Dieser Artikel wurde im Rahmen der Data Science Blogathon
1. Ziel
Das Ziel dieses Artikels ist es, die Preise der Flüge unter den verschiedenen Parametern vorherzusagen. Die in diesem Artikel verwendeten Daten sind auf Kaggle . öffentlich verfügbar. Dies wird ein Regressionsproblem sein, da die Ziel- oder abhängige Variable der Preis ist (fortlaufender numerischer Wert).
2. Einführung
Fluggesellschaften verwenden komplexe Algorithmen, um die Flugpreise unter den verschiedenen Bedingungen zu berechnen, die zu diesem Zeitpunkt vorliegen.. Diese Methoden berücksichtigen finanzielle Faktoren, Marketing und Social, um Flugpreise vorherzusagen.
Heute, die Zahl der Fluggäste ist deutlich gestiegen. Für Fluggesellschaften ist es schwierig, die Preise zu halten, da sich die Preise aufgrund unterschiedlicher Bedingungen dynamisch ändern. Deshalb werden wir versuchen, dieses Problem mit maschinellem Lernen zu lösen.. Dies kann Fluggesellschaften helfen, indem es vorhersagt, welche Preise sie halten können. Es kann Kunden auch helfen, zukünftige Flugpreise vorherzusagen und ihre Reise entsprechend zu planen..
3. Verwendete Daten
Kaggle-Daten wurden verwendet, Dies ist eine kostenlose Zugangsplattform für Datenwissenschaftler und Enthusiasten des maschinellen Lernens.
Quelle: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
Wir verwenden jupyter-notebook, um die Aufgabe der Flugpreisvorhersage auszuführen.
4. Datenanalyse
Das Verfahren zum Extrahieren von Informationen aus gegebenen Rohdaten wird als Datenanalyse bezeichnet. Hier verwenden wir eda Modul Datenaufbereitung Bibliothek, um diesen Schritt zu tun.
aus dataprep.eda importieren create_report
Pandas als pd importieren
Datenrahmen = pd.read_excel("../Ausgabe/Data_Train.xlsx")
Bericht erstellen(Datenrahmen)
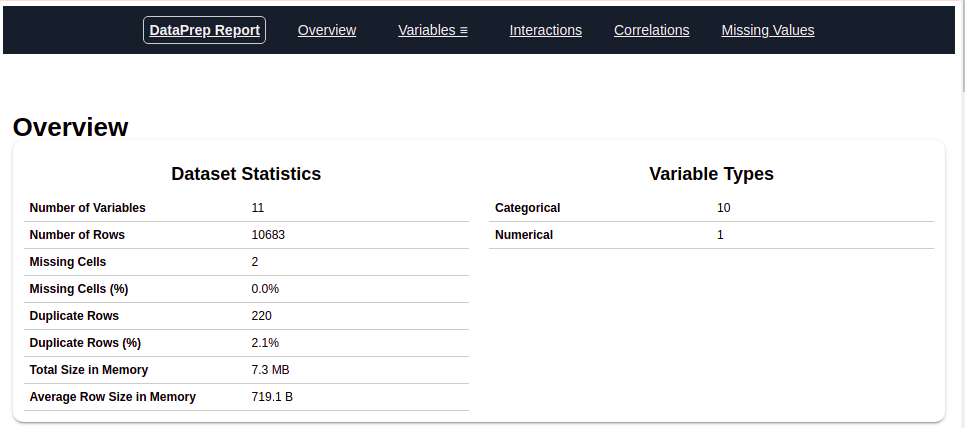
Nach dem Ausführen des obigen Codes, Sie erhalten einen Bericht wie in der Abbildung oben gezeigt. Dieser Bericht enthält mehrere Abschnitte oder Registerkarten. Der Abschnitt „Allgemeine Beschreibung“’ dieses Berichts liefert uns alle grundlegenden Informationen zu den von uns verwendeten Daten. Für die aktuellen Daten verwenden wir, wir haben folgende informationen bekommen:
Anzahl der Variablen = 11
Anzahl der Reihen = 10683
Charakteristische kategoriale Typennummer = 10
Charakteristische numerische Typennummer = 1
Zeilen dupliziert = 220, etc.
