Die Welt der Objekterkennung
Ich liebe es, im Deep-Learning-Bereich zu arbeiten. Geradeheraus, ist ein weites Feld mit einer Fülle von Techniken und Frameworks zum Analysieren und Lernen. Und der wahre Nervenkitzel beim Erstellen von Computer Vision- und Deep-Learning-Modellen entsteht, wenn ich reale Anwendungen wie Gesichtserkennung und Balltracking im Cricket sehe., unter anderem.
Und eines meiner Lieblingskonzepte von Machine Vision und Deep Learning ist die Objekterkennung.. Die Fähigkeit, ein Modell zu bauen, das Bilder durchgehen und mir sagen kann, welche Objekte vorhanden sind, Es ist ein unbezahlbares Gefühl!

Wenn Menschen ein Bild betrachten, wir erkennen das interessierende Objekt in Sekundenschnelle. Bei Maschinen ist dies nicht der Fall. Deswegen, Objekterkennung ist ein Computer-Vision-Problem, um Instanzen von Objekten in einem Bild zu lokalisieren.
Das ist die gute Nachricht: Objekterkennungsanwendungen sind einfacher denn je zu entwickeln. Die aktuellen Ansätze von heute konzentrieren sich auf die End-to-End-Pipeline, die die Leistung erheblich verbessert und auch zur Entwicklung von Echtzeit-Anwendungsfällen beigetragen hat.
In diesem Artikel, Ich werde Sie durch die Erstellung eines Objekterkennungsmodells mit der beliebten TensorFlow-API führen. Wenn Sie ein Neuling im Bereich Deep Learning sind, Computer Vision und die Welt der Objekterkennung, Ich empfehle Ihnen, die folgenden Ressourcen zu konsultieren:
Inhaltsverzeichnis
- Ein allgemeiner Rahmen für die Objekterkennung
- Was ist eine API?? Warum brauchen wir eine API?
- TensorFlow-Objekterkennungs-API
Ein allgemeiner Rahmen für die Objekterkennung
Normalerweise, Wir befolgen drei Schritte beim Erstellen eines Objekterkennungs-Frameworks:
- Zuerst, ein Deep-Learning-Algorithmus oder ein Deep-Learning-Modell wird verwendet, um einen großen Satz von Begrenzungsrahmen zu generieren, die sich über das gesamte Bild erstrecken (nämlich, eine Objektfinder-Komponente)

- Dann, visuelle Merkmale werden für jede der Begrenzungsboxen extrahiert. Sie werden ausgewertet und anhand der visuellen Merkmale wird festgestellt, ob und welche Objekte in den Boxen vorhanden sind (nämlich, eine Objektklassifizierungskomponente)

- Im letzten Nachbearbeitungsschritt, überlappende Boxen werden zu einer einzigen Bounding Box kombiniert (nämlich, nicht maximale Unterdrückung)




Das ist es, Sie sind bereit mit Ihrem ersten Objekterkennungs-Framework!
Was ist eine API?? Warum brauchen wir eine API?
API steht für Application Programming Interface. Eine API bietet Entwicklern eine Reihe gängiger Operationen, damit sie keinen Code von Grund auf neu schreiben müssen.
Stellen Sie sich eine API wie ein Restaurantmenü vor, das eine Liste von Gerichten zusammen mit einer Beschreibung jedes Gerichts enthält. Wenn wir angeben, welches Gericht wir wollen, das Restaurant macht die Arbeit und versorgt uns mit fertigen Gerichten. Wir wissen nicht genau, wie das Restaurant dieses Essen zubereitet, und es ist wirklich nicht nötig.
Irgendwie, APIs sparen viel Zeit. Sie bieten den Benutzern in vielen Fällen auch Komfort. Denk darüber nach: Facebook-Nutzer (mich eingeschlossen!) Sie schätzen die Möglichkeit, sich mit ihrer Facebook-ID bei vielen Apps und Websites anzumelden. Wie denkst du funktioniert das? Verwenden der Facebook-APIs, Natürlich!
Dann, In diesem Artikel, Wir werden die TensorFlow-API sehen, die für die Objekterkennungsaufgabe entwickelt wurde.
TensorFlow-Objekterkennungs-API
Die TensorFlow Object Detection API ist das Framework zum Erstellen eines Deep-Learning-Netzwerks, das Objekterkennungsprobleme löst.
Es gibt bereits zuvor trainierte Modelle in ihrem Framework, das sie als Model Zoo bezeichnen. Dazu gehört eine Sammlung von zuvor trainierten Modellen, die mit dem COCO-Datensatz trainiert wurden., der KITTI-Datensatz und der offene Bilddatensatz. Diese Modelle können für Schlussfolgerungen verwendet werden, wenn wir nur an Kategorien in diesem Datensatz interessiert sind.
Sie sind auch nützlich, um Ihre Modelle beim Training mit dem neuen Datensatz zu initialisieren. Die verschiedenen Architekturen, die im vortrainierten Modell verwendet werden, werden in dieser Tabelle beschrieben:

