Überblick
- Discutiremos cómo puede consultar una DatenbankEine Datenbank ist ein organisierter Satz von Informationen, mit dem Sie, Effizientes Verwalten und Abrufen von Daten. Einsatz in verschiedenen Anwendungen, Von Unternehmenssystemen bis hin zu Online-Plattformen, Datenbanken können relational oder nicht-relational sein. Das richtige Design ist entscheidend für die Optimierung der Leistung und die Gewährleistung der Informationsintegrität, und erleichtert so eine fundierte Entscheidungsfindung in verschiedenen Kontexten.... MongoDB usando la biblioteca PyMongo.
- Wir werden die grundlegenden Aggregationsoperationen in MongoDB behandeln.
Einführung
Nach der weltweiten Expansion des Internets, wir generieren jetzt Daten mit einer noch nie dagewesenen Geschwindigkeit. Weil die Durchführung jeder Art von Analyse von uns erfordern würde, / Lassen Sie uns die notwendigen Daten aus der Datenbank konsultieren, Es ist äußerst wichtig, dass wir das richtige Tool wählen, um die Daten abzufragen. Folglich, Wir können uns nicht vorstellen, SQL zu verwenden, um mit dieser Datenmenge zu arbeiten, da jede beratung teuer wird.
Abfragen einer MongoDB-Datenbank mit PyMongo
Genau hier kommt MongoDB ins Spiel. MongoDB ist eine unstrukturierte Datenbank, die Daten in Form von Dokumenten speichert. Was ist mehr, MongoDB puede manejar grandes volúmenes de datos de manera muy eficiente y es la NoSQL-DatenbankNoSQL-Datenbanken sind Datenmanagementsysteme, die sich durch ihre Flexibilität und Skalierbarkeit auszeichnen. Im Gegensatz zu relationalen Datenbanken, Verwenden Sie unstrukturierte Datenmodelle, als Dokumente, Schlüssel/Wert-Paar oder Grafiken. Sie sind ideal für Anwendungen, die den Umgang mit großen Informationsmengen und eine hohe Verfügbarkeit erfordern, wie z. B. bei sozialen Netzwerken oder Cloud-Diensten. Seine Popularität ist gewachsen in... más utilizada, da es eine reichhaltige Abfragesprache und einen schnellen und flexiblen Zugriff auf Daten bietet.
In diesem Artikel, Wir werden mehrere Beispiele sehen, wie man eine MongoDB-Datenbank mit PyMongo abfragt. Was ist mehr, veremos cómo utilizar los operadores de comparaciónLos operadores de comparación son herramientas fundamentales en programación y matemáticas que permiten evaluar relaciones entre valores. Estos incluyen operadores como mayor que (>), menor que (<), gleicht (==) y diferente de (!=). Su función principal es retornar un valor booleano, nämlich, richtig oder falsch, facilitando la toma de decisiones en algoritmos y la manipulación de datos en estructuras de control como condicionales y bucles.... und das operadores lógicosLos operadores lógicos son símbolos o palabras clave que permiten combinar y evaluar expresiones booleanas en programación y matemáticas. Los más comunes son AND, OR y NOT. Estos operadores son fundamentales para el desarrollo de algoritmos y la toma de decisiones en sistemas informáticos, facilitando la ejecución de condiciones complejas. Su correcto uso optimiza el flujo de control y mejora la eficiencia en la resolución de problemas...., Grundlagen zu regulären Ausdrücken und Aggregationspipelines.
