Einführung
Hin und wieder, Es wird eine Python-Bibliothek entwickelt, die das Potenzial hat, die Landschaft im Bereich Deep Learning zu verändern. PyTorch ist eine dieser Bibliotheken.
In den letzten Wochen, Ich habe mich ein bisschen mit PyTorch beschäftigt. Ich war beeindruckt, wie leicht es zu verstehen ist. Unter den verschiedenen Deep-Learning-Frameworks, die ich bisher verwendet habe, PyTorch war die flexibelste und müheloseste von allen.
![]()
In diesem Artikel, Wir werden PyTorch mit einem praktischeren Ansatz erkunden, die Grundlagen zusammen mit einer Fallstudie. Wir werden auch ein neurales Netzwerk vergleichen, das sowohl in numpy als auch in PyTorch von Grund auf neu erstellt wurde, um ihre Ähnlichkeiten in der Implementierung zu sehen..
Lass uns weitermachen!
Notiz: In diesem Artikel wird davon ausgegangen, dass Sie über ein grundlegendes Verständnis von Deep Learning verfügen. Wenn Sie Deep Learning nachholen möchten, zuerst diesen Artikel lesen.
Was ist mehr, wenn Sie eine detailliertere Erklärung von PyTorch von Grund auf wünschen, verstehen, wie Spanner funktionieren, wie Sie mit PyTorch mathematische und Matrixoperationen durchführen können, Ich empfehle dringend, dass Sie sich einen Anfängerleitfaden für PyTorch und wie es von Grund auf funktioniert, ansehen.
Inhaltsverzeichnis
- Ein Überblick über PyTorch
- Tauchen Sie ein in die technischen Details
- Aufbau eines neuronalen Netzwerks in Numpy vs. PyTorch
- Vergleich mit anderen Deep-Learning-Bibliotheken
- Fallstudie: Lösen eines Bilderkennungsproblems mit PyTorch
Wenn Sie die folgenden Konzepte lieber in einem strukturierten Format behandeln möchten, Sie können sich für diesen kostenlosen Kurs anmelden unter PyTorch und folge ihnen nach Kapiteln.
Ein Überblick über PyTorch
Die Schöpfer von PyTorch sagen, dass sie eine Philosophie haben: sie wollen zwingend sein. Das bedeutet, dass wir unsere Berechnung sofort ausführen. Das passt perfekt in die Python-Programmiermethodik, Was Wir müssen nicht warten, bis der gesamte Code geschrieben ist, bevor wir wissen, ob er funktioniert oder nicht. Wir können ganz einfach einen Teil des Codes ausführen und in Echtzeit überprüfen. Für mich, als Debugger für neuronale Netze, Das ist ein Segen!
PyTorch ist eine Python-basierte Bibliothek, die entwickelt wurde, um Flexibilität als Deep-Learning-Entwicklungsplattform zu bieten. Der PyTorch-Workflow ist der wissenschaftlichen Computerbibliothek von Python am nächsten: numpy.
Jetzt könnte ich fragen, Warum sollten wir PyTorch verwenden, um Deep-Learning-Modelle zu erstellen?? Ich kann drei Dinge aufzählen, die helfen könnten, das zu beantworten:
- Einfach zu bedienende API – Es ist so einfach wie Python sein kann.
- Python-Unterstützung – Wie bereits erwähnt, PyTorch lässt sich nahtlos in den Python Data Science Stack integrieren. Es ist numpy so ähnlich, dass Sie den Unterschied vielleicht nicht einmal bemerken.
- Dynamische Berechnungsgrafiken – Statt vordefinierter Charts mit spezifischen Funktionalitäten, PyTorch bietet uns einen Rahmen, um Computergrafiken zu erstellen, während wir fortfahren, und wir ändern sie sogar während der Laufzeit. Dies ist nützlich für Situationen, in denen wir nicht wissen, wie viel Speicher benötigt wird, um ein neuronales Netzwerk zu erstellen..
Einige weitere Vorteile der Verwendung von PyTorch sind die MultiGPU-Unterstützung, benutzerdefinierte Datenlader und vereinfachte Präprozessoren.
