, X_test, y_train, y_test = train_test_split(x, Ja, test_size = 0.3, random_state=20, stratifizieren=y)
Modelltraining
Unser Ziel ist es, die Klasse zu identifizieren / Art, zu der die Blume aufgrund einiger ihrer Eigenschaften gehört. Deswegen, Dies ist ein Klassifizierungsproblem und das von uns verwendete Modell verwendet K nächste Nachbarn.
von sklearn.neighbors importieren KNeighborsClassifier model = KNeighborsClassifier(7) model.fit(X_Zug,y_train) y_pred = model.predict(X_test)
Vorhersagen
von sklearn.metrics importieren Confusion_matrix von sklearn.metrics import precision_score cm = verwirrt_matrix(y_test, y_pred) #Verwirrung Matrix drucken(cm) drucken(Genauigkeit_Score(y_test, y_pred))
Die Verwirrungsmatrix zeigt Ihnen die Anzahl der falsch positiven, falsch negativ, wahre Positive und wahre Negative.
La puntuación de precisión le indicará en qué messenDas "messen" Es ist ein grundlegendes Konzept in verschiedenen Disziplinen, , die sich auf den Prozess der Quantifizierung von Eigenschaften oder Größen von Objekten bezieht, Phänomene oder Situationen. In Mathematik, Wird verwendet, um Längen zu bestimmen, Flächen und Volumina, In den Sozialwissenschaften kann es sich auf die Bewertung qualitativer und quantitativer Variablen beziehen. Die Messgenauigkeit ist entscheidend, um zuverlässige und valide Ergebnisse in der Forschung oder praktischen Anwendung zu erhalten.... nuestro modelo ha sido eficaz a la hora de ofrecer predicciones para nuevos datos. Das 97% es ist ein sehr gutes Ergebnis, und deshalb können wir sagen, dass unser Modell ein gutes Modell ist.
Den vollständigen Code finden Sie unter diese Google-Zusammenarbeit geplant.
Fazit
Ich hoffe sehr, dass Sie eine Ahnung von PCA hatten und auch mit dem oben diskutierten Beispiel vertraut sind. Es ist nicht so kompliziert zu verdauen, bleib einfach konzentriert. Lesen Sie dies unbedingt noch einmal, wenn Sie es nützlich finden, und entwickeln Sie den Algorithmus selbst, um ihn besser zu verstehen..
Einen schönen Tag noch !! 🙂
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





