Einführung
Menschen stellen ihr Sprachverständnis nicht jedes Mal neu, wenn wir einen Satz hören. Einen Beitrag gegeben, Wir erfassen den Kontext basierend auf unserem vorherigen Verständnis dieser Wörter. Eine der bestimmenden Eigenschaften, die wir haben, ist unser Gedächtnis (oder Haltekraft).
Kann ein Algorithmus das replizieren?? Die erste Technik, die mir in den Sinn kommt, ist ein neuronales Netzwerk (NN). Aber, leider, traditionelle NNs können das nicht. Nehmen Sie ein Beispiel für den Wunsch, vorherzusagen, was als nächstes in einem Video kommt. Ein traditionelles neuronales Netzwerk wird es schwer haben, genaue Ergebnisse zu erzielen.
Hier kommt das Konzept der rekurrenten neuronalen Netze ins Spiel. (RNN). RNNs sind im Deep-Learning-Bereich extrem beliebt geworden, was es noch dringender macht, sie zu lernen. Einige reale Anwendungen von RNN umfassen:
- Sprachakkreditierung
- Übersetzermaschine
- Musikalische Komposition
- Akkreditierung von Handschriften
- Grammatik lernen
 In diesem Beitrag, Wir werden zunächst kurz die Kernkomponenten eines typischen RNN-Modells überprüfen. Später werden wir die Deklaration des Problems konfigurieren, das wir abschließend lösen werden, indem wir ein RNN-Modell von Grund auf in Python implementieren.
In diesem Beitrag, Wir werden zunächst kurz die Kernkomponenten eines typischen RNN-Modells überprüfen. Später werden wir die Deklaration des Problems konfigurieren, das wir abschließend lösen werden, indem wir ein RNN-Modell von Grund auf in Python implementieren.
Wir können immer High-Level-Python-Bibliotheken nutzen, um ein RNN zu codieren. Dann, Warum von Grund auf neu codieren? Ich bin fest davon überzeugt, dass der beste Weg, ein Konzept zu lernen und wirklich zu verwurzeln, darin besteht, es von Grund auf neu zu lernen.. Und das zeige ich in diesem Tutorial.
Dieser Beitrag setzt ein grundlegendes Verständnis von rekurrenten neuronalen Netzen voraus. Falls Sie eine schnelle Auffrischung benötigen oder die Grundlagen von RNN erlernen möchten, Ich empfehle Ihnen, zuerst die folgenden Beiträge zu lesen:
Inhaltsverzeichnis
- Rückblende: eine Zusammenfassung wiederkehrender neuronaler Netzkonzepte
- Sequenzvorhersage mit RNN
- Erstellen eines RNN-Modells mit Python
Rückblende: eine Zusammenfassung wiederkehrender neuronaler Netzkonzepte
Lassen Sie uns kurz die Grundlagen hinter wiederkehrenden neuronalen Netzen zusammenfassen.
Wir werden dies anhand eines Beispiels von Sequenzdaten tun, sagen wir die Aktien eines bestimmten Unternehmens. Ein einfaches Modell für maschinelles Lernen, oder ein künstliches neuronales Netz, Sie können lernen, den Kurs von Aktien anhand einer Reihe von Merkmalen vorherzusagen, wie das Volumen der Aktien, der Blendenwert, etc. Abgesehen von diesen, der Preis hängt auch davon ab, wie sich die Aktie in den letzten Wochen und Fays entwickelt hat. Für einen Händler, Diese historischen Daten sind tatsächlich ein wichtiger Entscheidungsfaktor für Vorhersagen.
In herkömmlichen neuronalen Feedforward-Netzen, alle Testfälle werden als unabhängig betrachtet. Können Sie sehen, dass dies bei der Vorhersage von Aktienkursen nicht gut passt?? Das NN-Modell würde die oben genannten Aktienkurswerte nicht berücksichtigen, Keine tolle Idee!
