Einführung
Das PDF-Format oder tragbare Dokumentdatei ist heute eines der gebräuchlichsten Dateiformate. Es ist in allen Branchen weit verbreitet, wie in Behörden, medizinische Versorgung und sogar persönliche Arbeit. Während, Es gibt eine große Menge unstrukturierter Daten im PDF-Format und das Extrahieren dieser Daten, um aussagekräftige Informationen zu generieren, ist eine gängige Aufgabe von Data Scientists.
Es gibt mehrere Python-Bibliotheken für die Arbeit mit PDF-Dokumenten wie PYPDF2, etc. In diesem Tutorial, werde tragen Camelot.

Warum Camelot?
- Du hast die Kontrolle: im Gegensatz zu anderen Bibliotheken und Tools, die gute Ergebnisse liefern oder kläglich versagen (ohne Vermittler), Camelot gibt Ihnen die Möglichkeit, die Tabellenextraktion zu ändern. (Dies ist wichtig, da alles in der realen Welt, inklusive Extraktion von PDF-Tabellen, es ist verwirrend).
- Ein bisschen Tabellen können basierend auf Metriken wie Genauigkeit und Leerzeichen gelöscht werden, ohne jede Tabelle manuell anschauen zu müssen.
- Jede Tabelle ist ein Pandas DataFrame, das sich nahtlos in . integriert Datenanalyse und ETL-Workflows.
- In mehrere Formate exportieren, einschließlich JSON, Excel, HTML und SQLite.
Lasst uns beginnen
Vor der Installation der Camelot-Bibliotheken müssen wir installieren Geisterskript , Sobald wir das Ghost-Skript installiert haben, lass uns installieren camelot-py.
Führen Sie die folgenden Befehle aus :
pip installieren "camelot-py[Lebenslauf]"
Sobald Sie die camelot-py-Bibliothek installiert haben, wir werden startklar sein. Wir versuchen, daraus eine landesweite GST-Einnahmetabelle zu extrahieren pdf-Dokument.
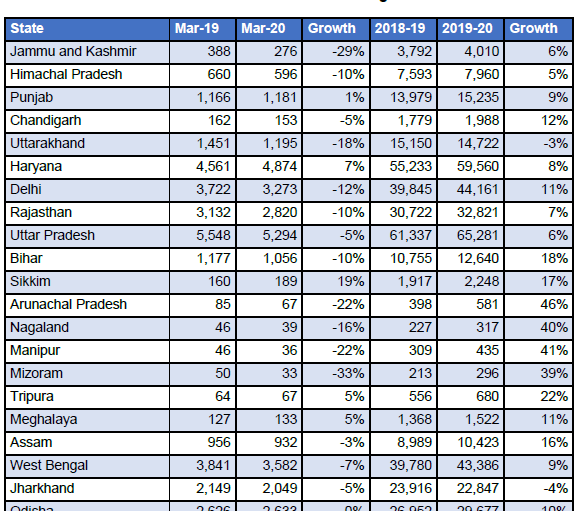
PDF-Tabelle
Camelot importieren
Wenn Sie Kamelot haben, Python gibt keine Fehlermeldung aus, wenn nicht, du wirst sehen ImportError.
# Syntax der Funktion camelot.read_pdf
Kamelot.read_pdf(
Dateipfad,
Seiten='1',
Passwort=Keine,
Geschmack='Gitter',
unterdrücke_stdout=Falsch,
layout_kwargs={},
**Kwargs,
)
Wenn Sie eine Tabelle von verschiedenen Seiten extrahieren müssen, Sie müssen die Seitenzahl angeben.
table2=camelot.read_pdf('gst-revenue-collection-märz2020.pdf', Geschmack="Strom", Seiten="0-3")
Tabellen2
Dadurch erhalten Sie eine Gesamtliste der Tabelle, die in einem PDF-Dokument vorhanden ist. Wir können eine Tabelle auswählen, die den Index übergibt.
Tabellen2[2] # 2 ist der Index
Tabellen2[2].parsing_report

Der obige Code liefert Ihnen Details wie Genauigkeit und Seitenzahl. Bitte beachten Sie, dass es 2 Seiten.
Der folgende Code extrahiert die Tabelle aus dem PDF-Dokument.
df2=tables2[2].df
df2
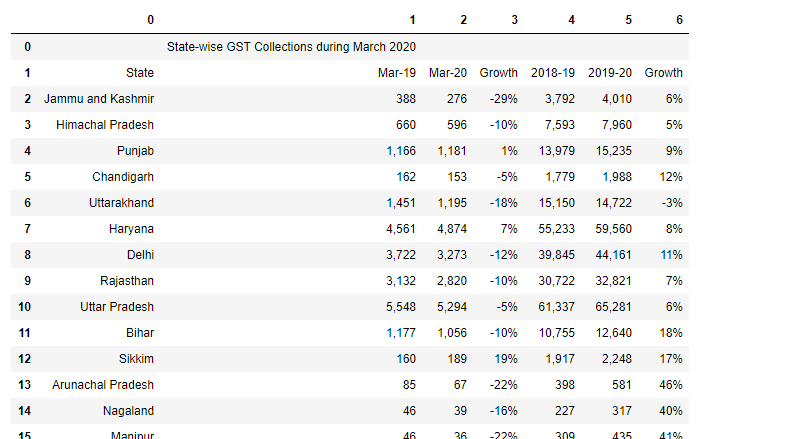
Unter diesen Umständen, weil die Tabelle in zwei verschiedene Seiten unterteilt ist. Dann können wir eine Lösung finden.
Tabellen2[3]
Tabellen2[3].parsing_report