Sehen wir uns die anderen Abschnitte des Berichts nacheinander an.
4.1 Variablen
Nach Auswahl des Variablenbereichs, Sie erhalten Informationen wie in den folgenden Abbildungen gezeigt.
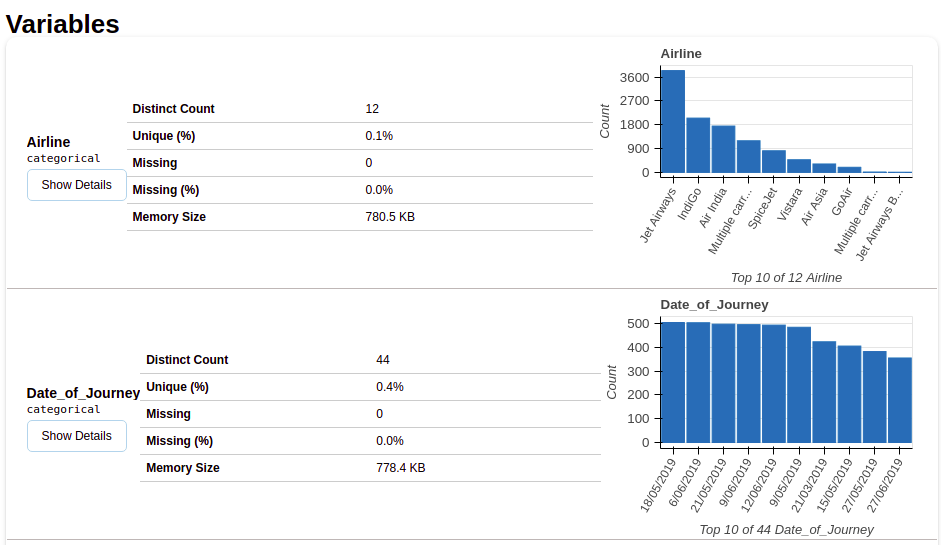
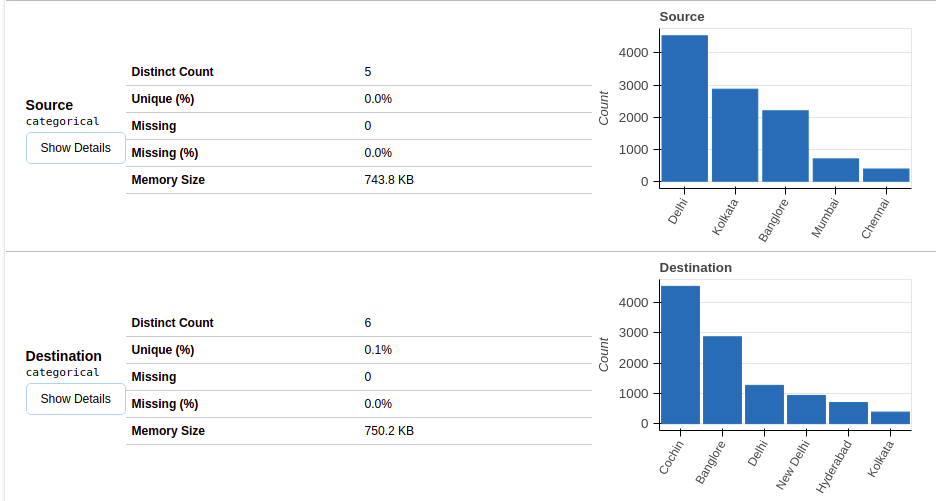
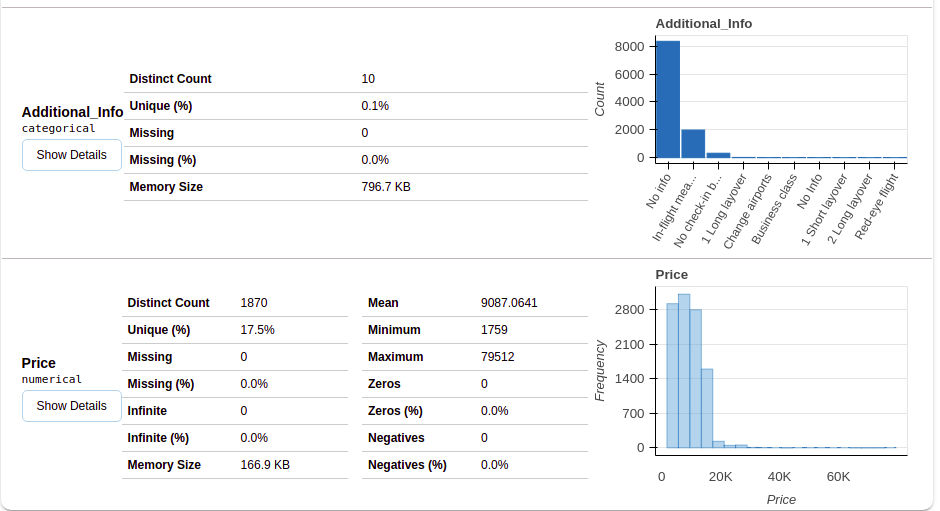
Dieser Abschnitt enthält den Typ jeder Variablen zusammen mit einer detaillierten Beschreibung der Variablen..
4.2 Fehlende Werte