Es gibt noch ein weiteres Konzept, auf das wir uns im Umgang mit zeitkritischen Daten verlassen können: wiederkehrende neuronale Netze (RNN).
Ein typisches RNN sieht so aus:

Das mag auf den ersten Blick einschüchternd wirken. Aber wenn wir es erst einmal entwickelt haben, die dinge sehen viel einfacher aus:
 Jetzt ist es für uns einfacher zu visualisieren, wie diese Netzwerke die Entwicklung der Aktienkurse berücksichtigen. Dies hilft uns, die Preise des Tages vorherzusagen. Hier, jede Vorhersage zum Zeitpunkt t (h_t) hängt von allen vorherigen Vorhersagen und den daraus gewonnenen Informationen ab. Ziemlich einfach, Wahrheit?
Jetzt ist es für uns einfacher zu visualisieren, wie diese Netzwerke die Entwicklung der Aktienkurse berücksichtigen. Dies hilft uns, die Preise des Tages vorherzusagen. Hier, jede Vorhersage zum Zeitpunkt t (h_t) hängt von allen vorherigen Vorhersagen und den daraus gewonnenen Informationen ab. Ziemlich einfach, Wahrheit?
RNNs können unseren Zweck der Sequenzbehandlung weitgehend lösen, aber nicht ganz.
Text ist ein weiteres gutes Beispiel für Sequenzdaten. In der Lage zu sein, vorherzusagen, welches Wort oder welcher Satz nach einem bestimmten Text steht, kann ein sehr nützlicher Vorteil sein.. Wir wollen unsere Modelle schreibe Shakespeare-Sonette!
Jetzt, Krankenschwestern sind ausgezeichnet, wenn es um einen kurzen oder kleinen Kontext geht. Aber in der Lage zu sein, eine Geschichte aufzubauen und sich daran zu erinnern, unsere Modelle müssen den Kontext hinter den Sequenzen verstehen können, wie ein menschliches Gehirn.
Sequenzvorhersage mit RNN
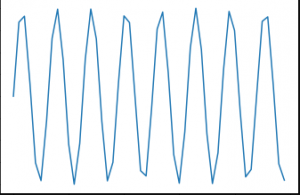
In diesem Beitrag, Wir arbeiten an einem Sequenzvorhersagehindernis mit RNN. Eine der einfachsten Aufgaben hierfür ist die Sinuswellenvorhersage. Die Sequenz enthält einen sichtbaren Trend und ist mithilfe von Heuristiken leicht zu korrigieren. So sieht eine Sinuswelle aus:
Wir werden zunächst ein wiederkehrendes neuronales Netz von Grund auf neu entwerfen, um dieses Problem zu lösen.. Unser RNN-Modell sollte auch gut verallgemeinerbar sein, damit wir es auf andere Sequenzprobleme anwenden können..
So formulieren wir unser Problem: gegeben eine Folge von 50 Zahlen, die zu einer Sinuswelle gehören, sagt die Zahl voraus 51 der Serie. Zeit, Ihren Jupyter-Laptop hochzufahren! (oder Ihre IDE Ihrer Wahl)!
RNN-Codierung mit Python
Paso 0: Datenaufbereitung
Ah, der unvermeidliche erste Schritt in jedem Data-Science-Projekt: Bereiten Sie die Daten vor, bevor Sie etwas anderes tun.
Wie erwartet unser Netzwerkmodell die Daten?? Ich würde eine Sequenz mit einer einzigen Länge akzeptieren 50 als Eingang. Dann, die Form der Eingabedaten ist:
(Anzahl_der_Datensätze x Länge_der_Sequenz x Typen_der_Sequenzen)
Hier, Typen_von_Sequenzen es 1, weil wir nur eine Art von Sequenz haben: la dann sinusförmig.
