Einführung
Schätztheorie Ja Hypothesentest sind die sehr wichtigen Konzepte der Statistik, die weit verbreitet sind von Statistiken, Ingenieure für maschinelles Lernen, Ja Datenwissenschaftler.
Dann, in diesem Beitrag, werden wir Punktschätzer in der Schätztheorie der Statistik diskutieren.
Inhaltsverzeichnis
1. Schätzer und Schätzer
2. Was sind Punktschätzer??
3. Was ist die Zufallsstichprobe und Statistik??
4. Zwei häufig verwendete Statistiken:
- Durchschnittliche Stichprobe
- Stichprobenabweichung
5. Eigenschaften von Punktschätzern
- Unparteilichkeit
- Effizient
- Konsistent
- Genug
6. Gemeinsame Methoden zum Auffinden von Punktschätzungen
7. Punktschätzung vs. Intervallschätzung
Schätzung und Schätzer
Sei X eine Zufallsvariable mit Verteilung Fx(x; θ), wobei θ ein unbekannter Parameter ist. Eine Zufallsstichprobe, x1, x2, –, xNorden, der Größe n genommen bei X.
Das Problem der Punktschätzung besteht in der Auswahl einer Statistik, g (x1, x2, —, xNorden), die den Parameter θ . am besten schätzt.
Einmal beobachtet, der Zahlenwert von g (x1, x2, —, xNorden) es heißt Schätzung und Statistik g (x1, x2, —, xNorden) es heißt Schätzer.
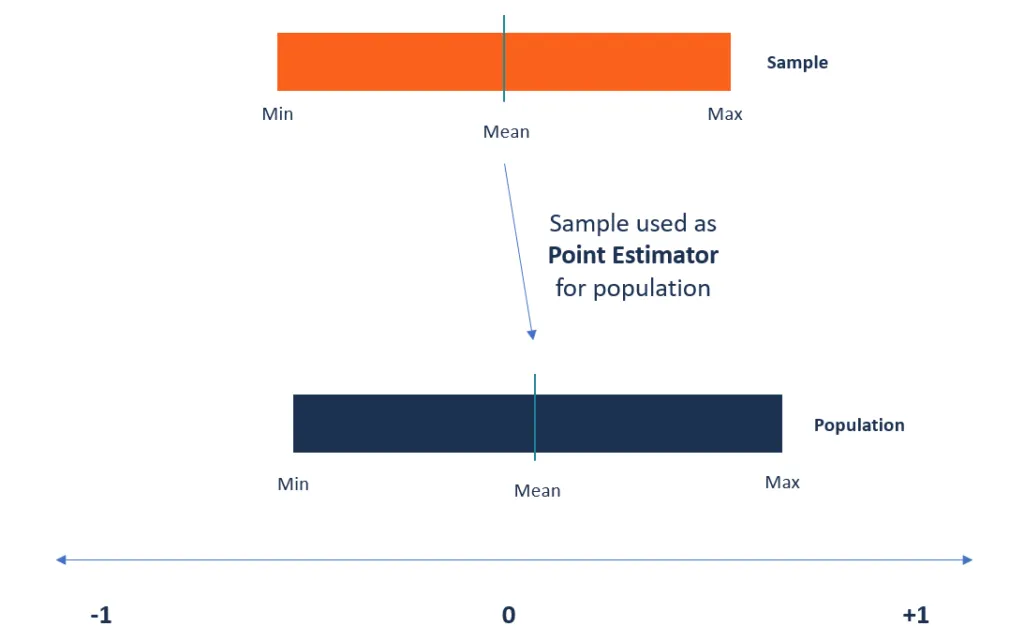
Was sind Punktschätzer??
Punktschätzer sind als Funktionen definiert, die verwendet werden, um einen Näherungswert eines Populationsparameters aus Zufallsstichproben der Population zu finden.. Sie verwenden Stichprobendaten einer Population, um eine Punktschätzung oder Statistik zu erstellen, die als beste Schätzung eines unbekannten Parameters einer Population dient.
