Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
Dieser Artikel zielt darauf ab, die Monte-Carlo-Simulation für die Analyse variabler Unsicherheiten vorzustellen. Monte Carlo kann die Fehlerausbreitung ersetzen, da sie die Nachteile der Fehlerweitergabe überwindet. Diskutieren:
- So verbreiten Sie den Fehler;
- Warum Monte Carlo anstelle der Fehlerweitergabe?? Ja
- Die Schritte, um die Unsicherheit von Monte Carlo zu realisieren.
Beginnen wir diese Diskussion mit einfachen Dingen. Wie viel gibt ein City A-Mitarbeiter in einem Monat für Lebenshaltungskosten aus?? Es gibt Tausende von Mitarbeitern in Stadt A mit unterschiedlichen Lebenshaltungskosten. Um die vorherige Frage zu beantworten, Wir müssen mehrere Mitarbeiter befragen und ihre Antworten aufzeichnen. Diese Mitarbeiter werden anders reagieren.. Ihre Lebenshaltungskosten variieren in einer Wahrscheinlichkeitsverteilung. Obwohl wir nicht die Ressourcen haben, jeden Mitarbeiter zu fragen, Wir können eine Gruppe von, zum Beispiel, 50 Mitarbeiter für die Befragung zur Darstellung der Bevölkerung.
Aber trotzdem, Wir brauchen noch eine Zahl, um die gesamten Lebenshaltungsausgaben darzustellen. Nehmen wir an, wir bekommen, dass die durchschnittlichen monatlichen Lebenshaltungskosten $ 2000. Oder, Eine andere Möglichkeit besteht darin, den Median zur Darstellung der Gesamtausgaben zu verwenden.. Um andere mögliche Lebenshaltungskosten auszudrücken, Wir können Standardabweichungen verwenden. Zum Beispiel, Die monatlichen Lebenshaltungskosten in Stadt A betragen $ 2000 ± 500 (Durchschnittliche ± Standardabweichung).
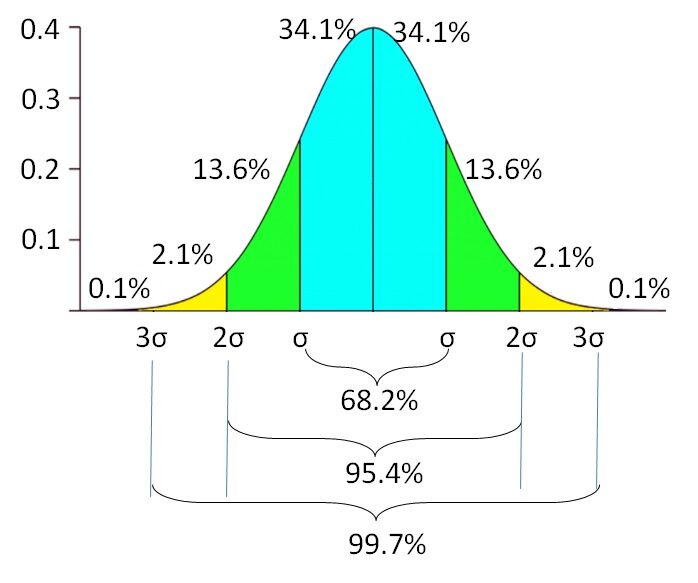
Es bedeutet, dass, wenn die Daten normal verteilt sind, das 68,2% der Mitarbeiter verbringen zwischen $ 1500 Ja $ 2500. Es gibt noch eine 31,8% der Mitarbeiter, die weniger als $ 1500 und mehr als $ 2500 in monatlichen Lebenshaltungskosten. Die Wahrscheinlichkeit der Lebensaufwendung sinkt, wenn sie sich vom Durchschnitt entfernt. Es besteht eine Wahrscheinlichkeit von 0,1% um Mitarbeiter zu finden, deren Lebenshaltungskosten unter dem $ 500 oder größer als $ 3500. Standardabweichung spiegelt variable Unsicherheit der Lebenshaltungsausgaben wider. Gibt die untere und obere Ausdehnung der Variablen an, Anstatt sich auf einen einzigen Wert zu verlassen.
