Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Das ultimative Ziel dieses Blogs ist es, die Stimmung eines bestimmten Textes mit Python vorherzusagen, wo wir NLTK . verwenden, auch bekannt als Natural Language Processing Toolkit, ein Python-Paket, das speziell für die textbasierte Analyse erstellt wurde. Dann, mit ein paar Zeilen Code, wir können leicht vorhersagen, ob ein Satz oder eine Rezension (im Blog verwendet) Ist es eine positive oder negative Bewertung?.
Bevor Sie direkt zur Implementierung übergehen, Lassen Sie mich kurz die Schritte einleiten, um sich ein Bild vom Analytics-Ansatz zu machen. Das sind nämlich:
1. Import der benötigten Module
2. Datensatzimport
3. Datenvorverarbeitung und Visualisierung
4. Modellbau
5. Vorhersage
Konzentrieren wir uns also auf jeden Schritt im Detail.
1. Import der benötigten Module:
Dann, wie wir alle wissen, Es ist notwendig, alle Module zu importieren, die wir anfänglich verwenden werden. Machen wir es also als ersten Schritt unserer Praxis.
numpy als np importieren #lineare Algebra Pandas als pd importieren # Datenverarbeitung, CSV-Datei I/O (z.B. pd.read_csv) import matplotlib.pyplot als plt #Für Visualisierung %matplotlib inline import seaborn als sns #Für eine bessere Visualisierung from bs4 import BeautifulSoup #For Text Parsing
Hier importieren wir alle notwendigen grundlegenden Importmodule, nämlich, numpy, Pandas, matplotlib, Seaborn y schöne Suppe, jeder mit seinem eigenen Anwendungsfall. Obwohl wir einige andere Module verwenden werden, sie ausschließen, wir werden sie verstehen, während wir sie benutzen.
2. Datensatzimport:
Eigentlich, Den Kaggle-Datensatz hatte ich schon vor längerer Zeit heruntergeladen, Also habe ich den Link zum Datensatz nicht. Dann, um den Datensatz und den Code zu erhalten, Ich werde den Link des Github-Repositorys platzieren, damit jeder darauf zugreifen kann. Jetzt, um den Datensatz zu importieren, Wir müssen die Pandas ‘read_csv-Methode’ verwenden’ gefolgt vom Dateipfad.
data = pd.read_csv('Bewertungen.csv')
Wenn wir den Datensatz drucken, Wir konnten sehen, dass es ‘568454 Zeilen × . gibt 10 Säulen', das ist ziemlich groß.
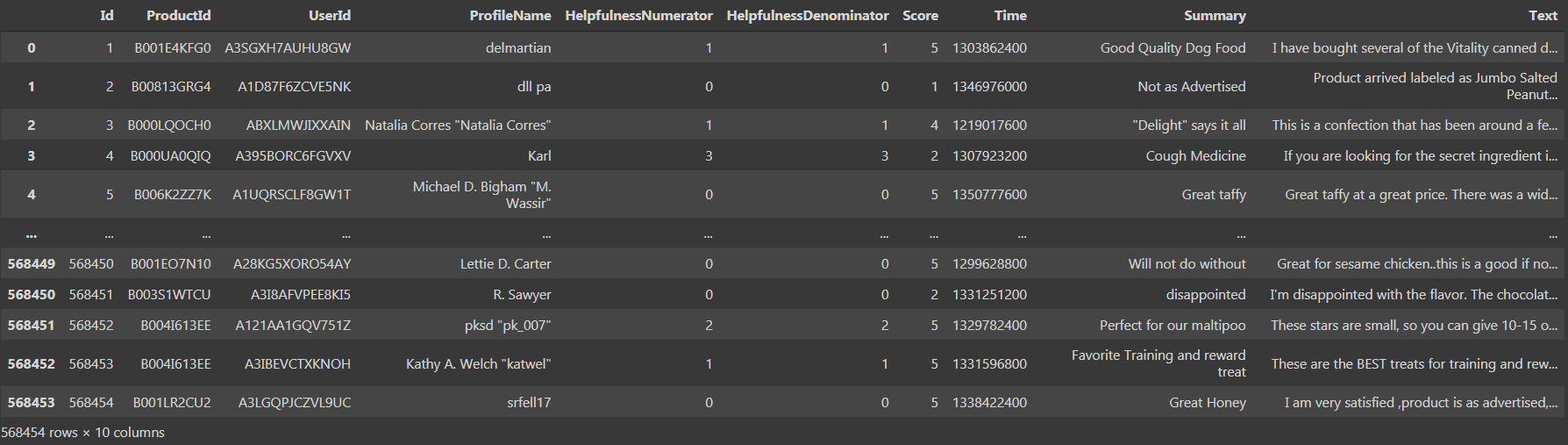
Wir sehen, dass es da ist 10 Säulen, nämlich, 'Ausweis', „Zähler Zähler“, „Nenner des Versorgungsunternehmens“, 'Punktzahl’ und Zeit’ als Datentyp int64 und 'ProductId', 'Benutzeridentifikation', 'Profilname', 'Zusammenfassung', 'Text’ als Objektdatentyp. Kommen wir nun zum dritten Schritt, nämlich, Datenvorverarbeitung und Visualisierung.