Bildquelle: Google Bilder
Sehr oft, vorhandene Methoden zur Ermittlung der Parameter großer Populationen sind unrealistisch.
Als Beispiel, wenn wir die durchschnittliche Körpergröße der Teilnehmer einer Konferenz ermitteln möchten, Es wird unmöglich sein, die genaue Höhe aller Konferenzstädte der Welt zu ermitteln. jedoch, ein Statistiker kann den Punktschätzer verwenden, um den Populationsparameter zu schätzen.
Zufallsstichprobe und Statistik
Aleatorische Probe: Eine Menge von IID (unabhängig und identisch verteilt) zufällige Variablen, x1, x2, x3, —, xNorden im gleichen Stichprobenraum aufgestellt wird, heißt Zufallsstichprobe der Größe n.
Statistiken: Eine Funktion einer Zufallsstichprobe heißt Statistik (wenn nicht von einer unbekannten Entität abhängig)
Als Beispiel, x1+ x2+ —— + xNorden, x12x2+ eX3, x1– xNorden
Stichprobenmittelwert und Stichprobenvarianz
Zwei wichtige Statistiken:
Lass x1, x2, x3, —, xNorden eine Zufallsstichprobe sein, dann:
Der Stichprobenmittelwert wird bezeichnet mit x, und die Stichprobenvarianz wird mit bezeichnet S2
Hier x̄ y2 sie heißen die Beispielparameter.
Populationsparameter sind durch . gekennzeichnet:
σ2 = Populationsvarianz und µ = Populationsmittelwert

Feige. Grundgesamtheit und Stichprobenmittelwert
Bildquelle: Google Bilder

Feige. Stichprobenpopulation und Varianz
Bildquelle: Google Bilder
Eigenschaften des Stichprobenmittels:
E (x) = 1 / n (Σ E (xich)) = 1 / n (nµ) = µ
Woher (x) = 1 / n2(Var (xich)) = 1 / n2 (n2) =2/Norden
Merkmale der Stichprobenvarianz:
S2 = 1 / (n-1) (Σ (xich– x )2 ) = 1 / (n-1) (xich2 – 2x̄ Σ xich + nx̄2 ) = 1 / (n-1) (xich2 – nx̄2 )
Jetzt, Nehmen wir die Erwartung von beiden Seiten, wir erhalten:
E (S2) = 1 / (n-1) (Σ E (xich2) – weder (x2)) = 1 / (n-1) (Σ (µ2+ σ2) – n (µ2+ σ2/ n)) = 1 / (n-1) ((n-1) σ2) =2.
Eigenschaften von Punktschätzern
In einem beliebigen Schätzproblem, wir können eine unendliche Klasse geeigneter Schätzer zur Auswahl haben. Das Problem ist, einen Schätzer zu finden g (x1, x2, —, xNorden), für einen unbekannten Parameter θ oder seine Funktion Ψ (θ), das hat eigenschaften “nett”.
Im Wesentlichen, wir möchten, dass der Schätzer g „nahe“ bei Ψ . ist.
Im Folgenden sind die wichtigsten Eigenschaften von Punktschätzern aufgeführt:
1. Unparteilichkeit:
Lassen Sie uns zuerst die Bedeutung des Begriffs verstehen “Voreingenommenheit”
Die Differenz zwischen dem erwarteten Wert des Schätzers und dem Wert des geschätzten Parameters wird als Bias eines Punktschätzers bezeichnet..
Deswegen, der Schätzer gilt als unverzerrt, wenn der geschätzte Wert des Parameters und der Wert des geschätzten Parameters gleich sind.
Zur selben Zeit, je näher der erwartete Wert eines Parameters am Wert des gemessenen Parameters liegt, je niedriger der Bias-Wert.
