[*]
Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Eines der Hauptprobleme, mit denen jeder konfrontiert ist, wenn er zum ersten Mal strukturiertes Streaming ausprobiert, ist das Einrichten der Umgebung, die zum Streamen seiner Daten erforderlich ist.. Wir haben einige Online-Tutorials, wie wir das einrichten können. Die meisten von ihnen konzentrieren sich darauf, Sie aufzufordern, eine virtuelle Maschine und ein Ubuntu-Betriebssystem zu installieren und dann alle erforderlichen Dateien zu konfigurieren, indem Sie die Bash-Datei ändern. Das funktioniert gut, aber nicht für alle. Sobald wir eine virtuelle Maschine verwenden, Manchmal müssen wir möglicherweise lange warten, wenn wir Maschinen mit weniger Speicher haben. Der Prozess kann aufgrund von Problemen mit der Speicherverzögerung stecken bleiben. Dann, für eine bessere Möglichkeit und eine einfache Bedienung, Ich zeige Ihnen, wie wir strukturiertes Streaming in unserem Windows-Betriebssystem konfigurieren können.
Gebrauchte Werkzeuge
Für die Konfiguration verwenden wir folgende Tools:
1. Kafka (zur Datenübertragung, fungiert als Produzent)
2. Tierpfleger
3. Pyspark (um die übermittelten Daten zu generieren, handelt als Verbraucher)
4. Jupyter-Notizbuch (Code-Editor)
Umgebungsvariablen
Es ist wichtig zu beachten, dass hier, Ich habe alle Dateien in Laufwerk C hinzugefügt. Was ist mehr, der Name muss mit dem der Dateien übereinstimmen, die Sie online installieren.
Wir müssen die Umgebungsvariablen setzen, wenn wir diese Dateien installieren. Bitte beachten Sie diese Bilder während der Installation für eine problemlose Erfahrung.
Das letzte Bild ist der Pfad der Systemvariablen.
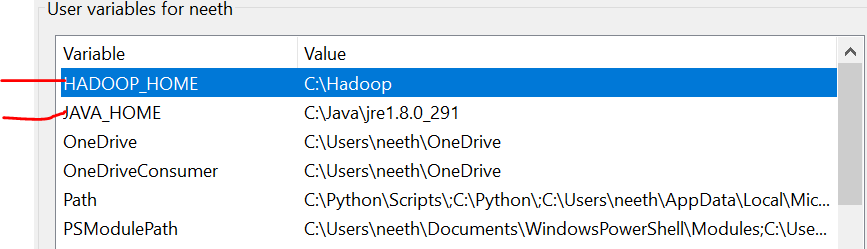
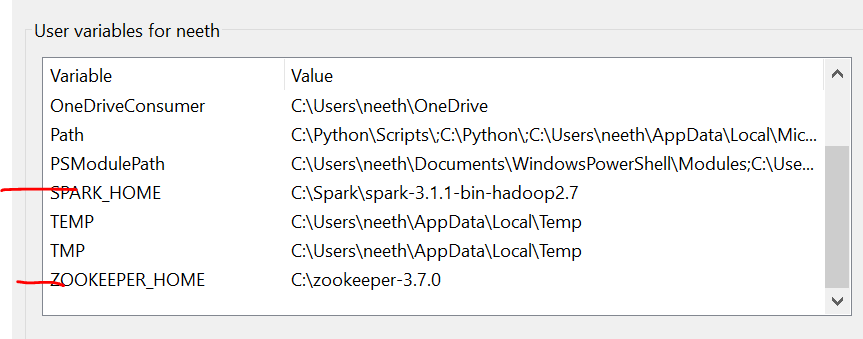
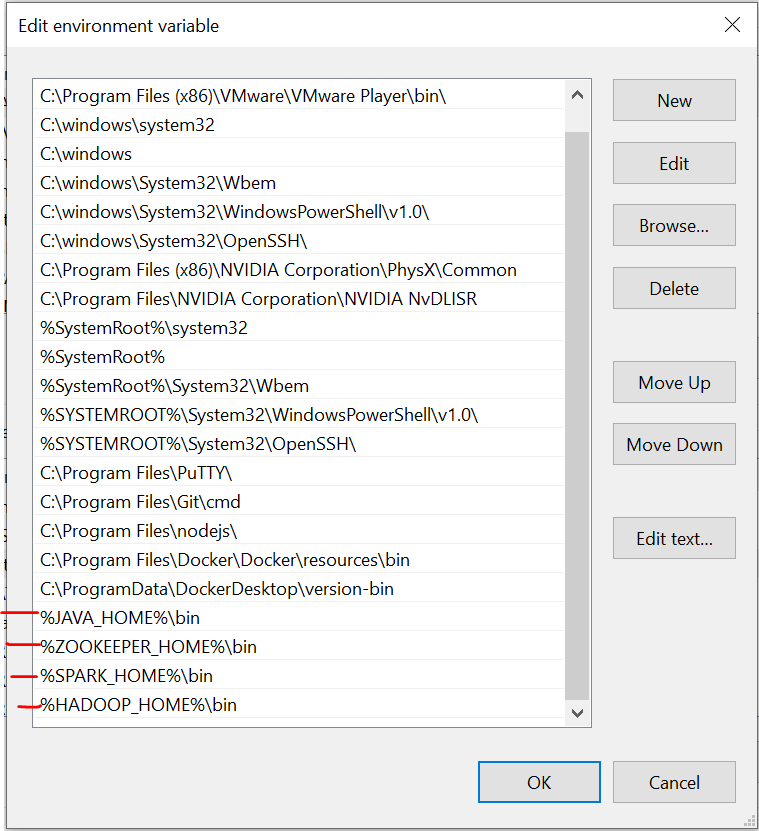
Erforderliche Dateien
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp=teilen
Kafka-Installation
Der erste Schritt ist die Installation von Kafka auf unserem System. Dazu müssen wir auf diesen Link gehen:
https://dzone.com/articles/running-apache-kafka-on-windows-os
Wir müssen Java installieren 8 zunächst und setzen Sie Umgebungsvariablen. Sie können alle Anweisungen über den Link erhalten.
