“So wie Sportler ohne eine ausgeklügelte Strategiekombination nicht gewinnen können, gestalten, Attitüde, Taktik und Geschwindigkeit, Performance Engineering erfordert eine gute Sammlung von Metriken und Tools, um die gewünschten Geschäftsergebnisse zu erzielen”.– Todd DeCapua
Einführung:
Über die Jahre, Die Einführung von maschinellem Lernen zur Unterstützung von Geschäftsentscheidungen hat exponentiell zugenommen. Laut Forbes, ML wird voraussichtlich wachsen auf $ 30.6 Milliarde für 2024 und es überrascht nicht, dass unzählige kundenspezifische ML-Lösungen auf den Markt kommen, die spezifische Geschäftsanforderungen erfüllen. Die einfache Verfügbarkeit von Rechenleistung, Cloud-Infrastruktur und Automatisierung hat es noch beschleunigt.
Der aktuelle Trend, die Möglichkeiten von ML in Unternehmen zu nutzen, hat Datenwissenschaftler und Ingenieure dazu veranlasst, Lösungen zu entwickeln / innovative Dienste und einer dieser Dienste war Model As A Service (MaaS). Wir haben viele dieser Dienste genutzt, ohne zu wissen, wie sie erstellt oder im Web bereitgestellt wurden, einige Beispiele umfassen Datenvisualisierung, Gesichtserkennung, Verarbeitung natürlicher Sprache, Predictive Analytics und mehr. Zusammenfassend, MaaS kapselt alle komplexen Daten, Modellschulung und -bewertung, Implementierung, etc., und ermöglicht es den Kunden, sie für ihren Zweck zu konsumieren.
So einfach es erscheinen mag, diese Dienste zu nutzen, Es gibt viele Herausforderungen bei der Erstellung eines solchen Dienstes, zum Beispiel: Wie pflegen wir den Service? Wie stellen wir sicher, dass die Genauigkeit unseres Modells mit der Zeit nicht abnimmt? etc. Wie bei jedem Dienst oder jeder Anwendung, Ein wichtiger zu berücksichtigender Faktor ist die Last oder der Verkehr, den ein Dienst / API kann damit umgehen, um Ihre Verfügbarkeit zu gewährleisten. Die beste Funktion der API ist eine hervorragende Leistung und die einzige Möglichkeit, dies zu testen, besteht darin, die API zu drücken, um zu sehen, wie sie reagiert. Das ist der Belastungstest.
In diesem Blog, Wir werden nicht nur sehen, wie dieser Service aufgebaut ist, aber auch wie man die Dienstlast testet, um die Hardwareanforderungen zu planen / Infrastruktur im Produktionsumfeld. Wir werden versuchen, dies in der folgenden Reihenfolge zu erreichen:
- Erstellen Sie eine einfache API mit FastAPI
- Erstellen Sie ein Klassifizierungsmodell in Python
- Wickeln Sie das Modell mit FastAPI
- Testen Sie die API mit dem Postman-Client
- Belastungstest mit Locust
Lasst uns beginnen !!
Erstellen einer einfachen Web-API mit FastAPI:
Der folgende Code zeigt die grundlegende FastAPI-Implementierung. Der Code wird verwendet, um eine einfache Web-API zu erstellen, die, nach Erhalt eines bestimmten Tickets, erzeugt eine bestimmte Ausgabe. Hier ist die Codeteilung:
- Laden Sie die Bibliotheken
- Erstellen Sie ein Anwendungsobjekt
- Erstellen Sie eine Route mit @ app.get ()
- Schreiben Sie eine Controller-Funktion mit einer definierten Host- und Portnummer
aus fastapi importieren FastAPI, Anfrage
von der Eingabe von Import-Dict
aus pydantic importieren BaseModel
uvicorn importieren
numpy als np importieren
Essiggurke importieren
Pandas als pd importieren
json importieren
app = FastAPI()
@app.get("/")
async def root():
Rückkehr {"Botschaft": "Gebaut mit FastAPI"}
if __name__ == '__main__':
uvicorn.run(App, Gastgeber="127.0.0.1", Port=8000)
Einmal ausgeführt, Sie können mit der URL zum Browser navigieren: http: // localhost: 8000 und beobachten Sie das Ergebnis, das in diesem Fall lautet: ‘ Gebaut mit FastAPI ‘
Erstellen einer API aus einem ML-Modell mit FastAPI:
Jetzt haben Sie eine klare Vorstellung von FastAPI, Sehen wir uns an, wie Sie ein Modell für maschinelles Lernen einschließen können (in Python entwickelt) in einer API in Python. Ich werde den Datensatz verwenden (Diagnose) Wisconsin-Brustkrebs. Das Ziel dieses ML-Projekts ist es, vorherzusagen, ob eine Person einen gutartigen oder bösartigen Tumor hat. ich werde benützen VSCode als mein Redakteur und beachten Sie, dass wir unseren Service mit testen werden Briefträger Klient. Dies sind die Schritte, die wir befolgen werden.