Mathematisch,
Ein Schätzer g (x1, x2, —, xNorden) heißt ein unverzerrter Schätzer von θ if
E (g (x1, x2, —, xNorden)) =
Mit anderen Worten, im Durchschnitt, wir erwarten, dass g nahe am wahren Parameter liegt θ. Wir haben gesehen, dass wenn X1, x2, —, xNorden sei eine Zufallsstichprobe aus einer Grundgesamtheit mit Mittelwert µ und Varianz σ2, nach
E (x) = µ y E (S2) =2
Deswegen, x̄ und s2 sind unverzerrte Schätzer für µ und σ2
2. Effizient:
Der effizienteste Punktschätzer ist der mit der kleinsten Varianz aller unverzerrten und konsistenten Schätzer.. Die Varianz stellt den Streuungsgrad der Schätzung dar, und die kleinste Varianz sollte von Stichprobe zu Stichprobe weniger variieren.
Allgemein, die Effizienz des Schätzers hängt von der Populationsverteilung ab.
Mathematisch,
Ein Schätzer Gramm1(x1, x2, —, xNorden) ist effizienter als Gramm2(x1, x2, —, xNorden), für θ ja
Woher (g1(x1, x2, —, xNorden)) <= Var (g2(x1, x2, —, xNorden))
3. Konsistent:
Konsistenz beschreibt, wie nahe der Punktschätzer am Parameterwert bleibt, wenn er größer wird.. Um es konsistenter und genauer zu machen, der Punktschätzer benötigt eine große Stichprobengröße.
Wir können auch überprüfen, ob ein Punktschätzer konsistent ist, indem wir seinen jeweiligen Erwartungswert und seine Varianz beobachten.
Damit der Punktschätzer konsistent ist, der erwartete Wert sollte sich dem tatsächlichen Wert des Parameters annähern.
Mathematisch,
Lass g1, g2, g3, ——- eine Folge von Schätzern sein, die Folge heißt konsistent, wenn sie mit Wahrscheinlichkeit gegen θ konvergiert, Mit anderen Worten,
P (| gMetro(x1, x2, —, xNorden) – θ | >) -> 0 wenn m-> ∞
Wenn X1, x2, —, xNorden ist eine Folge von Zufallsvariablen IID mit E (xich) = µ, später von WLLN (Schwaches Gesetz der großen Zahlen):
xNorden‘—–> µ Wahrscheinlichkeit
Wo XNorden„Ist der Mittelwert von X1, x2, x3, —, xNorden
4. Genug:
Seien Sie eine Probe von X ~ f (x; θ). Und Y = g (x1, x2, —, xNorden) ist eine Statistik, so dass für jede andere Statistik Z = h (x1, x2, —, xNorden), die bedingte Verteilung von Z, da Y = y nicht von θ abhängt, dann heißt Y ausreichende Statistik für θ.
Gemeinsame Methoden zum Auffinden von Punktschätzungen
Beim Punktschätzungsverfahren wird der Wert einer mit Hilfe von Stichprobendaten gewonnenen Statistik verwendet, um die beste Schätzung des jeweiligen unbekannten Parameters der Grundgesamtheit zu ermitteln.. Zur Berechnung bzw. Bestimmung der Punktschätzer können verschiedene Methoden verwendet werden, und jede Technik hat andere Eigenschaften. Einige der Methoden sind wie folgt:
1. Methode der Momente (MAMA)
Es beginnt mit der Betrachtung aller bekannten Fakten über eine Population und wendet diese Fakten dann auf eine Stichprobe der Population an.. Zuerst, leitet Gleichungen ab, die die Besetzungsmomente mit den unbekannten Parametern in Beziehung setzen.
Der nächste Schritt besteht darin, eine Stichprobe aus der Population zu extrahieren, die verwendet wird, um die Populationsmomente zu schätzen. Die in Schritt eins erzeugten Gleichungen werden dann mit Hilfe des Stichprobenmittels der Populationsmomente gelöst. Dies ergibt die beste Schätzung der unbekannten Populationsparameter.
