Einführung
Ein Bild sagt mehr als tausend Worte!
Im heutigen Wettbewerbsumfeld, Unternehmen wollen schnellere Entscheidungswege, um sicherzustellen, dass sie dem Rennen einen Schritt voraus sind.
Datenvisualisierung hilft in zwei kritischen Phasen des datengesteuerten Entscheidungsprozesses (Wie in der nächsten Abbildung gezeigt):
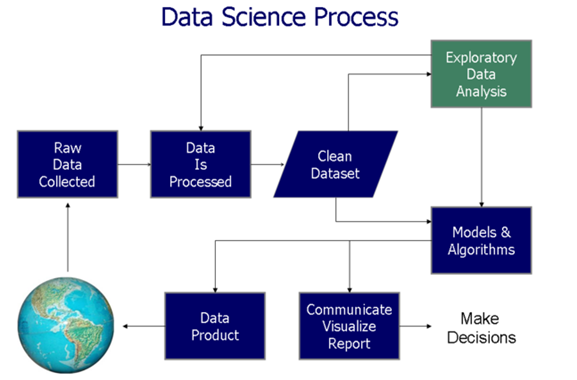
In diesem Artikel, wir werden die erkunden 4 Datenvisualisierungsanwendungen und deren Implementierung in SAS. Zum besseren Verständnis, Wir haben Beispieldatensätze genommen, um diese Visualisierung zu erstellen. Dann, die Hauptaspekte der Datenvisualisierung werden aufgezeigt:
- Vergleich machen: Inklusive Balkendiagramm, Liniendiagramm, Balkendiagramm, Säulendiagramm, gruppiertes Balkensäulendiagramm.
- Studienverhältnis: Inklusive Blasendiagramm, Streudiagramm
- Vertrieb studieren: Inklusive Histogramm, Ausbreitungsdiagramm,
- Komposition verstehen: Enthält gestapeltes Säulendiagramm

Lasst uns beginnen!
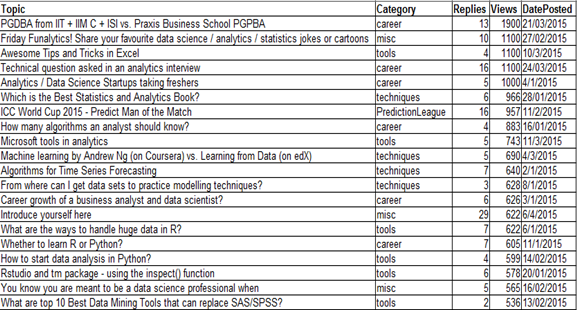
Zur Veranschaulichung, wir verwenden einen Datensatz 'diskutieren’ entnommen aus dem Analytische Vidhya-Diskussion. Die Daten enthalten das Diskussionsthema, die Kategorie, die Anzahl der Antworten auf den Beitrag und die Gesamtzahl der Aufrufe. Die Daten enthalten die 20 Hauptthemen:
1. Vergleich machen
ein) Balkengrafik
EIN Balkengrafik, auch bekannt als Balkengrafik stellt gruppierte Daten mit rechteckigen Balken dar, deren Längen proportional zu den Werten sind, die sie darstellen. Balken können vertikal oder horizontal gezeichnet werden. Ein vertikales Balkendiagramm wird manchmal als Säulenbalkendiagramm bezeichnet.
Illustration
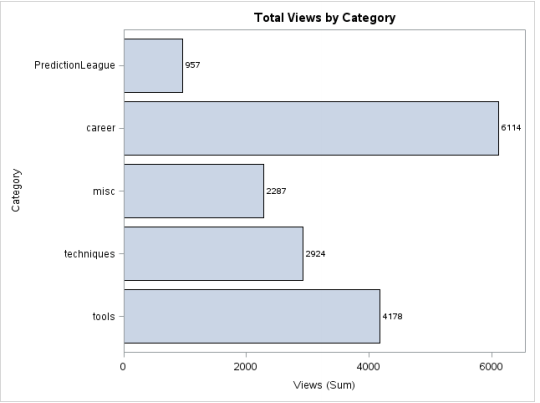
Ziel: Wir möchten die Anzahl der Ansichten jeder Kategorie wissen, die grafisch durch ein Balkendiagramm dargestellt wird.
