Überblick
- Erfahre mehr über das Taggen von Stimmteilen (POS),
- Abhängigkeitsanalyse und Bezirksanalyse verstehen
Einführung
Sprachkenntnisse sind die Tür zur Weisheit.
– Roger Speck
Das hat mich erstaunt Roger Speck gab das obige Zitat im dreizehnten Jahrhundert, und es hält immer noch, Es ist nicht so? Da werden mir sicher alle zustimmen.
Heute, die Art, Sprachen zu verstehen, hat sich seit dem 13. Jahrhundert stark verändert. Wir bezeichnen es jetzt als Linguistik und natürliche Sprachverarbeitung. Aber seine Bedeutung hat nicht nachgelassen; jedoch, hat enorm zugenommen. Du weißt, warum? Denn es ist Anwendungen wurden erschossen und einer von ihnen ist der Grund, warum Sie auf diesem Artikel gelandet sind.

Jede dieser Anwendungen beinhaltet komplexe NLP-Techniken und, um sie zu verstehen, gute Kenntnisse der Grundlagen des NLP sind erforderlich. Deswegen, bevor Sie zu komplexen Themen übergehen, Es ist wichtig, die Grundlagen korrekt zu halten.
Aus diesem Grund habe ich diesen Artikel erstellt, in dem ich einige grundlegende NLP-Konzepte behandeln werde.: Beschriftung von Wortarten (POS), Abhängigkeitsanalyse und Bezirksanalyse in der Verarbeitung natürlicher Sprache. Wir werden diese Konzepte verstehen und auch in Python umsetzen. Lasst uns beginnen!
Inhaltsverzeichnis
- Wortart kennzeichnen (POS)
- Abhängigkeitsanalyse
- Analyse der Wahlkreise
Wortart kennzeichnen (POS)
In unserer Schulzeit, wir haben alle die Wortarten studiert, das beinhaltet Substantive, Pronomen, Adjektive, Verben, etc. Wörter, die zu verschiedenen Wortarten gehören, bilden einen Satz. Es ist wichtig, den Sprachteil der Wörter in einem Satz zu kennen, um ihn zu verstehen.
Aus diesem Grund ist das POS-Etikettierungskonzept entstanden.. Sie haben sicher schon erraten, was POS-Tagging ist. Auch so, lassen Sie mich erklären.
Wortart kennzeichnen (POS) ist der Vorgang, den Wörtern in einem Satz verschiedene Tags, die als POS-Tags bekannt sind, zuzuordnen, die uns über den Sprachteil des Wortes informieren.
Allgemein gesagt, Es gibt zwei Arten von POS-Tags:
1. Universelle POS-Tags: Diese Tags werden in universellen Abhängigkeiten verwendet (AUS) (Letzte Version 2), ein Projekt, das konsistente Baumbank-Annotationen über mehrere Sprachen hinweg für viele Sprachen entwickelt. Diese Tags basieren auf der Art der Wörter. Zum Beispiel, SUBSTANTIV (gängiges Substantiv), ANPASSEN (Adjektiv), ADV (Adverb).
Universelle POS-Etikettenliste
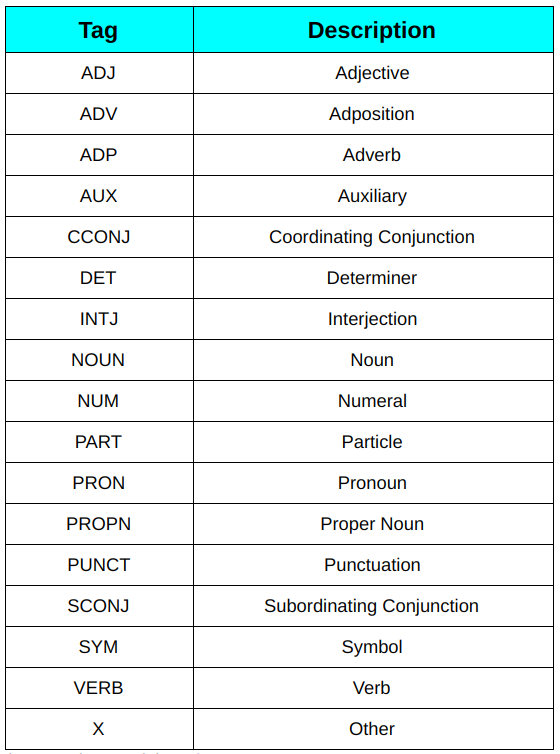
Sie können mehr über jeden von ihnen lesen hier.
