Einführung
Python ist eine der beliebtesten Sprachen in der Welt der Datenwissenschaft und des maschinellen Lernens. Es ist leicht zu erlernen und bietet viele Bibliotheken und Pakete und hat eine gute Entwickler-Community. Python-Bibliotheken und -Pakete sind eine Gruppe von Modulen, die uns das Leben erleichtern. Es gibt mehr von 137,000 Python-Bibliotheken und 198,826 vorgefertigte Python-Pakete, um die gewöhnliche Programmiererfahrung von Ingenieuren zu erleichtern. Diese Bibliotheken und Pakete sind für eine Vielzahl von fortgeschrittenen Anordnungen geplant.
Als Data-Science-Enthusiast, Ich habe Leute gesehen, die immer über berühmte Bibliotheken wie Datenmanipulationspandas und NumPy sprechen, zur Datenvisualisierung matplotlib, Seegeboren, Plotly und viele mehr, So modellieren Sie scikit-learn, TensorFlow, etc. In diesem Artikel werde ich nicht auf diese Bibliotheken eingehen, da es bereits Tonnen von Blogs gibt, Schauen Sie sich meinen Artikel über die am häufigsten verwendeten Python-Bibliotheken hier an. Aber in seinem Artikel, Ich werde einige versteckte Juwelen von Python-Bibliotheken behandeln, die der Data-Science-Welt unbekannt sind. Hier sind einige wichtige Bibliotheken, die Sie sich ansehen können 2021.

Diese Bibliotheken enthalten Funktionen wie den organisierten Umgang mit fehlenden Werten, Umgang mit Emojis, Konvertieren von Zahlen in Ints und Floats, Visualisierungs-Intelligence-Tools, Zeitreihenmodellierung und vieles mehr. Deckt ein breites Themenspektrum ab, Von der Verarbeitung natürlicher Sprache über die Datenvisualisierung bis hin zu Zeitreihen. Dann legen wir los.
Inhaltsverzeichnis
- Missingo
- Emot
- Bamboolib
- ppscore
- AutoViz
- Zähler
- PyFlux
- Flash-Text
Missingo
Reale Datasets enthalten in der Regel viele fehlende und NULL-Werte. Dies kann verschiedene Gründe haben, wie z. B. Datenlecks, Daten liegen nicht vor, etc. Manchmal, Es ist sehr irritierend, sich mit dieser Art von unübersichtlichen Daten auseinanderzusetzen. Diese unübersichtlichen Daten erfordern besondere Aufmerksamkeit, bevor sie in Algorithmen des maschinellen Lernens eingespeist werden, Da diese Algorithmen die fehlenden Werte nicht verarbeiten.
Wir brauchen einen besseren Ansatz, um mit diesen verlorenen Werten umzugehen. Hier kommt die Magie der Python-Bibliothek namens fehlen. Es hilft uns,oder mit Hilfe von Datenvisualisierungen mit fehlenden Werten umgehen auf eine viel bessere Art und Weise. Dies basiert auf matplotlib. Ab April 2021, Es verfügt über vier Arten von Diagrammen, um die Verteilung fehlender Daten zu verstehen, nämlich, das Balkendiagramm. Heatmap, Matrix und Dendrogramm. Dann legen wir los.
