Einführung
Verarbeitung natürlicher Sprache (PNL) ist aufgrund der wachsenden Zahl von Anwendungen wie Chatbots ein Bereich mit zunehmender Aufmerksamkeit, automatische Übersetzung, etc. Irgendwie, Die gesamte intelligente Maschinenrevolution basiert auf der Fähigkeit, den Menschen zu verstehen und mit ihm zu interagieren.
Ich beschäftige mich schon seit einiger Zeit mit NLP. Meine Reise begann mit der NLTK-Bibliothek in Python, was war die empfohlene Bibliothek zu dieser Zeit. NLTK ist eine perfekte Bibliothek für Bildung und Forschung, wird sehr schwer und mühsam, selbst die einfachsten Aufgaben zu erledigen.
Später, Mir wurde TextBlob vorgestellt, die auf NLTK und Pattern basiert. Ein großer Vorteil davon ist, dass es leicht zu erlernen ist und viele Funktionen wie die Sentiment-Analyse bietet., Pos-Beschriftung, Extraktion von Nominalphrasen, etc. Es ist jetzt meine Referenzbibliothek für die Durchführung von NLP-Aufgaben.
Als Randnotiz, Es ist Platz, die weithin als eine der leistungsstarken und fortschrittlichen Bibliotheken anerkannt ist, die zur Implementierung von NLP-Aufgaben verwendet werden. Aber nachdem ich sowohl spacig als auch TextBlob gefunden habe, Ich würde TextBlob aufgrund seiner einfachen Benutzeroberfläche immer noch einem Anfänger empfehlen.
Wenn es Ihr erster Schritt in NLP ist, TextBlob ist die perfekte Bibliothek zum Üben. Der beste Weg, diesen Artikel zu lesen, ist, dem Code zu folgen und die Aufgaben selbst zu erledigen. Dann legen wir los!
Notiz : In diesem Artikel werden NLP-Aufgaben nicht ausführlich beschrieben. Wenn Sie die Grundlagen überprüfen und hierher zurückkehren möchten, Du kannst diesen Artikel immer lesen.
Inhaltsverzeichnis
- Über TextBlob?
- System einrichten
- Probieren Sie NLP-Aufgaben mit TextBlob . aus
- Tokenización
- Extraktion von Nominalphrasen
- POS-Kennzeichnung
- Beugung und Wortstammung
- N-Gramm
- Stimmungsanalyse
- Andere coole Dinge mit TextBlob
- Rechtschreibkorrektur
- Erstellen Sie eine kurze Zusammenfassung eines Textes
- Übersetzung und Spracherkennung
- Klassifizieren von Text mit TextBlob
- Vor-und Nachteile
- Abschließende Anmerkungen
1. Über TextBlob?
TextBlob ist eine Python-Bibliothek und bietet eine einfache API, um auf ihre Methoden zuzugreifen und grundlegende NLP-Aufgaben auszuführen.
Das Schöne an TextBlob ist, dass sie wie Python-Strings sind. Dann, Sie können es transformieren und damit spielen, wie wir es in Python getan haben. Dann, Ich habe Ihnen unten einige grundlegende Aufgaben gezeigt. Mach dir keine Sorgen über die Syntax, es soll Ihnen nur eine Vorstellung davon geben, wie verwandt der TextBlob mit Python-Strings ist.
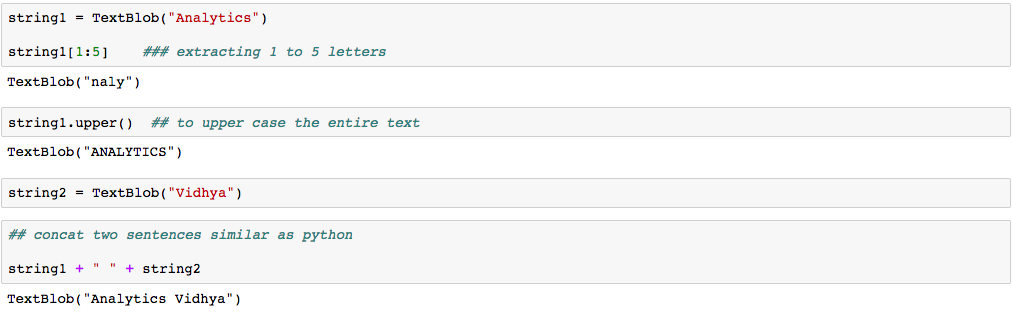 Dann, diese Dinge selbst zu tun, Lass uns schnell installieren und mit der Codierung beginnen.
