In meinem vorherigen Artikel, wir diskutierten “hSo verwenden Sie QVD um Ihre QlikView-Anwendung effizienter zu machen?”. In diesem Artikel, Wir werden einen Schritt nach vorne machen, um unsere Anwendung beim Umgang mit großen Transaktionsdaten effizienter zu machen. Wie ich in meinem vorherigen Artikel erwähnt habe, Ich habe an einer QlikView-Anwendung gearbeitet, wo ich Verkäufe über mehrere Kanäle für vordefinierte Frequenzen anzeigen musste (zum Beispiel, Täglich, Monatlich, Jährlich).
Anfänglich, Ich habe die gesamte Transaktionstabelle täglich neu geladen, obwohl ich die daten schon bis gestern bei mir hatte. Das hat nicht nur lange gedauert, es erhöhte auch die Belastung des Datenbankservers und des Netzwerks. Hier machte das inkrementelle Laden mit QVD einen großen Unterschied, indem nur neue oder aktualisierte Daten aus der Datenbank in eine Tabelle geladen wurden.
Inkrementelle Lasten:
Inkrementelles Laden ist definiert als die Aktivität, nur neue oder aktualisierte Datensätze aus der Datenbank in einen etablierten QVD zu laden. Inkrementelle Lasten sind nützlich, da sie im Vergleich zu Volllasten sehr effizient laufen, besonders für große Datensätze.
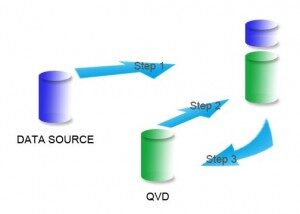
Inkrementelles Laden kann auf unterschiedliche Weise realisiert werden, gängige Methoden sind wie folgt:
- Nur einfügen (nicht auf doppelte Datensätze validieren)
- Einfügen und aktualisieren
- Einfügung, aktualisieren und löschen
Lass uns jedes davon verstehen 3 Szenarien mit einem Beispiel
1. Nur einfügen:
Nehmen wir an, wir haben rohe Verkaufsdaten (in Excel) und jedes Mal, wenn ein neuer Verkauf registriert wird, wird mit grundlegenden Details zum Verkauf bis zum Änderungsdatum aktualisiert. Da wir an QVD arbeiten, wir haben bereits QVD erstellt bis gestern (25 August 2014 in diesem Fall). Jetzt, Ich möchte nur die inkrementellen Datensätze laden (unten gelb markiert).
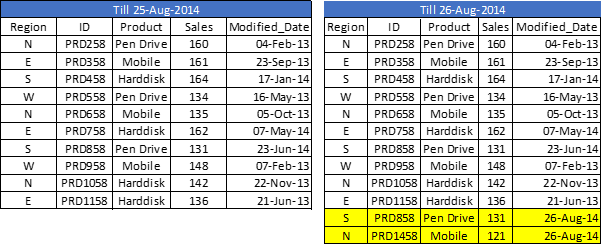
Um diese Übung durchzuführen, Erstellen Sie zuerst eine QVD für die Daten bis 25 August 2014. Um neue inkrementelle Datensätze zu identifizieren, Wir müssen das Datum wissen, bis zu dem, QVD ist bereits aktualisiert. Dies kann identifiziert werden, indem das Maximum von Modified_date in der verfügbaren QVD-Datei überprüft wird.
Wie bereits erwähnt, ich bin davon ausgegangen “Der Umsatz. qvd”Es wird mit Daten bis zu aktualisiert 25 August 2014. Um das letzte Änderungsdatum von . zu identifizieren “Der Umsatz. qvd”, Der folgende Code kann helfen:
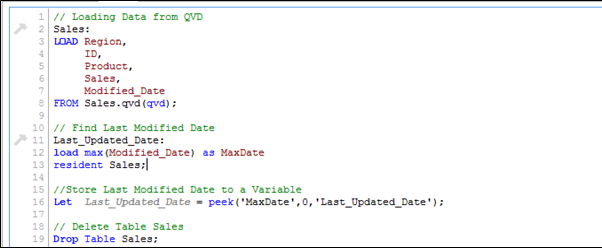
Hier, Ich habe die letzte aktualisierte QVD in den Speicher geladen und dann das Datum der letzten Änderung identifiziert, indem ich maximal gespeichert habe “Änderungsdatum”. Dann, wir speichern dieses Datum in einer Variablen “Last_Updated_Date“Und lass den Tisch fallen”Der Umsatz”. Im obigen Code, Ich habe benutzt Aussehen() Funktion zum Speichern des maximalen Änderungsdatums. Hier ist Ihre Syntax:
Spähen (Feldname, Zeilennummer, Tabellenname)
Diese Funktion gibt den Inhalt eines gegebenen Feldes für eine angegebene Zeile aus der internen Tabelle zurück. FieldName und TableName müssen als String angegeben werden und Row muss eine ganze Zahl sein. 0 bezeichnet den ersten Datensatz, 1 der zweite und so weiter. Negative Zahlen geben die Reihenfolge vom Ende der Tabelle an. -1 bezeichnet den letzten Datensatz.
