Einführung
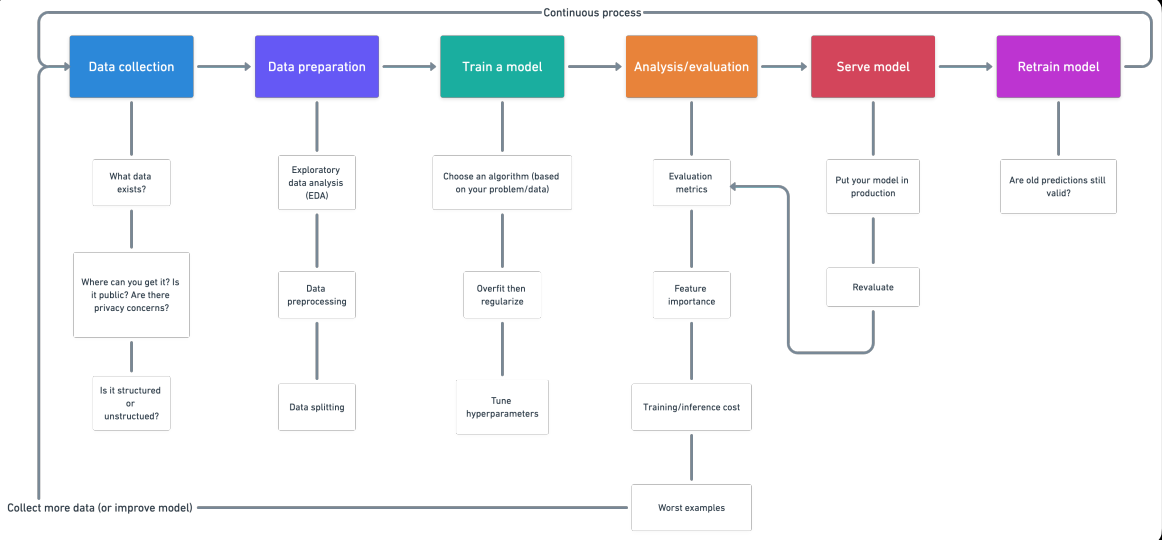
1. Datensammlung
- Welche Art von Problem versuchen wir zu lösen?
- Welche Datenquellen existieren bereits?
- Welche Datenschutzprobleme gibt es??
- Sind die Daten öffentlich??
- Wo sollen wir die Dateien speichern?
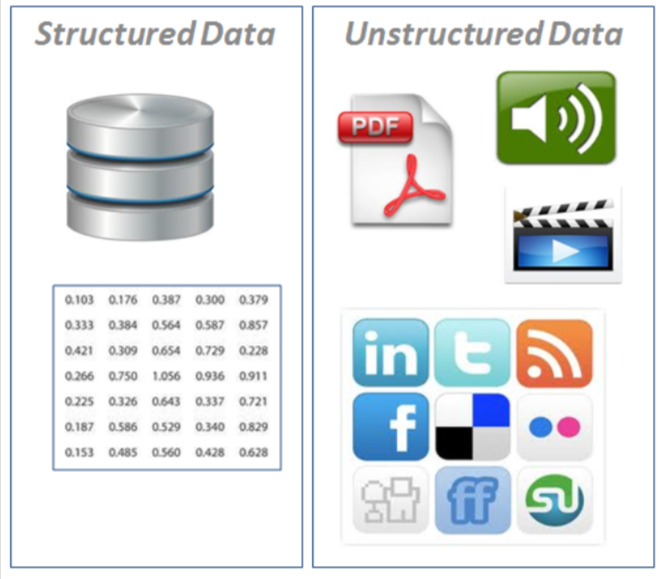
- Strukturierte Daten: erscheinen im Tabellenformat (Zeilen- und Spaltenstil, wie das, was Sie in einer Excel-Tabelle finden würden). Enthält verschiedene Arten von Daten, zum Beispiel, numerische Zeitreihen, kategorisch.
- · Nominal / kategorisch – So oder so (sich gegenseitig ausschließen). Zum Beispiel, für Autowaagen, Farbe ist eine Kategorie. Ein Auto kann blau sein, aber nicht weiß. Eine Bestellung ist egal.