Dieser Abschnitt bietet mehrere Möglichkeiten, fehlende Werte in Variablen zu analysieren. Wir werden drei am häufigsten verwendete Methoden besprechen, Balkengrafik, Spektrum und Heatmap. Lass uns jeden einzeln erkunden.
4.2.1 Balkengrafik
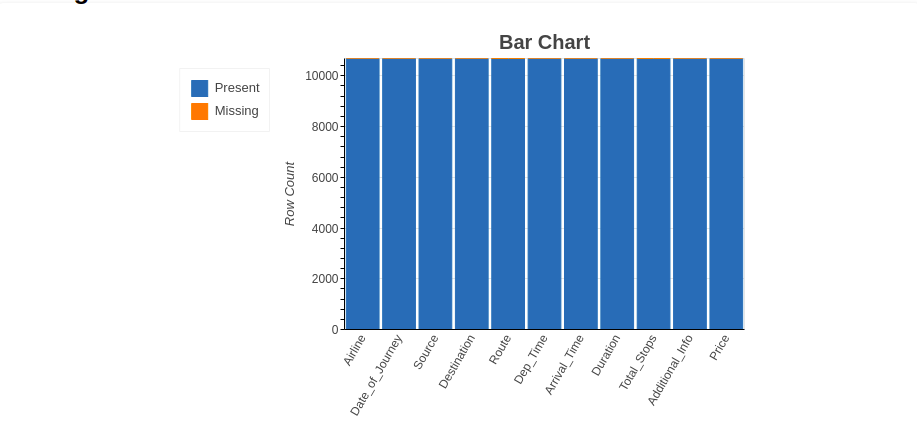
Die Balkendiagrammmethode zeigt die 'Anzahl der fehlenden und gegenwärtigen Werte'’ in jeder Variable in einer anderen Farbe.
4.2.2 Spektrum
Die Spektrummethode zeigt den Prozentsatz der fehlenden Werte in jeder Variablen an.