Fehlerausbreitung
Da Stadt A Arbeitnehmer Einkommen haben: $ 3200 ± 2000, Lebenshaltungskosten: $ 2000 ± 500, Kredit: $ 180 ± 130, unerwartete Einnahmen oder Ausgaben: $ 20 ± 300 und Bankzinssatz: 0,85 ± 0,35% monatlich. Wir wollen berechnen, wie viel ein Mitarbeiter in einem Monat sparen kann. Die Gleichung wird unten ausgedrückt:
Ersparnis = (Einkommen – Gastos_ des Lebens – Kredit + Einkommen / Unerwartete Ausgaben) × (1 + Interessen)
Monatliche Einsparungen werden als Gesamteinkommen berechnet, das von den Lebenshaltungskosten und Krediten abgezogen und zu unerwarteten Einnahmen oder Ausgaben addiert wird.. Nach einem Monat, Nominaler Sparzuwachs durch Bankzinsen. Wir berechnen die durchschnittlichen monatlichen Einsparungen und Unsicherheiten. Beachten Sie die folgende Gleichung zur Berechnung der Unsicherheit.
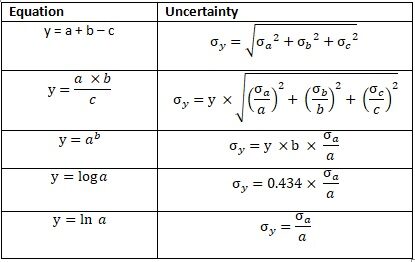
Abb.2 Fehlerausbreitung
Speichern1 = ((3200 ± 2000) - (2000 ± 500) - (180 ± 130) + (20 ± 300)) × (1 + (0.0085 ± 0.0035)) Speichern1 = 1040 ± σSaving_1
σSaving_1 = ((20002 + 5002 + 1302 + 20002))0.5 σSaving_1 = 2087
Speichern1 ± σSaving_1 = 1040 ± 2087
Diese berechnet die monatliche Ersparnis nach Berücksichtigung der Bankzinsen..
Speichern = Speichern1 × (1 + (0.0085 ± 0.0035)) Sparen = (1040 ± 2087) × (1.0085 ± 0.0035) Sparen = 1049 ± σSaving_2
σErsparnis = 1049 × ((2087/1040)2 + (0.0035/1.0085)2)0.5 σErsparnis = 1049 × 2.01 σErsparnis = 2105
Einsparungen ± σErsparnis = 1049 ± 2105
Aus dem Ergebnis, wir können das sehen, im Durchschnitt, Menschen können sparen $ 1049 in einem Monat mit der Unsicherheit von $ 2105. Die untere Grenze der monatlichen Ersparnisse ist – $ 1056 ($ 1049 – $ 2105), was ein negativer Wert ist. Die Unsicherheit selbst ist 2105, Was ist es 2 mal größer als der Durchschnittswert. Wenn wir die Grafik visualisieren, Wir können sehen, dass die Mitarbeitereinsparungen von – $ 6000 Ja $ 8000. Es mutet seltsam an, weil die Unter- und Obergrenze fast ausbalanciert sind.. ich denke, dass, in Wirklichkeit, Die Höhe der Einsparungen sollte stärker schwanken als die Höhe des Defizits..
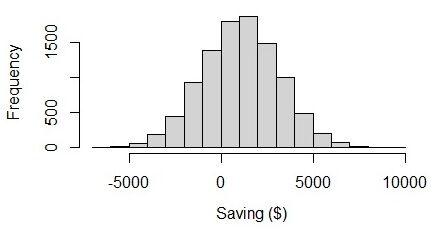
Abb.3 Visualisierung der Einsparungen in einer Normalverteilung
Wie kommt das?? Das Problem liegt in den Umsatzdaten. Das Einkommen von $ 3200 ± 2000 hat eine hohe Unsicherheit aufgrund von Einkommensschwankungen. Die Unsicherheit beträgt mehr als ein Drittel des Durchschnittswertes. Wenn wir annehmen, dass dies eine Normalverteilung ist, Wir werden sehen, dass die 4.8% der Bevölkerung hat Einkommen unter 0, Was nicht wahrscheinlich ist, dass es passiert. Eigentlich, Einkommen muss immer über % liegen 0. Dieses Problem tritt auf, wenn wir davon ausgehen, dass alle Variablen normalverteilt sind., Aber in Wirklichkeit sind sie es nicht..