- Numerisch: Jeder kontinuierliche Wert, bei dem der Unterschied zwischen ihnen wichtig ist. Zum Beispiel, beim Verkauf von Häusern, $ 107,850 ist mehr als $ 56,400.
- Ordinal: Daten, die eine Ordnung haben, aber der Abstand zwischen den Werten ist unbekannt. Zum Beispiel, eine frage wie, Wie würden Sie Ihre Gesundheit einschätzen? 1 al 5? 1 Arm sein, 5 gesund. Kannst du antworten 1, 2, 3, 4, 5, aber der Abstand zwischen den einzelnen Werten bedeutet nicht unbedingt, dass eine Antwort von 5 ist fünfmal so gut wie eine Antwort von 1. Zeitfolgen: Daten im Laufe der Zeit. Zum Beispiel, die historischen Verkaufswerte der Bulldozer von 2012 ein 2018.
- Zeitfolgen: Daten im Zeitverlauf. Zum Beispiel, die historischen Verkaufswerte der Bulldozer von 2012 ein 2018.
- Unstrukturierte Daten: Daten ohne starre Struktur (Bilder, Video, Stimme, natürlich
Sprachtext)
2. Datenaufbereitung
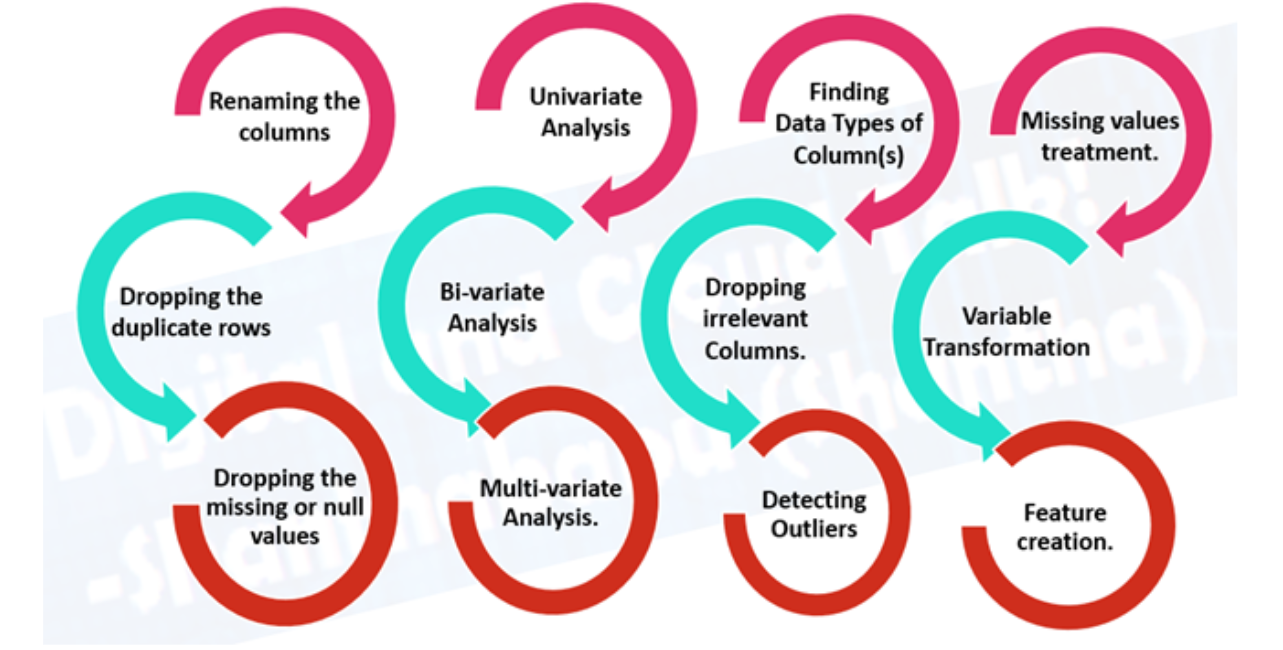
- Explorative Datenanalyse (EDA), Erfahren Sie mehr über die Daten, mit denen Sie arbeiten
- Was sind die charakteristischen Variablen (Eintrag) und die Zielvariable (Ausgang)? Zum Beispiel, Herzkrankheiten vorhersagen, charakteristische Variablen können das Alter sein, das Gewicht, die durchschnittliche Herzfrequenz und das Niveau der körperlichen Aktivität einer Person. Und die objektive Variable wird sein, ob sie eine Krankheit haben oder nicht.
