Überblick
- Verstehen Sie, was SQL- und NoSQL-Datenbanken sind.
- Überprüfen Sie den hervorgehobenen Unterschied zwischen SQL- und No SQL-Datenbanken.
- Dies ist keine vollständige Liste. Fühlen Sie sich frei, weitere Unterschiede zwischen SQL und NoSQL in den Kommentaren hinzuzufügen
Einführung
Sie können nicht aufhören, sich über Datenbanken in der Datenwissenschaft zu informieren. Eigentlich, wir müssen uns mit dem Umgang mit Datenbanken vertraut machen, Abfragen schnell ausführen, etc. als Data-Science-Profis. Es gibt keinen Weg, es zu vermeiden!
Es gibt zwei Dinge, die Sie wissen sollten: lernen Sie alles über die Datenbankverwaltung und erfahren Sie, wie Sie es effizient machen können. Creme, Sie werden einen langen Weg im Bereich Data Science gehen.
Als Dateningenieur, ist verpflichtet, mit allen Arten von Datenbanken zu arbeiten, insbesondere SQL und NoSQL. Aber trotzdem, die meisten von uns haben bereits umfangreiche Erfahrungen mit SQL-Datenbanken. Wo wir scheitern, ist, wenn wir auf NoSQL-Datenbanken umsteigen müssen, und es kann anfangs ein bisschen einschüchternd sein, ehrlich gesagt, Der Anfang ist immer das Schwerste.
Dann, um das Hindernis für dich zu glätten, Wir werden in diesem Artikel über einige wichtige Unterschiede zwischen diesen beiden Datenbanktypen sprechen.. Dies verschafft Ihnen einen Überblick über die beiden und erleichtert Ihnen den Start Ihrer Reise.. Lasst uns beginnen!
Inhaltsverzeichnis
- Was sind SQL-Datenbanken??
- Was sind NoSQL-Datenbanken??
- Unterschied zwischen SQL- und NoSQL-Datenbanken
- Schematisches Design
- Datenstruktur
- Geschwindigkeit
- Klettern
- Verwenden
- Hauptadresse, Hauptführer
Was sind SQL-Datenbanken??
SQL ist eine Standardabfragesprache, mit der relationale Datenbanken abgefragt werden können. Deswegen, diese Datenbanken werden oft auch als SQL-Datenbanken bezeichnet.
Der Hauptvorteil von Datenbanken gegenüber normalen Dateispeichersystemen besteht darin, dass die Datenredundanz stark reduziert wird., erleichtert den Datenaustausch zwischen mehreren Benutzern und gewährleistet die Sicherheit von Daten, die für ein Unternehmen von immenser Bedeutung sein können.
Jede Datenbank enthält mehrere Tabellen, mit Daten in Form von Zeilen und Spalten. Und jede Tabelle ist mit anderen Tabellen in der Datenbank verbunden.
Was sind NoSQL-Datenbanken??
NoSQL oder Nicht nur SQL erschien am Ende des Jahrzehnts 2000. Es geht um flexible Datenbanken, skalierbar, profitabel und kein Schema.
Sie wurden aus der Notwendigkeit heraus geboren, große Datenmengen zu verarbeiten, die wir in der heutigen Welt generieren, die in verschiedenen Varianten erhältlich sind und mit einer beschleunigten Geschwindigkeit erzeugt werden.
Im Vergleich zu SQL-Datenbanken, sie sind von verschiedenen arten: dokumentenbasiert, basierend auf Schlüsselwerten, basierend auf breiten Spalten, grafikbasiert. Jedes hat seine Vor- und Nachteile.
Lassen Sie uns nun eintauchen und einige der wichtigsten Unterschiede zwischen SQL- und NoSQL-Datenbanken sehen.