Außerdem, die Ausgabe hätte nur einen Wert für jeden Datensatz. Natürlich, das wird der Wert sein 51 in der Eingabereihenfolge. Dann wäre seine Form:
(Anzahl_von_Datensätzen x Typen_von_Sequenzen) #wobei type_of_sequences ist 1
Lass uns in den Code eintauchen. Zuerst, Importieren Sie unverzichtbare Bibliotheken:
%pylab im Einklang importieren Mathematik
So erstellen Sie eine Sinuswelle als Daten, Wir werden die Sinusfunktion von Python verwenden Mathematik Bücherei:
sin_wave = z.B.Array([Mathematik.ohne(x) zum x In z.B.arange(200)])
Visualisierung der Sinuswelle, die wir gerade erzeugt haben:
plt.Handlung(sin_wave[:50])

Die Daten werden wir jetzt im folgenden Codeblock erstellen:
x = [] Ja = [] seq_len = 50 Anzahl_Datensätze = len(sin_wave) - seq_len zum ich In Bereich(Anzahl_Datensätze - 50): x.anhängen(sin_wave[ich:ich+seq_len]) Ja.anhängen(sin_wave[ich+seq_len]) x = z.B.Array(x) x = z.B.expand_dims(x, Achse=2) Ja = z.B.Array(Ja) Ja = z.B.expand_dims(Ja, Achse=1)
Drucken Sie das Datenformular aus:
Beachten Sie, dass wir eine Schleife für gemacht haben (Anzahl_Datensätze – 50) weil wir reservieren wollen 50 Aufzeichnungen wie unsere Validierungsdaten. Wir können diese Validierungsdaten jetzt erstellen:
X_val = [] Y_val = [] zum ich In Bereich(Anzahl_Datensätze - 50, Anzahl_Datensätze): X_val.anhängen(sin_wave[ich:ich+seq_len]) Y_val.anhängen(sin_wave[ich+seq_len]) X_val = z.B.Array(X_val) X_val = z.B.expand_dims(X_val, Achse=2) Y_val = z.B.Array(Y_val) Y_val = z.B.expand_dims(Y_val, Achse=1)
Paso 1: Erstellen Sie die Architektur für unser RNN-Modell
Unsere nächste Aufgabe besteht darin, alle unverzichtbaren Variablen und Funktionen zu ermitteln, die wir im RNN-Modell verwenden werden.. Unser Modell nimmt die Eingabesequenz, wird es durch eine versteckte Schicht von verarbeiten 100 Einheiten und erzeugt eine Einzelwertausgabe:
Lernrate = 0.0001 nepoche = 25 T = 50 # Länge der Sequenz versteckt_dim = 100 output_dim = 1 bptt_truncate = 5 min_clip_value = -10 max_clip_value = 10
Später werden wir die Gewichte des Netzwerks definieren:
U = z.B.willkürlich.Uniform(0, 1, (versteckt_dim, T)) W = z.B.willkürlich.Uniform(0, 1, (versteckt_dim, versteckt_dim)) V = z.B.willkürlich.Uniform(0, 1, (output_dim, versteckt_dim))
Hier,
- U ist die Gewichtungsmatrix für die Gewichte zwischen Input- und Hidden-Layer
- V ist die Gewichtungsmatrix für Gewichtungen zwischen versteckten und Ausgabeschichten
- W ist die Gewichtsmatrix für gemeinsame Gewichte in der RNN-Schicht (versteckte Schicht)
Zusammenfassend, wir werden die Aktivierungsfunktion definieren, sigmoidea, in der versteckten Schicht zu verwenden:
def sigmoid(x): Rückkehr 1 / (1 + z.B.exp(-x))
Paso 2: trainiere das Modell
Nachdem wir unser Modell definiert haben, Abschließend können wir mit dem Training an unseren Sequenzdaten fortfahren. Wir können den Schulungsablauf in kleinere Schritte unterteilen, nämlich:
Paso 2.1: Auf Verlust von Trainingsdaten prüfen
Paso 2.1.1: Weitergeben
Paso 2.1.2: Berechnen Sie den Fehler
Paso 2.2: Auf Validierungsdatenverlust prüfen
Paso 2.2.1: Weitergeben
Paso 2.2.2: Berechnen Sie den Fehler
Paso 2.3: Starten Sie das eigentliche Training
Paso 2.3.1: Weitergeben
Paso 2.3.2: Backpropagation-Fehler
Paso 2.3.3: Aktualisieren Sie die Gewichte
Wir müssen diese Schritte bis zur Konvergenz wiederholen. Wenn das Modell zu überanpassen beginnt, Halt! Oder einfach die Anzahl der Epochen voreinstellen.