Code:
proc sgplot data = diskutieren;
hbar category/response = views stat = sum
datalabel datalabelattrs=(Gewicht=fett);
Titel "Gesamtaufrufe nach Kategorie";
Lauf;
Produktion:
B) Säulendiagramm
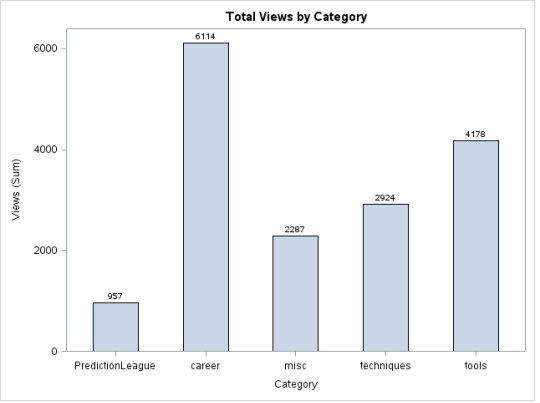
Säulendiagramme sind oft selbsterklärend. Sie sind einfach die vertikale Version eines Balkendiagramms, bei dem die Länge der Balken der Größe des Werts entspricht, den sie darstellen. Hier ist ein Manöver: wandeln Sie die oben gezeigte Grafik in -90 Grad, wird ein Säulendiagramm.
Code:
proc sgplot data = diskutieren;
hbar Kategorie/Antwort = Aufrufstatistik = Summe
datalabel datalabelattrs=(Gewicht=fett) Strichbreite = 0.5; /* Breite den Balken zuweisen*/
Titel 'Gesamtaufrufe nach Kategorie';
Lauf;
Produktion:
-> Erläuterung des Codes für das Balken- und Säulendiagramm:
- Kategorie: die Variable, nach der die Daten gruppiert werden sollen.
- Antwort = Aufrufe: Statistiken angegeben durch stat = Option werden für Variablenansichten berechnet, die nach Kategorievariable gruppiert sind.
- Die Option Datalabel gibt an, dass die berechneten Werte für jeden Balken angezeigt werden sollen.
- Die Option Gewicht = fett gibt an, dass die Datenbeschriftungen für jeden Balken fett dargestellt werden.
- Die Option Balkenbreite wird verwendet, um den Balken eine Breite zuzuweisen. Die Standardeinstellung ist 0.8 und die Reichweite ist 0.1-1.
C) Balkengrafik / geclustertes Säulendiagramm
Diese Art der Darstellung ist nützlich, wenn wir die Verteilung von Daten in zwei Kategorien visualisieren möchten.
Ziel: Wir wollen die Gesamtansichten der Themen im Diskussionsforum nach Kategorie und Veröffentlichungsdatum analysieren.
Code:
Daten diskussion_date;
diskutieren;
Monat = Monat(Datum der Veröffentlichung);
month_name=PUT(Datum der Veröffentlichung,monname.);
put month_name= @;
Lauf;
proc sgplot data=discuss_date;
vbar category/ response=views group=month_name groupdisplay=cluster
datalabel datalabelattrs = (Gewicht = fett) dataskin=gloss; y-Achsen-Raster;
Lauf;
Produktion:
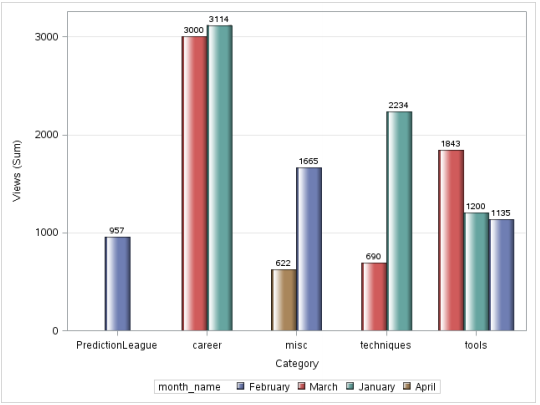
Aber trotzdem, Es gibt ein Problem mit diesem Bild, die Monate sind nicht chronologisch geordnet. Um das zu lösen, wir verwenden PROC-FORMAT.