Unterschied zwischen SQL- und NoSQL-Datenbanken
-
Schematisches Design
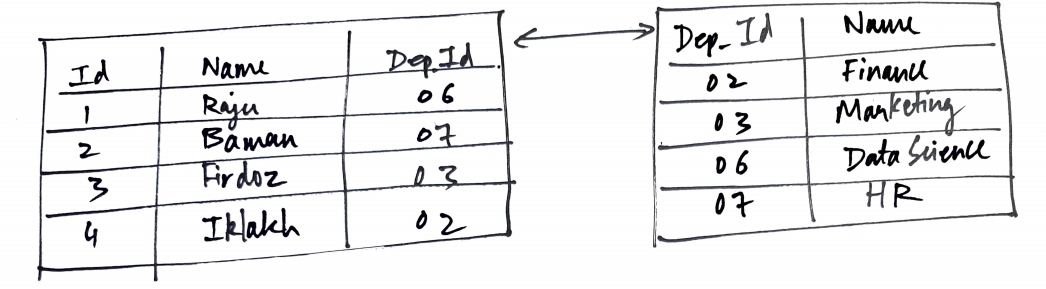
SQL-Datenbanken ist es so relationale Datenbanken die Daten in mehreren zusammenhängenden Tabellen speichern. Diese Tabellen sind Beziehungen. Jede Beziehung ist in Zeilen und Spalten organisiert. Jede Zeile ist a doppelt und hat einen Rekord, und jede Spalte ist a Attribut also hat jeder Datensatz normalerweise einen Wert. Datenbanktabellen sind mit SQL-Schlüsseln verknüpft.
Die Tabellenspalten enthalten einen bestimmten Datentyp. Wenn ein Datensatz Daten mit einem anderen Datentyp enthält, die Datenbank gibt einen Fehler aus. Was ist mehr, ein Datensatz muss die gleiche Anzahl von Werten enthalten wie die Anzahl der Spalten in der Tabelle oder er muss explizit einen NULL-Wert liefern. Die beliebtesten Beispiele für SQL-Datenbanken sind MySQL, PostgreSQL und Oracle.
Es gibt 4 NoSQL-Datenbanktypen: dokumentenbasiert, basierend auf Schlüsselwerten, breite spalten- und diagrammbasiert.
-
Dokumentbasierte Datenbanken
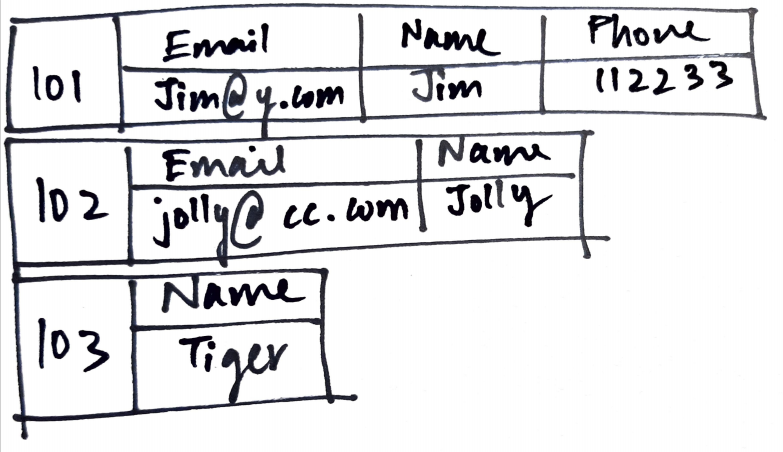
Diese Datenbanken speichern Daten in JSON-ähnlichen Dokumenten. Jedes Dokument hat ein Schlüsselwertformat, was bedeutet, dass die Daten halbstrukturiert sind. Auch wenn innerhalb eines Dokuments ein Wert für einen Schlüssel fehlt, die Datenbank gibt keinen Fehler aus. Ein beliebtes Beispiel ist MongoDB.