Paso 2.1: Auf Verlust von Trainingsdaten prüfen
Wir machen einen Vorwärtsdurchlauf durch unser RNN-Modell und berechnen den quadrierten Fehler der Vorhersagen für alle Datensätze, um den Verlustwert zu erhalten.
zum Epoche In Bereich(nepoche): # Verlust im Zug prüfen Verlust = 0.0 # Mache einen Vorwärtspass, um eine Vorhersage zu erhalten zum ich In Bereich(Ja.Form[0]): x, Ja = x[ich], Ja[ich] # Eingabe erhalten, Ausgabewerte jedes Datensatzes prev_s = z.B.Nullen((versteckt_dim, 1)) # Hier, prev-s ist der Wert der vorherigen Aktivierung von Hidden Layer; die als alle Nullen initialisiert wird zum T In Bereich(T): neuer_input = z.B.Nullen(x.Form) # Wir machen dann einen Vorwärtspass für jeden Zeitschritt in der Sequenz neuer_input[T] = x[T] # dafür, wir erstellen eine einzelne Eingabe für diesen Zeitschritt mulu = z.B.Punkt(U, neuer_input) mulw = z.B.Punkt(W, prev_s) hinzufügen = mulw + mulu S = sigmoid(hinzufügen) mulv = z.B.Punkt(V, S) prev_s = S # Fehler berechnen loss_per_record = (Ja - mulv)**2 / 2 Verlust += loss_per_record Verlust = Verlust / schweben(Ja.Form[0])
Paso 2.2: Auf Validierungsdatenverlust prüfen
Wir werden dasselbe tun, um den Verlust in den Validierungsdaten zu berechnen (im gleichen zyklus):
# Wertverlust prüfen Wertverlust = 0.0 zum ich In Bereich(Y_val.Form[0]): x, Ja = X_val[ich], Y_val[ich] prev_s = z.B.Nullen((versteckt_dim, 1)) zum T In Bereich(T): neuer_input = z.B.Nullen(x.Form) neuer_input[T] = x[T] mulu = z.B.Punkt(U, neuer_input) mulw = z.B.Punkt(W, prev_s) hinzufügen = mulw + mulu S = sigmoid(hinzufügen) mulv = z.B.Punkt(V, S) prev_s = S loss_per_record = (Ja - mulv)**2 / 2 Wertverlust += loss_per_record Wertverlust = Wertverlust / schweben(Ja.Form[0]) drucken('Epoche: ', Epoche + 1, ', Verlust: ', Verlust, ', Val Loss: ', Wertverlust)
Sie sollten das folgende Ergebnis erhalten:
Epoche: 1 , Verlust: [[101185.61756671]] , Val Loss: [[50591.0340148]] ... ...
Paso 2.3: Starten Sie das eigentliche Training
Jetzt starten wir mit dem eigentlichen Training des Netzwerks. In diesem, Zuerst werden wir einen Vorwärtsdurchlauf machen, um die Fehler zu berechnen und einen Rückwärtsdurchlauf, um die Gradienten zu berechnen und sie zu aktualisieren. Lass mich dir diese Schritt für Schritt zeigen, damit du dir vorstellen kannst, wie es in deinem Kopf funktioniert.