Code mit PROC-FORMAT:
Daten diskussion_date; diskutieren; Monat = Monat(Datum der Veröffentlichung); monat_num = Eingabe(Monat,5.); Lauf;
PROC-FORMAT;
WERT monthfmt
1 = 'Januar'
2 = 'Februar'
3 = 'März'
4 = 'April';
LAUF;
proc sgplot data=discuss_date;
vbar category/ response=views group = month_num groupdisplay=cluster datalabel
datalabelattrs = (Gewicht = fett) dataskin=gloss grouporder=aufsteigend;
Format month_num Monatsfmt.;
y-Achsen-Raster;
Lauf;
Produktion:
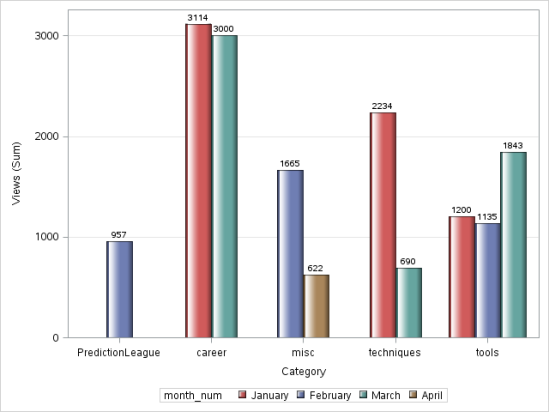
D) Liniendiagramm
EIN Liniendiagramm Ö Liniendiagramm ist eine Art von Diagramm, das Informationen als eine Reihe von Datenpunkten anzeigt, die als bezeichnet werden “Lesezeichen” verbunden durch gerade Liniensegmente. Ein Liniendiagramm wird häufig verwendet, um Datentrends über Zeitintervalle zu visualisieren., eine Zeitreihe, daher wird die Linie oft chronologisch gezogen. In diesen Fällen sind sie bekannt als Grafiken ausführen.
Für diese Abbildung, wir verwenden daten von PGDBA von IIT + IIM C + ISI frente a Praxis Business School PGPBA.
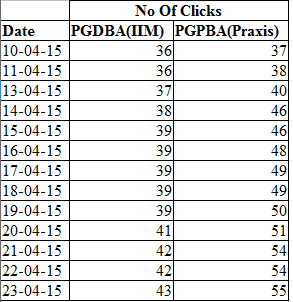
Code:
proc sgplot-Daten = Klicks;
vline-Datum/Antwort = PGDBA_IIM_ ;
vline Datum/Antwort = PGPBA_Praxis_;
y-Achsenbeschriftung = "Klicks";
Lauf;
Produktion:
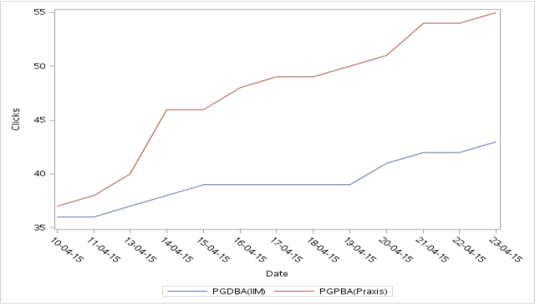
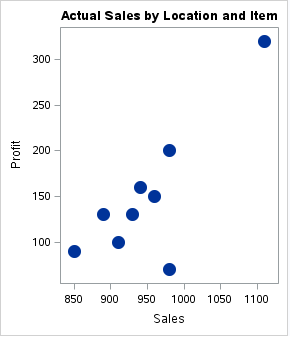
e) Balkendiagramm
Dieses Kombinationsdiagramm kombiniert die Funktionen des Balkendiagramms und des Liniendiagramms. Zeigt die Daten mit einer Reihe von Balken an und / oder Linien, von denen jeder eine bestimmte Kategorie repräsentiert. Eine Kombination von Balken und Linien in derselben Visualisierung kann beim Vergleichen von Werten in verschiedenen Kategorien nützlich sein.
Ziel: Wir möchten die prognostizierten Verkäufe mit den tatsächlichen Verkäufen für verschiedene Zeiträume vergleichen.