Installation
PIP install missingo
Importieren der Bibliothek
Missingo als MSNS importieren
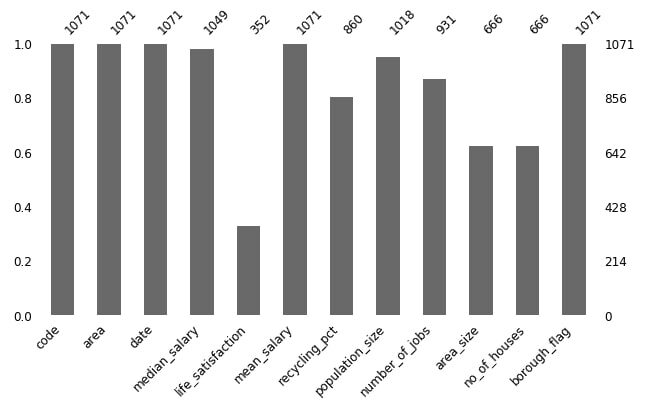
Im Balkendiagramm unten, Sie können die Anzahl der fehlenden Werte in jeder Spalte sehen:
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
Emot
Emojis sind in Chats sehr verbreitet. Wenn es um Aufgaben zur Verarbeitung natürlicher Sprache geht, Es ist sehr mühsam, sich mit Emojis zu beschäftigen. Hier kommt eine sehr nützliche Bibliothek, um Emoticons aus Textdaten loszuwerden. Es ist eine berühmte Python-Bibliothek, die sehr nützlich ist, wenn wir Umgang mit Emojis und Emoticons. Funktioniert gut mit Python 2 und Python 3. Es verwendet eine Zeichenfolge als Eingabe und gibt eine Liste aus dem Wörterbuch zurück. Dann legen wir los.
Installation
PIP Emot installieren
Importieren der Bibliothek
EMOT importieren
Code
import emot
text = "Ich liebe Python 👨 :-)"
emot.emoji(Text)
[{'Wert': '👨', 'bedeuten': ':Mann:', 'Lage': [14, 14], 'Flagge': Wahr}]
emot.emoticons(Text)
{'Wert': [':-)'], 'Lage': [[16, 19]], 'bedeuten': ["Glückliches Gesicht, Smiley"], 'Flagge': Wahr}

Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
Bamboolib
Das Analysieren und Visualisieren von Informationen ist die sinnvollste und zeitaufwändigste Interaktion. Wir müssen viel Zeit darauf verwenden, unmissverständlich zu untersuchen, was hier das Problem ist und was es zu sagen versucht. Wir verwenden verschiedene Arten von Python-Bibliotheken, um die Beispiele und Merkwürdigkeiten im Datensatz zu visualisieren und uns mit dem Datensatz vertraut zu machen.
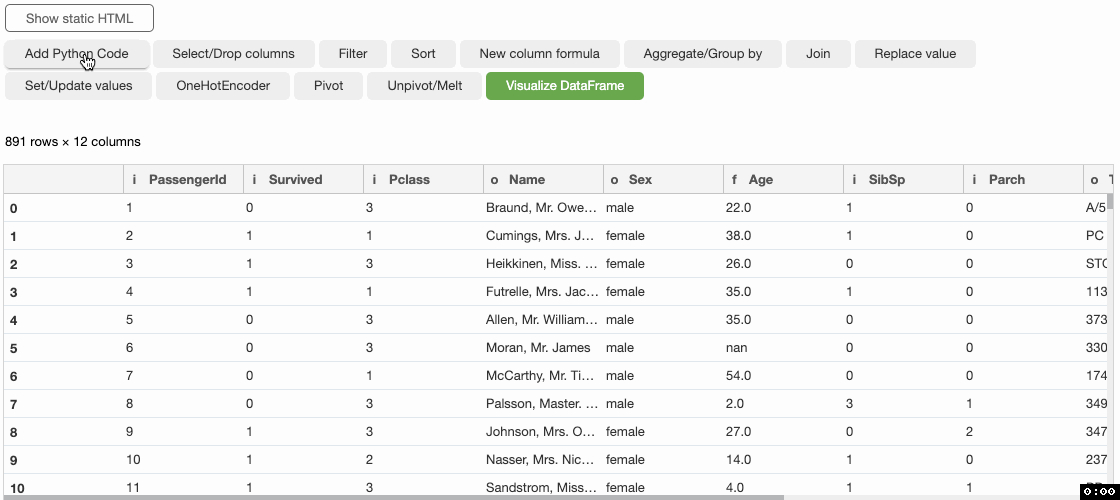
Bamboolib ist Panda GUI DataFrames , die es jedem ermöglicht, mit Python in Jupyter Notebook oder JupyterLab zu arbeiten. Bamboolib ist eine zutiefst intelligente und breit unterstützte Bibliothek, die es zu untersuchen gilt, Vorstellen und Kontrollieren von Informationen.