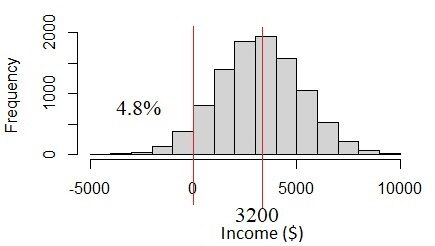
Abb.4 Normalverteilung, wenn die Standardabweichung des Einkommens zu groß ist
Monte-Carlo-Simulation
Was ist die Lösung?? Eine weitere Möglichkeit, die Unsicherheit zu bewerten, ist die Anwendung der Monte-Carlo-Simulation. Monte Carlo ist ursprünglich der Name eines Verwaltungsgebiets in Monaco. Aber das Monte Carlo unserer heutigen Diskussion ist statistisches Material.. Monte Carlo kann den Nachteil der Fehlerausbreitung überwinden. Die Monte-Carlo-Simulation, im Gegensatz zur Fehlerweitergabe, Kann mit einer anderen Datenverteilung als der Normalverteilung und mit Daten mit einer großen Standardabweichung arbeiten.

Abb.5 Monte Carlo in Monaco. Quelle: Google Karte
Die Monte-Carlo-Simulation simuliert oder generiert eine Reihe von Zufallszahlen entsprechend der Datenverteilung und den Parametern jeder Variablen. Einmal generiert, Alle Variablenwerte werden mit Hilfe der Gleichung. Das klingt etwas komplizierter als die Verwendung der Fehlerweitergabe.. Aber mit Data-Science-Tools, wie Python oder R, wird sehr einfach sein. In dieser Diskussion, wir werden die Verwendung der statistischen Sprache R demonstrieren.
Schritte zum Durchführen einer Monte-Carlo-Simulation
1. Überprüfen Sie die Wahrscheinlichkeitsdichtefunktion der Datenverteilung.
Nehmen wir an, wir untersuchen den Datensatz, der von der 50 befragt. Es gibt viele Arten von Wahrscheinlichkeitsdichtefunktionen und wir müssen bestimmen, welche zu unseren Daten passt.. Variablen mit Normalverteilung sind nur Lebenshaltungskosten und unerwartete Einnahmen oder Ausgaben. Die Verteilung der Umsatzdaten ist positiv.
In diesem Fall, Wir werden es als Gamma-Verteilung behandeln. Aus diesem Grund sind Mittelwert und Fehlerausbreitung für diese Daten nicht geeignet.. Die anderen beiden Variablen haben ebenfalls keine Normalverteilung. Der Bankzinssatz verteilt sich gleichmäßig auf 0,3 Ja 1,5.
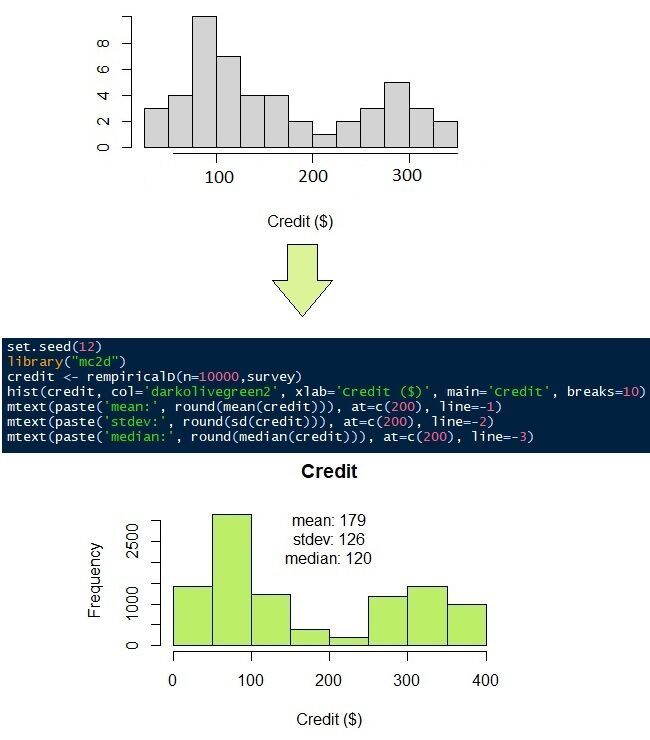
Die Verteilung der Kreditdaten zur Rückzahlung von Krediten ist ziemlich einzigartig. Die Daten verteilen sich hauptsächlich auf zwei Bevölkerungsgruppen. Die erste Gruppe hat weniger Kredit als die zweite. Nehmen wir an, die Verteilung von Kreditdaten passt zu keiner Wahrscheinlichkeitsdichtefunktion. Später, Wir verwenden eine nichtparametrische Verteilung.