3. Datenvorverarbeitung und Visualisierung:
Jetzt haben wir Zugriff auf die Daten und dann bereinigen wir sie. Verwenden der "Isnull-Methode" (). Summe ()’ wir könnten leicht die Gesamtzahl der fehlenden Werte im Datensatz finden.
data.isnull().Summe()
Wenn wir den obigen Code als Zelle ausführen, Wir haben festgestellt, dass es gibt 16 Ja 27 Nullwerte in 'ProfileName-Spalten’ und „Zusammenfassung“’ beziehungsweise. Jetzt, wir müssen die Nullwerte durch die zentrale Tendenz ersetzen oder die entsprechenden Zeilen mit den Nullwerten entfernen. Bei so vielen Reihen, die Beseitigung von Solo 43 Zeilen mit den Nullwerten würden die Gesamtpräzision des Modells nicht beeinflussen. Deswegen, es ist ratsam zu beseitigen 43 Zeilen mit der 'dropna'-Methode.
data = data.dropna()
Jetzt, Ich habe den alten Datenrahmen aktualisiert, anstatt eine neue Variable zu erstellen und den neuen Datenrahmen mit den sauberen Werten zu speichern. Jetzt, nochmal, wenn wir den Datenrahmen prüfen, Wir haben festgestellt, dass es gibt 568411 Reihen und das gleiche 10 Säulen, was bedeutet, dass 43 Zeilen, die die Nullwerte hatten, wurden entfernt und jetzt ist unser Datensatz bereinigt. Auch weiterhin, wir müssen die Daten so vorverarbeiten, dass das Modell sie direkt verwenden kann.
Para-Präprozessor, wir verwenden die Spalte „Score“’ im Datenrahmen, um Punkte im Bereich von '1 . zu haben’ eine '5', wo '1’ bedeutet eine negative Bewertung und '5’ bedeutet eine positive Bewertung. Aber es ist besser, die Punktzahl anfangs in einem Bereich von zu haben ‘0’ eine '2’ wo ‘0’ bedeutet eine negative Bewertung, ‘1’ bedeutet eine neutrale Bewertung und '2’ bedeutet eine positive Bewertung. Es ist ähnlich wie bei der Codierung in Python, aber hier verwenden wir keine eingebauten funktionen, aber wir führen explizit eine for where Schleife aus und erstellen eine neue Liste und fügen die Werte der Liste hinzu.
a=[]
für ich in daten['Punktzahl']:
wenn ich <3:
a.anhängen(0)
wenn ich==3:
a.anhängen(1)
wenn ich>3:
a.anhängen(2)
Angenommen, der 'Score’ liegt im Bereich von ‘0’ eine '2', Wir betrachten sie als negative Bewertungen und fügen sie mit einer Punktzahl von der Liste hinzu ‘0’, was bedeutet negative bewertung. Jetzt, wenn wir die Werte der in der Liste 'a . vorhandenen Punktzahlen grafisch darstellen’ wie die oben verwendete Nomenklatur, Wir haben festgestellt, dass es gibt 82007 negative Bewertungen, 42638 neutrale Bewertungen und 443766 positive Bewertungen. Wir können deutlich feststellen, dass ungefähr die 85% der Bewertungen im Datensatz haben positive Bewertungen und der Rest sind negative oder neutrale Bewertungen. Dies könnte mit Hilfe eines Zählplots in der Seegeborenenbibliothek klarer visualisiert und verstanden werden.