4.2.3 Heatmap
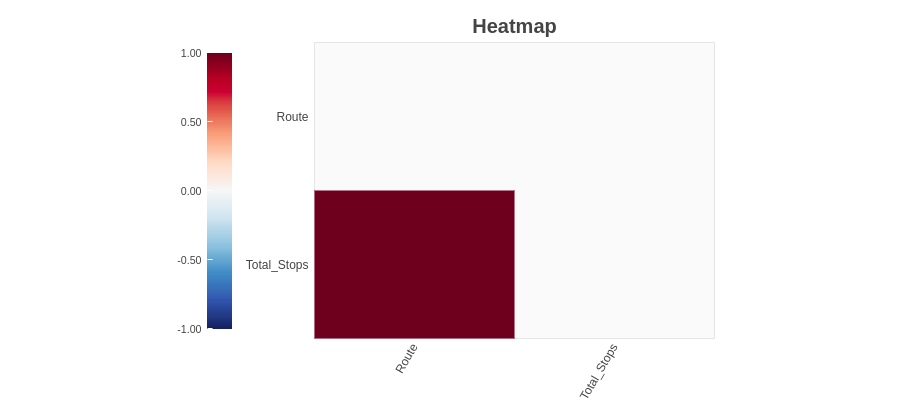
Die Heatmap-Methode zeigt die Variablen mit fehlenden Werten in Bezug auf die Korrelation. Seit ‘Route’’ und 'Total_Paradas’ sind stark korreliert, beide haben fehlende Werte.
Wie wir beobachten können, die 'Pfadvariablen’ und 'Total_Paradas’ haben fehlende Werte. Da wir bei der Spektrum-Balkendiagramm-Methode keine Informationen zu fehlenden Werten gefunden haben, aber wir finden fehlende Wertvariablen mit der Heatmap-Methode. Kombinieren dieser Informationen, Wir können sagen, dass die Variablen ‚Route‘’ und 'Total_Paradas’ haben fehlende Werte, sind aber sehr niedrig.
5. Datenaufbereitung
Bevor Sie mit der Datenvorbereitung beginnen, Schauen wir uns zuerst die Daten an.
dataframe.head()

Wie wir in der Datenanalyse gesehen haben, Es gibt 11 Variablen in den angegebenen Daten. Unten ist die Beschreibung jeder Variablen.
Fluggesellschaft: Name der Fluggesellschaft, mit der gereist wurde
Datum_der_Reise: Datum, an dem eine Person gereist ist
Quelle: Flugstartort
Bestimmung: Standort des Flugendes
Route: Enthält Informationen zum Start- und Zielort der Reise im Standardformat der Fluggesellschaften.
Dept_Time: Abflugzeit vom Startpunkt
Check-In: Ankunftszeit des Fluges am Zielort
Dauer: Flugdauer in Stunden / Protokoll
Total_Stops: Gesamtzahl der Zwischenlandungen des Fluges vor der Landung am Zielort.
Weitere Informationen: Zeigen Sie zusätzliche Informationen zu einem Flug an
Preis: Flugpreis
Einige Beobachtungen zu einigen der Variablen:
1. ‘Preis„Wird unsere abhängige Variable sein und alle verbleibenden Variablen können als unabhängige Variablen verwendet werden.
2. ‘Total_Stops'Kann verwendet werden, um festzustellen, ob der Flug direkt oder mit Anschluss war.
5.1 Umgang mit fehlenden Werten
Wie wir entdeckt haben, die 'Pfadvariablen’ und 'Total_Paradas’ haben sehr geringe fehlende Werte in den Daten. Sehen wir uns nun den Prozentsatz der fehlenden Werte in den Daten an.
(dataframe.isnull().Summe()/dataframe.shape[0])*100
Produktion :
Fluggesellschaft 0.000000 Datum_der_Reise 0.000000 Quelle 0.000000 Ziel 0.000000 Route 0.009361 Dept_Time 0.000000 Ankunftszeit 0.000000 Dauer 0.000000 Total_Stops 0.009361 Zusätzliche Information 0.000000 Preis 0.000000 dtyp: float64
Wie wir beobachten können, 'Route’ y 'Total_Stops’ sie haben beides 0.0094% von verlorenen Werten. In diesem Fall, es ist besser fehlende Werte zu entfernen.
dataframe.dropna(inplace= True) dataframe.isnull().Summe()
Produktion :
Fluggesellschaft 0 Datum_der_Reise 0 Quelle 0 Ziel 0 Route 0 Dept_Time 0 Ankunftszeit 0 Dauer 0 Total_Stops 0 Zusätzliche Information 0 Preis 0 dtyp: int64
Jetzt haben wir keinen Wertverlust.