Dieser Artikel ist eine Fortsetzung des MongoDB in Python Tutorial für Anfänger, wo wir die Herausforderungen unstrukturierter Datenbanken abdecken, Installationsschritte und grundlegende MongoDB-Operationen. Dann, wenn Sie ein kompletter Anfänger bei MongoDB sind, Ich würde dir empfehlen, diesen Artikel zuerst zu lesen.
Inhaltsverzeichnis
- Was ist PyMongo?
- Installationsschritte
- Fügen Sie die Daten in die Datenbank ein
- Konsultieren Sie die Datenbank
- Feldbasierter Filter
- Nach Vergleichsoperatoren filtern
- Nach logischen Operatoren filtern
- Reguläre Ausdrücke
- Aggregationsrohre
- Abschließende Anmerkungen
Was ist PyMongo?
PyMongo ist eine Python-Bibliothek, mit der wir uns mit MongoDB verbinden können. Was ist mehr, Dies ist die am meisten empfohlene Methode, um mit MongoDB und Python zu arbeiten.
Was ist mehr, Wir haben Python ausgewählt, um mit MongoDB zu interagieren, da es eine der am weitesten verbreiteten und wesentlich leistungsfähigeren Sprachen für ist Datenwissenschaft. PyMongo ermöglicht es uns, die Daten mit einer Syntax abzurufen, die der eines Wörterbuchs ähnelt.
Falls Sie ein Anfänger in Python sind, Ich empfehle Ihnen, sich für diesen kostenlosen Kurs anzumelden: Einführung in Python.
Installationsschritte
Die Installation von PyMongo ist einfach und unkompliziert. Hier, ich schätze du hast schon python 3 und MongoDB installiert. Der folgende Befehl hilft Ihnen bei der Installation von PyMongo:
pip3 installiere pymongo
Fügen Sie die Daten in die Datenbank ein
Lassen Sie uns nun die Dinge einrichten, bevor wir eine MongoDB-Datenbank mit PyMongo abfragen. Zuerst werden wir die Daten in die Datenbank einfügen. Die folgenden Schritte helfen Ihnen dabei:
-
Importieren Sie die Bibliotheken und verbinden Sie sich mit dem Mongo-Client
Starten Sie den MongoDB-Server auf Ihrem Computer. Ich gehe davon aus, dass eine Datei auf localhost ausgeführt wird: 27017.
Beginnen wir mit dem Importieren einiger der Bibliotheken, die wir verwenden werden. Standardmäßig, MongoDB-Server läuft auf Port 27017 von der lokalen Maschine. Später, Wir verbinden uns mit dem MongoDB-Client mit dem Pymongo Bücherei.
Später, db-Instanz von sample_db db abrufen. Falls es keine gibt, MongoDB erstellt eine für Sie.
-
Erstellen Sie die Sammlungen aus den JSON-Dateien
Wir werden Daten von einem Lebensmittellieferdienst verwenden, der in mehreren Städten tätig ist. Was ist mehr, Sie haben in diesen Städten mehrere Logistikzentren, um Lebensmittelbestellungen an ihre Kunden zu senden. Sie können die herunterladen Daten und Code hier.
- wöchentliche_nachfrage:
- ICH WÜRDE: eindeutige ID für jedes Dokument
- Woche: Wochennummer
- center_id: Eindeutige ID für das Fulfillment Center
- food_id: eindeutige Lebensmittel-ID
- checkout_price: Endpreis mit Rabatt, Steuern und Versandkosten
- Grundpreis: Grundpreis der Mahlzeit
- emailer_for_promotion: E-Mail-Versand für Lebensmittelwerbung
- homepage_featured: Auf der Homepage vorgestellte Speisen.
- Anzahl_Bestellungen: (Bestimmung) Anzahl der Bestellungen
- food_info:
- food_id: Eindeutige ID für Lebensmittel
- Kategorie: Art der Nahrung (Getränke / Snacks / Suppen….)
- Küche: Essensküche (Indien / Italienisch /…)
Dann erstellen wir zwei Sammlungen in der Datenbank sample_db:


- wöchentliche_nachfrage:
-
Daten in Sammlungen einfügen
Jetzt, los datos que tenemos están en formato JSONJSON, o JavaScript-Objekt-Notation, Es handelt sich um ein leichtgewichtiges Datenaustauschformat, das für Menschen leicht zu lesen und zu schreiben ist, und für Maschinen einfach zu analysieren und zu generieren. Es wird häufig in Webanwendungen verwendet, um Informationen zwischen einem Server und einem Client zu senden und zu empfangen. Seine Struktur basiert auf Schlüssel-Wert-Paaren, Dadurch ist es vielseitig einsetzbar und in der Softwareentwicklung weit verbreitet... Dann bekommen wir die Sammelinstanz, Wir werden die Datendatei lesen und die Daten mit dem einfügen insert_many Funktion.
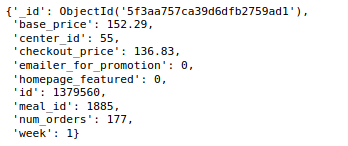
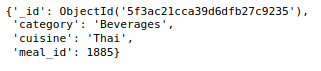
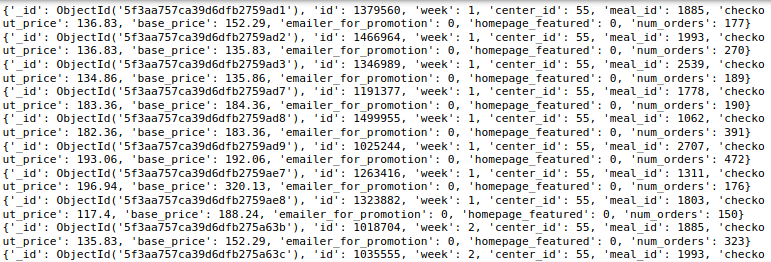
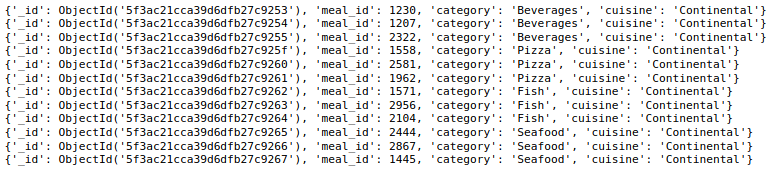
Schließlich, haben 456548 Dokumente in der wöchentlichen Bedarfserfassung und 51 Dokumente in der Lebensmittelinformationssammlung. Jetzt, Werfen wir einen Blick auf ein Dokument aus jeder dieser Sammlungen.
wöchentliche_sammlung
mahlzeit_info_sammlung
Jetzt, unsere Daten sind fertig. Lassen Sie uns diese Datenbank konsultieren.
Konsultieren Sie die Datenbank
Wir können eine MongoDB-Datenbank mit PyMonfo mit dem finden -Funktion, um alle Ergebnisse zu erhalten, die die gegebene Bedingung erfüllen, und auch unter Verwendung der einen finden Funktion, die nur ein Ergebnis zurückgibt, das die Bedingung erfüllt.
Das Folgende ist die Syntax von find und find_one:
deine_sammlung.find( {<< Anfrage >>} , { << Felder>>} )
Sie können die Datenbank mit den folgenden Filtertechniken abfragen:
-
Feldbasierter Filter
Zum Beispiel, Sie haben Hunderte von Feldern und möchten nur einige davon sehen. Sie können dies tun, indem Sie einfach alle erforderlichen Feldnamen mit dem Wert 1. Zum Beispiel:

Zweitens, wenn Sie nur einige Felder aus dem gesamten Dokument verwerfen möchten, Sie können die Feldnamen gleich setzen 0. Deswegen, nur diese Felder werden ausgeschlossen. Beachten Sie, dass Sie keine Kombination aus 1 Ja 0 um die Felder zu bekommen. Entweder müssen alle eins sein oder alle müssen null sein.

-
Mit einer Bedingung filtern
Jetzt, in diesem Abschnitt, Wir werden eine Bedingung in den ersten geschweiften Klammern und Feldern angeben, die in der zweiten verworfen werden soll. Folglich, gibt das erste Dokument mit center_id gleich zurück 55 und mahlzeit_id ist gleich 1885 Außerdem werden die Felder _id und week verworfen.

-
Nach Vergleichsoperatoren filtern
Im Folgenden sind die neun Vergleichsoperatoren in MongoDB aufgeführt.
NAME BEZEICHNUNG $eqWird mit Werten übereinstimmen, die einem angegebenen Wert entsprechen. $gtWird mit Werten übereinstimmen, die größer als ein bestimmter Wert sind. $gteEntspricht allen Werten, die größer oder gleich einem angegebenen Wert sind. $inEntspricht einem der angegebenen Werte in einem Array. $ltWird mit allen Werten übereinstimmen, die kleiner als ein bestimmter Wert sind. $lteEntspricht allen Werten, die kleiner oder gleich einem angegebenen Wert sind. $neWird mit allen Werten übereinstimmen, die nicht einem angegebenen Wert entsprechen. $ninEntspricht keinem der angegebenen Werte in einem Array. Im Folgenden finden Sie einige Beispiele für die Verwendung dieser Vergleichsoperatoren:
-
Gleich wie und nicht gleich
Wir finden alle Dokumente, bei denen center_id gleich ist 55 und homepage_featured ist nicht gleich 0. So verwenden wir die Suchfunktion, gibt den Cursor für diesen Befehl zurück. Was ist mehr, Verwenden Sie eine for-Schleife, um die Abfrageergebnisse zu durchlaufen.

-
Auf der Liste und nicht auf der Liste
Zum Beispiel, muss ein Element mit mehreren Elementen übereinstimmen. Dann, anstatt den Operator zu verwenden $ eq mehrmals, Wir können den Operator verwenden $ In. Wir werden versuchen, alle Dokumente zu finden, in denen center_id ist 24 du 11.

Später, wir suchen nach allen Dokumenten, bei denen center_id nicht in der angegebenen Liste vorhanden ist. Die folgende Abfrage gibt alle Dokumente zurück, bei denen center_id nicht ist 24 und weder 11.

-
Kleiner als und Größer als
Jetzt, Lassen Sie uns alle Dokumente finden, in denen center_id ist 55 und checkout_price ist größer als 100 und weniger als 200. Verwenden Sie dazu die folgende Syntax-

-
-
Nach logischen Operatoren filtern
NAME BEZEICHNUNG $andVerbindet die Abfrageklauseln mit einer Logik. ANDund gibt alle Dokumente zurück, die beide Bedingungen erfüllen.$notEs wird die Auswirkung einer Abfrage umkehren und Dokumente zurückgeben, die nicht Nein Abfrageausdruck übereinstimmen. $norVerbindet die Abfrageklauseln mit einer Logik. NORund alle Dokumente zurückgeben, die nicht den Klauseln entsprechen.$orVerbindet die Abfrageklauseln mit einer Logik. ORund alle Dokumente zurückgeben, die den Bedingungen einer der Klauseln entsprechen.Die folgenden Beispiele veranschaulichen die Verwendung logischer Operatoren:
-
Und Betreiber
Die folgende Abfrage gibt alle Dokumente zurück, bei denen center_id gleich . ist 11 und auch mahlzeit_id ist nicht gleich 1778. Die Unterabfragen für die Ja Der Operator wird eine Liste eingeben.

-
Betreiber OR
Die folgende Abfrage gibt alle Dokumente zurück, bei denen center_id gleich . ist 11 o Mahlzeit_id es 1207 Ö 2707. Was ist mehr, die Unterabfragen für die Ö Der Operator wird eine Liste eingeben.