- Wir werden zuerst unser Klassifizierungsmodell erstellen: KNeighborsClassifier ()
- Erstellen Sie unsere Serverdatei, die eine Logik für die API im enthält FlashAPI Struktur.
- Schließlich, Wir werden unseren Service testen mit Briefträger
Paso 1: Klassifizierungsmodell
Ein einfaches Klassifizierungsmodell mit dem Standardprozess zum Laden von Daten, Daten in Zug aufteilen / nachweisen, gefolgt vom Erstellen des Modells und Speichern des Modells im Pickle-Format in der Einheit. Ich werde nicht auf die Details der Konstruktion des Modells eingehen, da es in dem Artikel um Lasttests geht.
Pandas als pd importieren
numpy als np importieren
aus sklearn.model_selection import train_test_split
von sklearn.neighbors importieren KNeighborsClassifier
Jobbibliothek importieren, Essiggurke
Importieren von OS
yaml importieren
# Ordner zum Laden der Konfigurationsdatei
CONFIG_PATH = "../Konfigurationen"
# Funktion zum Laden der Yaml-Konfigurationsdatei
def load_config(Konfigurationsname):
"""[Die Funktion nimmt die yaml-Konfigurationsdatei als Eingabe und lädt die Konfiguration]
Args:
Konfigurationsname ([jaml]): [Die Funktion nimmt die yaml-Konfiguration als Eingabe an]
Kehrt zurück:
[Schnur]: [Gibt die Konfiguration zurück]
"""
mit offen(os.path.join(CONFIG_PATH, Konfigurationsname)) als Datei:
config = yaml.safe_load(Datei)
Konfiguration zurückgeben
config = load_config("config.yaml")
#Pfad zum Datensatz
Dateiname = "../../Daten/Brustkrebs-wisconsin.csv"
#lade Daten
data = pd.read_csv(Dateiname)
#ersetzen "?" mit -99999
data = data.replace('?', -99999)
# ID-Spalte ablegen
data = data.drop(Konfiguration["drop_columns"], Achse=1)
# Definiere X (unabhängige Variablen) Andy (Zielvariable)
X = np.array(data.drop(Konfiguration["Zielname"], 1))
y = np.array(Daten[Konfiguration["Zielname"]])
X_Zug, X_test, y_train, y_test = train_test_split(
x, Ja, test_size=config["Testgröße"], random_state= config["random_state"]
)
# Rufen Sie unseren Klassifikator auf und passen Sie ihn an unsere Daten an
Klassifikator = KNeighborsClassifier(
n_neighbors=config["n_nachbarn"],
Gewichte=config["Gewichte"],
algorithm=config["Algorithmus"],
leaf_size=config["Blattgröße"],
p=config["P"],
metrisch=config["metrisch"],
n_jobs=config["n_jobs"],
)
# den Klassifikator trainieren
Klassifikator.fit(X_Zug, y_train)
# Testen Sie unseren Klassifikator
Ergebnis = Klassifikator.Score(X_test, y_test)
drucken("Genauigkeitswert ist. {:.1F}".Format(Ergebnis))
# Modell auf Festplatte speichern
pickle.dump(Klassifikator, offen('../../FastAPI//Models/KNN_model.pkl','wb'))
Den vollständigen Code erhalten Sie unter Github
Paso 2: kompilieren Sie die API mit FastAPI:
Wir werden auf dem grundlegenden Beispiel aufbauen, das wir in einem vorherigen Abschnitt gemacht haben.