-
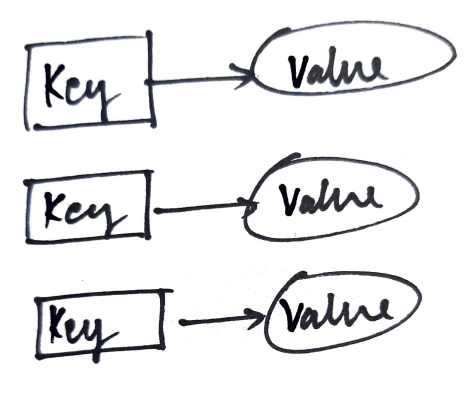
Schlüsselwertdatenbanken
Diese Datenbanken speichern Daten im Schlüsselwertformat. Sowohl Schlüssel als auch Werte können alles sein, von Strings zu komplexen Werten. Schlüssel werden in effizienten Indexstrukturen gespeichert und können Werte schnell und eindeutig lokalisieren. Dies macht sie ideal für Anwendungen, die eine schnelle Datenwiederherstellung erfordern.. Amazon DynamoDB ist ein Beispiel für diese Datenbanken.

-
Umfangreiche spaltenbasierte Datenbanken
Diese Datenbank speichert Daten in Datensätzen, die jeder relationalen Datenbank ähnlich sind, aber es hat die Fähigkeit, eine große Anzahl dynamischer Spalten zu speichern. Nämlich, die Anzahl der Spaltenwerte für Zeilen kann in diesen Datenbanken variieren. Gruppiert Spalten logisch in Spaltenfamilien. Kassandra ist ein beliebtes Beispiel.

-
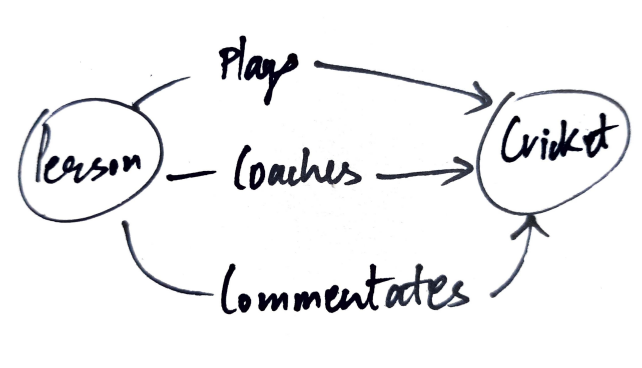
Graphbasierte Datenbanken
Sie verwenden Knoten, um Datenentitäten wie Orte zu speichern, Produkte, etc. und Kanten, um die Beziehung zwischen ihnen zu speichern. Es gibt keine Begrenzung für die Anzahl und Art der Beziehungen, die ein Knoten haben kann. Neo4j ist ein Beispiel für diese Datenbanken.

-
-
Datenstruktur
Die Bestimmung der Struktur oder des Schemas der Datenbank vor dem Hinzufügen von Daten ist eine Voraussetzung für SQL-Datenbanken. Dies bedeutet, dass diese Art von Datenbank nur strukturierte Daten speichern kann. Dies macht es sehr unflexibel, mit realen Daten umzugehen, die mit hoher Geschwindigkeit übertragen werden.. Das Aktualisieren des Schemas hier würde viel Zeit und Mühe kosten und viele Beziehungen aktualisieren müssen.
NoSQL-Datenbanken Zweitens, sie haben keine feste Struktur. Sie können mit jeder Art von Daten umgehen: strukturiert, halbstrukturiert oder unstrukturiert. Dies bedeutet, dass auch wenn die eingehenden Daten eine unterschiedliche Anzahl von Attributen haben, die Datenbank kann sie fehlerfrei verarbeiten. Dies macht NoSQL-Datenbanken sehr beliebt, da wir das Schema ohne große Unterbrechungen leicht ändern können.
-
Geschwindigkeit
Es gibt keinen wirklichen Unterschied zwischen den beiden, wenn es um die Geschwindigkeit geht. Beide funktionieren in den meisten Szenarien gleich gut. Aber trotzdem, Sie werden möglicherweise einige Unterschiede feststellen, wenn es um die Handhabung komplexer Abfragen und großer Datensätze geht.