sns.countplot(ein)
plt.xlabel('Bewertungen', Farbe="rot")
plt.ylabel('Zählen', Farbe="rot")
plt.xticks([0,1,2],['Negativ','Neutral','Positiv'])
plt.titel('ZÄHLGRUNDSTÜCK', Farbe="R")
plt.zeigen()
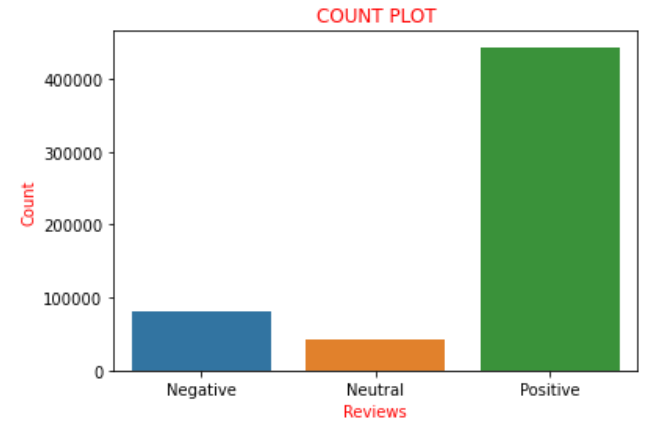
Deswegen, die obige Handlung stellt alle oben beschriebenen Sätze bildhaft dar. Jetzt konvertiere ich die Liste 'to’ die wir zuvor in einer neuen Spalte namens "Gefühl" kodiert hatten’ zum Datenrahmen, nämlich, 'Daten'. Jetzt kommt eine Wendung, bei der wir eine neue Variable erstellen, sagen wir "final_dataset"’ wobei ich nur die Spalte „Gefühl“ betrachte’ und „text“’ des Datenrahmens, das ist der neue Datenrahmen, an dem wir für den nächsten Teil arbeiten werden. Der Grund dafür ist, dass alle verbleibenden Spalten als solche betrachtet werden, die nicht zur Sentimentanalyse beitragen., Daher, ohne sie wegzuwerfen, Wir betrachten den Datenrahmen, um diese Spalten auszuschließen. Deswegen, das ist der Grund, nur die Spalten ‚Text‘ zu wählen’ und 'Gefühl'. Wir codieren das gleiche wie unten:
Daten['Gefühl']=a final_dataset = Daten[['Text','Gefühl']] final_dataset
Jetzt, wenn wir den ‘final_dataset’ drucken’ und wir finden den Weg, wir erfahren, dass es da ist 568411 Reihen und nur 2 Säulen. Aus dem final_dataset, wenn wir herausfinden, dass die Anzahl der positiven Rückmeldungen beträgt 443766 Einträge und die Anzahl der negativen Kommentare ist 82007. Deswegen, Es gibt einen großen Unterschied zwischen positivem und negativem Feedback. Deswegen, Es besteht eine größere Chance, dass die Daten zu gut passen, wenn wir versuchen, das Modell direkt zu erstellen. Deswegen, wir müssen nur wenige Eingaben aus dem final_datset auswählen, um eine Überanpassung zu vermeiden. Dann, aus verschiedenen Prüfungen, Ich habe festgestellt, dass der optimale Wert für die Anzahl der zu berücksichtigenden Überarbeitungen ist 5000. Deswegen, Ich erstelle zwei neue Variablendatenp’ und "Datum"’ und zufällig speichern 5000 positive bzw. negative Bewertungen zu den Variablen. Der Code, der dasselbe implementiert, ist unten:
datap = data_p.iloc[np.random.randint(1,443766,5000), :] datan = data_n.iloc[np.random.randint(1, 82007,5000), :] len(Daten), len(Datenp)
Jetzt erstelle ich eine neue Variable namens data und verkette die Werte in 'datap’ und "Datum".
