Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
CSV es ist ein typisches Datei Format nämlich häufig verwendet in Domänen wie METROOnetario Dienstleistungen, etc. Die meisten Anwendungen Sie können aktivieren Sie importieren und exportieren Wissen im CSV-Format.
Deswegen, es ist notwendig induzieren ein gutes verständnis vom CSV-Format zu einem höheren Treiber die Daten Sie sind verwenden mit Täglich.
Dann, entlang des Dieser Beitrag, wir werden mehrere Fälle von sehen Betriebs mit CSV-Dateien und bieten Beispiele, um alles zu verlinken entlang des.
Inhaltsverzeichnis
1. Was ist CSV?
2. Grundlegende Operationen mit CSV-Dateien
- Mit CSV-Dateien arbeiten
- Öffnen Sie eine CSV-Datei
- CSV-Datei speichern
3. Warum CSV-Dateien?
4. Grundlagen der Read_csv-Funktion () von Pandas
- Pandas importieren
- Öffnen Sie eine lokale CSV-Datei
- Öffnen Sie eine CSV-Datei über eine URL
5. Comprender los ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten.... de la función read_csv ()
- sep-Parameter
- index_col-Parameter
- Kopfzeilenparameter
- use_cols-Parameter
- Kompressionsparameter
- Parameter überspringen
- nrows-Parameter
- Codierungsparameter
- error_bad_lines-Parameter
- dtype-Parameter
- parse_dates-Parameter
- Konverterparameter
- na_values-Parameter
Lasst uns beginnen,
Was ist eine CSV?
CSV (Komma-getrennte Werte) vielleicht ein einfaches Dateiformat Gebraucht um tabellarische Daten zu speichern, mögen una hoja de cálculo o una DatenbankEine Datenbank ist ein organisierter Satz von Informationen, mit dem Sie, Effizientes Verwalten und Abrufen von Daten. Einsatz in verschiedenen Anwendungen, Von Unternehmenssystemen bis hin zu Online-Plattformen, Datenbanken können relational oder nicht-relational sein. Das richtige Design ist entscheidend für die Optimierung der Leistung und die Gewährleistung der Informationsintegrität, und erleichtert so eine fundierte Entscheidungsfindung in verschiedenen Kontexten..... CSV-Datei speichert Tabellendaten (Zahlen und Text) im Klartext. Jede Zeile der Datei könnte ein Datenregister. Jeder Datensatz besteht von 1 oder mehr Felder, durch Kommata abgetrennt, die Nutzung Komma als Feldtrennzeichen Ist das das Quelle für dieses Dateiformat benennen.
Grundlegende Operationen mit CSV-Dateien
In Grundfunktionen, Lass uns die folgenden drei Dinge verstehen:
- So arbeiten Sie mit CSV-Dateien
- So öffnen Sie eine CSV-Datei
- So speichern Sie eine CSV-Datei
Mit CSV-Dateien arbeiten
Mit CSV-Dateien arbeiten Es ist nicht diese mühsame Aufgabe, aber es ist ganz einfach. Aber trotzdem, zählen auf Ihr Arbeitsablauf, dort Es kann sein Warnungen das einfach vielleicht willst du beobachten Aus für.
Öffnen Sie eine CSV-Datei
Und Sie haben eine CSV-Datei, Sie öffne es in Excel ohne viel Mühe. Einfach Excel öffnen, geöffnet und finde die CSV-Datei herauszufinden mit (oder klicken Sie mit der rechten Maustaste auf die CSV-Datei und wählen Sie In Excel öffnen). Nach dem Öffnen der Datei, das wirst du merken die info es ist einfach Klartext in verschiedenen Zellen.
CSV-Datei speichern
Und das hättest du wohl gerne um viel zu sparen Ihre aktuelle Arbeitsmappe in einer CSV-Datei, Sie haben benutzen das hintere Befehle:
Archiv -> Speichern als … und wählen Sie CSV-Datei.
Meistens, Sie erhalten diese Warnung:

Bildquelle: Google Bilder
Lassen Sie uns verstehen, was uns dieser Fehler sagt.
Hier versucht Excel zu erwähnen ist, dass Ihre CSV-Dateien keine speichern vernünftig Formatierung im mindesten.
Zum Beispiel, Spaltenbreiten werden nicht gespeichert, Schriftstile, Farben, etc.
Nur deine alten Daten ist es so Gerettet in einem übermäßig kommagetrennte Datei.
Beachten Sie, dass auch nach Ihnen leg es zur Seite, Excel zeigt weiterhin die Formate an dass du allein ich hatte, Also lass dich davon nicht täuschen und denk das nach dem Öffnen die Arbeitsmappe wieder, dass ihre Formate noch da sein werden. Sie werden nicht sein.
Auch nach dem Öffnen einer CSV Komm herein Excel, wenn Sie ein ausreichendes Format anwenden im mindesten, So passen Sie die Breite der Spalten an Übung die info, Excel wird Sie trotzdem warnen dass du allein Ich kann die Formate nicht speichern dass du allein zusätzlich, Sie bekomme so eine Warnung:

Bildquelle: Google Bilder
Dann, das ziel Verwendet nämlich seine Formate können niemals in CSV-Dateien gespeichert werden.
Warum CSV-Dateien?
CSV-Dateien werden verwendet als der einfachste Weg sprechen Daten zwischen verschiedenen Anwendungen. Angenommen, Sie haben eine Datenbankanwendung und möchten exportieren die info in eine Datei. Und das hättest du wohl gerne um es in eine Excel-Datei zu exportieren, die Datenbankanwendung würdest du unterstützt den Export in XLS-Dateien *.
Aber trotzdem, da das CSV-Dateiformat es ist ganz einfach und Licht (viel viel Daher als XLS-Dateien *), es ist einfacher für abwechslungsreich Apps, um es zu unterstützen. In seiner grundlegenden Verwendung, hat eine Textzeile, mit jeden Säule von Dateien und alternative Wege für ein Komma. Das ist es. Und wegen dieser Einfachheit, Es ist einfach für Entwickler. machen Export Import praktischer Sinn mit CSV-Dateien zum Übertragen Wissen zwischen Apps anstatt viel anspruchsvoll Dateiformate.
Zum Beispiel,
Lass uns ein .... haben tabellarische Daten im unten angegebenen Formular:

Wenn wir diese Daten in a . umwandeln CSV-Format, also sieht es so aus:

Jetzt, wir sind mit allen Grundlagen von CSV-Dateien fertig. Dann, auf der Rückseite des Artikels, wir besprechen, wie man mit CSV-Dateien im Detail arbeitet.
Pandas importieren
Zuerst, wir importieren die notwendigen Abhängigkeiten als Pandas Python-Bibliothek.
Pandas als pd importieren
Dann, Abhängigkeit wird importiert, jetzt können wir den Datensatz einfach laden und lesen.
CSV-Lesefunktion
- Es ist eine wichtige Funktion von Pandas, CSV-Dateien zu lesen und Operationen an ihnen durchzuführen.
- Diese Funktion hilft uns, die Datei von Ihrem lokalen Computer oder von einer beliebigen URL zu laden.