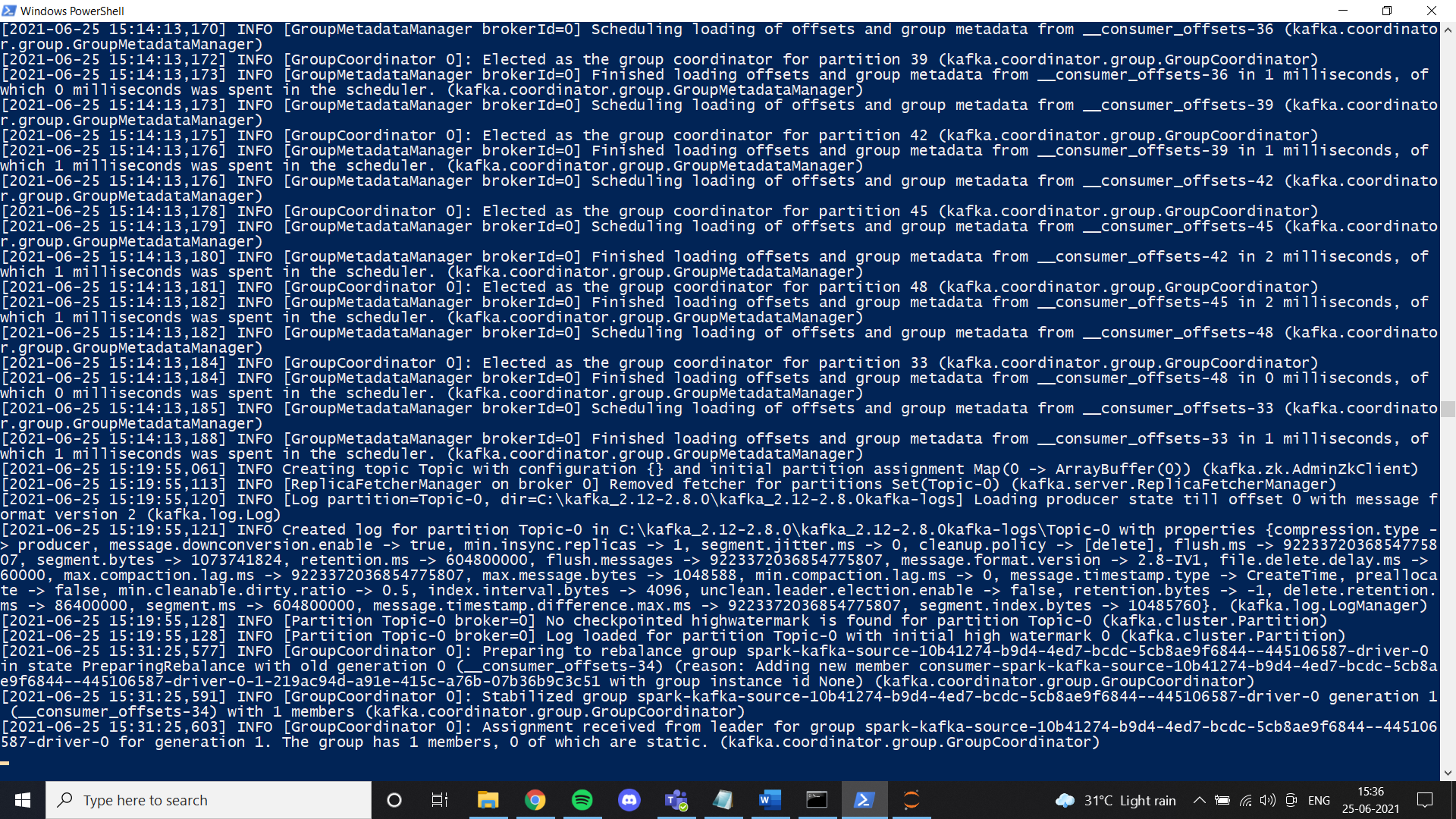
Sobald wir mit Java fertig sind, wir müssen einen Tierpfleger einsetzen. He agregado archivos de guardián del zoológico en Google Drive. Siéntase libre de usarlo o simplemente siga todas las instrucciones dadas en el enlace. Si instaló zookeeper correctamente y configuró la variable de entorno, puede ver este resultado cuando ejecute zkserver como administrador en el símbolo del sistema.
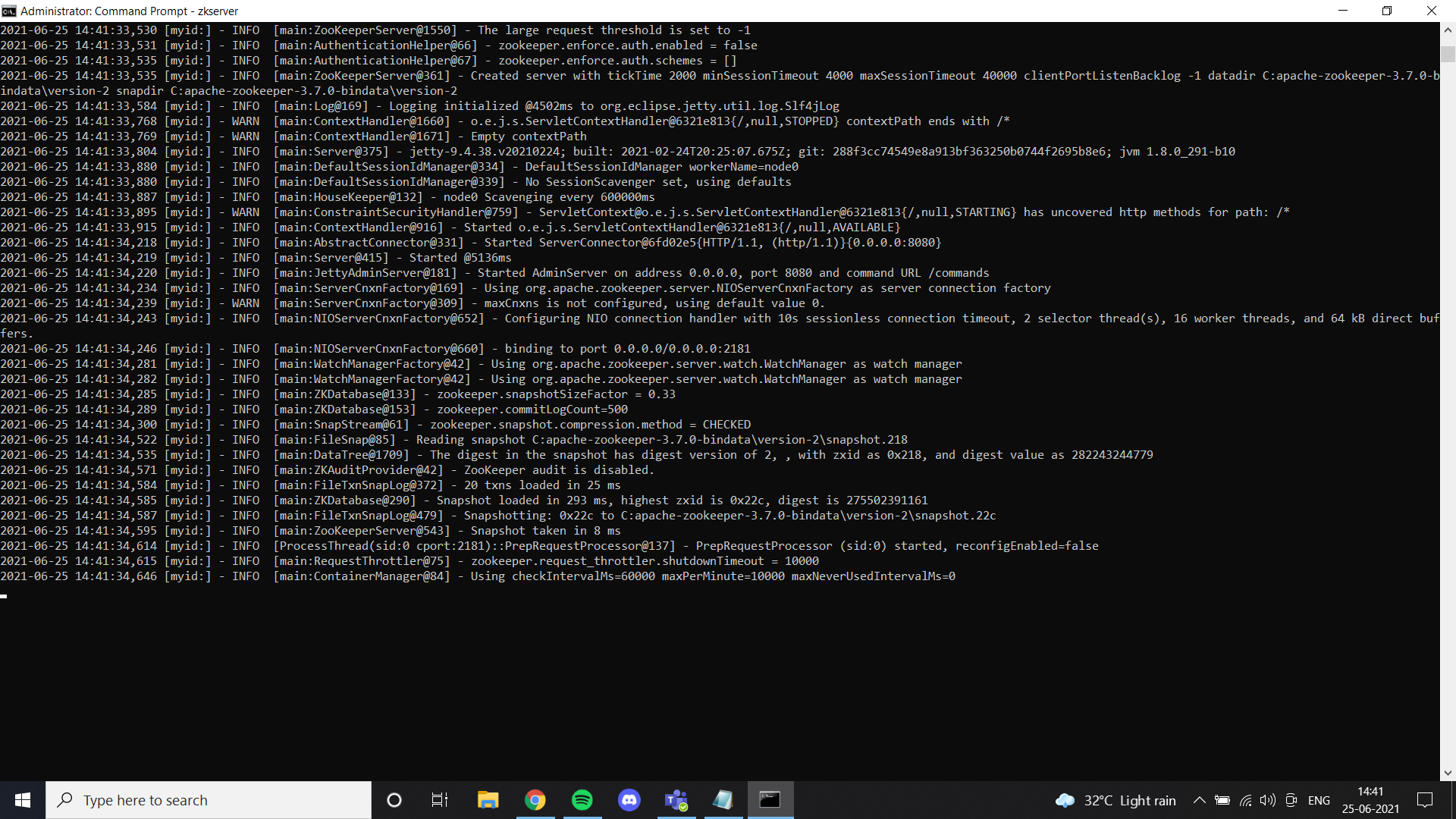
Dann, instale Kafka según las instrucciones del enlace y ejecútelo con el comando especificado.
.binwindowskafka-server-start.bat .configserver.properties
Una vez que todo esté configurado, Versuchen Sie, ein Thema zu erstellen und zu überprüfen, ob es richtig funktioniert. Wenn ja, Sie haben die Kafka-Installation abgeschlossen.
Funkeninstallation
In diesem Schritt, instalamos Spark. Grundsätzlich, Sie können diesem Link folgen, um Spark auf Ihrem Windows-Rechner zu konfigurieren.
https://phoenixnap.com/kb/install-spark-on-windows-10