Da wir das Datum kennen, ab dem die Datensätze als neue Datensätze gelten, wir können inkrementelle Datensätze aus dem Datensatz laden (Where-Klausel in der Load-Anweisung) und füge sie mit verfügbarem QVD zusammen (schau dir den Schnappschuss unten an).
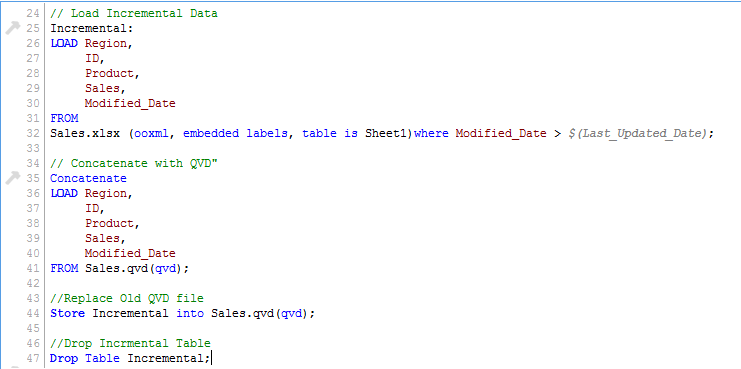
Jetzt, Aktualisierte QVD laden (Der Umsatz), hätte inkrementelle Datensätze.
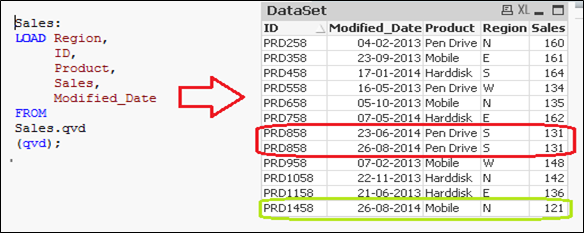
Wie du siehst, zwei Datensätze wurden hinzugefügt von 26 August 2014. Aber trotzdem, wir haben auch einen doppelten Datensatz eingefügt. Jetzt können wir sagen, dass eine Nur-INSERT-Methode keine doppelten Datensätze validiert, weil wir nicht auf die verfügbaren Datensätze zugegriffen haben.
Was ist mehr, Bei dieser Methode können wir den Wert vorhandener Datensätze nicht aktualisieren.
Um zusammenzufassen, Im Folgenden sind die Schritte aufgeführt, um nur die inkrementellen Datensätze in QVD mit der Methode INSERT only zu laden:
1) Identifizieren Sie neue Datensätze und laden Sie sie hoch
2) Verketten Sie diese Daten mit einer QVD-Datei
3) Ersetzen Sie die alte QVD-Datei durch eine neue verkettete Tabelle
2. Einfüge- und Aktualisierungsmethode:
Wie im vorherigen Beispiel zu sehen, Wir sind nicht in der Lage, die doppelte Datensatzprüfung durchzuführen und den vorhandenen Datensatz zu aktualisieren. Das ist wo, die Methode Einfügen und Aktualisieren hilft dabei:
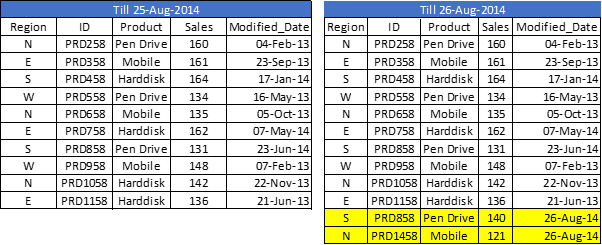
Im Datensatz oben (richtiger Tisch), Wir haben einen Rekord (ID = PRD1458) hinzufügen und noch mehr (ID = PRD858) zu verwirklichen (Verkaufswert von 131 ein 140). Jetzt, um doppelte Datensätze zu aktualisieren und zu überprüfen, wir brauchen einen Primärschlüssel in unserem Datensatz.
Angenommen, id ist der Primärschlüssel und, nach Änderungsdatum und Identifikation, wir sollten in der Lage sein, neue oder geänderte Datensätze zu identifizieren und zu klassifizieren.
Um diese Methode auszuführen, Befolgen Sie ähnliche Schritte, um die neuen Datensätze zu identifizieren, wie wir es bei der INSERT-only-Methode getan haben und während Sie die inkrementellen Daten mit einem vorhandenen verketten, Wir wenden die Überprüfung auf doppelte Datensätze an oder aktualisieren den Wert vorhandener Datensätze.