Dann, diese Dinge selbst zu tun, Lass uns schnell installieren und mit der Codierung beginnen.
2. Systemkonfiguration
Installieren von TextBlob auf Ihrem System in einer einfachen Aufgabe, Alles, was Sie tun müssen, ist den Anakonda-Indikator zu öffnen (das Terminal selbst verwendet Mac OS oder Ubuntu) und geben Sie die folgenden Befehle ein:
pip install -U textblob
Dadurch wird TextBlob installiert. Für Uneingeweihte: Praktische Arbeit in der Verarbeitung natürlicher Sprache verwendet in der Regel große Mengen an linguistischen Daten, Ö Korpora. Zum Herunterladen des erforderlichen Korpus, Sie können den folgenden Befehl ausführen
python -m textblob.download_corpora
3. NLP-Aufgaben mit TextBlob
3.1 Tokenización
Tokenisierung bezieht sich auf das Aufteilen von Text oder einem Satz in eine Folge von Token, die ungefähr entsprechen “Wörter”. Dies ist eine der Grundaufgaben des NLP. Um dies mit TextBlob . zu tun, folge den zwei schritten:
- Ein ... kreieren Textblob Gegenstand und führen ein Seil damit.
- Lama Funktionen von textblob, um eine bestimmte Aufgabe auszuführen.
Dann, Lass uns schnell ein Textblob-Objekt zum Abspielen erstellen.
aus Textblob importieren TextBlob
blob = TextBlob("DataPeaker ist eine großartige Plattform, um Data Science zu lernen. n Es hilft der Community durch Blogs, Hackathons, Diskussionen,etc.")
Jetzt, dieser Textblock kann in einen Satz und dann in Wörter umgewandelt werden. Sehen wir uns den unten gezeigten Code an.
3.2 Extraktion von Nominalphrasen
Wie wir die Wörter im vorherigen Abschnitt extrahiert haben, stattdessen, wir können einfach die Nominalphrasen aus dem Textblock extrahieren. Die Extraktion von Nominalphrasen ist besonders wichtig, wenn Sie die “die” in einem Satz. Sehen wir uns unten ein Beispiel an.
blob = TextBlob("DataPeaker ist eine großartige Plattform, um Data Science zu lernen.")
für np in blob.noun_phrases:
drucken (z.B)
>> Analytics-vidhya
tolle Plattform
Datenwissenschaft
Wie wir sehen, die ergebnisse stimmen nicht ganz, aber wir müssen uns bewusst sein, dass wir mit Maschinen arbeiten.
3.3 Einen Teil der Stimme benennen
Part-of-Speech-Tagging oder Grammatik-Tagging ist eine Methode zum Markieren von Wörtern, die in einem Text vorhanden sind, basierend auf ihrer Definition und ihrem Kontext. In einfachen Worten, sagt, wenn ein Wort ein Nomen ist, ein Adjektiv, ein Verb, etc. Dies ist nur eine Vollversion der Extraktion von Nominalphrasen, wo wir alle Wortarten in einem Satz finden wollen.
Schauen wir uns die Beschriftungen unseres Textblocks an.
für Worte, Tag in blob.tags:
drucken (Wörter, Schild)
>> Analytics-NNS
Vidhya NNP
ist VBZ
ein DT
toller JJ
Plattform NN
nach TO
VB lernen
Daten NNS
Wissenschaft NN
Hier, NN steht für ein Substantiv, DT stellt eine Determinante dar, etc. Sie können die vollständige Liste der Labels unter einsehen hier zu wissen, aber.