Mathematisch,
Betrachten Sie ein Beispiel X1, x2, x3, —, xNorden von F (x; θ1, θ2, —–, θMetro) .Ziel ist es, die Parameter θ1, θ2, —–, θMetro.
Lass die Bevölkerungsmomente sein (Theoretiker) ein1, ein2, ——–, einR, das sind Funktionen unbekannter Parameter θ1, θ2, —–, θMetro.
Durch Gleichsetzen der Stichprobenmomente und der Populationsmomente, wir erhalten die Schätzer von θ1, θ2, —–, θMetro.
2. Maximum-Likelihood-Schätzer (MLE)
Diese Methode zum Auffinden von Punktschätzern versucht, die unbekannten Parameter zu finden, die die Likelihood-Funktion maximieren. Nehmen Sie ein bekanntes Modell und verwenden Sie die Werte, um Datensätze zu vergleichen und die beste Übereinstimmung für die Daten zu finden.
Mathematisch,
Betrachten Sie ein Beispiel X1, x2, x3, —, xNorden aus (x; θ). Ziel ist es, die Parameter θ (Skalar oder Vektor).
Die Likelihood-Funktion wird gesetzt als:
L (θ; x1, x2, —, xNorden) = f (x1, x2, —, xNorden; θ)
Ein MLE von θ ist der Wert θ ‘(eine Beispielfunktion) was die Likelihoodfunktion maximiert
Ist L eine differenzierbare Funktion von θ, dann wird die nächste Likelihood-Gleichung verwendet, um den MLE . zu erhalten (θ ‘):
D / dθ (ln (L (θ; x1, x2, —, xNorden) = 0
Wenn θ ein Vektor . ist, dann wird angenommen, dass die partiellen Ableitungen die Likelihood-Gleichungen erhalten.
Punktschätzung vs. Intervallschätzung
Einfach, Es gibt zwei Haupttypen von Schätzern in der Statistik:
- Punktschätzer
- Intervallschätzer
Punktschätzung ist das Gegenteil von Intervallschätzung.
Punktschätzung erzeugt einen einzigartigen Wert, während die Intervallschätzung eine Reihe von Werten generiert.
Ein Punktschätzer ist eine Statistik, die verwendet wird, um den Wert eines unbekannten Parameters in einer Grundgesamtheit zu schätzen. Verwendet Stichprobendaten aus der Grundgesamtheit bei der Berechnung einer einzelnen Statistik, die als bester Schätzwert für den unbekannten Grundgesamtheitsparameter angesehen wird.

Bildquelle: Google Bilder
Umgekehrt, Die Intervallschätzung verwendet Stichprobendaten, um den Bereich möglicher Werte eines unbekannten Parameters in einer Population zu bestimmen. Der Parameterbereich ist so gewählt, dass er innerhalb von a . liegt 95% oder wahrscheinlicher, auch bekannt als Konfidenzintervall. Das Konfidenzintervall beschreibt, wie zuverlässig eine Schätzung ist und wird aus den beobachteten Daten berechnet. Die Endpunkte der Intervalle sind bekannt als Vorgesetzter Ja untere Vertrauensgrenzen.
Abschließende Anmerkungen
Danke fürs Lesen!
Ich hoffe, Ihnen hat der Beitrag gefallen und Sie haben Ihr Wissen über die Schätztheorie erweitert.
Zögern Sie nicht, mich zu kontaktieren Über Email
Alles was nicht erwähnt wurde oder du deine Gedanken teilen möchtest? Fühlen Sie sich frei, unten einen Kommentar zu hinterlassen und ich melde mich bei Ihnen.
Über den Autor
Aashi Goyal
Im Augenblick, Ich studiere meinen Bachelor of Technology (B.Tech) in Elektro- und Nachrichtentechnik Universidad Guru Jambheshwar (GJU), Hisar. Ich bin sehr gespannt auf die Statistik, Maschinelles Lernen und Deep Learning.
Die in diesem Beitrag gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