Seit seiner Einführung Anfang Januar 2016, viele Forscher haben es aufgrund seiner einfachen Erstellung neuer und sogar extrem komplexer Grafiken als Referenzbibliothek übernommen.. Nachdem ich das gesagt habe, es bleibt noch einige Zeit, bis PyTorch aufgrund seiner neuen und “im Aufbau”.
Tauchen Sie ein in die technischen Details
Bevor wir in die Details eintauchen, Sehen wir uns den PyTorch-Workflow an.
PyTorch verwendet ein zwingendes Paradigma / Ängstlich. Nämlich, Jede Codezeile, die zum Erstellen eines Diagramms erforderlich ist, definiert eine Komponente dieses Diagramms. Wir können Berechnungen an diesen Komponenten unabhängig durchführen, noch bevor Ihr Diagramm vollständig erstellt ist. Das nennt man “Definition durch Ausführung”.

Quelle: http://pytorch.org/about/
Die Installation von PyTorch ist ziemlich einfach. Sie können die Schritte ausführen, die in der offizielle Dokumente und führen Sie den Befehl gemäß Ihren Systemspezifikationen aus. Zum Beispiel, Dies war der Befehl, den ich basierend auf den von mir gewählten Optionen verwendet habe:
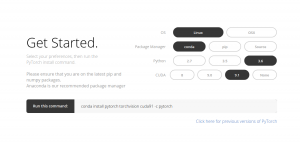
conda install pytorch Torchvision cuda91 -c pytorch
Die wichtigsten Elemente, die wir kennen müssen, wenn wir mit PyTorch beginnen, sind:
- PyTorch Spanner
- Mathematische Operationen
- Selbstbenotungsmodul
- Optim-Modul und
- Modul nn
Dann, wir werden uns jeden von ihnen genauer ansehen.
PyTorch Spanner
Tensoren sind nichts anderes als mehrdimensionale Matrizen. Tensoren in PyTorch ähneln den Ndarrays von Numpy, mit dem Zusatz, dass die Spanner auch auf einer GPU verwendet werden können. PyTorch-kompatibel verschiedene Arten von Spannern. Wenn Sie mit anderen Deep-Learning-Frameworks vertraut sind, muss auch Tensoren in TensorFlow gefunden haben. Eigentlich, Sie können auch die folgenden Aufgaben in Tensorflow implementieren und Ihren eigenen Vergleich zwischen PyTorch und TensorFlow durchführen.
Sie können ein einfaches eindimensionales Array wie unten gezeigt definieren:
# pytorch importieren Taschenlampe importieren # einen Tensor definieren Taschenlampe.FloatTensor([2])
2 [Fackel.FloatTensor der Größe 1]
Mathematische Operationen
Wie bei numpy, Es ist sehr wichtig, dass eine wissenschaftliche Computerbibliothek effiziente Implementierungen mathematischer Funktionen hat. PyTorch bietet Ihnen eine ähnliche Schnittstelle, mit mehr von 200 mathematische Operationen du kannst verwenden.
Unten ist ein Beispiel für eine einfache Additionsoperation in PyTorch:
a = Fackel.FloatTensor([2]) b = Brenner.FloatTensor([3]) ein + B
5 [Fackel.FloatTensor der Größe 1]
Klingt das nicht nach einem kinessentiellen Python-Ansatz?? Wir können auch verschiedene Matrixoperationen an den von uns definierten PyTorch-Tensoren durchführen. Zum Beispiel, wir transponieren eine zweidimensionale Matrix:
matrix = fackel.randn(3, 3) Matrix 0.7162 1.0152 1.1525 -0.3503 -0.9452 -1.0861 -0.1093 -0.0927 -0.0476 [Taschenlampe.FloatTensor der Größe 3x3] matrix.t() 0.7162 -0.3503 -0.1093 1.0152 -0.9452 -0.0927 1.1525 -1.0861 -0.0476 [Taschenlampe.FloatTensor der Größe 3x3]
Selbstbenotungsmodul
PyTorch verwendet eine Technik namens automatische Unterscheidung. Nämlich, Wir haben einen Recorder, der die von uns durchgeführten Operationen aufzeichnet und dann abspielt, um unsere Gradienten zu berechnen. Diese Technik ist besonders leistungsstark beim Aufbau neuronaler Netze, da wir bei der Berechnung der Differenzierung der Parameter im Direktdurchlauf Zeit in einer Epoche sparen.