3.4 Beugung und Wortstammung
Flexion ist ein Prozess von Wort Formation, bei der Zeichen zur Grundform von a . hinzugefügt werden Wort grammatikalische Bedeutungen ausdrücken. Wortflexion in TextBlob ist sehr einfach, nämlich, die Wörter, die wir aus einem Textblob tokenisiert haben, können leicht in Singular oder Plural geändert werden.
blob = TextBlob("DataPeaker ist eine großartige Plattform, um Data Science zu lernen. n Es hilft der Community durch Blogs, Hackathons, Diskussionen,etc.")
drucken (blob.sätze[1].Wörter[1])
drucken (blob.sätze[1].Wörter[1].singularisieren())
>> hilft
Hilfe
Die TextBlob-Bibliothek bietet auch ein integriertes Objekt namens Wort. Wir müssen nur ein Wortobjekt erstellen und dann eine Funktion direkt darauf anwenden, wie unten gezeigt.
aus Textblob importieren Word
w = Wort('Plattform')
w.pluralisieren()
>>'Plattformen'
Wir können die Tags auch verwenden, um eine bestimmte Art von Wörtern zu flektieren, wie unten gezeigt.
## mit Tags für Wort,pos in blob.tags: if pos == 'NN': drucken (Wort.pluralisieren()) >> Plattformen Wissenschaften
Wörter können mit gebildet werden lematizar Funktion.
## Lemmatisierung
w = Wort('Laufen')
w.lemmatisieren("v") ## v steht hier für Verb
>> 'Lauf'
3,5 N-Gramm
Eine Kombination mehrerer Wörter zusammen wird als N-Grams bezeichnet. Die N Gramm (n> 1) sind im Allgemeinen informativer als Wörter und können als Funktionen für die Sprachmodellierung verwendet werden. Auf N-Gramme kann in TextBlob einfach über die ngramas Funktion, was ein Tupel von n aufeinanderfolgenden Wörtern zurückgibt.
für ngram in blob.ngrams(2):
drucken (ngram)
>> ['Analytik', 'Vidhya']
['Vidhya', 'ist']
['ist', 'ein']
['ein', 'groß']
['groß', 'Plattform']
['Plattform', 'zu']
['zu', 'lernen']
['lernen', 'Daten']
['Daten', 'Wissenschaft']
3.6 Stimmungsanalyse
Die Stimmungsanalyse ist im Grunde der Prozess der Bestimmung der Einstellung oder Emotion des Autors, nämlich, ja es ist positiv, negativ oder neutral.
das Gefühl Die Textblob-Funktion gibt zwei Eigenschaften zurück, Polarität, Ja Subjektivität.
Die Polarität ist schwebend und liegt im Bereich von [-1,1] wo 1 bedeutet positive Aussage und -1 bedeutet negative Aussage. Subjektive Sätze beziehen sich im Allgemeinen auf Meinungen, persönliche Emotionen oder Urteile, während sich die objektiven auf sachliche Informationen beziehen. Subjektivität ist auch ein Schwimmer, der im Bereich von liegt [0,1].
Lassen Sie uns das Gefühl unseres Blobs überprüfen.
drucken (Klecks) blob.gefühl >> DataPeaker ist eine großartige Plattform, um Data Science zu lernen. Gefühl(Polarität=0.8, Subjektivität=0.75)
Wir können sehen, dass die Polarität 0,8, was bedeutet, dass die Aussage positiv ist und 0,75 Subjektivität bezieht sich auf die Tatsache, dass es sich meistens um eine öffentliche Meinung und nicht um eine sachliche Information handelt.