2. Monte-Carlo-Simulation generieren
Das Generieren einer Monte-Carlo-Simulation bedeutet, einen Satz von Zufallszahlen mit der gleichen Datenverteilung wie die Originaldaten zu generieren.. Um dies zu tun, Wir stellen einfach die Anzahl der Simulationen und Verteilungsparameter entsprechend der Art der Verteilung ein. Wir setzen die Anzahl der Simulationen in 10,000. Es bedeutet, dass wir die Daten von 50 Befragte in 10,000 Daten.
Die Parameter der Normalverteilung sind Mittelwert / Mittelwert und Standardabweichung. Wir wissen, dass Durchschnitts- ± Standardabweichungen der Lebenshaltungskosten und unerwartete Einnahmen oder Ergebnisse 2000 ± 500 Ja 20 ± 300 beziehungsweise. Jetzt, Wir können die Distributionen generieren. In diesem Artikel, Ich werde die Sprache R verwenden. Natürlich, Andere Data Science-Sprachen, als Python, Sie können es auch.. Sehen Sie, dass simulierte Daten einen ähnlichen Mittelwert und Standard haben, nicht gleich, als die Eingabeparameter.
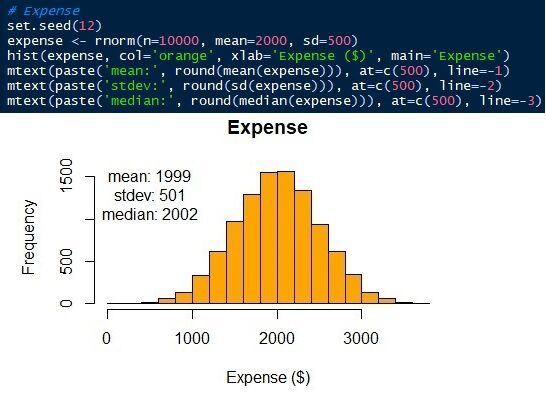
Abb.6 Normalverteilung der Lebenshaltungsausgaben
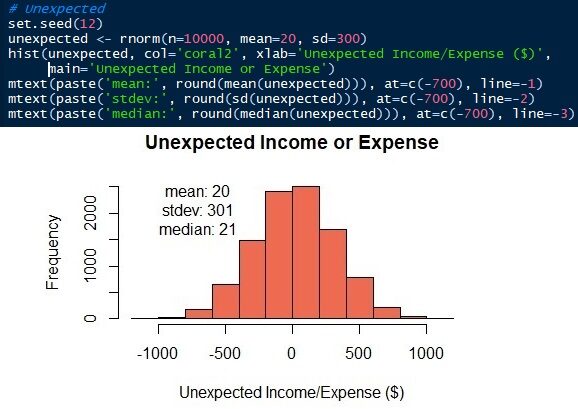
Abb.7 Normalverteilung unerwarteter Einnahmen oder Ausgaben
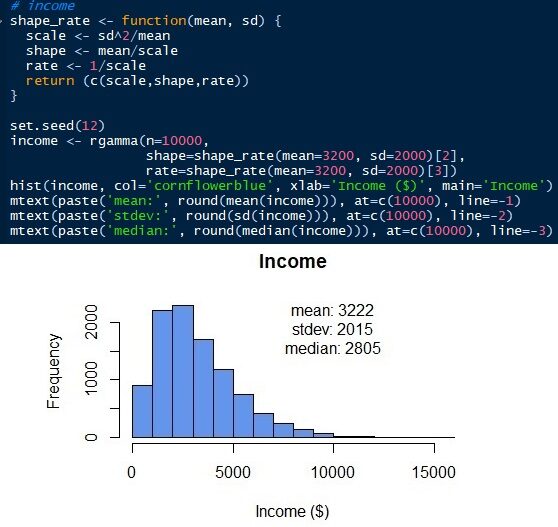
So generieren Sie die Gammaverteilung, Wir müssen andere Parameter kennen. Im Gegensatz zur Normalverteilung, Die Gammaverteilung hat eine Skalierung, Form und Geschwindigkeit als Parameter. Aber wir können diese Parameter mit der Standardabweichung und dem Mittelwert erhalten. (von). Skala = sd2/meinen. Form = Mittelwert / Skala. Preis = 1 / Skala. Später, Wir können die Gamma-Verteilung des Arbeitnehmereinkommens wie unten gezeigt simulieren. Die Gammaverteilung kann nur positive Werte haben. Es gibt keinen Wert darunter 0 da das Einkommen aller Arbeitnehmer eine positive Zahl sein muss. Die Normalverteilung