-
-
Mit regulären Ausdrücken filtern
Reguläre Ausdrücke sind sehr nützlich, wenn Sie Textfelder haben und nach Dokumenten mit einem bestimmten Muster suchen möchten. Falls Sie mehr über reguläre Ausdrücke erfahren möchten, Ich empfehle Ihnen, diesen Artikel zu lesen: Anfänger-Tutorial für reguläre Ausdrücke in Python.
Kann mit Operator verwendet werden. $ regex und wir können dem Operator einen Wert liefern, damit das Regex-Muster matc . ist. Wir verwenden für diese Abfrage die Sammlung "meal_info" und finden dann die Dokumente, in denen das Küchenfeld mit einem Zeichen beginnt C.

Nehmen wir ein weiteres Beispiel für reguläre Ausdrücke. Wir werden alle Dokumente entdecken, in denen die Kategorie mit dem Charakter beginnt. „S“ und die Küche endet mit „Ian“.

-
Aggregationsrohre
Die MongoDB Aggregation Pipeline bietet einen Rahmen für die Durchführung einer Reihe von Datentransformationen an einem Datensatz. Das Folgende ist seine Syntax:
deine_sammlung.Aggregat( [ { <Stufe 1> }, { <Stufe 2> },.. ] )
In der ersten Phase wird der gesamte Dokumentensatz als Eingabe verwendet und, von dort, jede nachfolgende Stufe nimmt die Ergebnismenge der vorherigen Transformation als Eingabe für die nächste Stufe und erzeugt die Ausgabe.
Es gibt ungefähr 10 im MongoDB-Aggregat verfügbare Transformationen, von denen wir sehen werden $ Spiel Ja $ Gruppe In diesem Artikel. Wir werden jede der Transformationen im nächsten MongoDB-Artikel ausführlich besprechen.
Zum Beispiel, In der ersten Stufe, Wir gleichen die Dokumente ab, bei denen center_id gleich ist 11 und in der nächsten stufe, zählt die Anzahl der Dokumente mit center_id gleich 11. Bitte beachten Sie, dass wir die $ zählen Operator gleicher Wert total_rows in der zweiten Stufe ist das der Name des Feldes, das wir in der Ausgabe haben wollen.

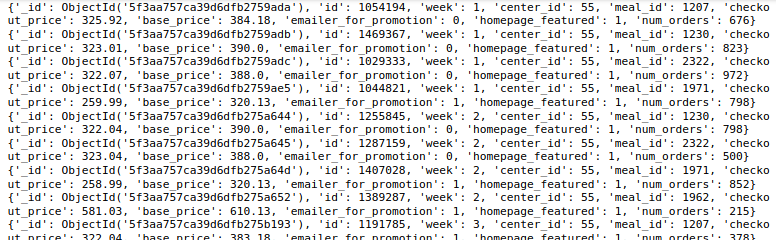
Jetzt, Nehmen wir ein anderes Beispiel, bei dem die erste Stufe dieselbe ist wie zuvor, nämlich, center_id gleich 11 und in der zweiten stufe, Wir möchten den Durchschnitt des Felds num_orders für die center_id berechnen 11 und die einzigen Mahlzeit_IDs für die center_id 11.









Abschließende Anmerkungen
Die unergründliche Datenmenge, die heute anfällt, macht es notwendig, bessere Alternativen wie diese zu finden, um Daten abzufragen. Um zusammenzufassen, In diesem Artikel, wir haben gelernt, wie man mit PyMongo eine MongoDB-Datenbank abfragt. Was ist mehr, wir haben es verstanden, verschiedene Filter entsprechend der erforderlichen Situation anzuwenden.
Falls Sie weitere Informationen zur Datenabfrage wünschen, Ich empfehle folgenden Kurs: Strukturierte Abfragesprache (SQL) für Datenwissenschaft
Im nächsten Artikel, wir werden Aggregationspipelines im Detail analysieren.
Ich ermutige Sie, Dinge selbst auszuprobieren und Ihre Erfahrungen im Kommentarbereich zu teilen. Was ist mehr, wenn Sie ein Problem mit einem der oben genannten Konzepte haben, Fragt mich gerne unten in den Kommentaren.