MobileNet-SSD
Die SSD-Architektur ist ein einzigartiges Faltungsnetzwerk, das lernt, Bounding-Box-Positionen vorherzusagen und diese Positionen in einem einzigen Durchgang zu klassifizieren. Deswegen, SSD kann Ende-zu-Ende trainiert werden. Das SSD-Netzwerk besteht aus einer Basisarchitektur (MobileNet in diesem Fall) gefolgt von mehreren Faltungsschichten:

SSD arbeitet mit Feature Maps, um die Position von Begrenzungsrahmen zu erkennen. Erinnern: eine Feature-Map hat die Größe Df * Df * m. Für jeden Standort auf der Feature-Karte, k Bounding Boxes werden vorhergesagt. Jede Bounding Box enthält die folgenden Informationen:
- Begrenzungsrahmen 4 Ecken wieder gut machen Standorte (cx, cy, w, h)
- Wahrscheinlichkeiten der Klasse C (c1, c2,… cp)
SSD Nein die Form der Box vorhersagen, eher wo ist die kiste. Die k Bounding Boxes haben jeweils eine Standardform. Formulare werden vor dem eigentlichen Training festgelegt. Zum Beispiel, in der vorherigen Abbildung, Es gibt 4 casillas, was bedeutet k = 4.
Verlust auf MobileNet-SSD
Mit dem letzten Satz gepaarter Quadrate, So können wir den Verlust berechnen:
L = 1/N (L-Klasse + L-Box)
Hier, N ist die Gesamtzahl der gepaarten Boxen. Die Klasse L ist der Softmax-Verlust für die Klassifizierung und die 'Box L’ ist der weiche Verlust L1, der den Fehler der gepaarten Boxen darstellt. Der weiche Verlust von L1 ist eine Modifikation des Verlusts von L1, die robuster gegenüber Ausreißern ist. Für den Fall, dass N ist 0, Verlust ist auch eingestellt auf 0.
MobileNet
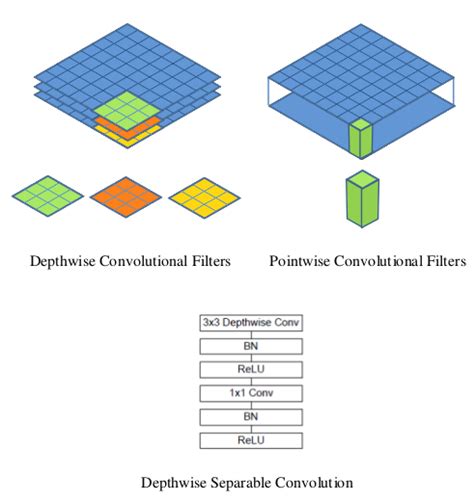
Das MobileNet-Modell basiert auf tiefenseparierbaren Faltungen, die eine Form von faktorisierten Faltungen sind. Diese zerlegen eine Standardfaltung in eine Tiefenfaltung und eine Faltung von 1 × 1 sogenannte Punktfaltung.
Für MobileNets, Tiefenfaltung wendet einen einzelnen Filter auf jeden Eingangskanal an. Punktfaltung wendet dann eine Faltung an 1 × 1 um die Ausgaben der Faltung in der Tiefe zu kombinieren.
Eine Standardfaltung filtert und kombiniert Eingaben in einem Schritt zu einem neuen Satz von Ausgaben. Tiefentrennbare Faltung teilt dies in zwei Schichten: eine separate Ebene zum Filtern und eine separate Ebene zum Kombinieren. Diese Faktorisierung hat den Effekt, die Berechnung und Größe des Modells drastisch zu reduzieren..
So laden Sie das Modell?
Im Folgenden finden Sie den Schritt-für-Schritt-Prozess in Google Colab, damit Sie die Objekterkennung einfach visualisieren können. Sie können auch dem Code folgen.
Installieren Sie das Modell
Stell sicher dass du hast pycocotools Eingerichtet:
Bekommen tensorflow/models Ö cd in das Hauptverzeichnis des Repositorys:
Protobufs erstellen und installieren Objekterkennung Paket:
Importieren Sie die erforderlichen Bibliotheken
Importieren Sie das Objekterkennungsmodul:
Modellvorbereitung
Ladegerät
Labelkarte wird geladen
Beschriften Sie Kartenindexkarten mit Kategorienamen, damit unser Faltungsnetzwerk Vorhersagen macht 5, lassen Sie uns wissen, dass dies einem Flugzeug entspricht:
Der Einfachheit halber, wir werden testen 2 Bilder:
Objekterkennungsmodell mit der TensorFlow-API
Laden Sie ein Objekterkennungsmodell:
Überprüfen Sie die Eingabesignatur des Modells (erwarten Sie eine Menge Bilder von 3 int8 typ farben):
Fügen Sie eine Wrapper-Funktion hinzu, um das Modell aufzurufen und die Ausgaben zu bereinigen:
Führen Sie es auf jedem Testbild aus und zeigen Sie die Ergebnisse an:
Unten ist das Beispielbild, das auf getestet wurde ssd_mobilenet_v1_coco (MobileNet-SSD aktiviert auf COCO-Datensatz):