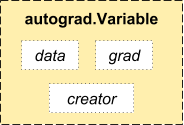
Quelle: http://pytorch.org/about/
aus fackel.autograd Importvariable x = variabel(train_x) y = variabel(train_y, require_grad=Falsch)
Optimales Modul
torch.optim ist ein Modul, das verschiedene Optimierungsalgorithmen implementiert, die zum Aufbau neuronaler Netze verwendet werden. Die meisten der am häufigsten verwendeten Methoden werden bereits unterstützt, damit wir sie nicht von Grund auf neu erstellen müssen (Außer du willst!).
Unten ist der Code zur Verwendung eines Adam-Optimierers:
Optimierer = brenner.optim.Adam(modell.parameter(), lr=learning_rate)
Modul nn
PyTorch autograd erleichtert das Definieren von Computergrafiken und das Aufnehmen von Farbverläufen, aber das rohe Autograd kann zu niedrig sein, um komplexe neuronale Netze zu definieren. Hier kann das nn-Modul helfen.
Das Paket nn definiert eine Reihe von Modulen, die wir als neuronale Netzwerkschicht betrachten können, die eine Ausgabe aus der Eingabe erzeugt und einige trainierbare Gewichtungen haben kann.
Sie können ein Modul nn als das schwer von PyTorch!
Taschenlampe importieren # Modell definieren model = brenner.nn.sequentiell( fackel.nn.Linear(input_num_units, hidden_num_units), fackel.nn.ReLU(), fackel.nn.Linear(hidden_num_units, output_num_units), ) loss_fn = fackel.nn.CrossEntropyLoss()
Jetzt kennen Sie die Grundkomponenten von PyTorch, Sie können ganz einfach Ihr eigenes neuronales Netzwerk von Grund auf neu aufbauen. Folgen Sie ihm, wenn Sie wissen möchten, wie!
Aufbau eines neuronalen Netzwerks in Numpy vs. PyTorch
Ich habe oben erwähnt, dass PyTorch und Numpy sehr ähnlich sind. Mal sehen warum. In diesem Abschnitt, Wir werden eine Implementierung eines einfachen neuronalen Netzes sehen, um ein binäres Klassifikationsproblem zu lösen (Sie können diesen Artikel für eine detaillierte Erklärung lesen).
## Neuronales Netzwerk in numpy
numpy als np importieren
#Eingabe-Array
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Ausgabe
y=np.array([[1],[1],[0]])
#Sigmoid-Funktion
def sigmoid (x):
Rückkehr 1/(1 + np.exp(-x))
#Ableitung der Sigmoidfunktion
def derivate_sigmoid(x):
Rückgabe x * (1 - x)
#Variableninitialisierung
epoch=5000 #Trainingsiterationen einstellen
lr=0.1 #Lernrate einstellen
inputlayer_neurons = X.shape[1] #Anzahl der Features im Datensatz
hiddenlayer_neurons = 3 #Anzahl der versteckten Schichten Neuronen
Ausgabe_Neuronen = 1 #Anzahl der Neuronen auf der Ausgangsschicht
#Gewichtungs- und Bias-Initialisierung
wh=np.zufällig.uniform(Größe=(inputlayer_neurons,Hiddenlayer_neurons))
bh=np.random.uniform(Größe=(1,Hiddenlayer_neurons))
wout=np.random.uniform(Größe=(Hiddenlayer_neurons,Ausgabe_Neuronen))
bout=np.random.uniform(Größe=(1,Ausgabe_Neuronen))
für mich in Reichweite(Epoche):
#Weiterleitung
hidden_layer_input1=np.dot(x,NS)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1=np.dot(hiddenlayer_activations,Straße)
output_layer_input= output_layer_input1+ Kampf
Ausgang = Sigmoid(output_layer_input)
#Backpropagation
E = y-Ausgang
Steigung_Ausgabe_Schicht = Derivate_sigmoid(Ausgang)
Steigung_hidden_layer = Derivate_sigmoid(hiddenlayer_activations)
d_Ausgabe = E * Steigung_Ausgabe_Schicht
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * Steigung_hidden_layer
wout += hiddenlayer_activations.T.dot(d_ausgabe) *lr
Kampf += np.sum(d_ausgabe, Achse=0,keepdims=True) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh + = np.sum(d_hiddenlayer, Achse=0,keepdims=True) *lr
drucken('tatsächlich :n', Ja, 'n')
drucken('vorhergesagt :n', Ausgang)
Jetzt, Versuchen Sie, den Unterschied in einer supereinfachen Implementierung desselben in PyTorch zu erkennen (die Unterschiede sind im folgenden Code fett gedruckt).