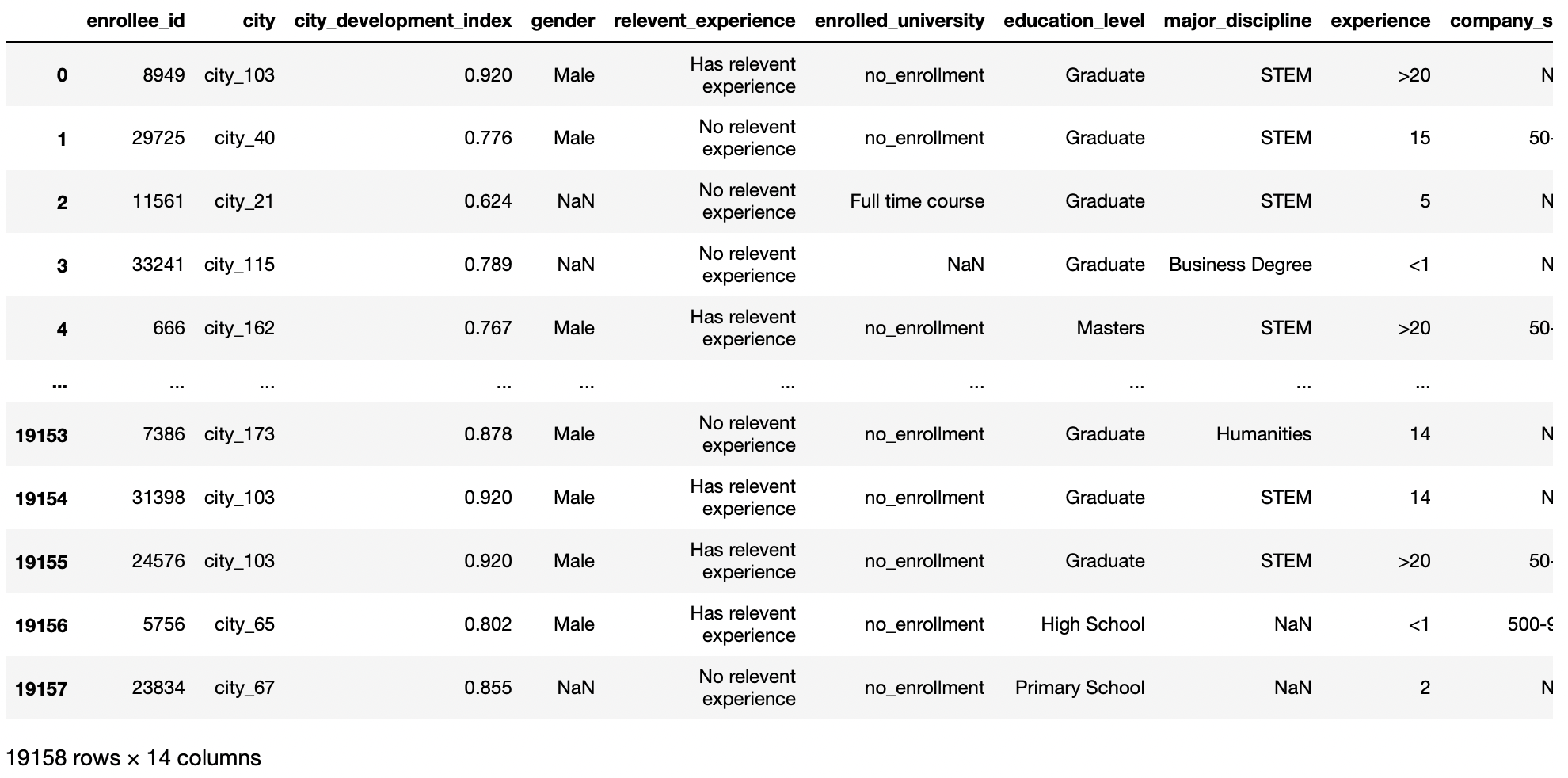
Öffnen Sie eine lokale CSV-Datei
Wenn sich die Datei am selben Ort wie in unserer Python-Datei befindet, Geben Sie dann den Dateinamen ein, um diese Datei hochzuladen; andererseits, Sie müssen den Pfad relativ dazu angeben.
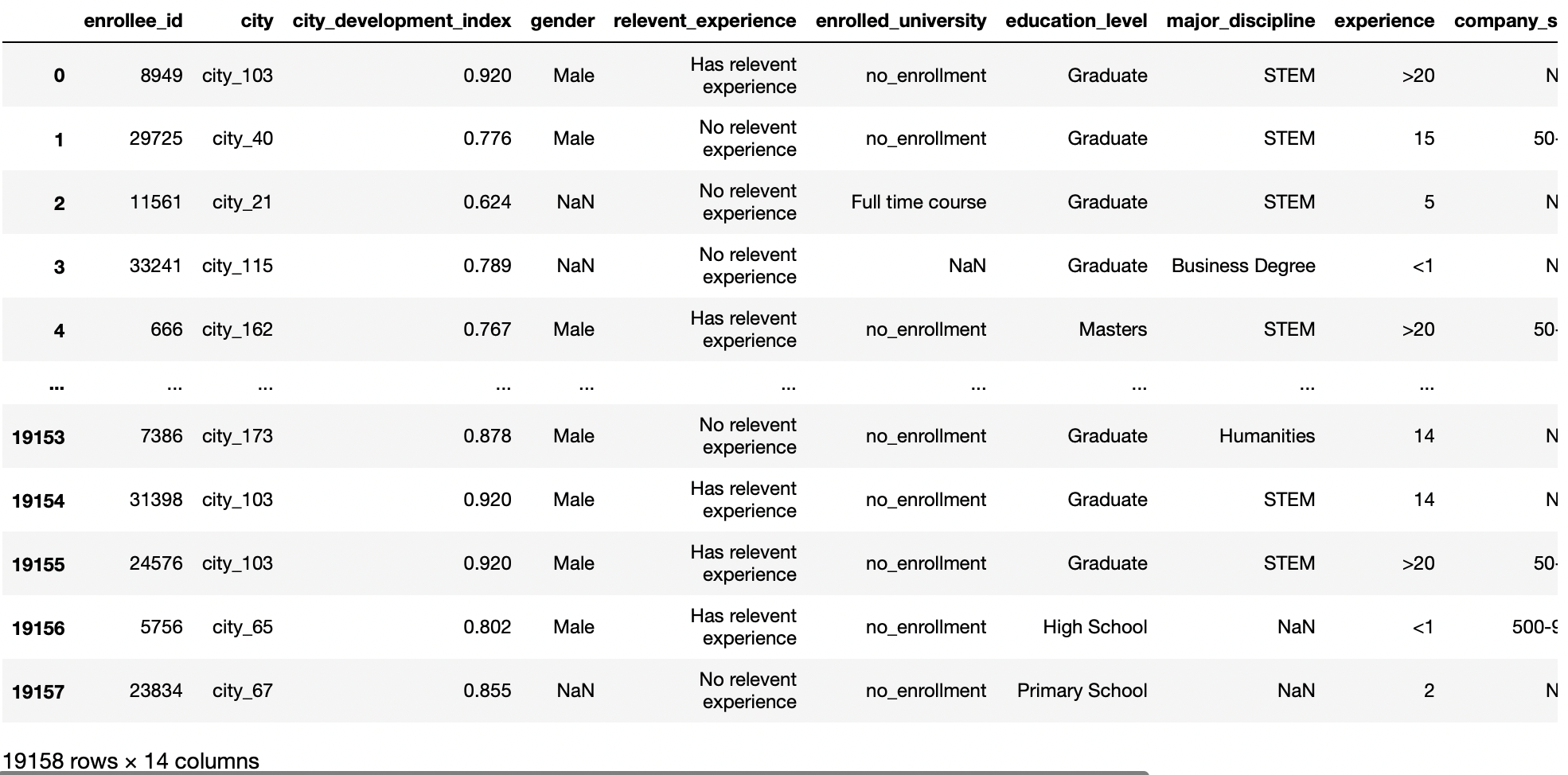
df = pd.read_csv('aug_train.csv')
df
Produktion:
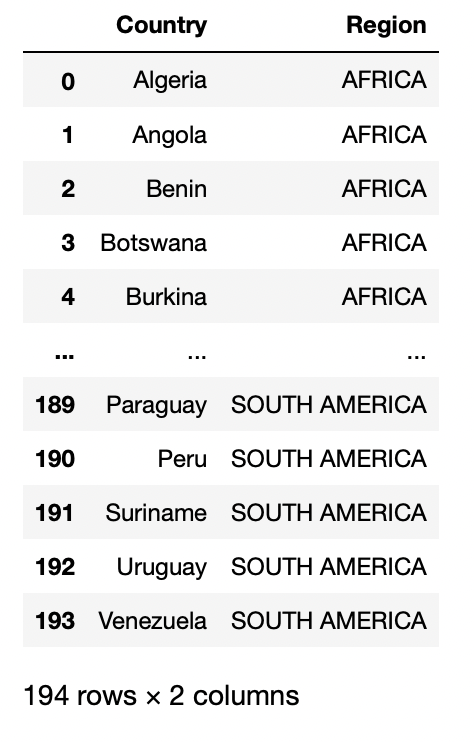
Öffnen Sie eine CSV-Datei über eine URL
Wenn die Datei nicht direkt auf unserem lokalen Computer vorhanden ist, aber wir müssen die Daten einer bestimmten URL suchen, dann nehmen wir die Hilfe des Requests-Moduls, um diese Daten zu laden.