Home-SSD
Die Architektur des Inception-SSD-Modells ähnelt der der vorherigen MobileNet-SSD. Der Unterschied besteht darin, dass die Basisarchitektur hier das Inception-Modell ist. Um mehr über das Heimnetzwerk zu erfahren, Gehe hier hin: Das Startup-Netzwerk von Grund auf verstehen.
So laden Sie das Modell?
Ändern Sie einfach den Modellnamen im Discovery-Teil der API:
Später, Machen Sie die Vorhersage, indem Sie die oben beschriebenen Schritte befolgen. Voilà!
Schneller RCNN
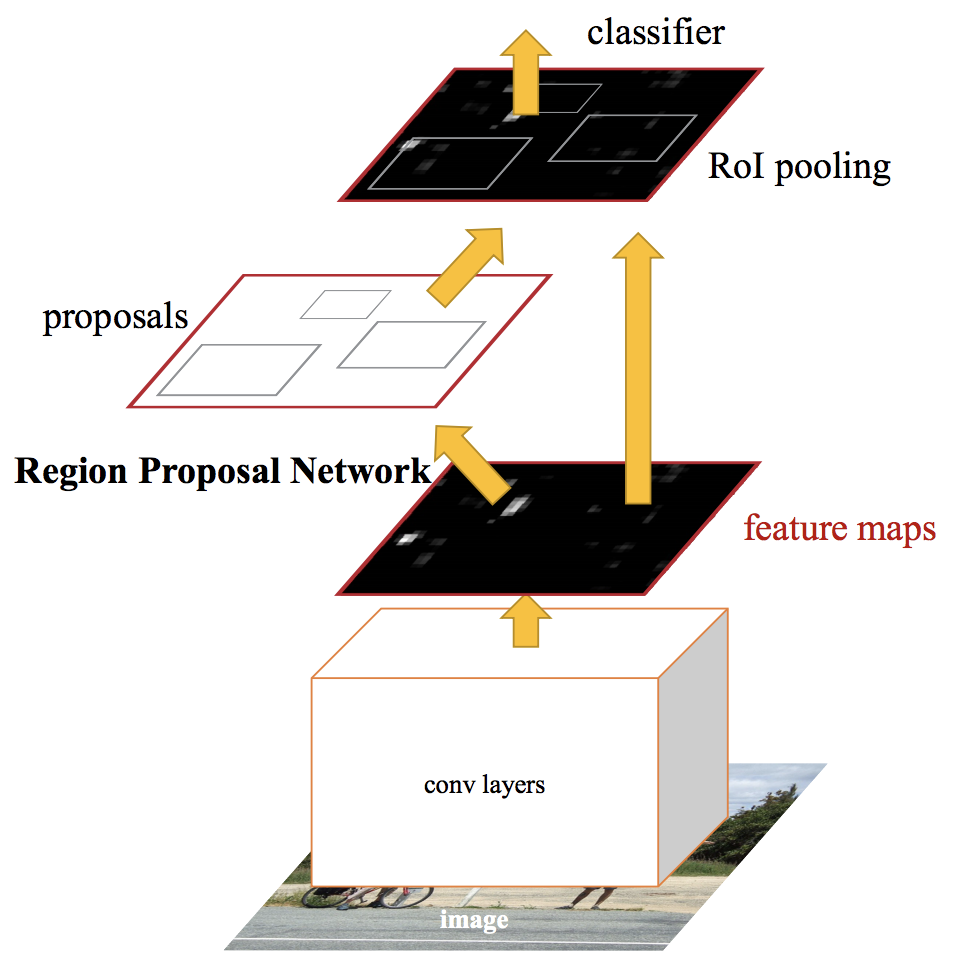
Hochmoderne Objekterkennungsnetzwerke stützen sich auf Regionsvorschlagsalgorithmen, um Hypothesen über die Position von Objekten zu formulieren. Fortschritte wie SPPnet und Fast R-CNN haben die Ausführungszeit dieser Erkennungsnetzwerke verkürzt, Entlarvung der Berechnung des Regionsvorschlags als Engpass.
Ein schnelleres RCNN, Wir speisen das Eingabebild in das neuronale Faltungsnetzwerk ein, um eine Karte der Faltungsmerkmale zu erstellen. Aus dem Faltungskennfeld, Wir identifizieren den Bereich der Vorschläge und verformen sie in Quadrate. Und bei Verwendung einer Gruppierungsebene von RoI (Region-of-Interest-Schicht), Wir formen sie in eine feste Größe um, damit sie in eine vollständig verbundene Ebene passen.
Aus dem Merkmalsvektor RoI, wir verwenden einen Softmax-Layer, um die Klasse der vorgeschlagenen Region und auch die Offset-Werte für die Bounding Box vorherzusagen.
Um mehr über Faster RCNN zu erfahren, Lies diesen tollen Artikel – Eine praktische Implementierung des Faster R-CNN-Algorithmus zur Objekterkennung (Teil 2 – mit Python-Codes).
So laden Sie das Modell?
Ändern Sie einfach den Modellnamen im Discovery-Teil der API erneut:
Später, Machen Sie die Vorhersage mit den gleichen Schritten, die wir zuvor befolgt haben. Unten ist das Beispielbild, wenn es einem schnelleren RCNN-Modell bereitgestellt wird:

Wie du siehst, das ist viel besser als das SSD-Mobilenet-Modell. Aber es kommt mit einem Kompromiss: es ist viel langsamer als das Vorgängermodell. Dies sind die Entscheidungen, die Sie treffen müssen, wenn Sie das richtige Objekterkennungsmodell für Ihr Deep-Learning- und Computer Vision-Projekt auswählen..
Welches Objekterkennungsmodell sollte ich wählen?
Je nach Ihren spezifischen Anforderungen, Sie können das richtige Modell aus der TensorFlow-API auswählen. Wenn wir ein Hochgeschwindigkeitsmodell wünschen, das bei der Erkennung der Videoübertragung mit hohen fps arbeiten kann, das Single-Shot-Detection-Netzwerk (SSD) funktioniert besser. Wie der Name schon sagt, SSD-Netzwerk bestimmt alle Bounding-Box-Wahrscheinlichkeiten auf einmal; deshalb, es ist ein viel schnelleres Modell.
Aber trotzdem, mit Einzelschusserkennung, Geschwindigkeit gewinnen auf Kosten der Präzision. Con FasterRCNN, wir erhalten hohe präzision, aber niedrige geschwindigkeit. Also erkunden und dabei, Sie werden feststellen, wie mächtig diese TensorFlow-API sein kann.