- Was hast du für eine? Strukturierte Zeitreihen, unstrukturiert, numerisch. Fehlende Werte? Falls Sie sie löschen oder vervollständigen, die Imputationsfunktion.
- Wo sind die Ausreißer? Wie viele davon gibt es? Warum sind die hier? Gibt es Fragen, die Sie einem Domain-Experten zu Daten stellen können?? Zum Beispiel, Könnte ein Arzt für Herzerkrankungen etwas Licht in seinen Herzerkrankungen-Datensatz bringen??
- Datenvorverarbeitung, Vorbereitung Ihrer Daten für die Modellierung.
- Imputationsfunktion: fehlende Werte ergänzen (ein Modell für maschinelles Lernen kann nicht lernen
in Daten, die nicht da sind)
- Einzelanrechnung: Mit Medien füllen, ein Median der Spalte.
- Mehrere Imputationen: Modellieren Sie andere fehlende Werte und mit dem, was Ihr Modell findet.
- KNN (k nächste Nachbarn): Füllen Sie die Daten mit einem Wert aus einem anderen ähnlichen Beispiel aus.
- Viel mehr, wie zufällige Imputation, die letzte Beobachtung vorgetragen (für Zeitreihen), das sich bewegende Fenster und die häufigsten.
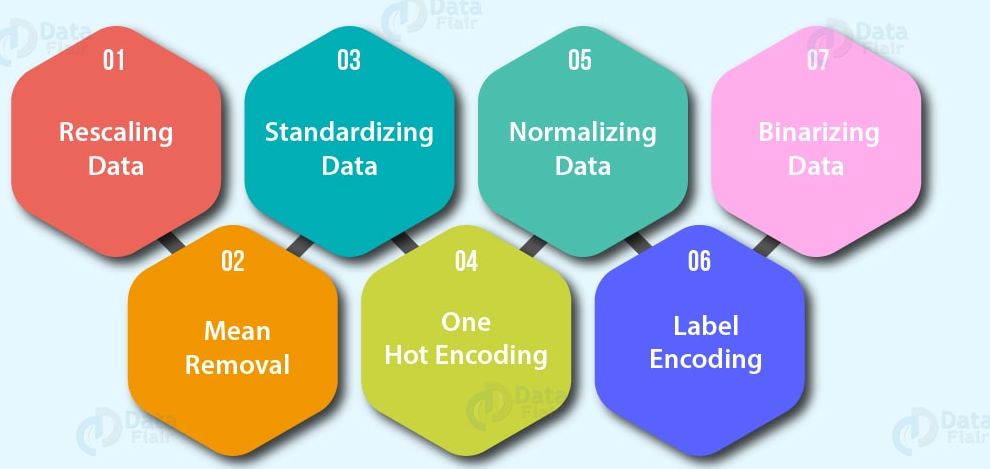
- Funktionscodierung (Werte in Zahlen umwandeln). Ein Modell für maschinelles Lernen
erfordert, dass alle Werte numerisch sind)
- Eine heiße Codierung: Wandeln Sie alle eindeutigen Werte in Listen mit Nullen und Einsen um, bei denen der Zielwert ist 1 und der Rest sind Nullen. Zum Beispiel, Wenn ein Auto grün färbt, rot, Blau, verde, die Zukunft der Autofarbe würde dargestellt als [1, 0, und 0] und ein ernstes rot [0, 1, und 0].
- Label-Encoder: Wandeln Sie Beschriftungen in eindeutige numerische Werte um. Zum Beispiel, wenn Ihre Zielvariablen verschiedene Tiere sind, wie ein Hund, Katze, Vogel, diese könnten werden 0, 1 Ja 2, beziehungsweise.