2. Detaillierte POS-Etiketten: Diese Etiketten sind das Ergebnis der Aufteilung von universellen POS-Etiketten in mehrere Etiketten, wie NNS für Substantive im Plural und NN für Substantive im Singular im Vergleich zu NOUN für Substantive im Englischen. Diese Tags sind sprachspezifisch. Sie können sich die vollständige Liste ansehen hier.
Jetzt wissen Sie, was Point-of-Sale-Etiketten sind und was Point-of-Sale-Etikettierung ist. Dann, Schreiben wir den Python-Code für die POS-Tagging-Sätze. Für diesen Zweck, Ich habe hier Spacy verwendet, aber es gibt andere Bibliotheken wie NLTK Ja Strophe, die auch verwendet werden kann, um das gleiche zu tun.

Im obigen Codebeispiel, Ich habe den Speicherplatz geladen de_web_core_sm Modell und verwendet es, um die POS-Tags zu erhalten. Sie können sehen, dass die pos_ gibt universelle POS-Tags zurück, Ja Etikett_ gibt detaillierte POS-Tags für die Wörter im Satz zurück.
Abhängigkeitsanalyse
Die Abhängigkeitsanalyse ist der Prozess der Analyse der grammatikalischen Struktur eines Satzes basierend auf den Abhängigkeiten zwischen den Wörtern in einem Satz.
In Abhängigkeitsanalyse, mehrere Labels repräsentieren die Beziehung zwischen zwei Wörtern in einem Satz. Diese Tags sind die Abhängigkeits-Tags. Zum Beispiel, im Satz “Regenzeit”, das Wort regnerisch die Bedeutung des Substantivs ändern Klima. Deswegen, es gibt eine Abhängigkeit vom Klima -> regnerisch, in dem die Klima verhalte dich wie er Kopf und das regnerisch fungiert als abhängig Ö Kind. Diese Abhängigkeit wird repräsentiert durch Zustand Schild, was den Adjektivmodifikator darstellt.
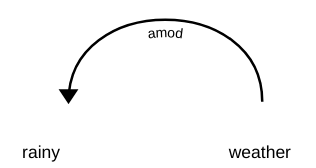
Ähnlich, Es gibt viele Abhängigkeiten zwischen Wörtern in einem Satz, Beachten Sie jedoch, dass eine Abhängigkeit nur aus zwei Wörtern besteht, von denen eines als Kopf und das andere als Kind fungiert. Im Folgenden, Es gibt 37 Universelle Abhängigkeitsbeziehungen, die in universeller Abhängigkeit verwendet werden (Ausführung 2). Du kannst sie alle anschauen hier. Abgesehen von diesen, es gibt auch viele sprachspezifische Tags.
Jetzt verwenden wir Spacy und finden die Abhängigkeiten in einem Satz.

Im obigen Codebeispiel, das ab_ gibt das Abhängigkeits-Tag eines Wortes zurück und Textkopf gibt die jeweiligen . zurück Kopf Wort. Wenn du es bemerkt hast, im Bild oben, das Wort ich nehme hat ein Abhängigkeits-Tag von WURZEL. Dieses Tag wird dem Wort zugewiesen, das als Überschrift für viele Wörter in einem Satz dient, aber es ist nicht die Tochter eines anderen Wortes. Allgemein, ist das Hauptverb des Satzes ähnlich wie ‘tok’ in diesem Fall.
Jetzt wissen Sie, welche Abhängigkeits-Tags und welches Hauptwort, Sekundär und Wurzel sind. Aber bedeutet Parsing nicht, einen Parsing-Baum zu generieren?