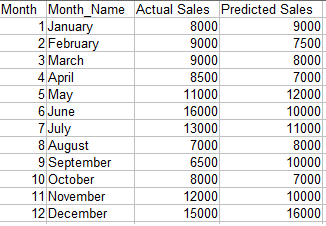
Code:
proc sgplot data=Taktstrich;
vbar Monat/Antwort=actual_sales datalabel datalabelattrs = (Gewicht = fett)
Fillattrs = (Farbe = braun);
vline Monat/Antwort=predicted_sales
lineattr =(Dicke = 3) Markierungen;
xaxis-Label= "Monat";
y-Achsenbeschriftung = "Der Umsatz";
Schlüssellegende / location=innen position=obenlinks quer=1;
Lauf;
Notiz: Die Daten müssen nach der x-Achsen-Variablen geordnet werden.
Produktion:
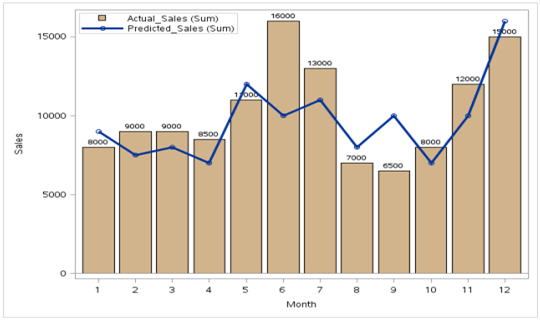
2) Studiere die Beziehung
ein) Blasendiagramm
Ein Blasendiagramm ist ein Diagrammtyp, der drei Datendimensionen anzeigt. Jedes Wesen mit seinem Triplett (v1, v2, v3) zugehörige Daten werden als Scheibe dargestellt, die zwei der vich Werte auf der Festplatte xy Lage und der dritte für seine Größe. – Quelle: Wikipedia.
Daten für Betriebssystem:
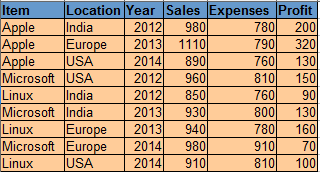
Code:
proc sgplot data = os;
Blase X=Ausgaben Y=Umsatzgröße=Gewinn
/fillattrs=(Farbe = blaugrün) datalabel = Standort;
Lauf;
Produktion:
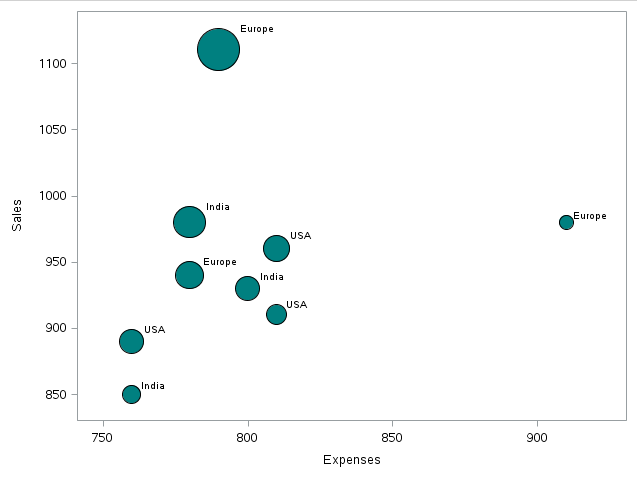
Wie wir sehen können, Es gibt einen Rekord, bei dem Umsatz und Gewinn am höchsten sind, während die Vergleichskosten geringer sind als bei einigen anderen Datenpunkten.
B) Streudiagramm für die Beziehung
Ein einfaches Streudiagramm zwischen zwei Variablen kann uns eine Vorstellung von der Beziehung zwischen ihnen geben: linear, exponentiell, etc. Diese Informationen können bei einer späteren Analyse nützlich sein.