- Codierung einbetten: Lernen Sie eine Darstellung zwischen all den verschiedenen Datenpunkten. Zum Beispiel, Ein Sprachmodell ist eine Darstellung der Beziehung verschiedener Wörter zueinander. Auch für strukturierte Daten wird zunehmend Einbettung angeboten (tabellarisch).
- Funktionsstandardisierung (skaliert) oder Standardisierung: Wenn numerische Variablen auf unterschiedlichen Skalen liegen (zum Beispiel, die Anzahl_der_Badezimmer liegt zwischen 1 Ja 5 und die Größe_des_Landes dazwischen 500 Ja 20000 Quadratmeter), Einige Algorithmen für maschinelles Lernen funktionieren nicht sehr gut. Skalierung und Standardisierung helfen, dieses Problem zu lösen.
- Funktionsengineering: wandeln Sie die Daten in eine Darstellung um (möglicherweise) aussagekräftiger durch Hinzufügen von Domänenwissen
- Zersetzen
- Diskretisierung: große Gruppen in kleinere Gruppen umwandeln
- Kreuzungs- und Interaktionsfunktionen: Kombination von zwei oder mehr Funktionen
- Die Eigenschaften des Indikators: andere Teile der Daten verwenden, um auf etwas potenziell Signifikantes hinzuweisen
- Merkmalsauswahl: auswählen
die wertvollsten Funktionen Ihres Datasets zum Modellieren. Mögliche Reduzierung der Trainingszeit und Überanpassung (weniger allgemeine Daten und weniger redundante Daten zum Trainieren) und Verbesserung der Genauigkeit.
- Dimensionsreduktion: Eine gängige Methode zur Dimensionsreduktion, PCA oder Hauptkomponentenanalyse erfordert viele Dimensionen (Merkmale) und verwenden Sie lineare Algebra, um sie auf weniger Dimensionen zu reduzieren. Zum Beispiel, nehme an, du hast 10 numerische Funktionen, Ich könnte PCA ausführen, um es auf zu reduzieren 3.
- Bedeutung der Funktion (Nachmodellierung): Ein Modell an einen Datensatz anpassen, Überprüfen Sie dann, welche Eigenschaften für die Ergebnisse am wichtigsten waren, entferne das unwichtigste.
- Verpackungsmethoden wie genetische Algorithmen und rekursive Feature-Entfernung das Erstellen großer Teilmengen von Feature-Optionen beinhalten und dann diejenigen entfernen, die nicht wichtig sind.
- Umgang mit Ungleichgewichten: Haben Ihre Daten 10,000 Beispiele für eine Klasse, aber nur 100 Beispiele für andere?
- Sammeln Sie mehr Daten (ja kann)
- Verwenden Sie das unausgeglichene Paket von scikit-learn-contrib- lernen
- Verwenden Sie SMOTE: Synthetische Minoritäts-Oversampling-Technik. Erstellen Sie synthetische Samples Ihrer Junior-Klasse, um zu versuchen, das Spielfeld auszugleichen.
- Ein nützlicher Gegenstand zum Anschauen ist “Aus unausgeglichenen Daten lernen”.
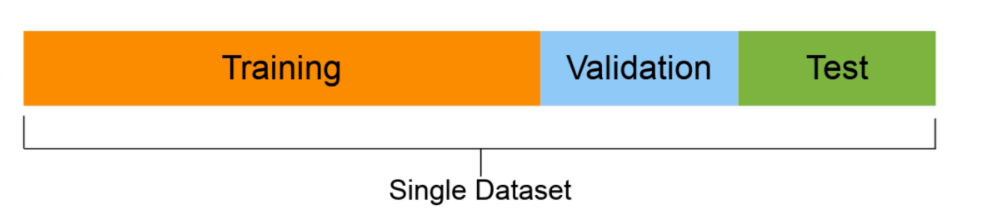
- Trainingsset (allgemein 70-80% der Daten): das Modell erfährt davon.