## neuronales netzwerk in pytorch
Taschenlampe importieren
#Eingabe-Array
X = Taschenlampe.Tensor([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Ausgabe
y = Taschenlampe.Tensor([[1],[1],[0]])
#Sigmoid-Funktion
def sigmoid (x):
Rückkehr 1/(1 + fackel.exp(-x))
#Ableitung der Sigmoidfunktion
def derivate_sigmoid(x):
Rückgabe x * (1 - x)
#Variableninitialisierung
epoch=5000 #Trainingsiterationen einstellen
lr=0.1 #Lernrate einstellen
inputlayer_neurons = X.shape[1] #Anzahl der Features im Datensatz
hiddenlayer_neurons = 3 #Anzahl der versteckten Schichten Neuronen
Ausgabe_Neuronen = 1 #Anzahl der Neuronen auf der Ausgangsschicht
#Gewichtungs- und Bias-Initialisierung
w=fackel.randn(inputlayer_neurons, Hiddenlayer_neurons).Typ(Taschenlampe.FloatTensor)
bh=fackel.randn(1, Hiddenlayer_neurons).Typ(Taschenlampe.FloatTensor)
Straße =fackel.randn(Hiddenlayer_neurons, Ausgabe_Neuronen)
Kampf=fackel.randn(1, Ausgabe_Neuronen)
für mich in Reichweite(Epoche):
#Weiterleitung
hidden_layer_input1 = Taschenlampe.mm(x, NS)
hidden_layer_input = hidden_layer_input1 + bh
hidden_layer_activations = sigmoid(hidden_layer_input)
output_layer_input1 = Taschenlampe.mm(hidden_layer_activations, Straße)
output_layer_input = output_layer_input1 + Kampf
Ausgang = Sigmoid(output_layer_input1)
#Backpropagation
E = y-Ausgang
Steigung_Ausgabe_Schicht = Derivate_sigmoid(Ausgang)
Steigung_hidden_layer = Derivate_sigmoid(hidden_layer_activations)
d_Ausgabe = E * Steigung_Ausgabe_Schicht
Error_at_hidden_layer = Taschenlampe.mm(d_ausgabe, wout.t())
d_hiddenlayer = Error_at_hidden_layer * Steigung_hidden_layer
wout += Taschenlampe.mm(hidden_layer_activations.t(), d_ausgabe) *lr
Kampf += d_output.sum() *lr
w += Taschenlampe.mm(X.t(), d_hiddenlayer) *lr
bh += d_output.sum() *lr
drucken('tatsächlich :n', Ja, 'n')
drucken('vorhergesagt :n', Ausgang)
Vergleich mit anderen Deep-Learning-Bibliotheken
In Eins Benchmarking-Skript, Es hat sich gezeigt, dass PyTorch alle anderen großen Deep-Learning-Bibliotheken beim Training eines Lang- und Kurzzeitgedächtnisnetzwerks übertrifft (LSTM) mit der niedrigsten Medianzeit pro Epoche (siehe Bild unten).

APIs zum Laden von Daten sind in PyTorch gut gestaltet. Schnittstellen werden in einem Datensatz spezifiziert, ein Sampler und ein Dataloader.
Beim Vergleich von Tools zum Laden von Daten in TensorFlow (Leser, colas, etc.), ich fand PyTorchDatenlademodule sind recht einfach zu bedienen. Was ist mehr, PyTorch ist perfekt, wenn Sie versuchen, ein neuronales Netzwerk aufzubauen, Wir müssen uns also nicht auf High-Level-Bibliotheken von Drittanbietern wie keras verlassen.
Zweitens, Ich würde immer noch nicht empfehlen, PyTorch für die Implementierung zu verwenden. PyTorch muss sich noch entwickeln. Wie die PyTorch-Entwickler gesagt haben, „Was wir sehen, ist, dass Benutzer zuerst ein PyTorch-Modell erstellen. Wenn sie bereit sind, ihr Modell in der Produktion bereitzustellen, mach es einfach zu einem Caffe-Modell 2 und dann senden sie es an eine mobile Plattform oder eine andere ".