Importanfragen
aus io importieren StringIO
URL = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
Überschriften = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0"}
req = Anfragen.get(URL, headers=header)
data = StringIO(Anf.text)
pd.read_csv(Daten)
Produktion:
sep-Parameter
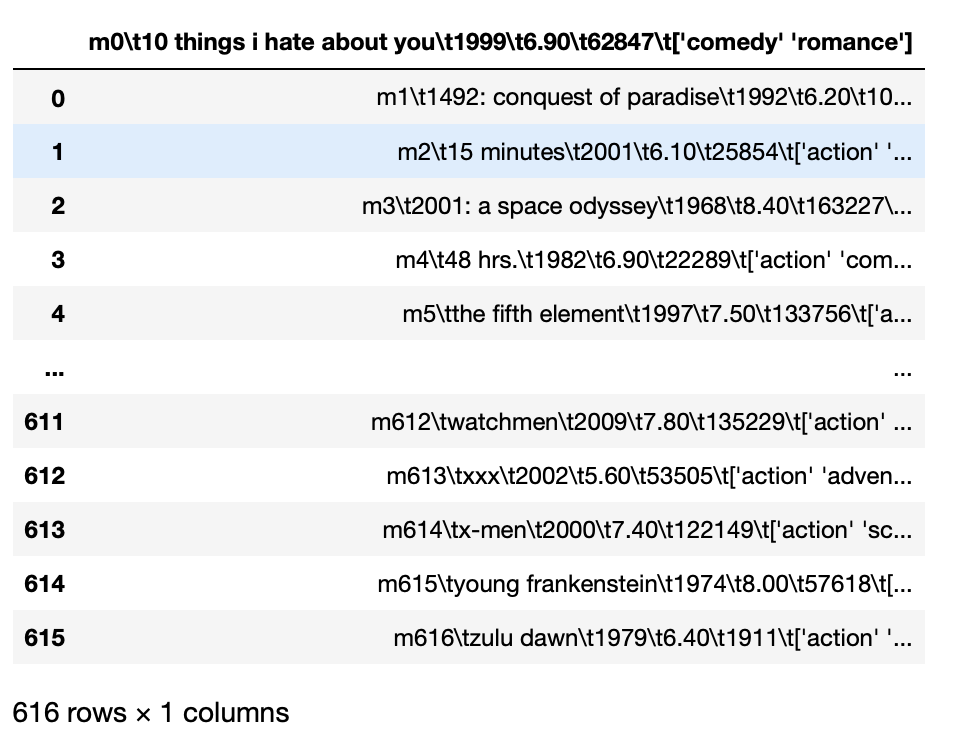
Wenn wir einen Datensatz haben, in dem die Entitäten in einer bestimmten Zeile nicht durch ein Komma getrennt sind, dann müssen wir den sep-Parameter verwenden, um das Trenn- oder Trennzeichen anzugeben.
Zum Beispiel, Wenn wir eine TSV-Datei haben, nämlich, die Entitäten sind durch Tabs getrennt und wenn wir versuchen, diese Daten direkt zu laden, alle Entitäten werden kombiniert geladen.
Pandas als pd importieren
pd.read_csv('movie_titles_metadata.tsv')
Produktion:
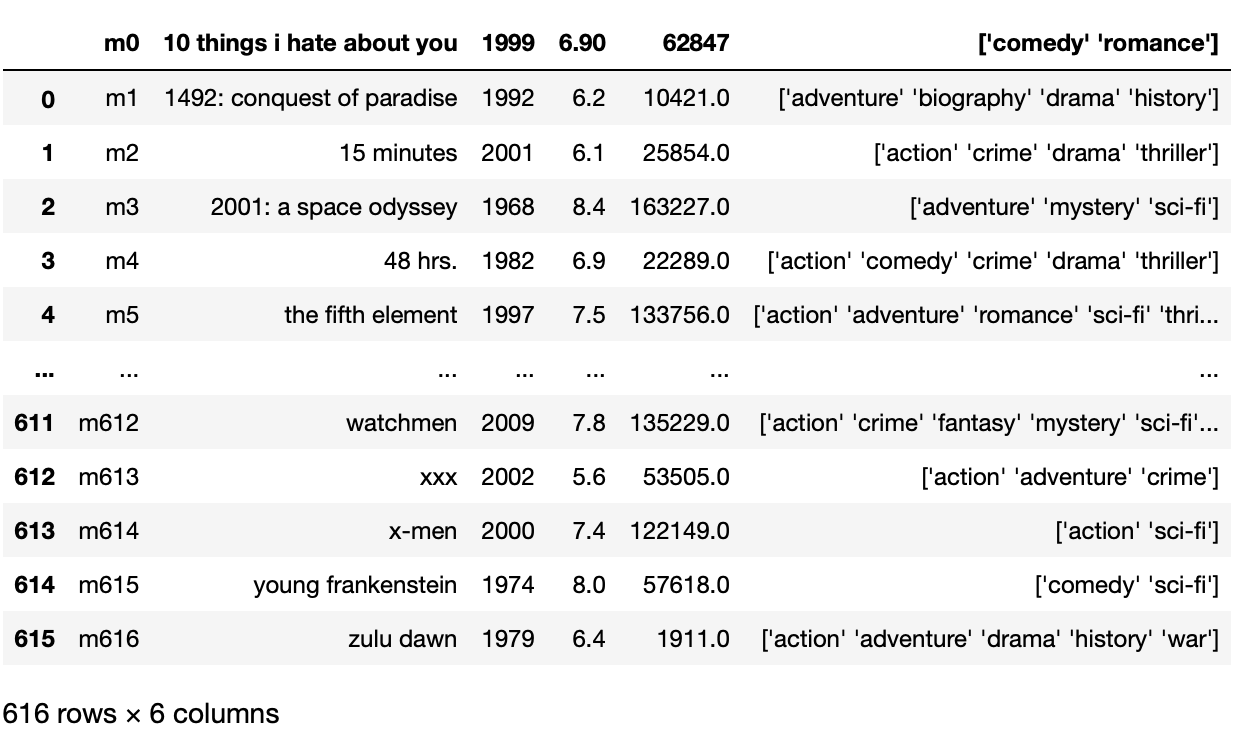
Um das obige Problem für die CSV-Datei zu lösen, wir müssen den sep-Parameter überschreiben zu ‚T‘ anstatt ‚,‘ das ist ein Standardtrennzeichen.
Pandas als pd importieren
pd.read_csv('movie_titles_metadata.tsv',sep = 't')
Produktion:
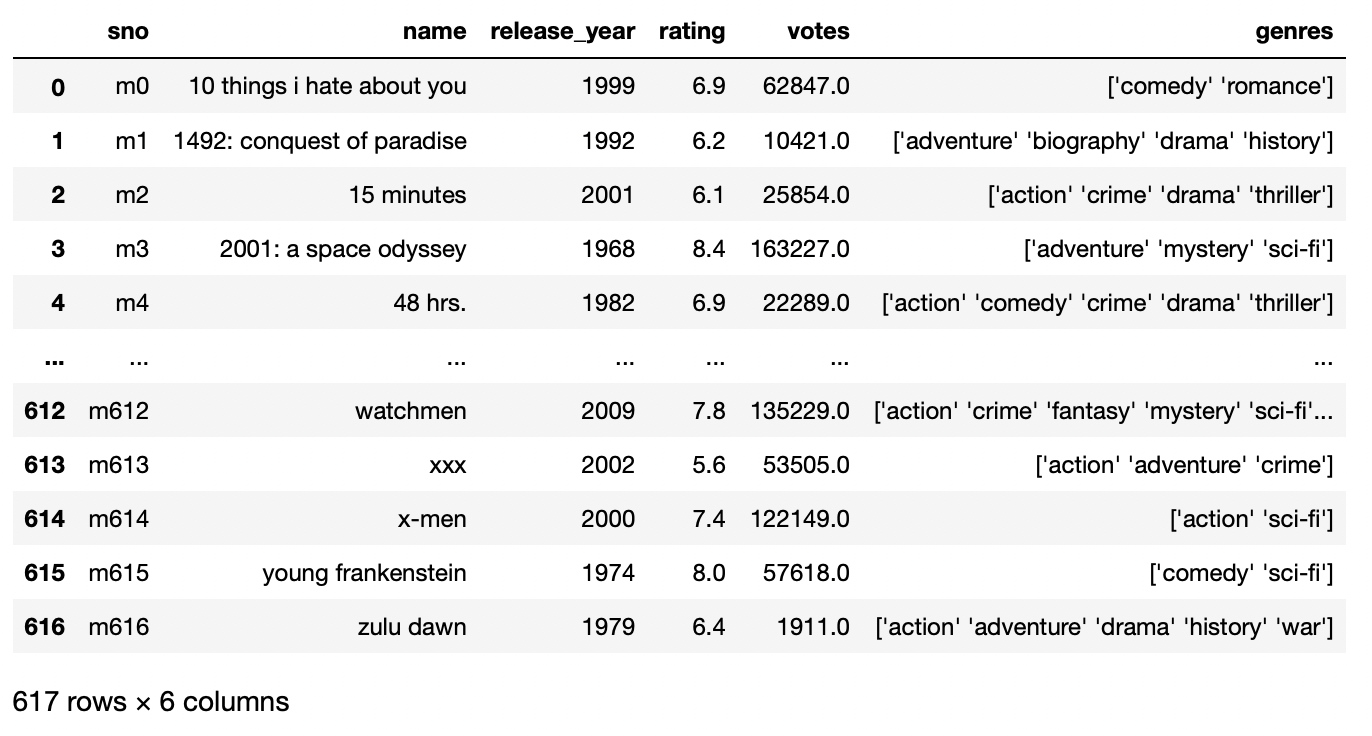
Im obigen Beispiel, Wir haben beobachtet, dass die erste Zeile als Name der Spalte behandelt wird, und um dieses Problem zu lösen und unseren benutzerdefinierten Namen für die Spalten zu erstellen, wir müssen die Liste der Wörter mit Namen als Namen der Liste angeben.