würde negative Werte ergeben, wenn der Standardfehler zu groß ist. Sehen Sie, dass die simulierte Verteilung einen Mittelwert und eine Standardabweichung von 3222 Ja 2015 beziehungsweise, die nahe an den ursprünglichen Eingabeparametern liegen. Aber wir haben einen Median von 2805. Der Median der Gammaverteilung, Im Gegensatz zur Normalverteilung, ist weit vom Durchschnitt entfernt.
Das Guthaben, das monatlich zu zahlen ist, wie bereits erwähnt, hat keine ausreichende Wahrscheinlichkeitsdichtefunktion. Werfen Sie einen Blick auf die Antworten von 50 Umfragen in Abbildung 9 (Graues Histogramm). Es scheint, dass die meisten Menschen ihren Kredit für $ 100 Ja $ 300. So simulieren Sie die 50 Beobachtungen in 10,000 Beobachtungen, Wir können eine nichtparametrische Verteilung verwenden. Wie der Name schon sagt, Nichtparametrische Verteilung erfordert keine Parameter, als Durchschnitt, die Standardabweichung, das Formular oder die Rate, ebenso wie die Normal- und Gammaverteilung. Benötigt nur die Originaldaten.
Die letzte zu simulierende Variable ist der Bankzinssatz. Der Bankzinssatz variiert von 0,3 ein 1,5 gleichmäßig. Wir simulieren 10,000 Beobachtungen von 0.3 ein 1.5 mit gleicher Wahrscheinlichkeit.
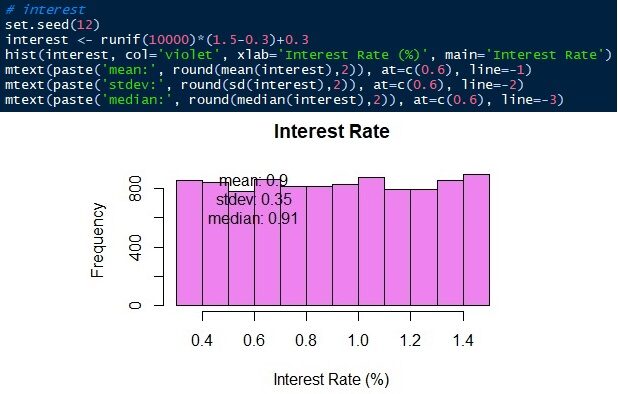
3. Kombination von Monte-Carlo-Simulationen
Der letzte Schritt besteht darin, die Monte-Carlo-Simulationen anhand der Gleichung zu kombinieren, um die monatlichen Einsparungen zu berechnen.. Um dies zu tun, Wir müssen nur alle Simulationen in einer Tabelle zusammenfassen. Später, Wir können berechnen 10,000 Monatliche Sparreihen. Das Ergebnis ist $ 1073 ± 2052, Nicht unähnlich der Fehlerausbreitung. Aber, Monte-Carlo-Simulation zeigt Wahrscheinlichkeitsdichte. Wir können sehen, dass die mittleren Einsparungen $ 666 und die Daten reichen von $ 2000 Ja 10000.