Code:
proc sgplot data = os;
Titel 'Verhältnis von Gewinn und Umsatz';
Streuung X= Umsatz Y = Gewinn/
Markerattrs=(Symbol=Kreisgefüllte Größe=15);
Lauf;
Produktion:
3. Studieren Sie die Verteilung
ein) Histogramm
EIN Histogramm ist eine grafische Darstellung der Verteilung numerischer Daten. Es ist eine Schätzung der Wahrscheinlichkeitsverteilung einer stetigen Variablen. So erstellen Sie ein Histogramm, der erste schritt ist “Gruppe” der Wertebereich, nämlich, Teile den gesamten Wertebereich in eine Reihe kleiner Intervalle und zähle dann, wie viele Werte in jedes Intervall fallen. Bins werden im Allgemeinen als aufeinanderfolgende Intervalle angegeben, Nichtüberlappung einer Variablen. Die Behälter (Intervalle) muss benachbart sein und, wie gewöhnlich, die gleiche Größe. Die Rechtecke in einem Histogramm werden so gezeichnet, dass sie sich berühren, um anzuzeigen, dass die ursprüngliche Variable stetig ist.
Code:
proc sgplot data = sashelp.cars;
Histogramm msrp/fillattrs=(Farbe = Stahl)Maßstab = Anteil;
Dichte msrp;
Lauf;
Produktion:
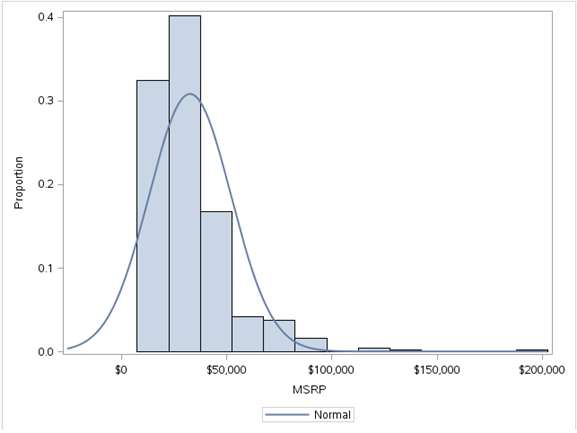
Wir haben hier den Datensatz sashelp.mtcars verwendet. Ein Histogramm der MSRP-Variablen gibt uns die vorherige Zahl. Dies sagt uns, dass die MSRP-Variable nach rechts verdreht ist, zeigt an, dass die meisten Datenpunkte unten liegen $ 50,000. Aussagekräftige Erkenntnisse können aus Histogrammen gewonnen werden.
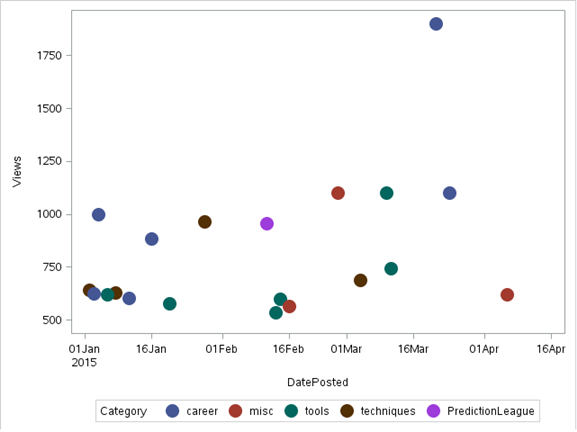
B) Ausbreitungsdiagramm
in einem Streudiagramm Daten werden als eine Sammlung von Punkten angezeigt, jeweils mit dem Wert einer Variablen, die die Position auf der horizontalen Achse bestimmt, und dem Wert der anderen Variablen, die die Position auf der vertikalen Achse bestimmt. Es kann sowohl verwendet werden, um die Verteilung von Daten zu sehen. und greifen Sie auf die Beziehung zwischen Variablen zu.