pd.read_csv('movie_titles_metadata.tsv',sep = 't',Namen=['schnein','Name','Erscheinungsjahr','Bewertung','Stimmen','Genres'])
Produktion:
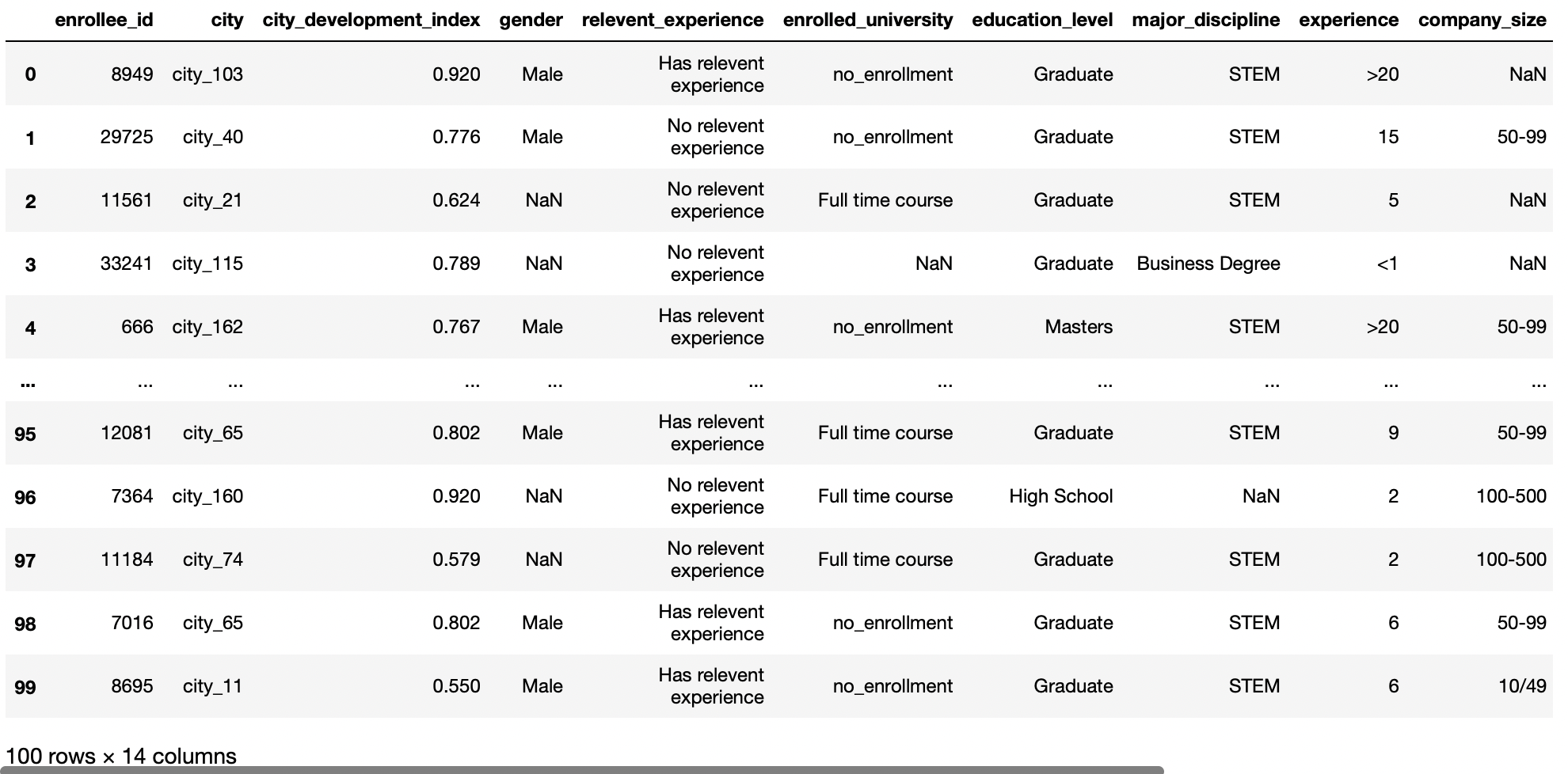
Index-Spalte-Parameter
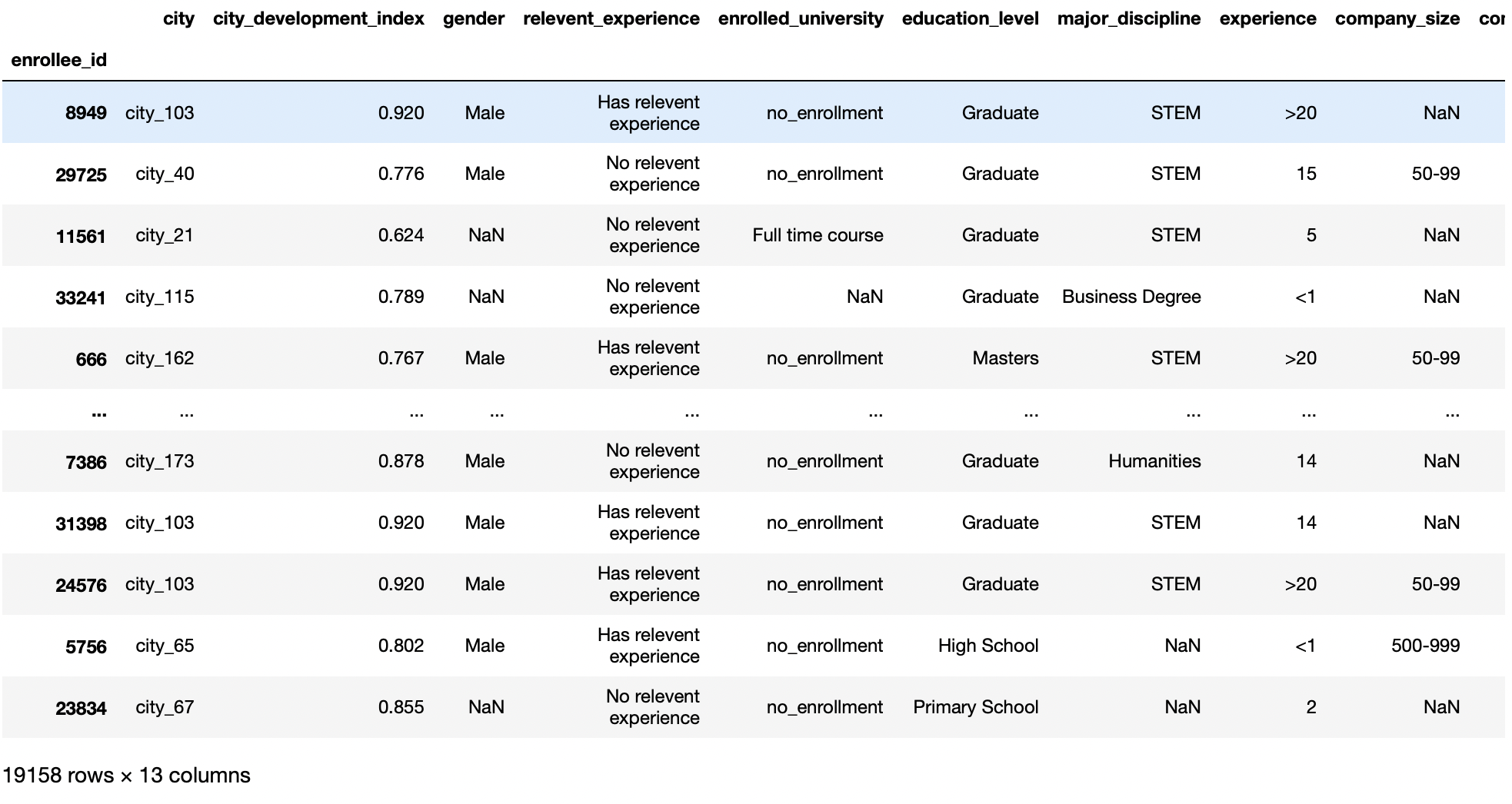
Este parámetro nos permite establecer qué columnas se utilizarán como IndexDas "Index" Es ist ein grundlegendes Werkzeug in Büchern und Dokumenten, Dies ermöglicht es Ihnen, die gewünschten Informationen schnell zu finden. Allgemein, Sie wird am Anfang einer Arbeit präsentiert und organisiert die Inhalte hierarchisch, mit Kapiteln und Abschnitten. Die richtige Vorbereitung erleichtert die Navigation und verbessert das Verständnis des Materials, was es zu einer unverzichtbaren Ressource sowohl für Studenten als auch für Fachleute in verschiedenen Bereichen macht.... des Datenrahmens. Der Standardwert für diesen Parameter ist Keine, und Pandas fügen automatisch eine neue Spalte hinzu, beginnend mit 0 um die Indexspalte zu beschreiben.