Eigentlich, Selbst eine Person ohne Programmierkenntnisse kann damit Wissen aus Informationen extrahieren, wie Du brauchst keine Programmiererfahrung. Bamboolib ist nicht Open Source, Das bedeutet, dass Sie Bamboolib kaufen müssen, um es zu verwenden, bietet aber eine kostenlose vorläufige Form von 14 Tage, damit Sie es vollständig untersuchen und wahrnehmen können, wie es für Sie sehr wertvoll sein kann.
Installation
PIP Bamboolib installieren
Importieren der Bibliothek
Bambus importieren

Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
ppscore
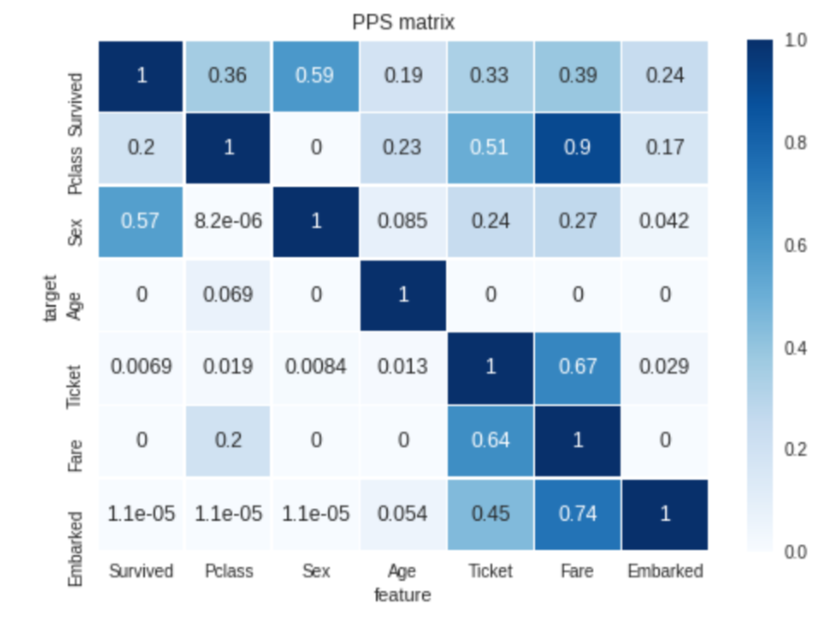
Die vollständige Ergänzung von ppscore ist der Predictive Power Score. Diese Python-Bibliothek wurde von Bamboolib-Entwicklern erstellt. Der Predictive Power Score ist eine Alternative zur Korrelationsmatrix. Dieser Score ist asymmetrisch und kann Erkennen von linearen oder nichtlinearen Beziehungen zwischen zwei Spalten in unserem Datensatz. Beginnen wir also mit dieser Bibliothek.
Installation
pip install ppscore
Importieren der Bibliothek
PPRescore importieren
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
AutoViz
Es ist die am meisten unterschätzte Python-Bibliothek, die jemals verwendet wurde zu Durchführen einer explorativen Datenanalyse. Diese Bibliothek visualisiert automatisch jede Art von Datensatz, einschließlich auch großer Datensätze. Schön Visualisierungen können mit einem einzigen Code gezeichnet werden.. Sie müssen nur Ihre Datendatei angeben (TXT, JSON oder CSV) und visualisieren Sie es automatisch. Laden Sie einfach Ihre Daten hoch und AutoViz stellt Ihnen automatisch die richtigen Diagramme zur Verfügung, mit denen Sie in Sekundenschnelle Erkenntnisse gewinnen können. Dann legen wir los.

Installation
pip install autoviz
Importieren der Bibliothek
Autoviz importieren
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
Zähler
Es ist ein sehr interessantes Python-Modul für die Textverarbeitung. Dass Konvertieren von Zahlen in natürlicher Sprache in Gleitkommazahlen und Ints. Dies ist ein sehr nützliches Modul bei der Verarbeitung natürlicher Sprache. Zu
Beispiel, Wenn du zweiundvierzig wirst’ In 42, "Eine Milliarde und eine’ In 1000000001
etc. Also lasst uns anfangen.