Paso 2.3.1: Weitergeben
Im Vorverkaufspass:
- Zuerst multiplizieren wir die Eingabe mit den Gewichten zwischen der Eingabe und den versteckten Schichten.
- Addiere dies mit Multiplikationsgewichten in der RNN-Schicht. Dies liegt daran, dass wir das Wissen des vorherigen Zeitschritts erfassen möchten.
- Führen Sie es durch eine Sigmoid-Aktivierungsfunktion.
- Multiplizieren Sie dies mit den Gewichten zwischen den versteckten und den Ausgabeschichten.
- Auf der Ausgabeschicht, wir haben eine lineare Aktivierung der Werte, also übergeben wir den Wert nicht explizit durch eine Triggerebene.
- Speichern Sie den Zustand im aktuellen Layer und auch den Zustand im vorherigen Zeitschritt in einem Wörterbuch
Hier ist der Code, um einen Vorwärtspass durchzuführen (Beachten Sie, dass es eine Fortsetzung des vorherigen Zyklus ist):
# Zugmodell zum ich In Bereich(Ja.Form[0]): x, Ja = x[ich], Ja[ich] Schichten = [] prev_s = z.B.Nullen((versteckt_dim, 1)) von = z.B.Nullen(U.Form) dV = z.B.Nullen(V.Form) dW = z.B.Nullen(W.Form) dU_t = z.B.Nullen(U.Form) dV_t = z.B.Nullen(V.Form) dW_t = z.B.Nullen(W.Form) dU_i = z.B.Nullen(U.Form) dW_i = z.B.Nullen(W.Form) # Vorwärtspass zum T In Bereich(T): neuer_input = z.B.Nullen(x.Form) neuer_input[T] = x[T] mulu = z.B.Punkt(U, neuer_input) mulw = z.B.Punkt(W, prev_s) hinzufügen = mulw + mulu S = sigmoid(hinzufügen) mulv = z.B.Punkt(V, S) Schichten.anhängen({'S':S, 'vorher_s':prev_s}) prev_s = S
Paso 2.3.2: Backpropagation-Fehler
Nach dem Vorwärtsausbreitungsschritt, wir berechnen die Gradienten in jeder Schicht und propagieren die Fehler zurück. Wir werden die verkürzte Rückausbreitung durch die Zeit verwenden (TBPTT), statt Vanille zurückvermehren. Es mag komplex erscheinen, aber eigentlich ist es ganz einfach.
Der zentrale Unterschied zwischen BPTT und Backprop besteht darin, dass der Backpropagation-Schritt für alle Zeitschritte in der RNN-Schicht durchgeführt wird. Dann, wenn die Länge unserer Folge ist 50, wir werden alle Zeitschritte vor dem aktuellen Zeitschritt zurückpropagieren.
Wenn du richtig geraten hast, BPTT scheint sehr rechenintensiv zu sein. Dann, anstatt sich rückwärts durch alle vorherigen Zeitschritte zu propagieren, wir propagieren bis zu x Zeitschritte zurück, um Rechenleistung zu sparen. Betrachten Sie dies ideologisch ähnlich dem stochastischen Gradientenabstieg, wobei wir einen Stapel von Datenpunkten anstelle aller Datenpunkte einschließen.