Dann, ermöglicht es uns, eine Spalte als Zeilenbeschriftung für einen bestimmten DataFrame zu verwenden. Diese Funktion ist nützlich, wenn wir eine ID-Spalte mit unserem Datensatz haben können und diese Spalte nicht von unseren Vorhersagen betroffen ist, Also machen wir diese Spalte zu unserem Zeilenindex anstelle des Standardwertes.
pd.read_csv('aug_train.csv',index_col="enrollee_id")
Produktion:
Kopfzeilenparameter
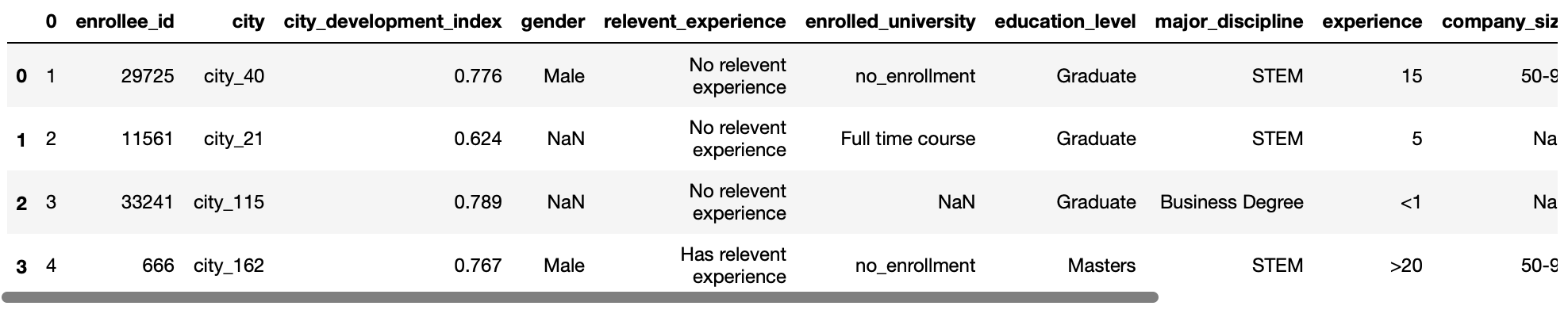
Auf diese Weise können wir festlegen, welche Zeile als Spaltennamen für Ihren Datenrahmen verwendet wird. Erwarte die Eingabe als int-Wert oder eine Liste von int-Werten.
Der Standardwert für diesen Parameter ist Kopfzeile = 0, was bedeutet, dass die erste Zeile der CSV-Datei als Spaltennamen betrachtet wird.
pd.read_csv('test.csv',Kopfzeile=1)
Produktion:
use-cols-Parameter
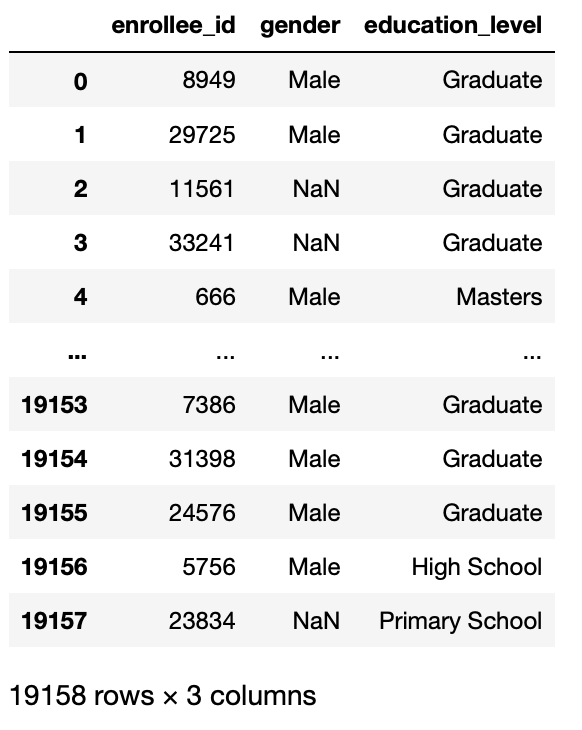
Geben Sie an, welche Spalten aus dem vollständigen Datensatz in den Datenrahmen importiert werden sollen. Sie können eine Liste von int-Werten oder direkt die Namen der Spalten eingeben.
Diese Funktion ist nützlich, wenn wir unsere Analyse nur für einige Spalten durchführen müssen, nicht in allen Spalten unseres Datensatzes.
Dann, Dieser Parameter gibt eine Teilmenge der Spalten in Ihrem Dataset zurück.
pd.read_csv('aug_train.csv',usecols =['enrollee_id','Geschlecht','Bildungsniveau'])
Produktion:
Kompressionsparameter
Wenn wahr und nur eine Spalte wird übergeben, gibt den Pandas-String anstelle eines DataFrame zurück.
pd.read_csv('aug_train.csv',usecols =['Geschlecht'],quetschen=wahr)
Produktion:
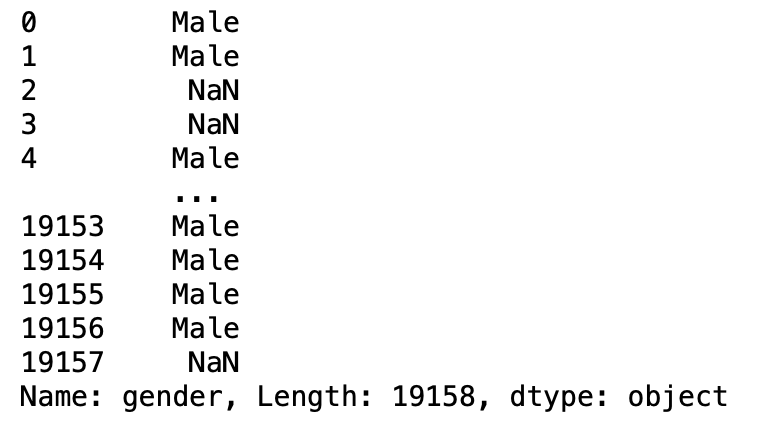
Parameter überspringen
Dieser Parameter wird verwendet, um im neuen Datenrahmen übergebene Zeilen zu überspringen.