Jawohl, Wir generieren den Baum hier, aber wir visualisieren es nicht. Der durch die Abhängigkeitsanalyse erzeugte Baum wird als Abhängigkeitsbaum bezeichnet. Es gibt mehrere Möglichkeiten, es zu visualisieren, aber der Einfachheit halber, wir werden verwenden VERSCHIEBUNG die verwendet wird, um die Abhängigkeitsanalyse anzuzeigen.

Im Bild oben, die Pfeile stellen die Abhängigkeit zwischen zwei Wörtern dar, in denen das Wort an der Spitze des Pfeils das Kind ist und das Wort am Ende des Pfeils der Kopf ist. Das Wurzelwort kann als Überschrift für mehrere Wörter in einem Satz fungieren, aber es ist nicht die Tochter eines anderen Wortes. Sie können oben sehen, dass das Wort "nahm"’ hat mehrere ausgehende Pfeile, aber keine eingehenden. Deswegen, ist die Wurzel des Wortes. Eine interessante Sache am Wurzelwort ist, dass, wenn Sie anfangen, die Abhängigkeiten in einem Satz zu verfolgen, kann zum Wurzelwort kommen, egal mit welchem wort es beginnt.
Jetzt, da Sie sich mit der Abhängigkeitsanalyse auskennen, Lernen wir eine andere Art von Analyse kennen, die als Konstituentenanalyse bekannt ist.
Analyse der Wahlkreise
Konstituentenanalyse ist der Prozess der Analyse von Sätzen, indem sie in Teilphrasen, auch Konstituenten genannt, unterteilt werden.. Diese Subphrasen gehören zu einer bestimmten Kategorie der Grammatik wie NP (Nominalphrase) der VP (verbale Phrase).
Lassen Sie uns mit Hilfe eines Beispiels verstehen. Angenommen, ich habe den gleichen Satz, den ich in den vorherigen Beispielen verwendet habe, nämlich, “Ich habe mehr als zwei Stunden gebraucht, um einige Seiten aus dem Englischen zu übersetzen”. und ich habe eine Wahlkreisanalyse dazu durchgeführt. Dann, der konstituierende Parsing-Baum für diesen Satz ist gegeben durch:
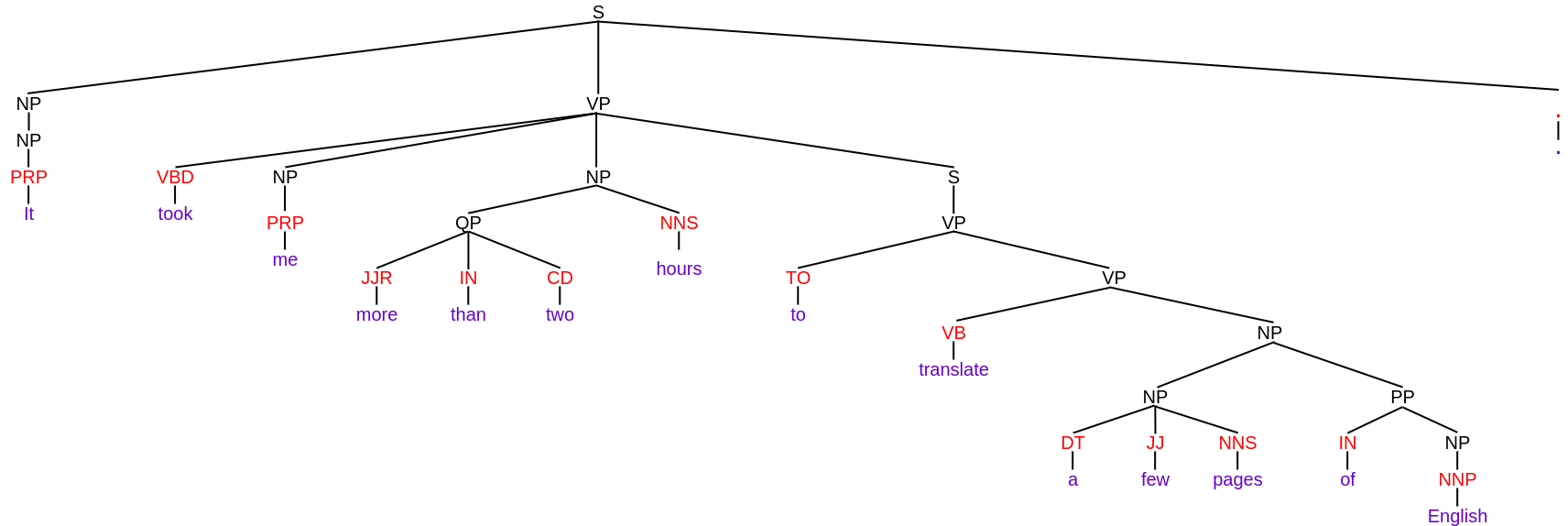
Im Baum oben, die Wörter des Satzes sind lila und die POS-Tags sind rot geschrieben. Außer diesen, alles ist schwarz geschrieben, was die Komponenten darstellt. Man sieht deutlich, wie sich der ganze Satz in Unterphrasen aufteilt, bis nur noch die Wörter in den Terminals stehen. Was ist mehr, Es gibt verschiedene Labels, um Komponenten zu kennzeichnen wie
- VP für Verbphrase
- NP für Nominalphrasen