- Validierungsset (normalerweise von 10 al 15% der Daten): die Modellhyperparameter entsprechen diesem
- Testset (normalerweise zwischen 10% und das 15% der Daten): die endgültige Leistung der Modelle wird auf dieser Grundlage bewertet. Wenn du es gut gemacht hast, hoffentlich geben die Testergebnisse einen guten Hinweis darauf, wie sich das Modell in der realen Welt verhalten sollte. Verwenden Sie diesen Datensatz nicht zur Anpassung an das Modell.
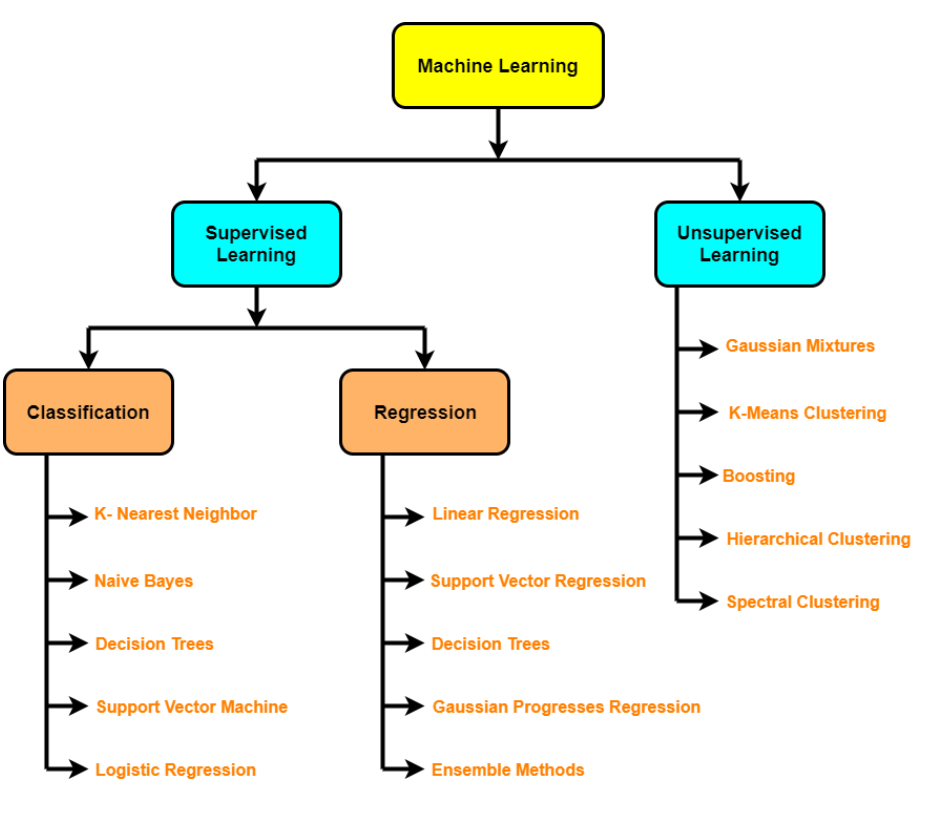
3. Trainieren Sie das Modell anhand der Daten (3 Schritte: wähle einen Algorithmus, passt das modell, Passform durch Regularisierung reduzieren)
- Überwachte Algorithmen: lineare Regression, Logistische Regression, KNN, SVM, Entscheidungsbaum und Random Forests, AdaBoost / Gradient Boosting Maschine (Impuls)
- Unüberwachte Algorithmen: Gruppierung, Dimensionsreduktion (PCA, automatische Encoder, t-SN), Anomalieerkennung
- Batch-Lernen
- Online lernen
- Lerntransfer
- Aktives Lernen
- Montage
- Fehleinstellung – tritt auf, wenn Ihr Modell mit Ihren Daten nicht so funktioniert, wie Sie es möchten. Versuchen Sie, für ein längeres oder fortgeschritteneres Modell zu trainieren.
- Übereinstellung– tritt auf, wenn der Validierungsverlust zunimmt oder wenn das Modell im Trainingssatz besser abschneidet als im Testsatz.