pd.read_csv('aug_train.csv',Skiprows =[0,1])
Produktion:
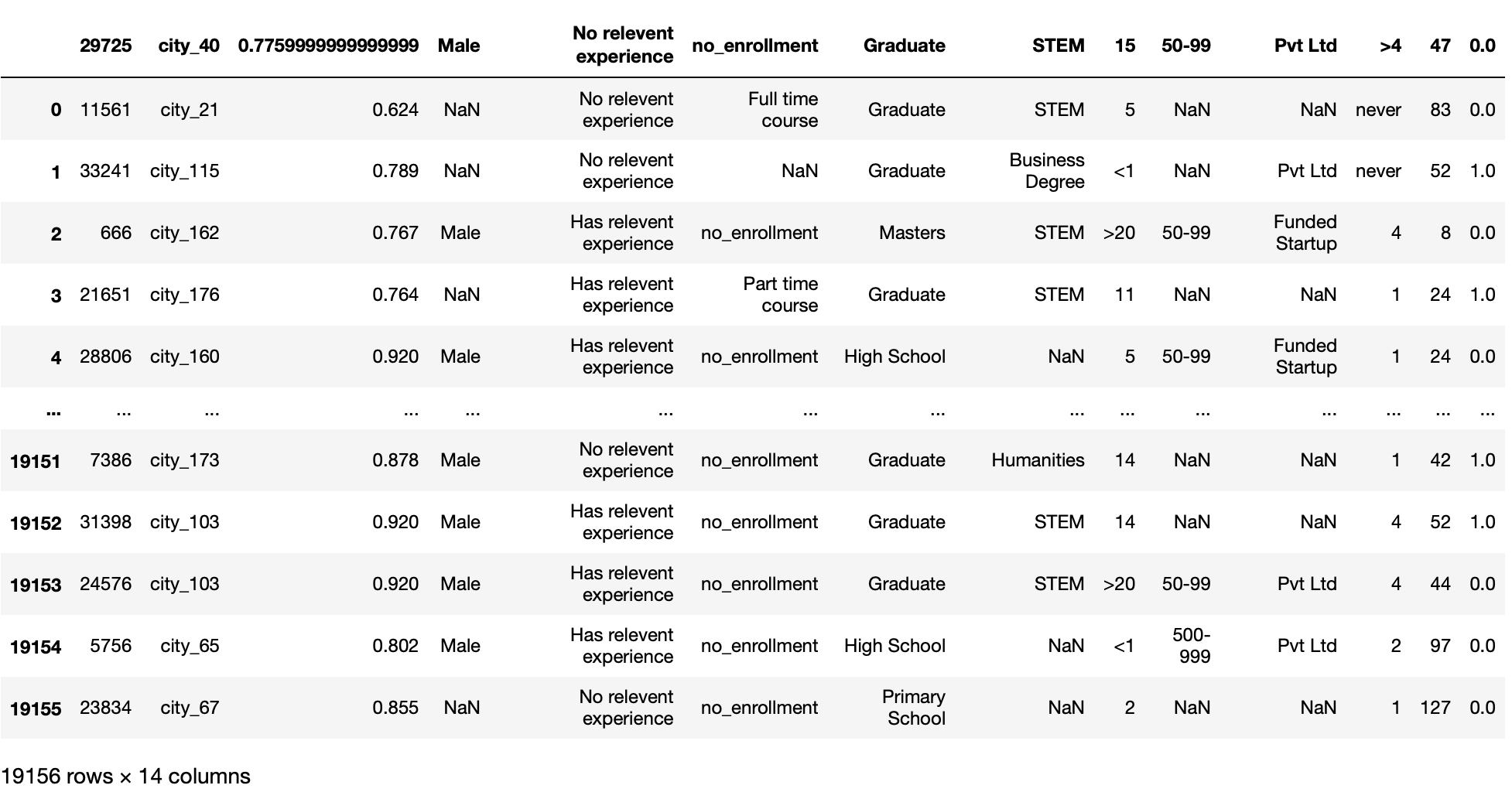
nrows-Parameter
Diese Funktion liest nur die feste Nummer (vom Benutzer entschieden) der ersten Zeilen der Datei. Sie benötigen einen int-Wert.
Dieser Parameter ist nützlich, wenn wir einen großen Datensatz haben und unseren Datensatz in Blöcken laden möchten, anstatt den gesamten Datensatz direkt zu laden.
pd.read_csv('aug_train.csv',Zeilen = 100)
Produktion:
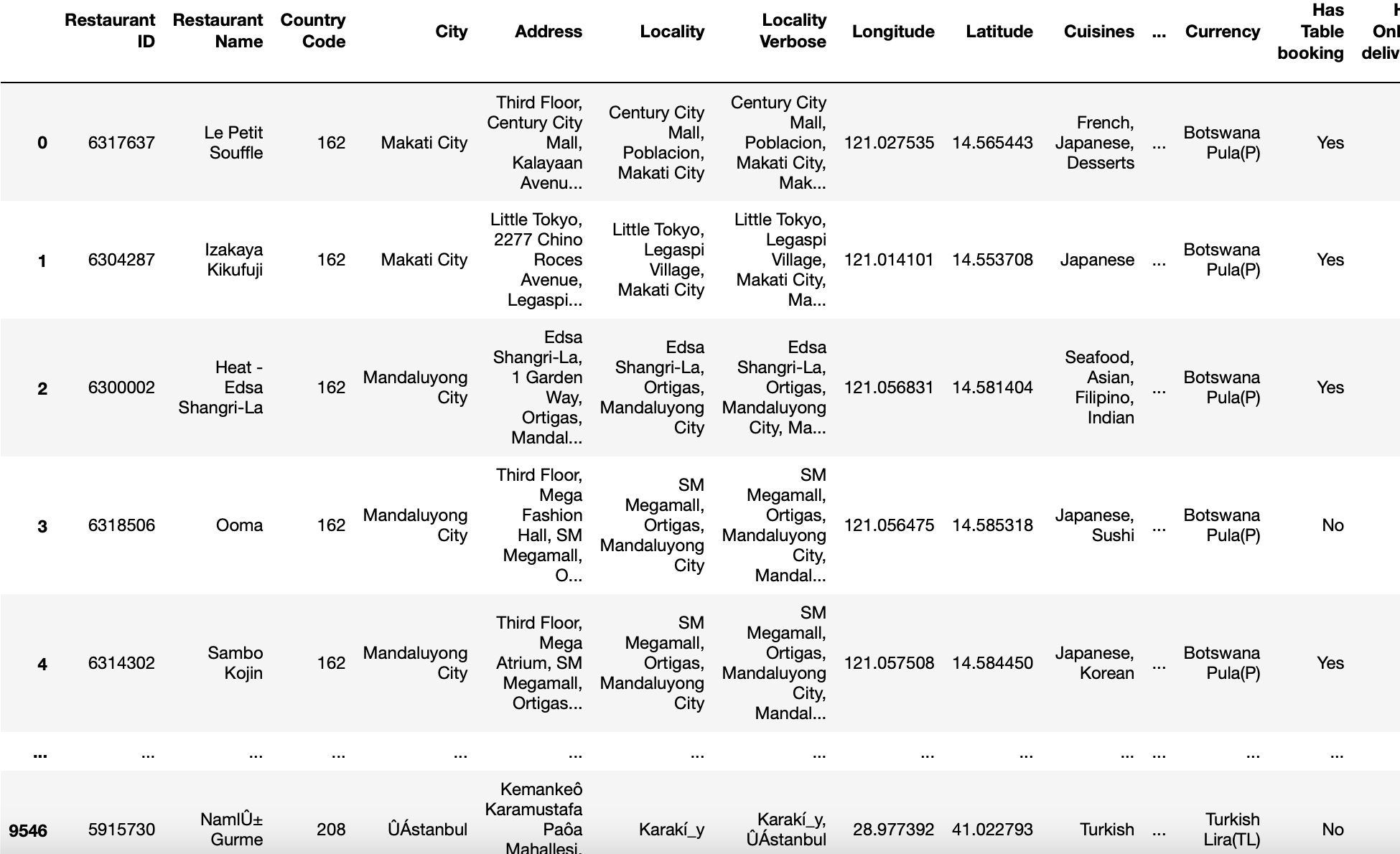
Codierungsparameter
Dieser Parameter hilft zu bestimmen, welche Codierung für UTF beim Lesen oder Schreiben von Dateien verwendet werden soll.
Manchmal, Was passiert ist, dass unsere Dateien nicht standardmäßig codiert sind, nämlich, UTF-8. Dann, speichere das mit einem Texteditor oder füge den Parameter hinzu „Codificación = ‚utf-8 ′ es funktioniert nicht. In beiden Fällen, gibt den Fehler zurück.
Dann, um dieses Problem zu lösen, wir rufen unsere read_csv-Funktion mit . auf Codierung = ‚latin1 ′, Codierung =‘ iso-8859-1 ′ o codificación = ‚cp1252 ′ (Dies sind einige der verschiedenen Codierungen, die in Windows zu finden sind).
pd.read_csv('zomato.csv',Kodierung='lateinisch-1')
Produktion:
error-bad-lines-Parameter
Wenn wir einen Datensatz haben, in dem einige Zeilen zu viele Felder haben (Zum Beispiel, eine CSV-Zeile mit zu vielen Kommas), demnächst, standardmäßig, eine Ausnahme wird geworfen und verursacht, und es wird kein DataFrame zurückgegeben.