Während eines der Schritte, Es wird nach der Konfiguration der Winutils-Datei gefragt. Für Ihren Komfort, Ich habe die Datei dem Drive-Link hinzugefügt, den ich geteilt habe. In einem Ordner namens Hadoop. Legen Sie diesen Ordner einfach auf Ihrem Laufwerk C ab und legen Sie die Umgebungsvariable wie in den Bildern gezeigt fest. Ich empfehle Ihnen dringend, die Spark-Datei zu verwenden, die ich zu Google Drive hinzugefügt habe. Einer der Hauptgründe ist die Datenübertragung, die wir benötigen, um eine strukturierte Übertragungsumgebung manuell einzurichten. In unserem Fall, Ich habe alle notwendigen Dinge konfiguriert und die Dateien nach vielen Versuchen geändert. Falls Sie eine neue Konfiguration vornehmen möchten, mach es gerne. Wenn die Konfiguration nicht richtig funktioniert, Bei der Übertragung von Daten in pyspark erhalten wir einen solchen Fehler:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Sobald wir eins sind mit Spark, Jetzt können wir die erforderlichen Daten aus einer CSV-Datei in einen Producer streamen und mit dem Kafka-Theme in einen Consumer holen. Ich arbeite hauptsächlich mit dem Jupiter-Notizbuch und, Daher, Ich habe ein Notizbuch für dieses Tutorial verwendet.