5.2 Umgang mit Datums- und Uhrzeitvariablen
Tenemos 'Date_of_Journey', eine Variable vom Typ Datum und’ Abt_Zeit',’ Arrival_Time 'die Zeitinformationen erfasst.
Wir können "Journey_day" extrahieren’ und 'Journey_Month’ de la Variable 'Date_of_Journey'. “Reisetag” zeigt den Tag des Monats an, an dem die Reise begonnen hat.
Datenrahmen["Reise_Tag"] = pd.to_datetime(dataframe.Date_of_Journey, format="%d/%m/%Y").dt.Tag Datenrahmen["Reise_Monat"] = pd.to_datetime(Datenrahmen["Datum_der_Reise"], Format = "%d/%m/%Y").dt.Monat Datenrahmen.Tropfen(["Datum_der_Reise"], Achse = 1, inplace = wahr)
Ähnlich, wir können "Abfahrtszeit" extrahieren’ und „Abfahrtszeit“’ sowie „Ankunftszeit und Ankunftsminute“’ der Variablen ‚Time_dep.’ Und "Ankunftszeit"’ beziehungsweise.
Datenrahmen["Ab_Stunde"] = pd.to_datetime(Datenrahmen["Dept_Time"]).dt.Stunde Datenrahmen["Ab_min"] = pd.to_datetime(Datenrahmen["Dept_Time"]).dt.Minute Datenrahmen.Tropfen(["Dept_Time"], Achse = 1, inplace = wahr)
Datenrahmen["Ankunft_Stunde"] = pd.to_datetime(dataframe.Arrival_Time).dt.Stunde Datenrahmen["Ankunft_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.Minute Datenrahmen.Tropfen(["Ankunftszeit"], Achse = 1, inplace = wahr)
Wir haben auch Informationen über die Dauer der Variablen 'Dauer'. Diese Variable enthält kombinierte Informationen zu Stunden und Minuten der Dauer.
Wir können "Duration_hours" extrahieren’ und „Dauer_Minuten“’ getrennt von der Variablen 'Dauer'.
def get_duration(x):
x=x.split(' ')
Stunden=0
Minuten=0
wenn len(x)==1:
x=x[0]
wenn x[-1]=='h':
Stunden=int(x[:-1])
anders:
Minuten=int(x[:-1])
anders:
Stunden=int(x[0][:-1])
Minuten=int(x[1][:-1])
Rückgabezeiten,Minuten
Datenrahmen['Dauer_Stunden']=dataframe.Duration.apply(Lambda x:get_duration(x)[0])
Datenrahmen['Dauer_mins']=dataframe.Duration.apply(Lambda x:get_duration(x)[1])
dataframe.drop(["Dauer"], Achse = 1, inplace = wahr)
5.3 Kategoriales Datenhandling
Fluggesellschaft, Herkunft, Bestimmung, Route, Total_Stops, Zusätzliche Informationen sind die kategorialen Variablen, die wir in unseren Daten haben. Lass uns jeden einzeln behandeln.
Fluggesellschaft variabel
Sehen wir uns an, wie die Variable Fluggesellschaft mit der Variablen Price zusammenhängt.