Dann, um solche Probleme zu lösen, wir müssen diesen Parameter auf False setzen, dann bist du „fehlerhafte Leitungen“ wird aus dem zurückgegebenen DataFrame entfernt. (Nur gültig mit C-Analysator)
pd.read_csv('BX-Bücher.csv', sep=';', Kodierung="lateinisch-1",error_bad_lines=Falsch)
Produktion:
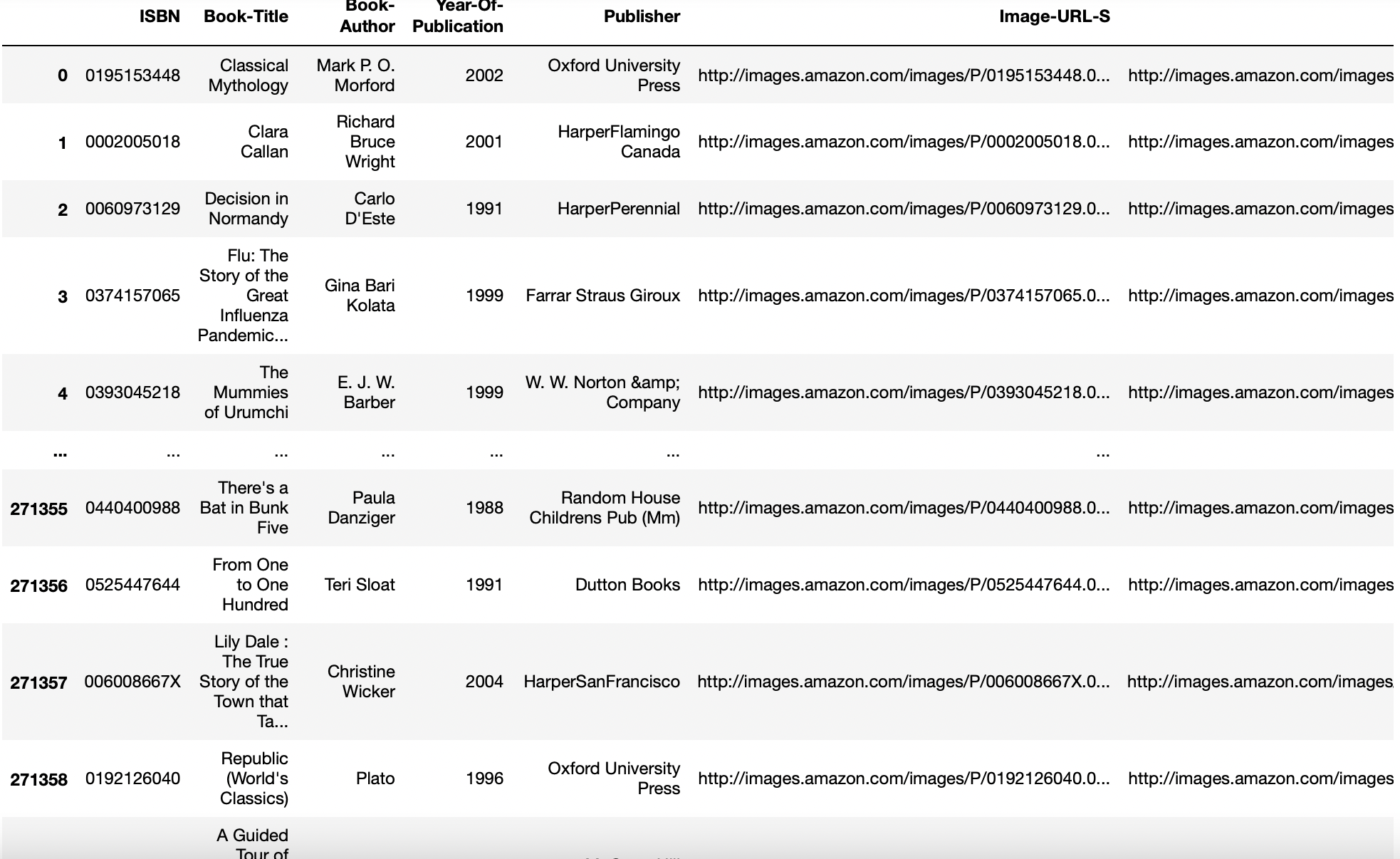
dtype-Parameter
Datentyp für Daten oder Spalten. Zum Beispiel, {‚ein‘: z.B. float64, ‚B‘: z.B. int32}
Manchmal, um unsere Spalten vom float-Datentyp in den int-Datentyp zu konvertieren, diese Funktion ist nützlich.
pd.read_csv('aug_train.csv',dtyp={'Ziel':int}).die Info()
Produktion:
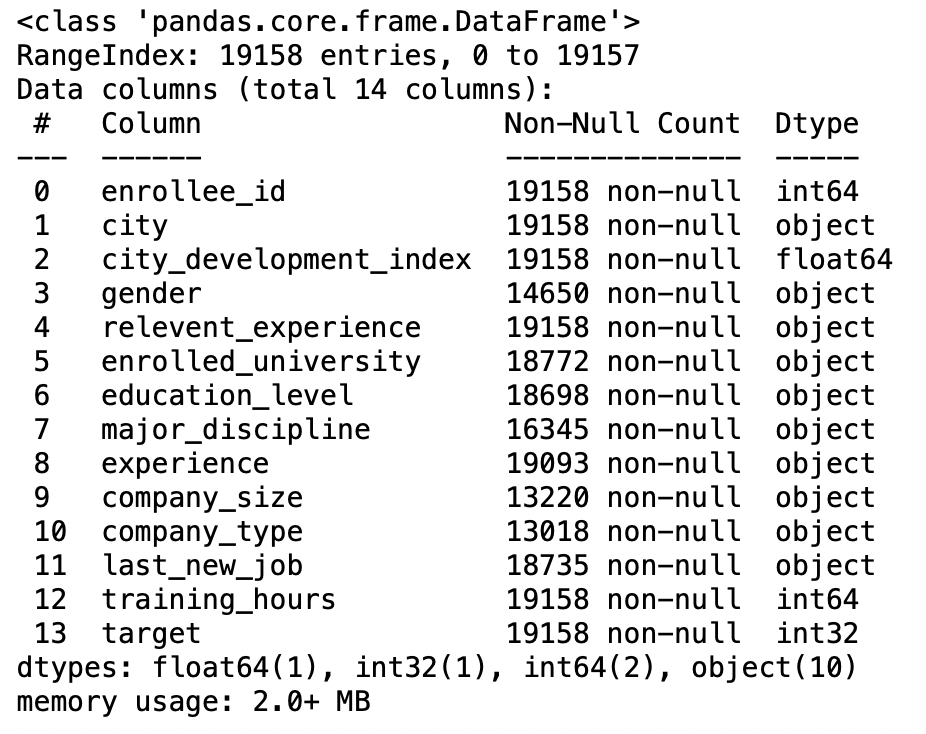
parse-dates-Parameter
Wenn wir diesen Parameter wahr machen, Versuchen Sie dann, den Index zu parsen.
Zum Beispiel, Und [1, 2, 3] -> versuche die Spalten zu parsen 1, 2, 3 jeweils als separate Datumsspalte und wenn wir die Spalten kombinieren müssen 1 Ja 3 und als einzelne Datumsspalte analysieren, verwenden [[1,3]].