Installation
PIP Numerizer installieren
Importieren der Bibliothek
von numerizer import numerize
Code
Numerize("Zweiundvierzig")
'42'
numerize('eine Milliarde und eine')
'1000000001'
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
PyFlux
Die Zeitreihenforschung ist wohl das am häufigsten auftretende Problem im Bereich des maschinellen Lernens. PyFlux ist eine Open-Source-Bibliothek in Python, die eindeutig mit Zeitreihenproblemen arbeitet. Die Bibliothek verfügt über eine brillante Gruppe aktueller Zeiteinteilungsmodelle, darunter:, aber sie sind nicht auf ARIMA-Modelle beschränkt, GARCH und VAR. Deswegen, PyFlux bietet eine probabilistische Möglichkeit, mit der Visualisierung der Zeitdisposition umzugehen. Dann legen wir los.
Installation
PIP PyFlux installieren
Importieren der Bibliothek
Pyflux importieren
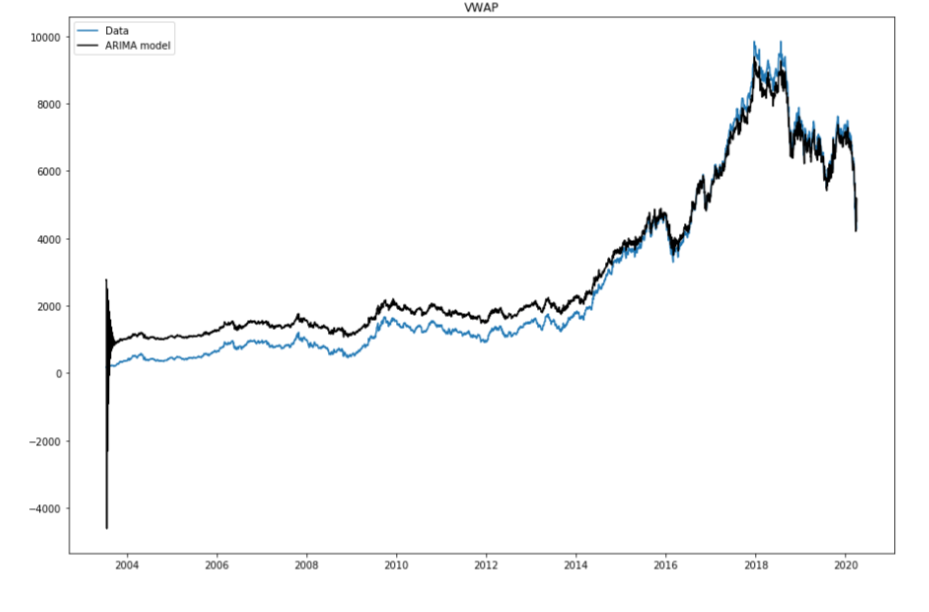
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
FlashText
FlashText ist eine explizit erstellte Python-Bibliothek Suche in der Ersetzung von Wörtern in einem Datensatz. Heutzutage, Die Funktionsweise von FlashText besteht darin, dass ein Wort oder eine Zusammenfassung von Wörtern und eine Zeichenfolge erforderlich sind. Wörter, die FlashText als Schlüsselwörter bezeichnet, werden in der Zeichenfolge untersucht oder ersetzt.
Lassen Sie uns Informationen über die Funktionsweise von FlashText sehen. Der Moment, in dem Schlüsselwörter zur Suche oder zum Spoofing an FlashText übergeben werden, werden als Trie-Datenstruktur gespeichert, die in Abrufaufträgen produktiv ist. Dann legen wir los.