Seegeboren als sns importieren
sns.set()
sns.catplot(y = "Preis", x = "Fluggesellschaft", data = train_data.sort_values("Preis", aufsteigend = falsch), Art="boxen", Höhe = 6, Aspekt = 3)
plt.zeigen()
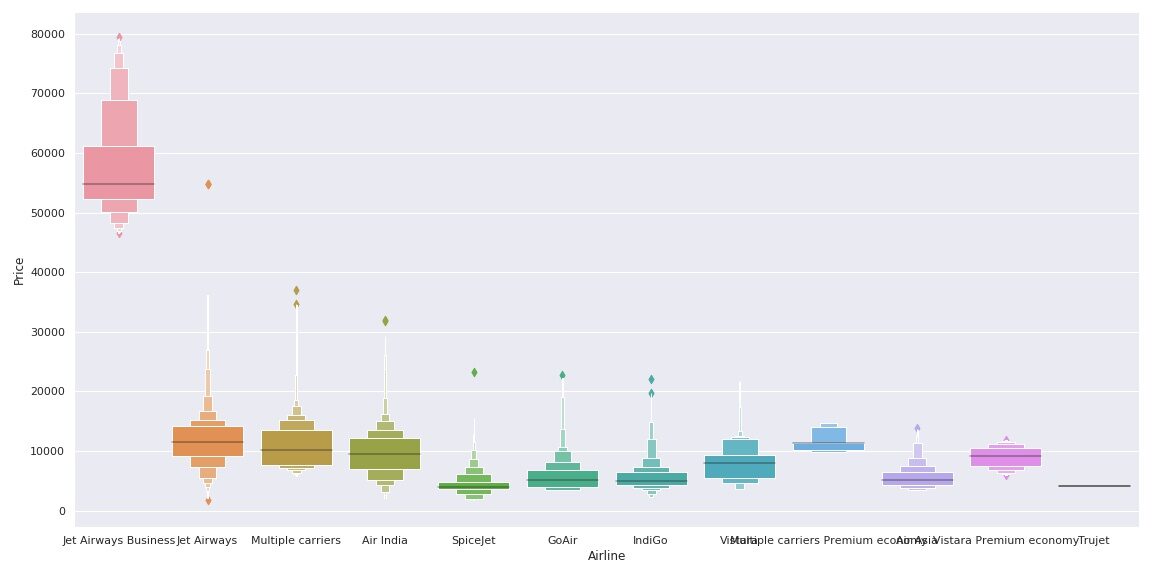
Wie wir sehen können, der Name der Fluggesellschaft ist wichtig. „JetAirways-Geschäft“’ hat die höchste Preisklasse. Der Preis anderer Fluggesellschaften variiert ebenfalls.
Von dem Fluggesellschaft variabel ist Nominale kategoriale Daten (Es gibt keinerlei Reihenfolge in den Namen der Fluggesellschaften) wir werden verwenden One-Hot-Codierung um diese Variable zu handhaben.
Fluggesellschaft = Datenrahmen[["Fluggesellschaft"]] Fluggesellschaft = pd.get_dummies(Fluggesellschaft, drop_first= True)
Die Daten von 'Airline’ codiert in One-Hot werden in der Variablen Airline gespeichert, wie im obigen Code gezeigt.
Quell- und Zielvariable
Nochmal, die 'Quellvariablen’ und „Ziel“’ sind nominale kategoriale Daten. Wir werden die One-Hot-Codierung erneut verwenden, um diese beiden Variablen zu verarbeiten.
Quelle = Datenrahmen[["Quelle"]] Quelle = pd.get_dummies(Quelle, drop_first= True) Ziel = train_data[["Ziel"]] Ziel = pd.get_dummies(Ziel, drop_first = Wahr)
Pfadvariable
Die Pfadvariable repräsentiert den Weg der Reise. Da die Variable ‚Total_Stops’ erfasst die Informationen, wenn der Flug direkt oder verbunden ist, Ich habe beschlossen, diese Variable zu eliminieren.
dataframe.drop(["Route", "Zusätzliche Information"], Achse = 1, inplace = wahr)
Total_Stops-Variable
Datenrahmen["Total_Stops"].einzigartig()
Produktion:
Array(['ununterbrochen', '2 Haltestellen', '1 Haltestelle', '3 Haltestellen', '4 Haltestellen'],
dtype=Objekt)
Hier, nonstop bedeutet 0 Waage, was Direktflug bedeutet. Ähnlich, die Bedeutung anderer Werte liegt auf der Hand. Wir können sehen, dass es ein Ordinale kategoriale Daten dann verwenden wir LabelEncoder hier um diese Variable zu handhaben.