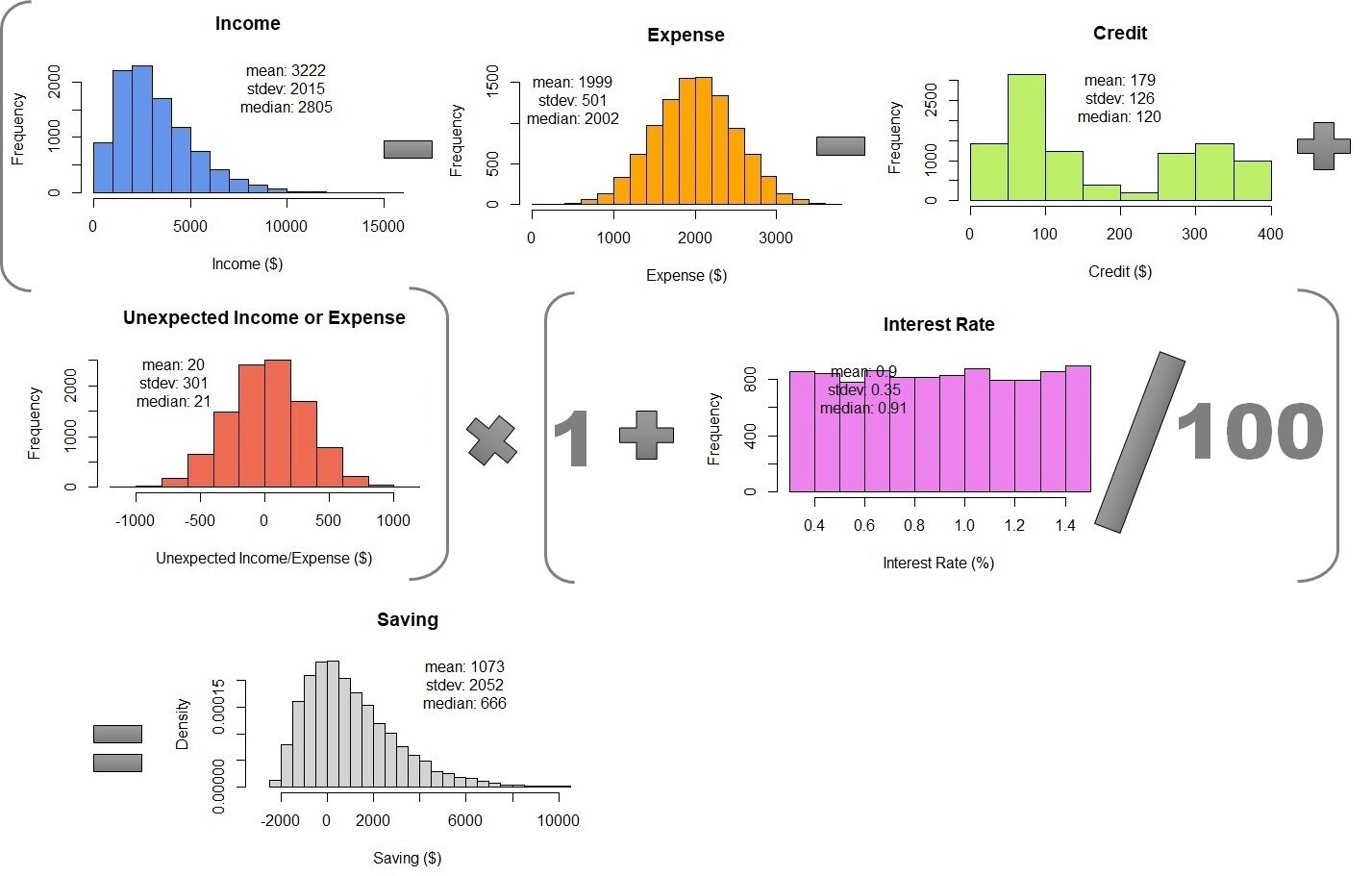
Tisch 1 – Kombination von Monte-Carlo-Simulationen
Jetzt, Schauen wir uns ein weiteres Beispiel mit räumlicher und zeitlicher Variabilität an. Die Aufgabe besteht darin, den Oberflächenabfluss eines Beckens zu berechnen. Das Einzugsgebiet ist die Grenze der Oberflächenwasserhydrologie. Jeder Regen, der unter das Becken fällt, wird nicht außerhalb der Grenze liegen.. Ein Teil des Regens infiltriert den Boden entsprechend der Größe der Bodenpartikel und der Art der Bodenbedeckung.. Wasser, das nicht in den Boden eindringt, wird als Oberflächenabfluss bezeichnet.. Oberflächenabfluss fließt als Abfluss aus dem Fluss in den Fluss.