Dies sind die konstituierenden Labels. Sie können sich über verschiedene Etiketten für die Bestandteile informieren hier.
Jetzt wissen Sie, was Wahlkreisanalyse ist, also ist es an der zeit in python zu codieren. Jetzt, spaCy bietet keine offizielle API für die Inhaltsstoffanalyse. Deswegen, wir werden die benutzen Berkeley-Neuralanalysator. Es ist eine Python-Implementierung von Parsern basierend auf Wahlkreisanalyse mit einem aufmerksamen Kodierer von ACL 2018.
Sie können zu diesem Zweck auch StanfordParser mit Stanza oder NLTK verwenden, aber hier habe ich Berkely Neural Parser verwendet. Um dies zu verwenden, Wir müssen es zuerst installieren. Sie können dies tun, indem Sie den folgenden Befehl ausführen.
!pip installieren
Dann musst du die herunterladen benerpar_de2 Modell.
Sie haben vielleicht bemerkt, dass ich hier TensorFlow 1.x verwende, weil derzeit, benepar ist nicht kompatibel mit TensorFlow 2.0. Jetzt ist es an der Zeit, Wahlkreise zu analysieren.

Hier, _.parse_string generiert den Parse-Baum als String.
Abschließende Anmerkungen
Jetzt, Sie wissen bereits, was POS-Etikettierung ist, Abhängigkeitsanalyse und Konstituentenanalyse und wie sie Ihnen helfen, Textdaten zu verstehen, nämlich, POS-Tags informieren Sie über den grammatikalischen Teil von Wörtern in einem Satz, Die Abhängigkeitsanalyse informiert Sie über die Abhängigkeiten zwischen den Wörtern in einem Satz und die Konstituentenanalyse informiert Sie über die Subphrasen oder Konstituenten eines Satzes. Sie sind nun bereit, zu komplexeren Teilen des NLP überzugehen.. Als nächste Schritte, Sie können die folgenden Artikel zur Informationsextraktion lesen.
In diesen Artikeln, Sie lernen, wie Sie POS-Tags und Abhängigkeits-Tags verwenden, um Informationen aus dem Korpus zu extrahieren. Was ist mehr, für weitere Informationen zu spaCy, Sie können diesen Artikel lesen: SpaCy-Tutorial zum Erlernen und Beherrschen der Verarbeitung natürlicher Sprache (PNL) Abgesehen von diesen, wenn Sie die Verarbeitung natürlicher Sprache durch einen Kurs erlernen möchten, Folgendes kann ich empfehlen das beinhaltet alles, von Projekten bis hin zu individuellen Tutorials:
Wenn Sie diesen Artikel informativ fanden, teile es mit deinen Freunden. Was ist mehr, Sie können unten Ihre Fragen kommentieren.