data = pd.concat([Datenp,Daten]) len(Daten)
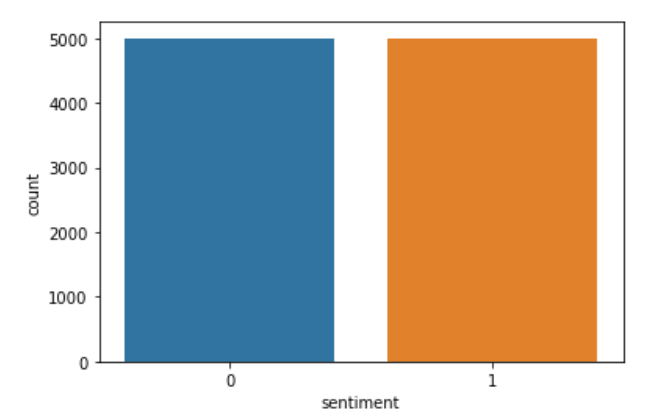
Jetzt erstelle ich eine neue Liste namens 'c’ und was ich tue, ist ähnlich der Kodierung, aber explizit. Ich behalte die negativen Bewertungen “0” Was “0” und die positiven Bewertungen “2” vorher wie “1” In “C”. Später, wieder ersetze ich die in 'c . gespeicherten Sentimentwerte’ in Spaltendaten. Später, um zu sehen, ob der Code korrekt ausgeführt wurde, Ich verfolge die Spalte „Gefühl“. Der Code, der dasselbe implementiert, ist:
c=[]
für ich in daten['Gefühl']:
wenn ich==0:
c.anhängen(0)
wenn ich==2:
c.anhängen(1)
Daten['Gefühl']=c
sns.countplot(Daten['Gefühl'])
plt.zeigen()
Wenn wir die Daten sehen, Wir können feststellen, dass es einige HTML-Tags gibt, da die Daten ursprünglich von tatsächlichen E-Commerce-Sites bezogen wurden. Deswegen, Wir können feststellen, dass Tags vorhanden sind, die entfernt werden müssen, da sie für die Sentimentanalyse nicht notwendig sind. Deswegen, Wir verwenden die BeautifulSoup-Funktion, die den 'html.parser . verwendet’ und wir können unerwünschte Tags ganz einfach aus Bewertungen entfernen. Um die Aufgabe auszuführen, Ich erstelle eine neue Spalte namens "Review"’ was den geparsten Text speichert und die Spalte mit dem Namen "Gefühl" löscht’ um Redundanzen zu vermeiden. Ich habe die obige Aufgabe mit einer Funktion namens 'strip_html' erledigt.. Der Code, um dasselbe zu tun, ist wie folgt:
def strip_html(Text):
Suppe = SchöneSoup(Text, "html.parser")
zurücksuppe.get_text()
Daten['Rezension'] = Daten['Text'].anwenden(strip_html)
data=data.drop('Text',Achse=1)
daten.kopf()
Jetzt sind wir am Ende eines langwierigen Prozesses der Datenvorverarbeitung und Visualisierung angelangt. Deswegen, Jetzt können wir mit dem nächsten Schritt fortfahren, nämlich, Modellbau.
4. Baumodell:
Bevor wir direkt springen, um das Modell zu bauen, das wir brauchen, kleine Hausaufgaben machen. Wir wissen, dass wir Artikel brauchen, damit Menschen Gefühle klassifizieren können, Determinanten, Konjunktionen, Satzzeichen, etc, wie wir die Rezension klar verstehen und dann bewerten können. Aber das ist bei Maschinen nicht der Fall, Sie brauchen sie also nicht wirklich, um das Gefühl zu klassifizieren, aber sie sind buchstäblich verwirrt, wenn sie anwesend sind. Dann, um diese Aufgabe wie jede andere Sentiment-Analyse durchzuführen, wir müssen die 'nltk'-Bibliothek verwenden. NLTK son las siglas de ‘Natural Language Processing Toolkit’. Dies ist eine der besten Bibliotheken für die Durchführung von Stimmungsanalysen oder anderen textbasierten maschinellen Lernprojekten. Dann, mit Hilfe dieser Bibliothek, Ich entferne zuerst die Satzzeichen und dann die Wörter, die dem Text kein Gefühl hinzufügen. Zuerst verwende ich eine Funktion namens 'punc_clean’ wodurch Satzzeichen aus jeder Rezension entfernt werden. Der Code, um dasselbe zu implementieren, ist der folgende:
nltk importieren
auf jeden Fall punc_clean(Text):
String als st . importieren
a=[w für w im Text, wenn w nicht in st. Zeichensetzung]
''.join zurückgeben(ein)
Daten['Rezension'] = Daten['Rezension'].anwenden(punc_clean)
daten.kopf(2)
Deswegen, der obige Code entfernt Satzzeichen. Jetzt, dann, Wir müssen die Wörter entfernen, die dem Satz kein Gefühl verleihen. Diese Wörter heißen “leere Worte”. Liste mit fast allen Stoppwörtern konnte gefunden werden hier. Dann, wenn wir die Liste der leeren Wörter überprüfen, wir können feststellen, dass es auch das Wort enthält “Nein”. Deswegen, es ist notwendig, dass wir die “Nein” aus “Revision”, da es der Stimmung einen gewissen Wert verleiht, weil es zur negativen Stimmung beiträgt. Deswegen, Wir müssen den Code so schreiben, dass wir andere Wörter außer dem entfernen “Nein”. Der Code, um dasselbe zu implementieren, ist:
def remove_stopword(Text):
stopword=nltk.corpus.stopwords.words('Englisch')
stopword.remove('nicht')
a=[w für w in nltk.word_tokenize(Text) wenn w nicht im Stoppwort]
zurück ' '.beitreten(ein)
Daten['Rezension'] = Daten['Rezension'].anwenden(remove_stopword)
Deswegen, jetzt haben wir nur noch einen schritt hinter dem modellbau. Der nächste Grund besteht darin, jedem Wort in jeder Bewertung einen Sentiment-Score zuzuordnen. Dann, um es umzusetzen, wir müssen eine andere Bibliothek aus dem sklearn-Modul verwenden’ Was ist der 'TfidVectorizer’ die in 'feature_extraction.text' vorhanden ist. Es wird dringend empfohlen, den 'TfidVectorizer . zu durchlaufen’ Dokumente um ein klares Verständnis der Bibliothek zu bekommen. Hat viele Parameter als Eingabe, Codierung, min_df, max_df, ngram_range, binär, dtyp, use_idf und viele weitere Parameter, jeder mit seinem eigenen Anwendungsfall. Deswegen, es wird empfohlen, dies durchzugehen Blog um zu verstehen, wie 'TfidVectorizer' funktioniert. Der Code, der dasselbe implementiert, ist:
aus sklearn.feature_extraction.text import TfidfVectorizer vektor = TfidfVectorizer(ngram_range=(1,2),min_df=1) vectr.fit(Daten['Rezension']) vect_X = vectr.transform(Daten['Rezension'])
Jetzt ist es an der Zeit, das Modell zu bauen. Da es sich um eine binäre Klassenklassifizierung der Stimmungsanalyse handelt, nämlich, ‘1’ verweist auf eine positive Bewertung und ‘0’ verweist auf eine negative Bewertung. Dann, Es ist klar, dass wir einen der Klassifikationsalgorithmen verwenden müssen. Die hier verwendete ist die logistische Regression. Deswegen, wir müssen 'LogisticRegression' importieren’ um es als unser Modell zu verwenden. Später, wir müssen alle Daten als solche anpassen, weil ich es gut fand, die Daten mit brandneuen Daten anstelle des verfügbaren Datensatzes zu testen. Also habe ich den ganzen Datensatz angepasst. Dann benutze ich die '.score Funktion ()’ um die Modellbewertung vorherzusagen. Der Code, der die oben genannten Aufgaben implementiert, ist wie folgt:
from sklearn.linear_model import LogisticRegression Modell = LogistischeRegression() clf=model.fit(vect_X,Daten['Gefühl']) clf.score(vect_X,Daten['Gefühl'])*100
Wenn wir das obige Code-Snippet ausführen und die Modellbewertung überprüfen, wir kommen dazwischen 96 Ja 97%, da sich der Datensatz jedes Mal ändert, wenn wir den Code ausführen, da wir die Daten zufällig betrachten. Deswegen, Wir haben unser Modell erfolgreich gebaut, das auch mit einer guten Punktzahl. Dann, Warum warten, um zu testen, wie unser Modell im realen Szenario funktioniert?? Also gehen wir jetzt zum letzten und letzten Schritt der 'Vorhersage' über’ um die Leistung unseres Modells zu testen.
5. Vorhersage:
Dann, um die Leistung des Modells zu klären, Ich habe zwei einfache Sätze "Ich liebe Eis" und "Ich hasse Eis" verwendet, die sich eindeutig auf positive und negative Gefühle beziehen.. Das Ergebnis ist wie folgt:

Hier die '1’ und das ‘0’ beziehen sich auf positive bzw. negative Stimmung. Warum werden einige Bewertungen aus der realen Welt nicht getestet?? Ich bitte Sie als Leser, dasselbe zu überprüfen und zu beweisen. Meistens würden Sie die gewünschte Ausgabe erhalten, aber wenn das nicht geht, Ich bitte Sie, zu versuchen, die Parameter des 'TfidVectorizer . zu ändern’ und setze das Modell auf "LogisticRegression".’ um die erforderliche Ausgabe zu erhalten. Dann, für die ich den Link zum Code und zum Datensatz angehängt habe hier.
Du verbindest dich mit mir durch verlinktin. Ich hoffe, dieser Blog ist hilfreich, um zu verstehen, wie die Sentimentanalyse praktisch mit Hilfe von Python-Codes durchgeführt wird. Danke, dass du den Blog gesehen hast.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