Die folgende Tabelle zeigt die monatliche Niederschlagsintensität in einem Jahr und den Abflusskoeffizienten in einem 1,5 km.2 Becken. Unsicherheit kann auf räumliche und zeitliche Heterogenität zurückzuführen sein. Der Niederschlags- und Abflusskoeffizient (aufgrund der Boden- und Bodenbedeckungsart) variiert räumlich im Becken. Der Niederschlag des Beckens wird mit mehreren Regenmessern gemessen. Sie ergeben durchschnittliche Niederschläge mit Unsicherheit aufgrund der räumlichen Verteilung. Die Verteilung der Bodenbedeckung ergibt auch die Unsicherheit des Abflusskoeffizienten.
Ein Abflusskoeffizient ist der Anteil des Regens, der nicht in den Boden eindringt und zum Oberflächenabfluss wird.. Wald- oder Grobbodentyp hat einen niedrigen Abflusskoeffizienten. Siedlungen oder Häuser haben einen hohen Abflusskoeffizienten. Die Umwandlung von Waldflächen in Siedlungen erhöht den Abflusskoeffizienten, da ein höherer Anteil des Regenwassers Oberflächenabfluss sein wird.
Zeitliche Variabilität tritt auch auf, weil die Niederschläge in der Regen- und Trockenzeit unterschiedlich sind.. Die Veränderung der Bodenbedeckung im Laufe der Zeit verursacht auch die zeitliche Variabilität des Abflusskoeffizienten.. Weitere Unsicherheitsquellen sind die Qualität der Messinstrumente, Messverfahren, Umwelt- und andere ungeklärte Bedingungen aufgrund mangelnden Wissens.
| Mein | Niederschlag (mm / mein) | Abflusskoeffizient | Bereich (km2) |
| Johanna | 320 ± 37 | 0,3 ± 0,2 | 1,5 |
| Feb | 350 ± 59 | 0,3 ± 0,2 | 1,5 |
| Meer | 205 ± 26 | 0,4 ± 0,1 | 1,5 |
| April | 170 ± 41 | 0,4 ± 0,1 | 1,5 |
| Mai | 106 ± 48 | 0,4 ± 0,1 | 1,5 |
| Juni | 91 ± 32 | 0,4 ± 0,1 | 1,5 |
| Jul | 77 ± 16 | 0,4 ± 0,1 | 1,5 |
| August | 52 ± 15 | 0,7 ± 0,2 | 1,5 |
| sep | 100 ± 50 | 0,7 ± 0,2 | 1,5 |
| Okt | 120 ± 46 | 0,7 ± 0,2 | 1,5 |
| nov | 253 ± 45 | 0,7 ± 0,2 | 1,5 |
| Dec | 210 ± 48 | 0,7 ± 0,2 | 1,5 |
Die Gleichung lautet: Oberflächenabfluss = Niederschlagsintensität × Abflusskoeffizient × Einzugsgebiet. Die gesamte Verteilung wird mit Hilfe einer Gammaverteilung simuliert. Der durchschnittliche monatliche Oberflächenabfluss beträgt 124.000 ± 30 m3/mein. Der Median beträgt 120.000 m3/mein.
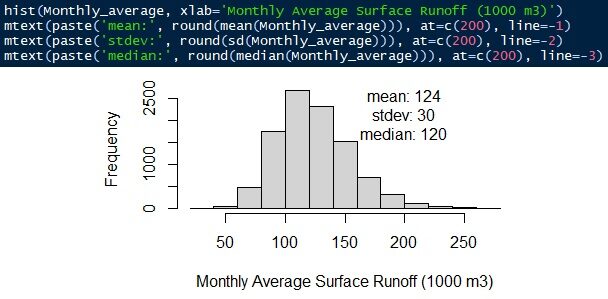
Abb.12 Durchschnittlicher monatlicher Oberflächenabfluss
Über den Autor
Verbinde dich hier mit mir https://www.linkedin.com/in/rendy-kurnia/
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