4. Andere coole Dinge zu tun
4.1 Rechtschreibkorrektur
Die Rechtschreibprüfung ist eine interessante Funktion, die TextBlob bietet, Sie erreichen uns über die Richtig Arbeite wie unten gezeigt.
blob = TextBlob('DataPeaker ist eine großartige Plattform zum Erlernen von Datenwissenschaften')
blob.korrekt()
>> TextBlob("DataPeaker ist eine großartige Plattform, um Data Science zu lernen")
Wir können auch die Liste der vorgeschlagenen Wörter und Ihr Vertrauen mit der Rechtschreibprüfung Funktion.
blob.words[4].Rechtschreibprüfung()
>> [('groß', 0.5351351351351351),
('werden', 0.3162162162162162),
('gewachsen', 0.11216216216216217),
('grau', 0.026351351351351353),
('grüßen', 0.006081081081081081),
('Bund', 0.002702702702702703),
('Streugut', 0.0006756756756756757),
('lockig', 0.0006756756756756757)]
4.2 Erstellen Sie eine kurze Zusammenfassung eines Textes
Dies ist ein einfacher Trick, mit dem wir die Dinge verwenden, die wir zuvor gelernt haben. Zuerst, werfen Sie einen Blick auf den unten gezeigten Code und verstehen Sie sich selbst.
zufällig importieren
blob = TextBlob('DataPeaker ist eine florierende Community für die datengesteuerte Industrie. Diese Plattform ermöglicht
Leute, um mehr über Analytics aus seinen Artikeln zu erfahren, Q&Ein Forum, und Lernwege. Ebenfalls, wir helfen
Profis & Amateure, ihre Fähigkeiten zu verbessern, indem sie eine Plattform für die Teilnahme an Hackathons bereitstellen.')
Nomen = Liste()
für Wort, Tag in blob.tags:
if-Tag == 'NN':
Nomen.anhängen(Wort.lemmatisieren())
drucken ("In diesem Text geht es um...")
für Artikel in random.sample(Substantive, 5):
Wort = Wort(Artikel)
drucken (Wort.pluralisieren())
>> In diesem Text geht es um...
Gemeinschaften
Plattformen
Foren
Plattformen
Branchen
Einfach, Es ist nicht so? Vorher haben wir eine Liste von Substantiven aus dem Text extrahiert, um dem Leser eine allgemeine Vorstellung von den Dingen zu geben, auf die sich der Text bezieht..
4.3 Übersetzung und Spracherkennung
Können Sie erraten, was in der folgenden Zeile steht??
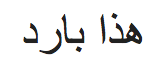
Und und! Können Sie erraten, welche Sprache das ist?? Mach dir keine Sorgen, wir erkennen es mit textblob…
blob.detect_language() >> 'Mit'
Dann, Es ist arabisch. Jetzt, Versuchen wir, es ins Englische zu übersetzen, damit wir wissen, was mit TextBlob geschrieben wird.
blob.translate(from_lang='ar', to = 'de')
>> TextBlob("das ist cool")
Auch wenn Sie die Ausgangssprache nicht explizit definieren, TextBlob erkennt die Sprache automatisch und übersetzt sie in die gewünschte Sprache.
blob.translate(to = 'de') ## oder du kannst direkt so machen
>> TextBlob("das ist cool")
Das ist wirklich cool !!! 😀
5. Klassifizieren von Text mit TextBlob
Lassen Sie uns mit TextBlob ein einfaches Textklassifizierungsmodell erstellen. Dafür, erste, wir müssen ein Training vorbereiten und Daten testen.