Hier ist der Code, um die Fehler rückwärts zu verbreiten:
# Ableitung von pred dmulv = (mulv - Ja) # Rückwärtspass zum T In Bereich(T): dV_t = z.B.Punkt(dmulv, z.B.transponieren(Schichten[T]['S'])) dsv = z.B.Punkt(z.B.transponieren(V), dmulv) ds = dsv Papa = hinzufügen * (1 - hinzufügen) * ds dmulw = Papa * z.B.ones_like(mulw) dprev_s = z.B.Punkt(z.B.transponieren(W), dmulw) zum ich In Bereich(T-1, max(-1, T-bptt_truncate-1), -1): ds = dsv + dprev_s Papa = hinzufügen * (1 - hinzufügen) * ds dmulw = Papa * z.B.ones_like(mulw) dmulu = Papa * z.B.ones_like(mulu) dW_i = z.B.Punkt(W, Schichten[T]['vorher_s']) dprev_s = z.B.Punkt(z.B.transponieren(W), dmulw) neuer_input = z.B.Nullen(x.Form) neuer_input[T] = x[T] dU_i = z.B.Punkt(U, neuer_input) dx = z.B.Punkt(z.B.transponieren(U), dmulu) dU_t += dU_i dW_t += dW_i dV += dV_t von += dU_t dW += dW_t
Paso 2.3.3: Aktualisieren Sie die Gewichte
Schließlich, wir aktualisieren die Gewichte mit den Gradienten der berechneten Gewichte. Eine Sache, auf die wir achten müssen, ist, dass Gradienten dazu neigen, zu explodieren, wenn Sie sie nicht unter Kontrolle halten.. Dies ist ein grundlegendes Thema beim Training neuronaler Netze., nennt man das explosive Gradientenproblem. Deshalb müssen wir sie in Reichweite halten, damit sie nicht explodieren. Wir können es so machen
Wenn von.max() > max_clip_value: von[von > max_clip_value] = max_clip_value Wenn dV.max() > max_clip_value: dV[dV > max_clip_value] = max_clip_value Wenn dW.max() > max_clip_value: dW[dW > max_clip_value] = max_clip_value Wenn von.Mindest() < min_clip_value: von[von < min_clip_value] = min_clip_value Wenn dV.Mindest() < min_clip_value: dV[dV < min_clip_value] = min_clip_value Wenn dW.Mindest() < min_clip_value: dW[dW < min_clip_value] = min_clip_value # aktualisieren U -= Lernrate * von V -= Lernrate * dV W -= Lernrate * dW
Beim Training des Vorgängermodells, wir bekommen dieses ergebnis:
Epoche: 1 , Verlust: [[101185.61756671]] , Val Loss: [[50591.0340148]] Epoche: 2 , Verlust: [[61205.46869629]] , Val Loss: [[30601.34535365]] Epoche: 3 , Verlust: [[31225.3198258]] , Val Loss: [[15611.65669247]] Epoche: 4 , Verlust: [[11245.17049551]] , Val Loss: [[5621.96780111]] Epoche: 5 , Verlust: [[1264.5157739]] , Val Loss: [[632.02563908]] Epoche: 6 , Verlust: [[20.15654115]] , Val Loss: [[10.05477285]] Epoche: 7 , Verlust: [[17.13622839]] , Val Loss: [[8.55190426]] Epoche: 8 , Verlust: [[17.38870495]] , Val Loss: [[8.68196484]] Epoche: 9 , Verlust: [[17.181681]] , Val Loss: [[8.57837827]] Epoche: 10 , Verlust: [[17.31275313]] , Val Loss: [[8.64199652]] Epoche: 11 , Verlust: [[17.12960034]] , Val Loss: [[8.54768294]] Epoche: 12 , Verlust: [[17.09020065]] , Val Loss: [[8.52993502]] Epoche: 13 , Verlust: [[17.17370113]] , Val Loss: [[8.57517454]] Epoche: 14 , Verlust: [[17.04906914]] , Val Loss: [[8.50658127]] Epoche: 15 , Verlust: [[16.96420184]] , Val Loss: [[8.46794248]] Epoche: 16 , Verlust: [[17.017519]] , Val Loss: [[8.49241316]] Epoche: 17 , Verlust: [[16.94199493]] , Val Loss: [[8.45748739]] Epoche: 18 , Verlust: [[16.99796892]] , Val Loss: [[8.48242177]] Epoche: 19 , Verlust: [[17.24817035]] , Val Loss: [[8.6126231]] Epoche: 20 , Verlust: [[17.00844599]] , Val Loss: [[8.48682234]] Epoche: 21 , Verlust: [[17.03943262]] , Val Loss: [[8.50437328]] Epoche: 22 , Verlust: [[17.01417255]] , Val Loss: [[8.49409597]] Epoche: 23 , Verlust: [[17.20918888]] , Val Loss: [[8.5854792]] Epoche: 24 , Verlust: [[16.92068017]] , Val Loss: [[8.44794633]] Epoche: 25 , Verlust: [[16.76856238]] , Val Loss: [[8.37295808]]
Gut aussehen! Zeit, die Vorhersagen zu erhalten und sie zu zeichnen, um eine visuelle Vorstellung davon zu bekommen, was wir entworfen haben.