Fallstudie: Lösen eines Bilderkennungsproblems in PyTorch
Um sich mit PyTorch vertraut zu machen, Wir werden das Deep-Learning-Praxisproblem von DataPeaker lösen: Identifiziere die Ziffern. Werfen wir einen Blick auf unsere Problemstellung:
Unser Problem ist ein Bilderkennungsproblem, um Ziffern eines bestimmten Bildes von . zu identifizieren 28 x 28. Wir haben eine Teilmenge von Bildern zum Trainieren und den Rest zum Testen unseres Modells.
Zuerst, Laden Sie die Zug- und Testdateien herunter. Der Datensatz enthält eine komprimierte Datei aller Bilder und sowohl train.csv als auch test.csv sind nach den entsprechenden Zug- und Testbildern benannt. Zusätzliche Funktionen sind in den Datensätzen nicht enthalten, Nur Rohbilder werden im '.png'-Format bereitgestellt.
Lasst uns beginnen:
PASO 0: Fertig werden
ein) Importieren Sie alle erforderlichen Bibliotheken
# Module importieren %pylab inline Importieren von OS numpy als np importieren Pandas als pd importieren von scipy.misc import imread von sklearn.metrics import precision_score
B) Lass uns einen Seed-Wert setzen, damit wir die Zufälligkeit unserer Modelle kontrollieren können
# Um potenzielle Zufälligkeiten zu stoppen Samen = 128 rng = np.random.RandomState(Samen)
C) Der erste Schritt besteht darin, Verzeichnispfade festzulegen, Zu Ihrer Sicherheit!
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'Daten')
# auf Existenz prüfen
os.path.exists(root_dir), os.path.exists(data_dir)
PASO 1: Datenladen und Vorverarbeitung
ein) Jetzt lesen wir unsere Datensätze. Diese liegen im .csv-Format vor und haben einen Dateinamen zusammen mit den entsprechenden Tags.
# Datensatz laden train = pd.read_csv(os.path.join(data_dir, 'Bahn', 'train.csv')) test = pd.read_csv(os.path.join(data_dir, 'Test.csv')) sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv')) train.head()
| Dateiname | Etikett | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
B) Mal sehen, wie unsere Daten aussehen!! Wir lesen unser Bild und zeigen es.
# ein Bild drucken
img_name = rng.choice(train.Dateiname)
filepath = os.path.join(data_dir, 'Bahn', 'Bilder', 'Bahn', img_name)
img = imread(Dateipfad, flatten=Wahr)
pylab.imshow(img, cmap='grau')
pylab.achse('aus')
pylab.show()

D) Zur einfacheren Datenmanipulation, Wir speichern alle unsere Bilder als numpy Arrays
# Bilder laden, um Zug- und Testset zu erstellen
Temperatur = []
für img_name in train.filename:
image_path = os.path.join(data_dir, 'Bahn', 'Bilder', 'Bahn', img_name)
img = imread(Bildpfad, flatten=Wahr)
img = img.astype('float32')
temp.anhängen(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astyp('float32')
Temperatur = []
für img_name in test.filename:
image_path = os.path.join(data_dir, 'Bahn', 'Bilder', 'Prüfung', img_name)
img = imread(Bildpfad, flatten=Wahr)
img = img.astype('float32')
temp.anhängen(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astyp('float32')
train_y = train.label.values
e) Wie es ein typisches AA-Problem ist, Um die korrekte Funktion unseres Modells zu testen, erstellen wir ein Validierungsset. Nehmen wir eine Divisionsgröße von 70:30 für den Zugsatz vs. den Validierungssatz
# Validierungsset erstellen split_size = int(train_x.shape[0]*0.7) train_x, val_x = train_x[:split_size], train_x[split_size:] train_y, val_y = train_y[:split_size], train_y[split_size:]
PASO 2: Modellbau
ein) Jetzt kommt der Hauptteil! Lassen Sie uns unsere neuronale Netzwerkarchitektur definieren. Wir definieren ein neuronales Netz mit 3 Eingabeebenen, versteckt und verlassen. Die Anzahl der Neuronen in Input und Output ist fest, denn der Input ist unser Bild von 28 x 28 und die Ausgabe ist ein Vektor von 10 x 1 was stellt die klasse dar. Wir nehmen 50 Neuronen in der verborgenen Schicht. Hier verwenden wir Adam wie unsere Optimierungsalgorithmen, das ist eine effiziente Variante des Gradient Descent Algorithmus.