- Regulierung: eine Sammlung von Technologien zur Vorbeugung / Überanpassung reduzieren (zum Beispiel, L1, L2, Aufgabe, Früher Halt, Datenerweiterung, Batch-Normalisierung)
- Hyperparameter-Tuning – Führe eine Reihe von Experimenten mit verschiedenen Einstellungen durch und finde heraus, welche am besten funktioniert
4. Analyse / Auswertung
- Einstufung: Präzision, Präzision, Erholung, F1, Verwirrung Matrix, mittlere mittlere Genauigkeit (Objekterkennung)
- Rückschritt – MSE, VIEL, R ^ 2
- Aufgabenbasierte Metrik: zum Beispiel, für das autonome Auto, Vielleicht möchten Sie die Anzahl der Verbindungsabbrüche wissen
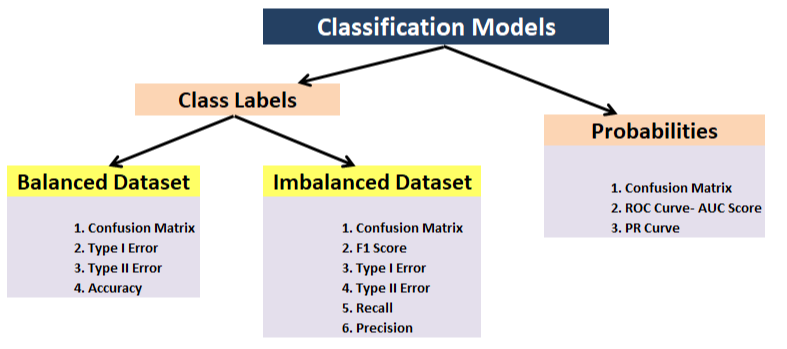
- Bedeutung der Funktion
- Ausbildung / Inferenzzeit / Kosten
- Was ist, wenn das Werkzeug: wie mein Modell im Vergleich zu anderen Modellen ist?
- Weniger sichere Beispiele: Wo ist das Modell falsch?
- Verzerrungsausgleich / Abweichung
5. Servicemodell (Umsetzung eines Modells)
- Setzen Sie das Modell ein Produktion und schau wie es geht.
- Instrumente die du benutzen kannst: TensorFlow Servinf, PyTorch-Bereitstellung, Google AI-Plattform, Weisenmacher
- MLOps: wo Softwareentwicklung auf maschinelles Lernen trifft, im Wesentlichen die gesamte Technologie, die für ein maschinelles Lernmodell erforderlich ist, damit es in der Produktion funktioniert

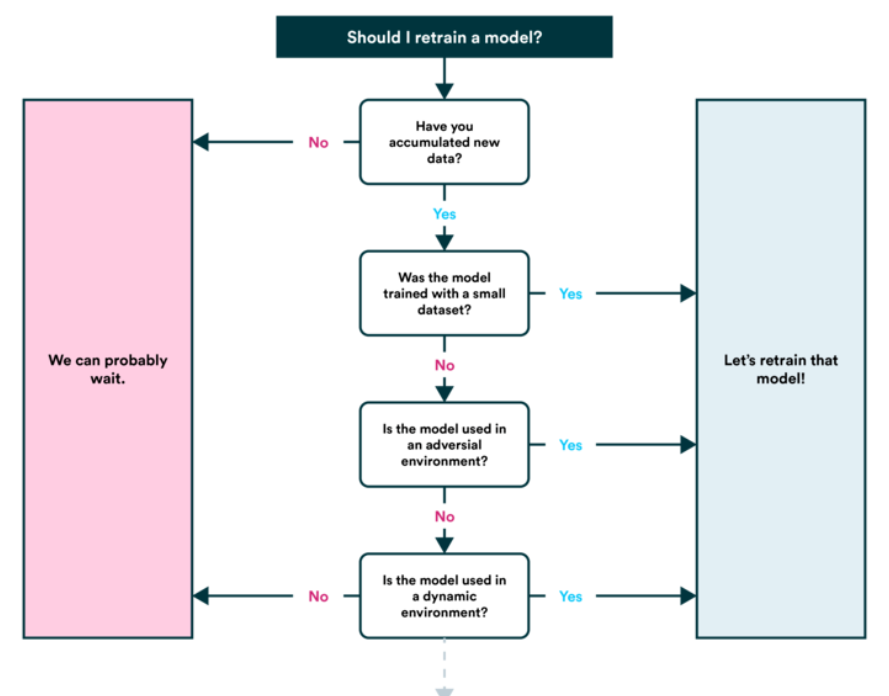
6. Umschulungsmodell
- Sehen Sie, wie das Modell nach der Veröffentlichung funktioniert (oder vor der Veröffentlichung) basierend auf verschiedenen Bewertungsmetriken und wiederholen Sie die vorherigen Schritte bei Bedarf (erinnern, maschinelles Lernen ist sehr experimentell, Hier sollten Sie also Ihre Daten und Experimente im Auge behalten.