Paso 3: Vorhersagen erhalten
Wir werden einen Vorwärtsdurchlauf durch die trainierten Gewichte machen, um unsere Vorhersagen zu erhalten:
Preds = [] zum ich In Bereich(Ja.Form[0]): x, Ja = x[ich], Ja[ich] prev_s = z.B.Nullen((versteckt_dim, 1)) # Vorwärtspass zum T In Bereich(T): mulu = z.B.Punkt(U, x) mulw = z.B.Punkt(W, prev_s) hinzufügen = mulw + mulu S = sigmoid(hinzufügen) mulv = z.B.Punkt(V, S) prev_s = S Preds.anhängen(mulv) Preds = z.B.Array(Preds)
Diese Vorhersagen zusammen mit den tatsächlichen Werten grafisch darstellen:
plt.Handlung(Preds[:, 0, 0], 'g') plt.Handlung(Ja[:, 0], 'R') plt.zeigen()

Das stand in den Trainingsdaten. Woher wissen wir, ob unser Modell nicht zu eng war? Hier kommt das Validierungsset ins Spiel., die wir zuvor erstellt haben:
Preds = [] zum ich In Bereich(Y_val.Form[0]): x, Ja = X_val[ich], Y_val[ich] prev_s = z.B.Nullen((versteckt_dim, 1)) # Für jeden Zeitschritt... zum T In Bereich(T): mulu = z.B.Punkt(U, x) mulw = z.B.Punkt(W, prev_s) hinzufügen = mulw + mulu S = sigmoid(hinzufügen) mulv = z.B.Punkt(V, S) prev_s = S Preds.anhängen(mulv) Preds = z.B.Array(Preds) plt.Handlung(Preds[:, 0, 0], 'g') plt.Handlung(Y_val[:, 0], 'R') plt.zeigen()

Nichts Schlechtes. Die Vorhersagen scheinen beeindruckend. Auch der RMSE-Score in den Validierungsdaten ist respektabel:
von sklearn.metrics importieren mittlere quadratische Fehler Mathematik.sqrt(mittlere quadratische Fehler(Y_val[:, 0] * max_val, Preds[:, 0, 0] * max_val))
0.127191931509431
Abschließende Anmerkungen
Ich kann nicht genug betonen, wie nützlich RNNs bei der Arbeit mit Sequenzdaten sind. Ich flehe alle an, diese Erkenntnisse zu übernehmen und auf einen Datensatz anzuwenden. Nehmen Sie eine NLP-Hürde und sehen Sie, ob Sie eine Lösung finden können. Du kannst mich jederzeit im Kommentarbereich unten erreichen, wenn du Fragen hast.
In diesem Beitrag, Wir haben gelernt, wie man mit der numpy-Bibliothek ein wiederkehrendes neuronales Netzwerkmodell von Grund auf neu erstellt. Natürlich, Sie können eine High-Level-Bibliothek wie Keras oder Caffe verwenden, Aber es ist wichtig, das Konzept zu kennen, das Sie implementieren.
Teile deine Gedanken, Fragen und Kommentare zu diesem Beitrag unten. Viel Spaß beim Lernen!