Datenrahmen.ersetzen({"ununterbrochen": 0, "1 halt": 1, "2 stoppt": 2, "3 stoppt": 3, "4 stoppt": 4}, inplace = wahr)
Variable Additional_Info
dataframe.Additional_Info.unique()
Produktion:
Array(['Keine Informationen', 'Essen an Bord nicht inbegriffen',
'Kein aufzugebendes Gepäck inbegriffen', '1 Kurzer Zwischenstopp', 'Keine Informationen',
'1 langer Zwischenstopp', 'Flughäfen ändern', 'Business Class',
'Nachtflug', '2 langer Zwischenstopp'], dtype=Objekt)
Wie wir sehen können, Diese Funktion erfasst relevante Informationen, die den Flugpreis erheblich beeinflussen können. Auch die Werte „Keine Angaben“ werden wiederholt.. Lass uns das zuerst handhaben.
Datenrahmen['Zusätzliche Information'].ersetzen({"Keine Informationen": 'Keine Informationen'}, inplace = wahr)
jedoch, diese Variable sind auch nominale kategoriale Daten. Lassen Sie uns One-Hot Encoding verwenden, um diese Variable zu handhaben.
Add_info = Datenrahmen[["Zusätzliche Information"]] Add_info = pd.get_dummies(Zus. Info, drop_first = Wahr)
5.4 Endgültiger Datenrahmen
Jetzt erstellen wir den endgültigen Datenrahmen, indem wir alle Tag-codierten und One-Hot-Funktionen in den ursprünglichen Datenrahmen verketten. Wir werden auch die ursprünglichen Variablen entfernen, mit denen wir neue codierte Variablen vorbereitet haben.
dataframe = pd.concat([Datenrahmen, Fluggesellschaft, Quelle, Ziel,Zus. Info], Achse = 1) dataframe.drop(["Fluggesellschaft", "Quelle", "Ziel","Zusätzliche Information"], Achse = 1, inplace = wahr)
Sehen wir uns die Anzahl der endgültigen Variablen an, die wir im Datenrahmen haben.
dataframe.shape[1]
Produktion:
38
Dann, haben 38 Variablen im endgültigen Datenrahmen, einschließlich der abhängigen Variablen 'Preis'. Da ist nur 37 Variablen für das Training.
6. Modellbau
X=dataframe.drop('Preis',Achse=1)
y = Datenrahmen['Preis']
#Zug-Test-Split
aus sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, Ja, test_size = 0.2, random_state = 42)
6.1 Faule Vorhersage-App
Eines der Probleme bei der Modellierungsübung ist “So entscheiden Sie, welcher Algorithmus für maschinelles Lernen angewendet werden soll?”
Hier kommt Lazy Prediction ins Spiel.. Lazy Prediction ist eine in Python verfügbare Bibliothek für maschinelles Lernen, die uns schnell die Leistung mehrerer Standardklassifizierungen oder Regressionsmodelle auf mehreren Leistungsmatrizen bereitstellen kann..
Mal sehen wie es funktioniert...
Wie wir an einer Regressionsaufgabe arbeiten, Wir werden Regressor-Modelle verwenden.
von lazypredict.Überwachter Import LazyRegressor reg = LazyRegressor(ausführlich=0, ignore_warnings=Falsch, custom_metric=Keine) Modelle, Vorhersagen = reg.fit(x_train, x_test, y_train, y_test) modelle.kopf(10)
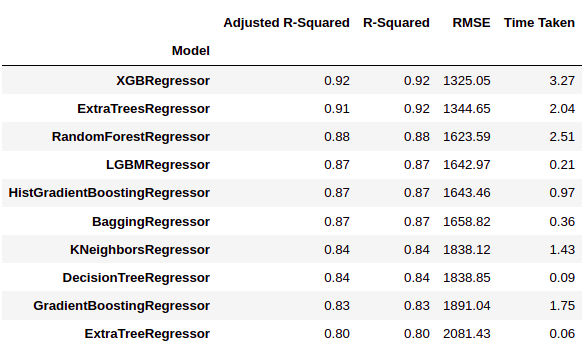
Wie wir sehen können, LazyPredict liefert uns Ergebnisse aus mehreren Modellen in mehreren Leistungsmatrizen. In der Abbildung oben, Wir haben die zehn besten Modelle gezeigt.