Installation
PIP FlashText installieren
Importieren der Bibliothek
FlashText importieren
Aussehend:
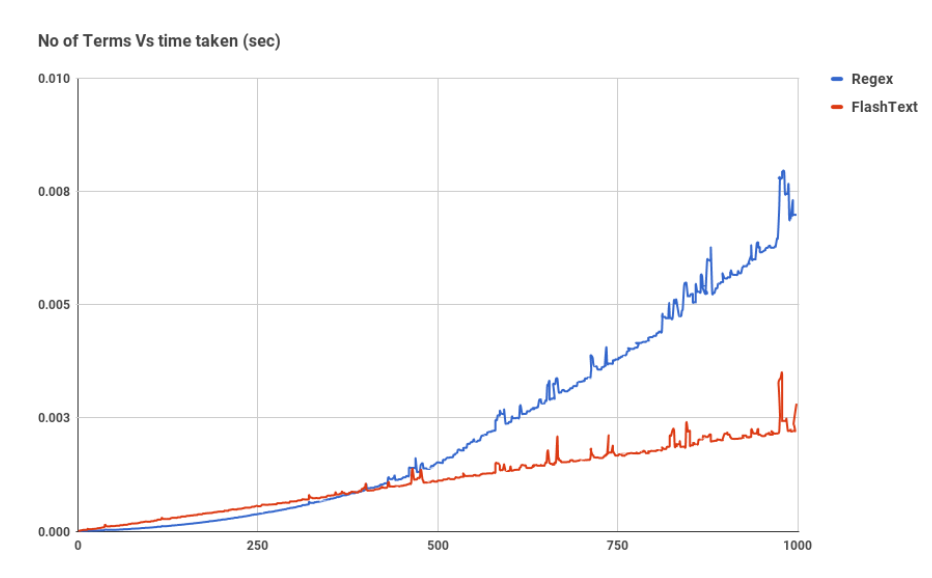
Ersatz:
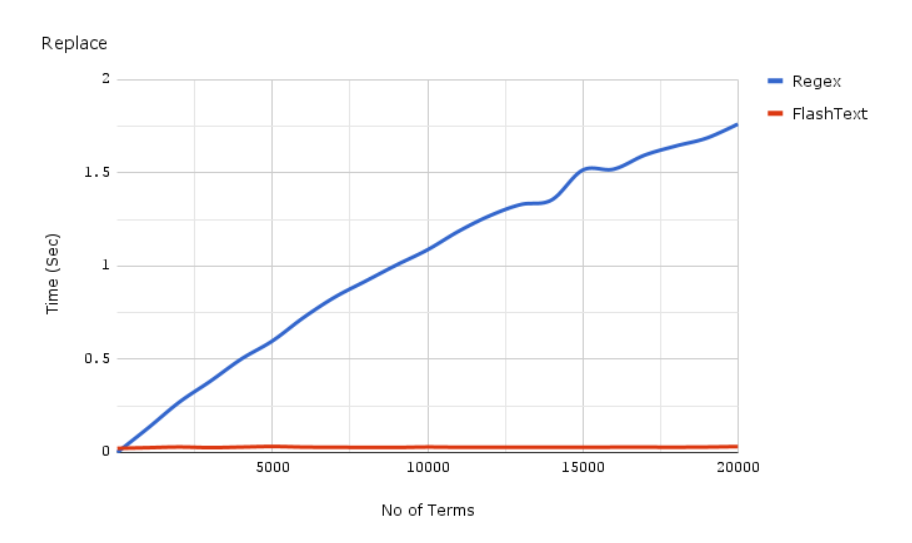
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation: Verknüpfung
Schlussbemerkung
Sie können meine Artikel hier einsehen: Artikel
Vielen Dank für das Lesen dieses Artikels und für Ihre Geduld.. Lassen Sie mich im Kommentarbereich über Kommentare. Teile diesen Artikel, es wird mir die Motivation geben, mehr Blogs für die Data Science Community zu schreiben.
E-Mail-Identifikation: gakshay1210@ gmail.com
Folgen Sie mir auf LinkedIn: LinkedIn
Die in diesem Artikel gezeigten Medien über Python-Pakete sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