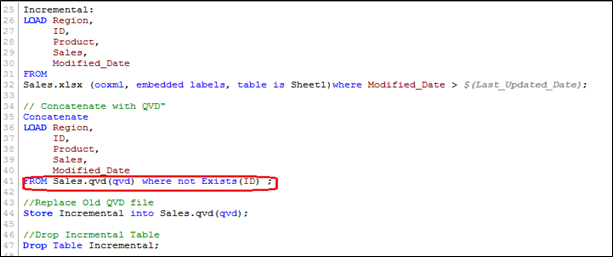
Hier, Wir haben nur die Datensätze geladen, bei denen der Primärschlüssel (ICH WÜRDE) ist neu und verwendet die Funktion Exists () verhindert, dass QVD veraltete Datensätze lädt, da sich die AKTUALISIERTE Version derzeit im Speicher befindet, so werden vorhandene Datensatzwerte automatisch aktualisiert.
Jetzt, Wir haben alle einzigartigen Datensätze, die in QVD verfügbar sind, mit einem aktualisierten Verkaufswert für ID (PRD858).
3. INSERT-Methode, AKTUALISIEREN UND LÖSCHEN:
Das Skript für diese Methode ist INSERT . sehr ähnlich & AKTUALISIEREN, aber trotzdem, Hier ist ein zusätzlicher Schritt erforderlich, um die gelöschten Datensätze zu löschen.
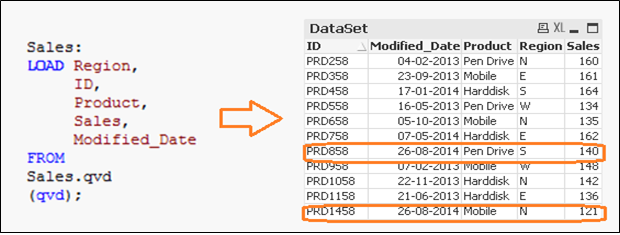
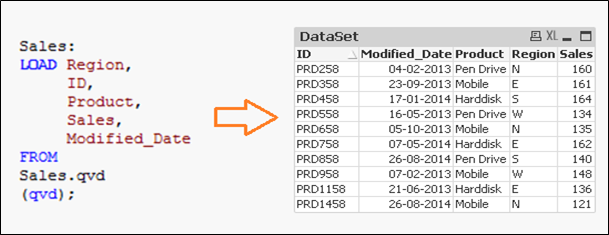
Wir laden die Primärschlüssel aller Datensätze des aktuellen Datensatzes und wenden einen Inner Join mit dem verketteten Datensatz an (Alt + Inkrementell). Der innere Join behält nur die gemeinsamen Register und, Daher, löscht unerwünschte Datensätze. Angenommen, wir möchten einen Datensatz löschen aus (ID PRD1058) im Beispiel oben.
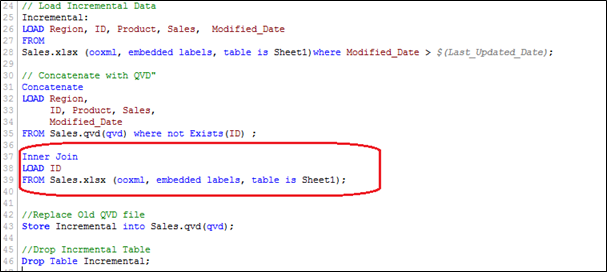
Hier, wir haben einen Datensatz mit dem Zusatz eines Datensatzes (ID PRD1458), einen Datensatz ändern (ID PRD158) und Löschen eines Datensatzes (ID PRD1058).
Abschließende Anmerkungen:
In diesem Artikel, Wir haben diskutiert, wie inkrementelle Ladevorgänge besser sind und eine effiziente Möglichkeit zum Laden von Daten im Vergleich zu VOLLSTÄNDIGEN Ladevorgängen bieten. Als gute Praxis, Sie sollten eine regelmäßige Sicherung Ihrer Daten erstellen, da diese beeinträchtigt werden können oder es zu Datenverlusten kommen kann, bei Problemen mit dem Datenbankserver und dem Netzwerk.
Abhängig von Ihrer Branche und dem Bedarf der Anwendung, Sie können auswählen, welche Methode für Sie geeignet ist. Die meisten gängigen Anwendungen in der BFSI-Branche basieren auf Insert und Update. Das Löschen von Datensätzen wird normalerweise nicht verwendet.
Kennen Sie eine ähnliche Situation oder haben Sie einen anderen Trick unter dem Hut, um die Effizienz von Qlikview-Anwendungen zu verbessern?? Wenn ja, Ich würde gerne Ihre Gedanken durch die Kommentare unten hören., da es auch anderen zugute kommt, die versuchen, mit einer ähnlichen Situation umzugehen.