Hier kannst du es merken, Wir extrahieren die Tabelle von Seite Nr 3.
df3=Tabellen2[3].df
df3
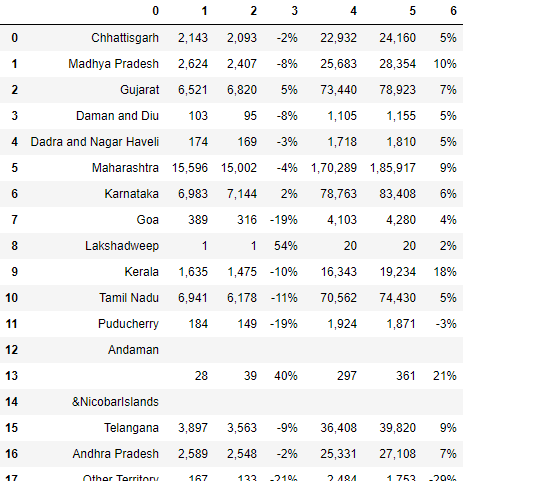
Das Folgende ist der Code zum Hinzufügen von df2 und df3.
df4=df2.anhängen(df3)
df4
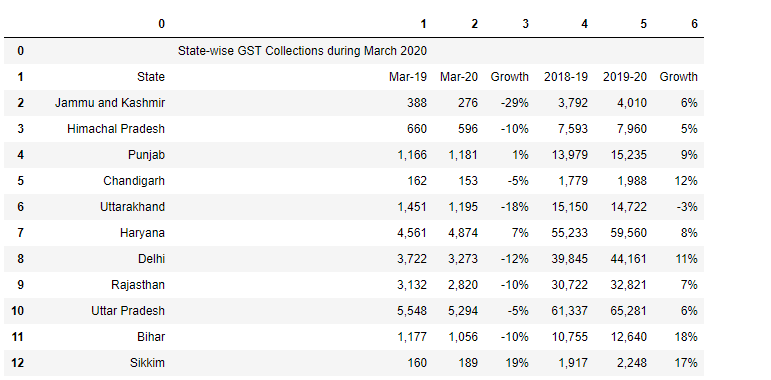
df5 = df4[1:] df5.head() neuer_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header
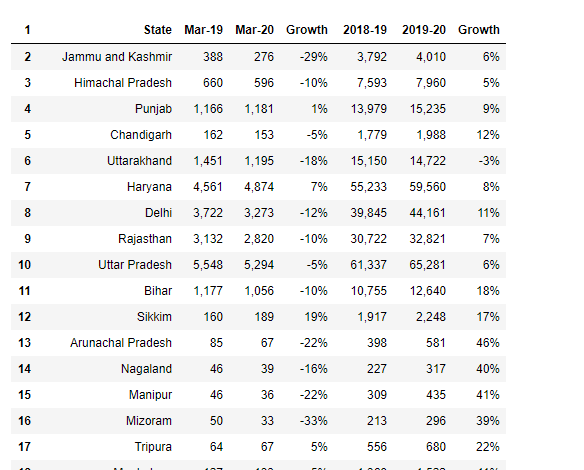
Hier hast du, wir haben eine tabelle aus pdf extrahiert, Jetzt können wir diese Daten in einem beliebigen Format auf das lokale System exportieren.
Fazit
Das Extrahieren von Tabellendaten aus PDF mit Hilfe der Camelot-Bibliothek ist wirklich einfach. Zur selben Zeit, wir wissen, dass es viele unstrukturierte Daten im PDF-Format gibt und, nach dem Extrahieren der Tabellen, Wir können viele Analysen und Visualisierungen basierend auf Ihren Geschäftsanforderungen durchführen.
Ich hoffe dieser Beitrag hilft dir und spart dir viel Zeit. Lass es mich wissen, wenn du Vorschläge hast.
GLÜCKLICHES CODIEREN.
Über den Autor

Prabhat Kumar – Associate Analyst
Ich bin ein Ingenieur, der heute in den wichtigsten multinationalen Unternehmen als Associate Analyst und Innovationsbegeisterter arbeitet, Ich liebe es, neue Dinge zu lernen, Ich glaube, dass jede Information eine Geschichte hat und ich liebe es, die Geschichten zu lesen.
Prabhat Pathak (LinkedIn Profil) ist Associate Analyst.