Zuerst in deinem Notizbuch, Sie müssen einige Bibliotheken installieren:
1. pip installiert pyspark
2. Pip-Installer Kafka
3. pip installieren py4j
Wie funktioniert strukturiertes Streaming mit Pyspark?
Wir haben eine CSV-Datei mit Daten, die wir übertragen möchten. Fahren wir mit dem klassischen Iris-Dataset fort. Jetzt, wenn wir die Irisdaten übertragen wollen, wir müssen Kafka als Produzent verwenden. Kafka, wir erstellen ein Thema, an das wir die Iris-Daten übermitteln und der Verbraucher kann den Datenrahmen dieses Themas abrufen.
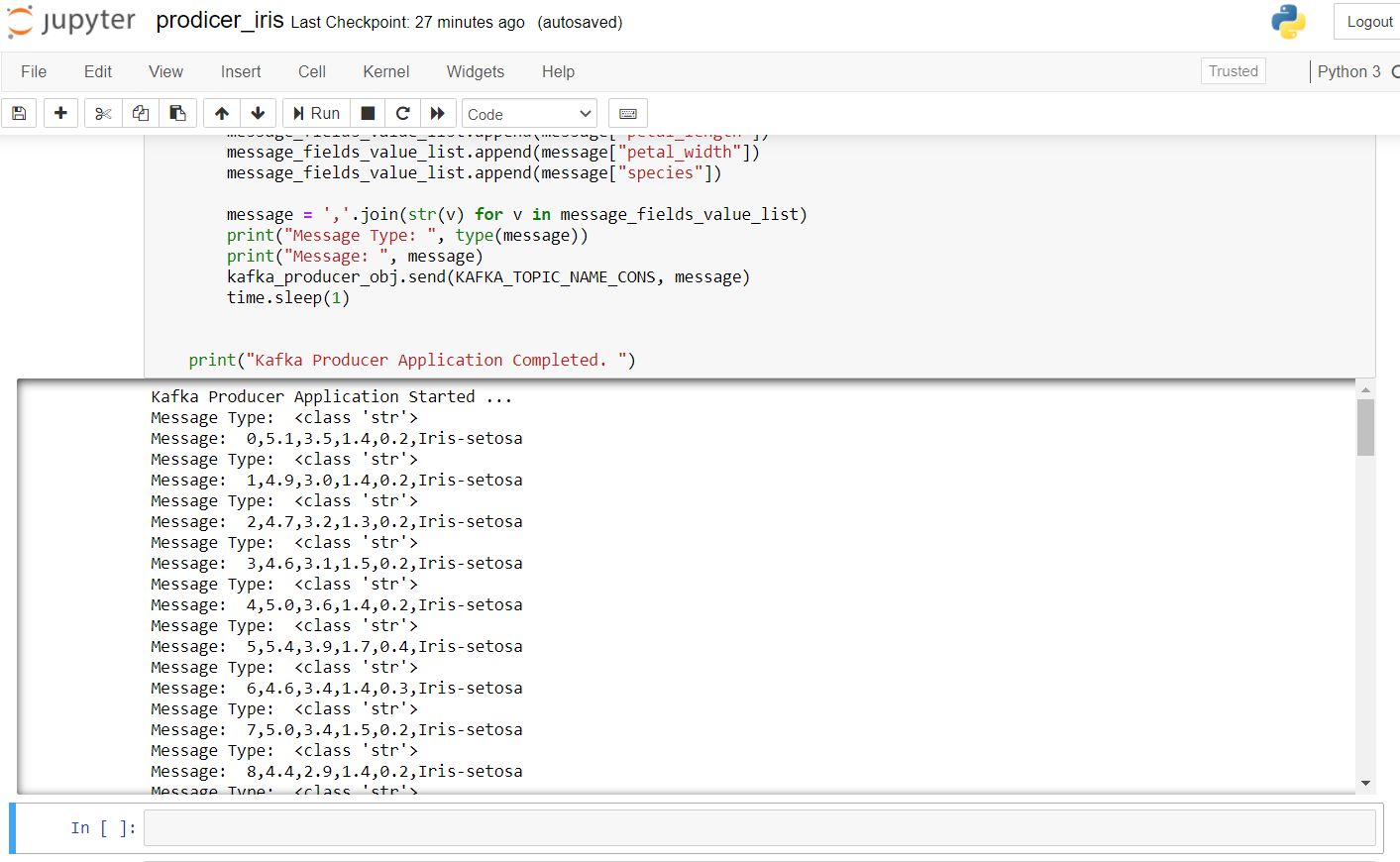
Das Folgende ist der Herstellercode zum Übertragen von Irisdaten:
Para iniciar el productor, tenemos que ejecutar zkserver como administrador en el símbolo del sistema de Windows y luego iniciar Kafka usando: .binwindowskafka-server-start.bat .configserver.properties desde el símbolo del sistema en el directorio de Kafka. Si obtiene un error de “no broker”, significa que Kafka no se está ejecutando correctamente.
El resultado después de ejecutar este código en el cuaderno jupyter se ve así:
Jetzt, revisemos al consumidor. Ejecute el siguiente código para ver si funciona bien en un nuevo portátil.
Una vez que ejecute esto, debería obtener un resultado como este:
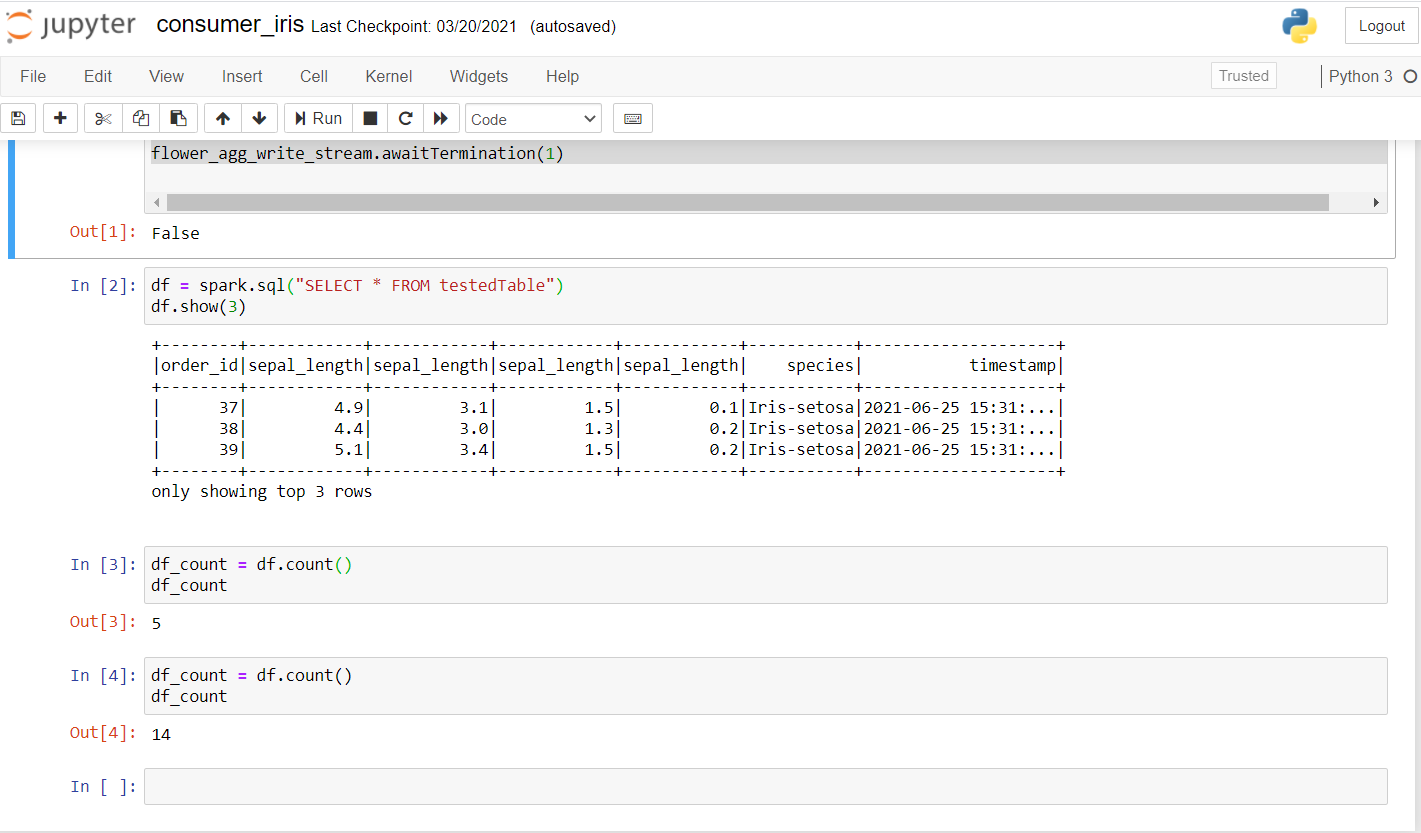
Wie du siehst, habe ein paar Anfragen gestellt und geprüft, ob die Daten übertragen wurden. Das erste Konto war 5 Ja, nach ein paar sekunden, das Konto wurde erhöht auf 14, Bestätigung, dass Daten übertragen werden.
Hier, Grundsätzlich, Die Idee ist, einen Funkenkontext zu schaffen. Wir erhalten die Daten, indem wir Kafka zu unserem Thema auf dem angegebenen Port übermitteln. Spark-Sitzung kann mit getOrCreate erstellt werden () wie im Code gezeigt. Im nächsten Schritt wird der Kafka-Stream gelesen und die Daten können mit load . geladen werden (). Da die Daten übertragen werden, es wäre nützlich, einen Zeitstempel zu haben, in dem jeder der Datensätze angekommen ist. Wir spezifizieren das Schema wie in unserem SQL und erstellen abschließend einen Datenrahmen mit den Werten der übertragenen Daten mit seinem Zeitstempel. Schließlich, mit einer Bearbeitungszeit von 5 Sekunden, Wir können Daten in Stapeln empfangen. Wir verwenden SQL View, um Daten im angehängten Modus vorübergehend im Speicher zu speichern, und wir können alle Operationen mit unserem Spark-Datenrahmen ausführen.
Den vollständigen Code finden Sie hier:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
Dies ist eines meiner Spark-Streaming-Projekte, Sie können sich für detailliertere Abfragen und die Verwendung von maschinellem Lernen in Spark darauf beziehen:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
Verweise
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Vorschaubild -> https://unsplash.com/photos/ImcUkZ72oUs
Fazit
Wenn Sie diese Schritte befolgen, Sie können alle Umgebungen einfach konfigurieren und Ihr erstes strukturiertes Streaming-Programm mit Spark und Kafka . ausführen. Bei Schwierigkeiten bei der Einrichtung, Zögere nicht mich zu kontaktieren:
[E-Mail geschützt]
https://www.linkedin.com/in/siddharth-m-426a9614a/