Laden Sie die Bibliotheken:
aus fastapi importieren FastAPI, Anfrage von der Eingabe von Import-Dict aus pydantic importieren BaseModel uvicorn importieren numpy als np importieren Essiggurke importieren Pandas als pd importieren json importieren
Laden Sie das gespeicherte KNN-Modell und schreiben Sie eine Routing-Funktion, um das Json . zurückzugeben:
app = FastAPI()
@app.get("/")
async def root():
Rückkehr {"Botschaft": "Hallo Welt"}
# Laden Sie das Modell
# model = pickle.load(offen('../Models/KNN_model.pkl','rb'))
model = pickle.load(offen('../Models/KNN_model.pkl','rb'))
@app.post('/Vorhersagen')
auf jeden Fall(Karosserie: diktieren):
"""[Zusammenfassung]
Args:
Karosserie (diktieren): [Die Methode pred verwendet Response als Eingabe im Json-Format und gibt den vorhergesagten Wert aus dem gespeicherten Modell zurück.]
Kehrt zurück:
[Json]: [Die Funktion pred gibt den vorhergesagten Wert zurück]
"""
# Holen Sie sich die Daten aus der POST-Anfrage.
Daten = Körper
varListe = []
für val in data.values():
varList.append(val)
# Machen Sie eine Vorhersage aus dem gespeicherten Modell
Vorhersage = model.predict([varListe])
# Extrahiere den Wert
Ausgabe = Vorhersage[0]
#die Ausgabe im JSON-Format zurückgeben
Rückkehr {'Die Vorhersage ist': Ausgang}
# 5. Führen Sie die API mit uvicorn aus
# Läuft auf http://127.0.0.1:8000
if __name__ == '__main__':
"""[Die API wird auf dem localhost auf Port ausgeführt 8000]
"""
uvicorn.run(App, Gastgeber="127.0.0.1", Port=8000)
Den vollständigen Code erhalten Sie unter Github.
Verwenden des Postman-Clients:
In unserem vorherigen Abschnitt, Wir erstellen eine einfache API, in der das Drücken der http: // localhost: 8000 im Browser haben wir eine Ausgabenachricht bekommen “Gebaut mit FastAPI”. Dies ist in Ordnung, solange die Ausgabe einfacher ist und eine Benutzer- oder Systemeingabe erwartet wird. Aber wir bauen ein Modell als Service, bei dem wir Daten als Eingabe für die Vorhersage des Modells senden.. In diesem Fall, Wir werden einen besseren und einfacheren Weg brauchen, um es zu testen. wir werden verwenden Postbote um unsere API zu testen.
- Führen Sie die Datei server.py aus
- Öffnen Sie den Postman-Client, geben Sie die unten hervorgehobenen relevanten Details ein und klicken Sie auf die Schaltfläche "Senden"..
- Siehe das Ergebnis im Antwortabschnitt unten.
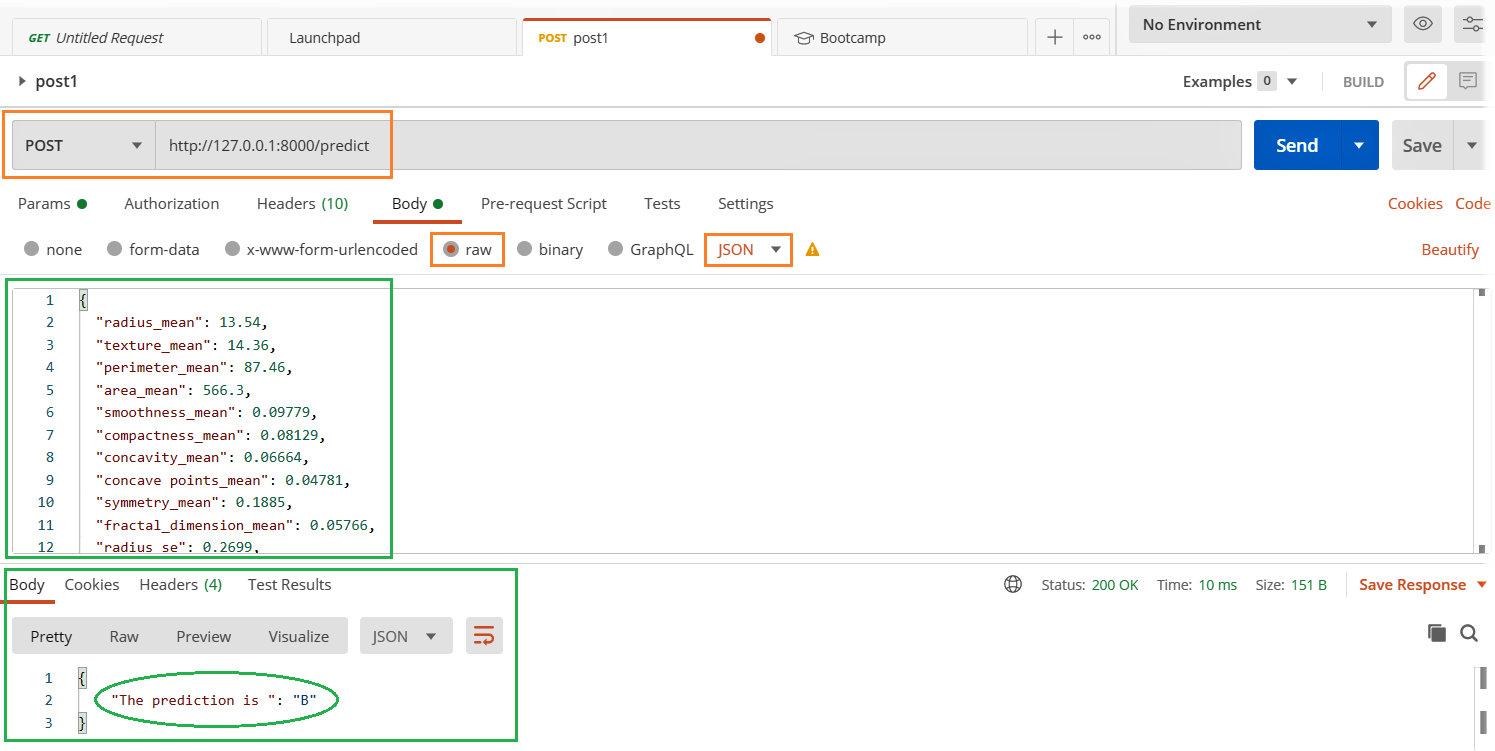
Sind Ihre Anwendungen und Dienste unter maximaler Last stabil?
Zeit für den Ladetest:
Wir werden die Locust-Bibliothek für Lasttests und den einfachsten Weg zur Installation erkunden Langosta es ist
pip installiere Heuschrecke
Lass uns eine erstellen perf.py Datei mit folgendem Code. Ich habe auf den Code verwiesen Schnellstart Hummer Seite
Importzeit
json importieren
aus Heuschreckenimport HttpUser, Aufgabe, zwischen
Klasse QuickstartUser(HttpUser):
Wartezeit = zwischen(1, 3)
@Aufgabe(1)
def testFlasche(selbst):
laden = {
"radius_mean": 13.54,
"textur_mean": 14.36,
......
......
"fractal_dimension_worst": 0.07259}
myheader = {'Inhaltstyp': 'anwendung/json', 'Annehmen': 'anwendung/json'}
self.client.post("/Vorhersagen", data= json.dumps(Belastung), headers=myheaders)
Greifen Sie auf die vollständige Codedatei von . zu Github
Hummer starten: Navigieren Sie zum Verzeichnis perfekt.py und führe den folgenden Code aus.