pd.read_csv('IPL-Spiele 2008-2020.csv',parse_dates=['Datum']).die Info()
Produktion:
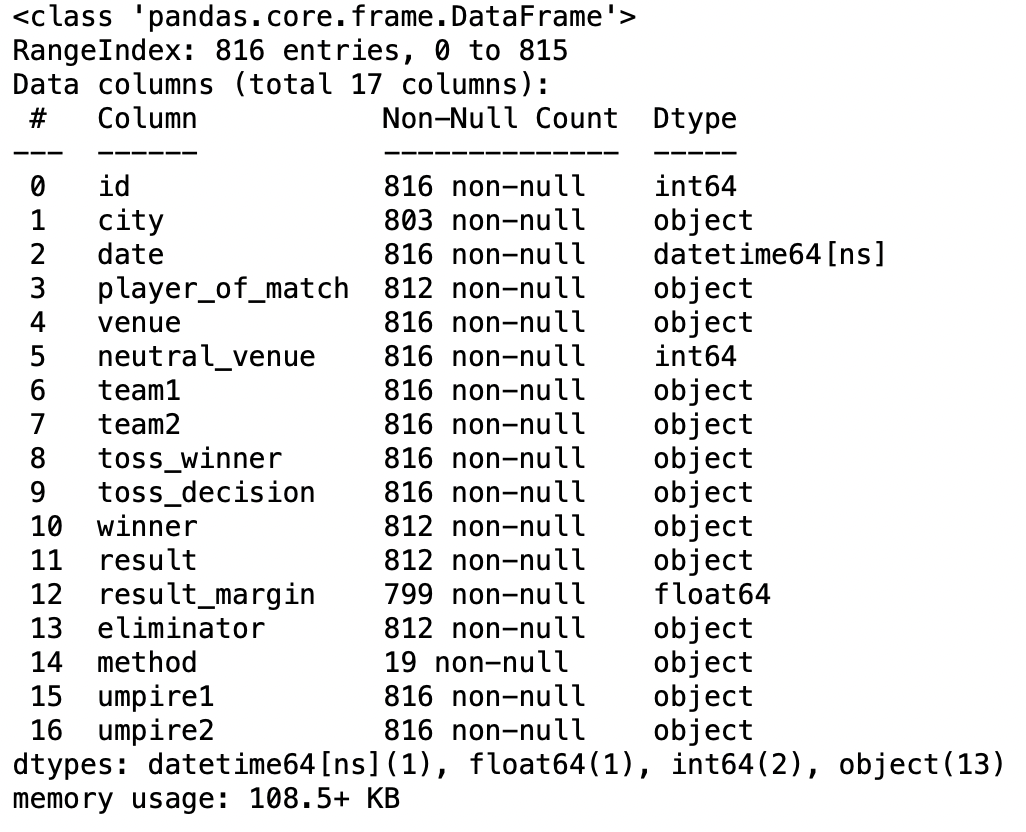
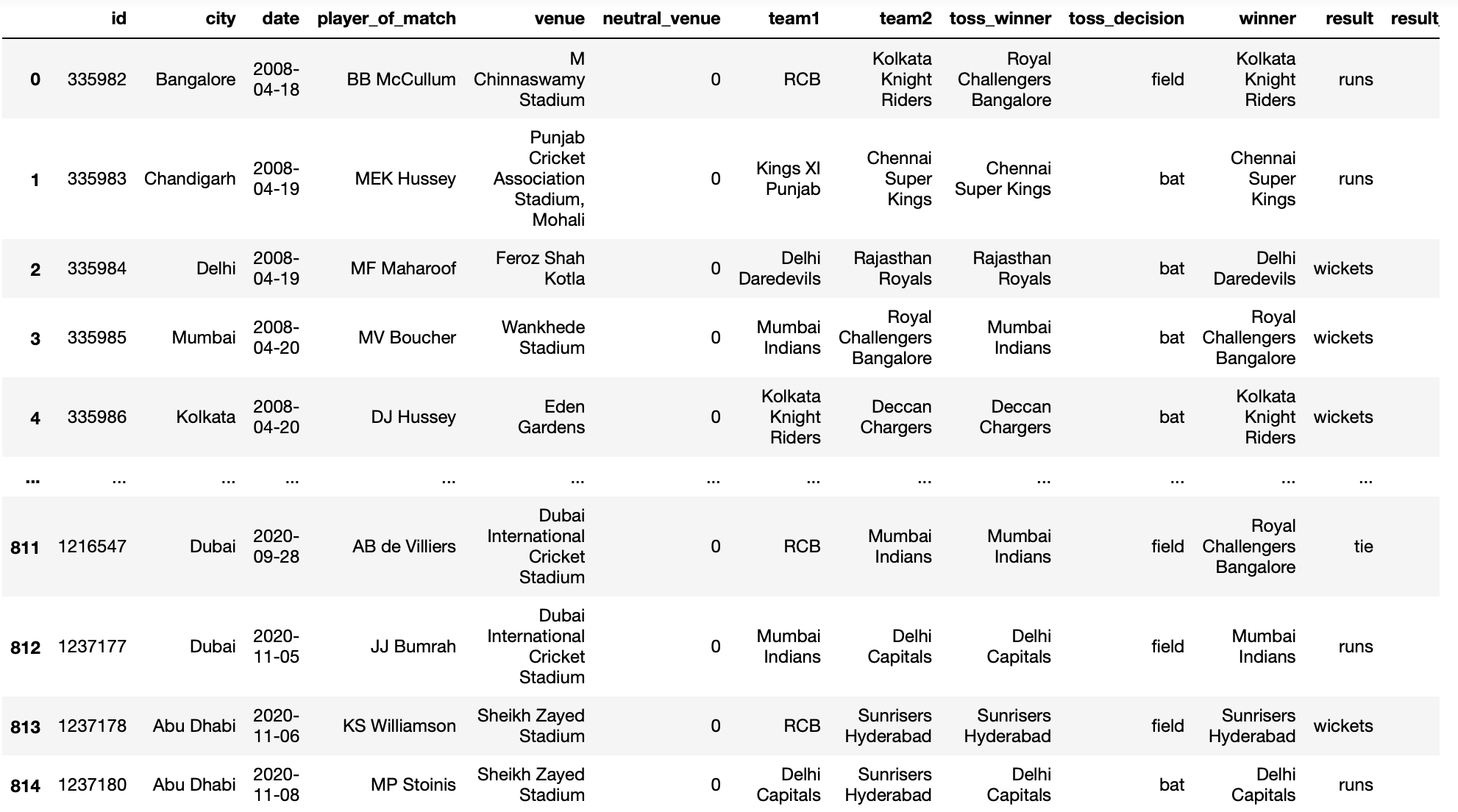
Konverterparameter
Dieser Parameter hilft uns, Werte in den Spalten basierend auf einer vom Benutzer angegebenen benutzerdefinierten Funktion umzuwandeln.
def umbenennen(Name):
wenn Name == "Royal Challengers Bangalore":
Rückkehr "RCB"
anders:
Rückgabename
umbenennen("Royal Challengers Bangalore")
Produktion:
‚RCB‘
pd.read_csv('IPL-Spiele 2008-2020.csv',Konverter={'team1':umbenennen})
Produktion:
Parameterwerte in
Wie wir wissen, die fehlenden Standardwerte sind NaN. Wenn wir möchten, dass andere Strings als NaN . betrachtet werden, dann müssen wir diesen Parameter verwenden. Erwarte eine Liste von Strings als Eingabe.
Manchmal, in unserem Datensatz, ein anderer Symboltyp wird verwendet, um sie in fehlende Werte umzuwandeln, also damals diese Werte als verloren zu verstehen, Wir verwenden diesen Parameter.
pd.read_csv('aug_train.csv',na_values=['Männlich',])
Produktion:
Damit ist unsere Diskussion abgeschlossen!!
HINWEIS: In diesem Artikel, Wir werden nur die Parameter besprechen, die bei der täglichen Arbeit mit CSV-Dateien sehr nützlich sind.. Aber wenn Sie mehr Parameter wissen möchten, Besuchen Sie die offizielle Pandas-Website hier.
Oder Sie können sich darauf beziehen Verknüpfung was ist mehr.
Abschließende Anmerkungen
Danke fürs Lesen!
Wenn es dir gefallen hat und du mehr wissen willst, zu meinen anderen Artikeln zu Data Science und Machine Learning, indem du auf das klickst Verknüpfung
Kontaktieren Sie mich gerne unter Linkedin, Email.
Alles was nicht erwähnt wurde oder du deine Gedanken teilen möchtest? Fühlen Sie sich frei, unten einen Kommentar zu hinterlassen und ich melde mich bei Ihnen.
Über den Autor
Chirag Goyal
Heutzutage, Ich studiere meinen Bachelor of Technology (B.Tech) in Informatik und Ingenieurwissenschaften von Indisches Technologieinstitut Jodhpur (IITJ). Ich freue mich sehr über maschinelles Lernen, das tiefes LernenTiefes Lernen, Eine Teildisziplin der Künstlichen Intelligenz, verlässt sich auf künstliche neuronale Netze, um große Datenmengen zu analysieren und zu verarbeiten. Diese Technik ermöglicht es Maschinen, Muster zu lernen und komplexe Aufgaben auszuführen, wie Spracherkennung und Computer Vision. Seine Fähigkeit, sich kontinuierlich zu verbessern, wenn mehr Daten zur Verfügung gestellt werden, macht es zu einem wichtigen Werkzeug in verschiedenen Branchen, von Gesundheit... und Künstliche Intelligenz.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