- Sie werden auch feststellen, dass Ihre Modellvorhersagen zu "altern" beginnen’ (im Allgemeinen nicht in einem schicken Stil) das "ableiten", wenn sich Datenquellen ändern oder aktualisiert werden (neue Hardware, etc.). Dann wirst du ihn wieder trainieren wollen.
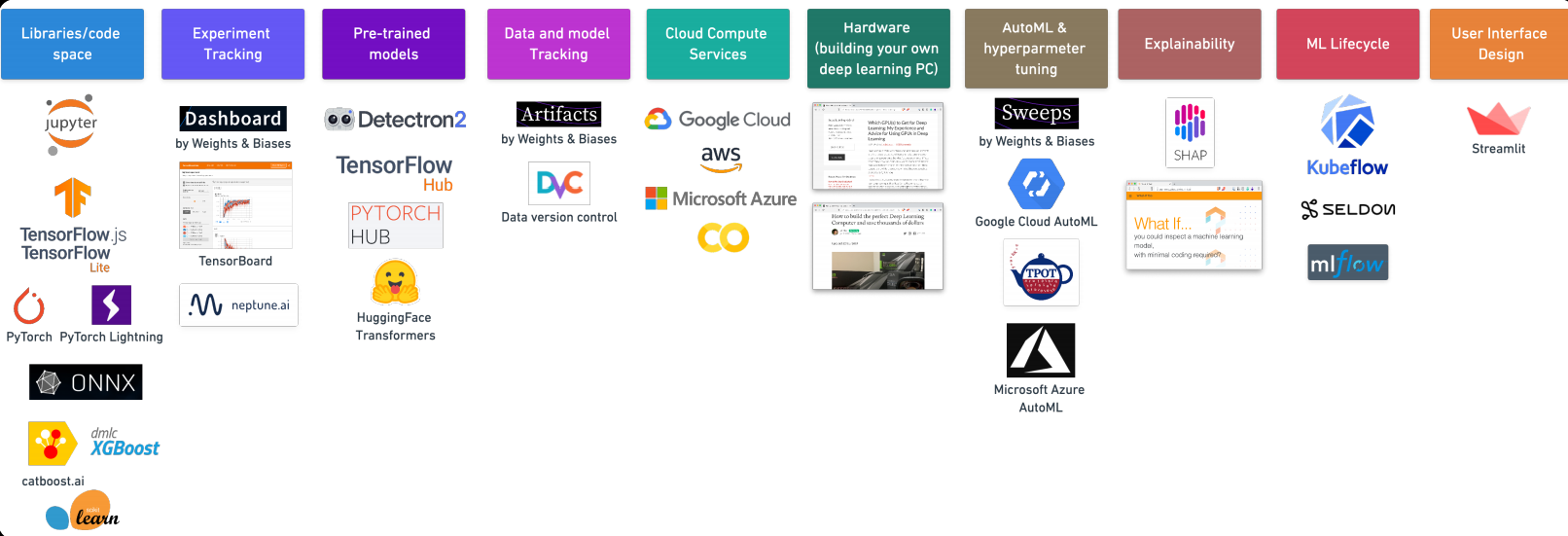
7. Werkzeuge für maschinelles Lernen
Danke, dass du das gelesen hast. Wenn dir dieser Artikel gefällt, Teile es mit deinen Freunden. Bei Anregungen / Zweifel, kommentiere unten.
E-Mail-Identifikation: [E-Mail geschützt]
Folgen Sie mir auf LinkedIn: LinkedIn
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