Notiz: zur Veranschaulichung, wir verwenden einen Datensatz 'diskutieren’ entnommen aus dem Analytische Vidhya-Diskussion
Code:
proc sgplot data = diskutieren;
Streuung X= gepostetes Datum Y = Ansichten/Gruppe=Kategorie
Markerattrs=(Symbol=Kreisgefüllte Größe=15);
Lauf;
Produktion:
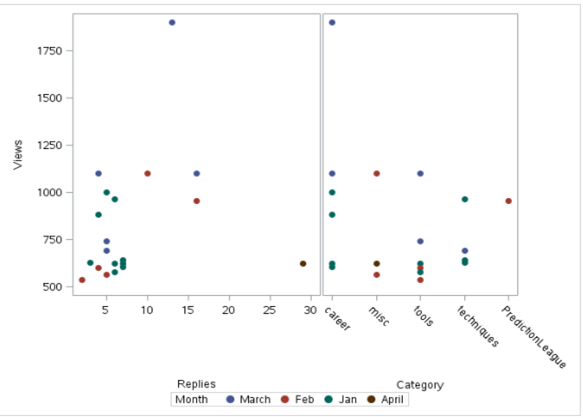
das SGSCATTER Das Verfahren kann auch für Streudiagramme verwendet werden. Es hat den Vorteil, mehrere Streudiagramme erstellen zu können. Unten ist die Ausgabe mit sgcscatter:
Code:
proc sgscatter data = diskutieren;
Vergleiche y = Ansichten x = (Antwortkategorie)
/Gruppe = Monat Markerattrs=(Symbol = kreisgefüllte Größe = 10);
Lauf;
Produktion:
Eine wichtige Anwendung des Scatterplots ist die Interpretation der Residuen aus der linearen Regression. Ein Streudiagramm der Residuen gegenüber den vorhergesagten Werten der vorhergesagten Variablen hilft uns zu bestimmen, ob die Daten heteroskedastisch oder homoskedastisch sind..
HETEROSQUEDASTIC HOMOSQUEDASTIC
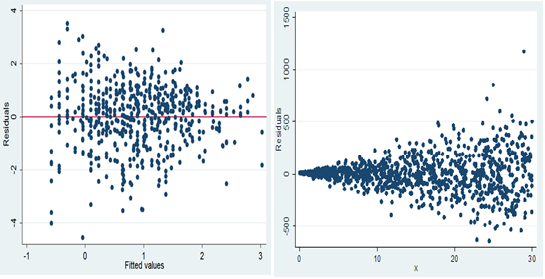
4) Komposition
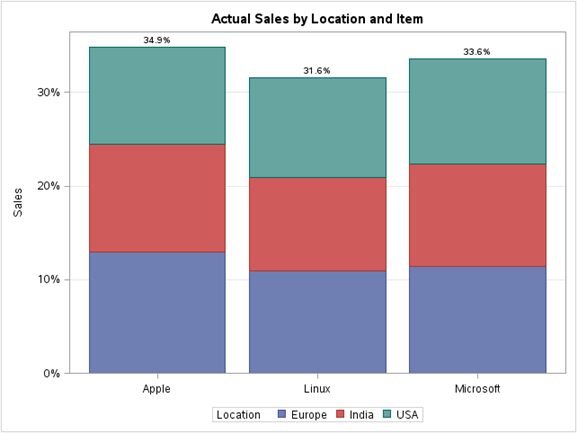
ein) Gestapeltes Säulendiagramm:
Auf einem gestapelten Balkendiagramm, gestapelte Balken stellen verschiedene Gruppen übereinander dar. Die Höhe des resultierenden Balkens zeigt das kombinierte Ergebnis der Gruppen.
Zum Beispiel, wenn wir den Gesamtumsatz pro Artikel nach Standort gruppiert in den Gesamtdaten des Betriebssystemdatensatzes sehen möchten, wir können das gestapelte Säulendiagramm verwenden. Unten ist die Abbildung:
Code:
proc sgplot data = os; title 'Tatsächliche Verkäufe nach Standort und Artikel'; vbar Artikel / response=Sales group=Standortstatistik=Prozentdatenlabel; x-Achsen-Anzeige=(nolabel); yaxis Rasterbeschriftung="Der Umsatz"; Lauf;
Produktion:
Abschließende Anmerkungen:
Visualisierungen werden zu einem natürlichen Weg, um Massendaten zu verstehen. Sie vermitteln Informationen einfach und erleichtern den Gedankenaustausch mit anderen. In diesem Artikel, Wir analysieren einige grundlegende Visualisierungen, die mit SAS base erstellt werden können. Diese können eine großartige Möglichkeit sein, unsere Daten zusammenzufassen, Informationen bekommen, Beziehungen finden, etc.
Fanden Sie diesen Artikel nützlich?? Gibt es andere Visualisierungen, die Sie verwendet haben und die Sie mit unserem Publikum teilen können?? Fühlen Sie sich frei, sie über die Kommentare unten zu teilen..