Hier 'XGBRegressor’ und 'ExtraTreesRegressor’ andere Modelle deutlich übertreffen. Es braucht viel Trainingszeit gegenüber anderen Modellen. In diesem Schritt können wir die Priorität wählen, wenn wir wollen “Wetter” Ö “Leistung”.
Wir haben uns entschieden zu wählen “Leistung” über die Trainingszeit. Also werden wir ‚XGBRegressor‘ trainieren und die Endergebnisse visualisieren.
6.2 Modelltraining
von xgboost importieren XGBRegressor Modell = XGBRegressor() model.fit(x_train,y_train)
Produktion:
XGBRegressor(base_score=0.5, Booster="gbtbaum", colsample_bylevel = 1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
Wichtigkeit_Typ="gewinnen", Interaktion_constraints="",
Lernrate=0.300000012, max_delta_step=0, max_tiefe=6,
min_child_weight=1, fehlt = nan, monotone_constraints="()",
n_Schätzer = 100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, Unterstichprobe=1,
tree_method='genau', valid_parameters=1, Ausführlichkeit=Keine)
Lassen Sie uns die Leistung des Modells überprüfen …
y_pred = model.predict(x_test)
drucken("Trainingsergebnis" :',Modell.Score(x_train, y_train))
drucken('Prüfungsergebnis :',Modell.Score(x_test, y_test))
Produktion:
Trainingsergebnis : 0.9680428701701702 Prüfungsergebnis : 0.918818721300552
Wie wir sehen können, die Modellnote ist ziemlich gut. Lassen Sie uns die Ergebnisse einiger Vorhersagen visualisieren.
Anzahl_der_Beobachtungen=50
x_ax = Reichweite(len(y_test[:Anzahl_der_Beobachtungen]))
plt.plot(x_ax, y_test[:Anzahl_der_Beobachtungen], Etikett="Original")
plt.plot(x_ax, y_pred[:Anzahl_der_Beobachtungen], Etikett="vorhergesagt")
plt.titel("Flugpreistest und vorhergesagte Daten")
plt.xlabel('Beobachtungsnummer')
plt.ylabel('Preis')
plt.legende()
plt.zeigen()
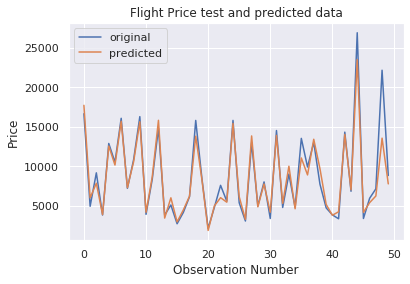
Wie wir in der vorherigen Abbildung sehen können, Modellvorhersagen und Originalpreise überschneiden sich. Dieses visuelle Ergebnis bestätigt die hohe Punktzahl des Modells, das wir zuvor gesehen haben.
7. Fazit
In diesem Artikel, Wir haben gesehen, wie man die Laze Prediction-Bibliothek anwendet, um den besten maschinellen Lernalgorithmus für die jeweilige Aufgabe auszuwählen.
Lazy Prediction spart Zeit und Mühe bei der Erstellung eines Modells für maschinelles Lernen, indem es Modellleistung und Trainingszeit bereitstellt. Je nach Situation kann man jede wählen.
Es kann auch verwendet werden, um eine Reihe von Modellen für maschinelles Lernen zu erstellen. Es gibt viele Möglichkeiten, die Funktionen der LazyPredict-Bibliothek zu verwenden.
Ich hoffe, dieser Artikel hat Ihnen geholfen, die Ansätze zur Datenanalyse zu verstehen, Datenaufbereitung und Modellierung viel einfacher.
Kontaktieren Sie den Kommentarbereich bei Fragen.
Danke und einen schönen Tag noch.. 🙂
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