Heuschrecke -f perf.py
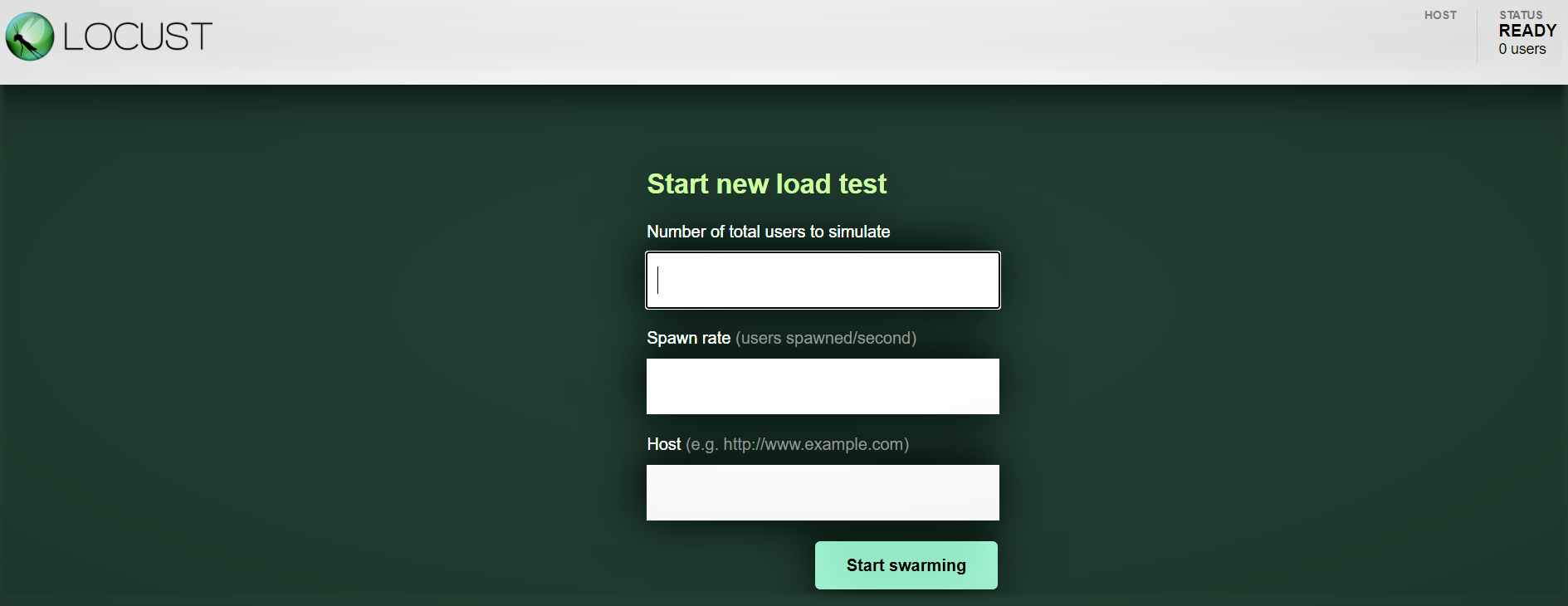
Interfaz-Web-Heuschrecke:
Sobald Sie Locust mit dem obigen Befehl gestartet haben, Navigieren Sie zu einem Browser und zeigen Sie ihn auf http: // localhost: 8089. Sie sollten die folgende Seite sehen:
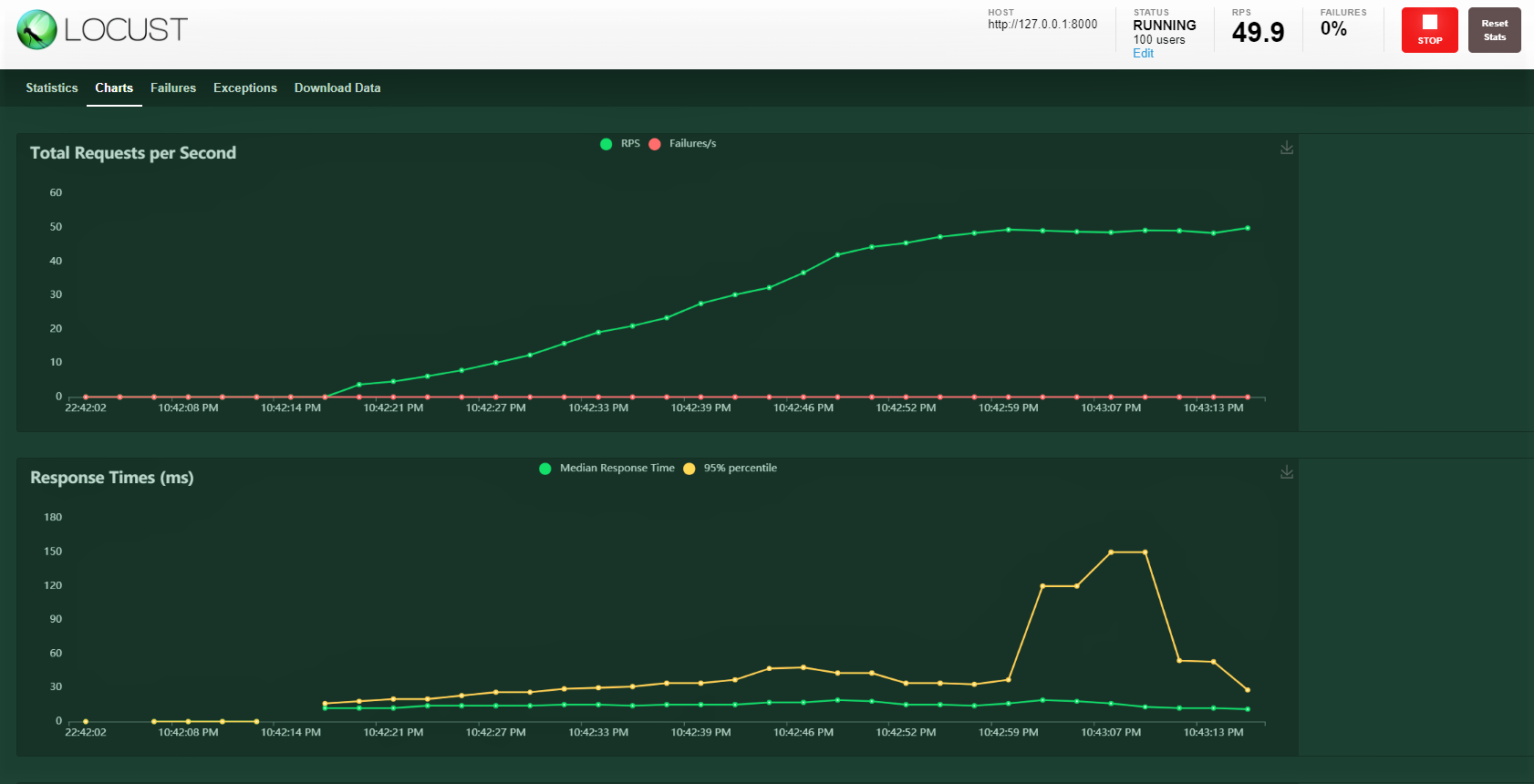
Versuchen wir es mit 100 Benutzer, Generationenverhältnis 3 Ihr Gastgeber: http: 127.0.0.1: 8000 wo unsere API läuft. Sie können den folgenden Bildschirm sehen. Sie können den Anstieg der Last im Laufe der Zeit und der Reaktionszeit sehen, eine grafische Darstellung zeigt die mittlere Zeit und andere Metriken.
Notiz: Stellen Sie sicher, dass server.py ausgeführt wird.

Fazit:
Wir behandeln viel in diesem Blog, vom Modellbau, Schließen mit einer FastAPI, der Dienstnachweis mit dem Postboten und schließlich die Durchführung eines Belastungstests mit 100 simulierte Benutzer, die mit einer allmählich ansteigenden Last auf unseren Dienst zugreifen. Wir konnten überwachen, wie der Dienst reagiert.
Meistens gibt es SLAs auf Unternehmensebene, die eingehalten werden müssen, nämlich, Halten Sie einen bestimmten Schwellenwert für eine Reaktionszeit wie 30 ms oder 20 ms ein. Wenn SLAs nicht eingehalten werden, es gibt potenzielle finanzielle Auswirkungen je nach Vertrag oder Verlust von Kunden, da sie den Service nicht schnell genug erhalten haben.
Ein Lasttest hilft uns, die maximalen und potenziellen Fehlerquellen zu verstehen. Später, wir können proaktive Maßnahmen planen, indem wir unsere Hardwarekapazität erhöhen und, wenn der Dienst im Kubernetes-Konfigurationstyp bereitgestellt wird, konfigurieren Sie es, um die Anzahl der Pods mit zunehmender Last zu erhöhen.
Viel Spaß beim Lernen !!!!
Du kannst dich mit mir verbinden – Linkedin
Sie können den Code als Referenz finden: Github
Verweise
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