Ausbildung = [
('Tom Holland ist ein schrecklicher Spiderman.','pos'),
('ein schrecklicher Javert (Russell Crowe) hat Les Miserables für mich ruiniert...','pos'),
("The Dark Knight Rises ist der größte Superheldenfilm aller Zeiten"!','neg'),
('Fantastic Four hätte nie gemacht werden dürfen.','pos'),
(„Wes Anderson ist mein Lieblingsregisseur!','neg'),
(„Kapitän Amerika“ 2 ist ziemlich genial.','neg'),
('Lass uns so tun als ob "Batman und Robin" nie passiert..','pos'),
]
testen = [
("Superman war nie ein interessanter Charakter.",'pos'),
(„Fantastischer Mr. Fox ist ein großartiger Film!','neg'),
("Dragonball Evolution ist einfach schrecklich"!!','pos')
]
Textblob bietet ein integriertes Klassifikatormodul zum Erstellen eines benutzerdefinierten Klassifikators. Dann, lass es uns schnell importieren und einen einfachen Klassifikator erstellen.
von Textblob-Importklassifikatoren Klassifikator = Klassifikatoren.NaiveBayesClassifier(Ausbildung)
Wie oben zu sehen ist, wir haben die Trainingsdaten an den Klassifikator übergeben.
Beachten Sie, dass wir hier den Naive Bayes-Klassifikator verwendet haben, TextBlob bietet aber auch den unten gezeigten Entscheidungsbaum-Klassifizierer.
## Entscheidungsbaum-Klassifikator dt_classifier = classifiers.DecisionTreeClassifier(Ausbildung)
Jetzt, Lassen Sie uns die Genauigkeit dieses Klassifikators für den Testdatensatz überprüfen und TextBlob bietet uns auch die Möglichkeit, die informativeren Funktionen zu überprüfen.
drucken (Klassifikator.Genauigkeit(testen))
classifier.show_informative_features(3)
>> 1.0
Die informativsten Funktionen
enthält(ist) = Wahres Negativ : pos = 2.9 : 1.0
enthält(abscheulich) = Falsch negativ : pos = 1.8 : 1.0
enthält(noch nie) = Falsch negativ : pos = 1.8 : 1.0
Was, Wir können das sehen, wenn der Text enthält “es ist”, dann ist die Aussage mit hoher Wahrscheinlichkeit negativ.
Um eine kleine Idee zu geben, Lassen Sie uns unseren Klassifikator auf einen zufälligen Text überprüfen.
blob = TextBlob('das Wetter ist schrecklich!', Klassifizierer = Klassifizierer)
drucken (blob.klassifizieren())
>> negativ
Dann, basierend auf Training im obigen Datensatz, unser Klassifikator hat uns das richtige Ergebnis geliefert.
Beachten Sie, dass wir hier eine Datenvorverarbeitung und -bereinigung hätten durchführen können, Aber hier war mein Ziel, Ihnen eine Idee zu geben, wie wir mit TextBlob eine Textklassifizierung durchführen können.
6. Vor-und Nachteile
Vorteile:
- Angenommen, ist auf den Schultern von NLTK und Pattern aufgebaut, Daher, macht es Anfängern einfach, indem es eine intuitive Benutzeroberfläche für NLTK . bereitstellt.
- Bietet Übersetzungs- und Spracherkennung, die mit Google Translate funktioniert (nicht mit Spacy ausgestattet).
Nachteile:
- Es ist etwas langsamer im Vergleich zum Weltraum, aber schneller als NLTK. (Platz> TextBlob> NLTK)
- Bietet keine Funktionen wie Abhängigkeitsanalyse, Wortvektoren, etc. das sorgt für spacig.
7. Abschließende Anmerkungen
Ich wünsche Ihnen viel Spaß beim Lernen dieser Bibliothek. TextBlob, in Wirklichkeit, bietet eine sehr einfache Schnittstelle für Anfänger, um grundlegende NLP-Aufgaben zu erlernen.
Ich würde allen Anfängern empfehlen, mit dieser Bibliothek zu beginnen und dann, fortgeschrittene Arbeit leisten, Sie können auch lernen, Abstand zu halten. Wir werden TextBlob weiterhin für das erste Prototyping in fast allen NLP-Projekten verwenden.
Den vollständigen Code für diesen Artikel finden Sie in meinem github Repository.
Was ist mehr, Fanden Sie diesen Artikel nützlich?? Teile deine Meinung / Gedanken im Kommentarbereich unten.