Taschenlampe importieren aus fackel.autograd Importvariable
# Anzahl der Neuronen in jeder Schicht input_num_units = 28*28 hidden_num_units = 500 output_num_units = 10 # verbleibende Variablen setzen Epochen = 5 batch_size = 128 Lernrate = 0.001
B) Zeit unser Modell zu trainieren
# Modell definieren model = brenner.nn.sequentiell( fackel.nn.Linear(input_num_units, hidden_num_units), fackel.nn.ReLU(), fackel.nn.Linear(hidden_num_units, output_num_units), ) loss_fn = fackel.nn.CrossEntropyLoss() # Optimierungsalgorithmus definieren Optimierer = brenner.optim.Adam(modell.parameter(), lr=learning_rate)
## Hilfsfunktionen
# einen Batch von Datensätzen vorverarbeiten
def preproc(unrein_batch_x):
"""Werte in Bereich umwandeln 0-1"""
temp_batch = unsauber_batch_x / unrein_batch_x.max()
temp_batch zurückgeben
# einen Stapel erstellen
def batch_creator(batch_size):
dataset_name="Bahn"
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, batch_size)
batch_x = eval(dataset_name + '_x')[Batch_Maske]
batch_x = preproc(batch_x)
if dataset_name == 'train':
batch_y = eval(dataset_name).ix[Batch_Maske, 'Etikett'].Werte
Batch_x zurückgeben, batch_y
# Zugnetz
total_batch = int(zug.form[0]/batch_size)
für Epoche in Reichweite(Epochen):
avg_cost = 0
für mich in Reichweite(total_batch):
# Stapel erstellen
batch_x, Batch_y = Batch_Ersteller(batch_size)
# Übergeben Sie diese Charge für das Training
x, y = variabel(fackel.from_numpy(batch_x)), Variable(fackel.from_numpy(batch_y), require_grad=Falsch)
vorher = Modell(x)
# Verlust bekommen
Verlust = Verlust_fn(pred, Ja)
# Backpropagation durchführen
verlust.rückwärts()
Optimierer.Schritt()
avg_cost += loss.data[0]/total_batch
drucken(Epoche, avg_cost)
# Trainingsgenauigkeit erhalten x, y = variabel(fackel.from_numpy(Vorverarbeitung(train_x))), Variable(fackel.from_numpy(train_y), require_grad=Falsch) vorher = Modell(x) final_pred = np.argmax(pred.data.numpy(), Achse=1) Genauigkeit_Score(train_y, final_pred)
# Validierungsgenauigkeit erhalten x, y = variabel(fackel.from_numpy(Vorverarbeitung(val_x))), Variable(fackel.from_numpy(val_y), require_grad=Falsch) vorher = Modell(x) final_pred = np.argmax(pred.data.numpy(), Achse=1) Genauigkeit_Score(val_y, final_pred)
Die Trainingsnote ist:
0.8779008746355685
während der Validierungsscore ist:
0.867482993197279
Das ist eine beeindruckende Punktzahl!, vor allem, wenn wir ein sehr einfaches neuronales Netz nur für fünf Epochen trainiert haben!
Abschließende Anmerkungen
Ich hoffe, dieser Artikel hat Ihnen eine Vorstellung davon gegeben, wie das PyTorch-Framework die Perspektive des Aufbaus von Deep-Learning-Modellen verändern kann. In diesem Artikel, Wir haben nur an der Oberfläche gekratzt. Vertiefen, du kannst Lesen Sie die Dokumentation Ja Tutorials auf PyTorchs eigener offizieller Seite.
In den nächsten Artikeln, ich werde mich bewerben PyTorch für die Audioanalyse und wir werden versuchen, Deep-Learning-Modelle für die Sprachverarbeitung zu erstellen. Bleiben Sie dran!
Haben Sie PyTorch zum Erstellen einer Anwendung oder in einem Ihrer Data Science-Projekte verwendet?? Lass es mich in den Kommentaren unten wissen..