SQL-Datenbanken erfordern eine standardisierte Datenspeicherung, um Datenredundanz zu vermeiden. Dies reduziert zwar den von der Datenbank benötigten Speicherplatz und gewährleistet eine einfache Aktualisierung der Datensätze, kann Auswirkungen auf die Datenbankabfrage haben. Zum Beispiel, Das Ausführen komplexer Abfragen wie Joins in einer Datenbank mit mehreren Tabellen kann ziemlich ermüdend sein, vor allem, wenn die Datengröße ziemlich groß wird. NoSQL-Datenbanken überwinden diesen Nachteil.
NoSQL-Datenbanken Es spielt keine Rolle, ob es eine Datenduplizierung gibt, da die Speicherung bei NoSQL-Datenbanken kein Problem darstellt. Daten in NoSQL-Datenbanken werden generell abfrageoptimiert gespeichert. Das bedeutet, dass Sie Daten so speichern können, wie Sie sie nach einer Abfrage benötigen würden. Dies schließt das ganze Problem von Joins aus und macht die Aufgabe der Abfrage viel schneller.
Zum Beispiel, SQL-Datenbanken erfordern, dass Sie zwei separate Tabellen für Mitarbeiterinformationen und Abteilungsinformationen führen, sie mit einem Fremdschlüssel verknüpfen, vielleicht die Abteilungs-ID.

Aber trotzdem, bei NoSQL-Datenbanken, como MongoDB, kann die vollständigen Informationen über den Mitarbeiter speichern, inklusive Abteilungsinformationen, innerhalb desselben Dokuments, obwohl Sie einige Werte verschachteln können, wenn Sie möchten.

Notiz: kann immer noch Joins auf NoSQL-Datenbanken durchführen.
-
Klettern
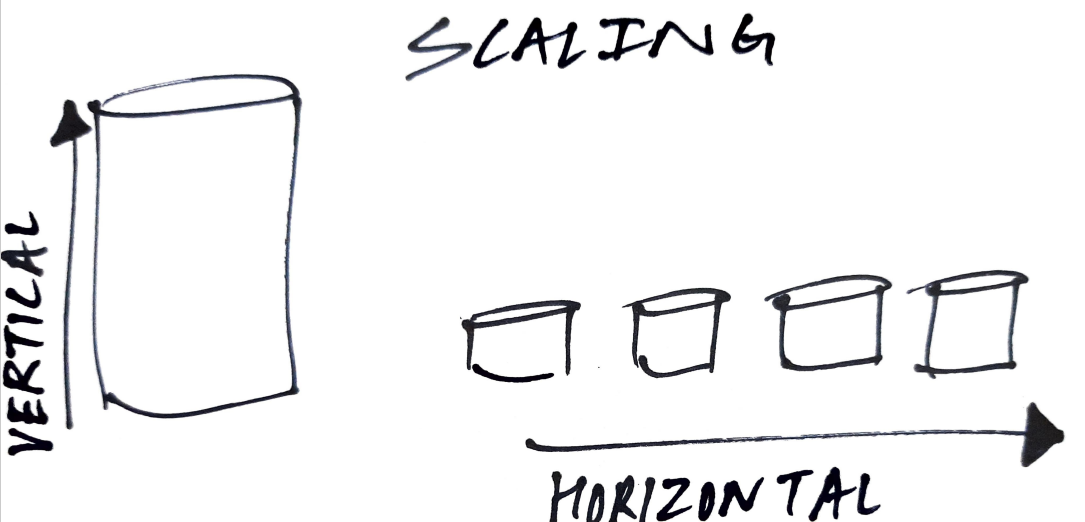
SQL-Datenbanken laufen auf herkömmlichen Maschinen. Das heißt, sie laufen auf einem einzigen Server. Jetzt, wenn Sie die aktuelle Kapazität Ihres Servers überschreiten, müsste eine leistungsstärkere CPU verwenden, füge mehr RAM hinzu, Stapelspeicher, etc. Das ist vertikale Skala. Das kann ziemlich teuer werden, vor allem, wenn Sie mit Big Data zu tun haben (im Auftrag von TB, GB, PB, etc.)
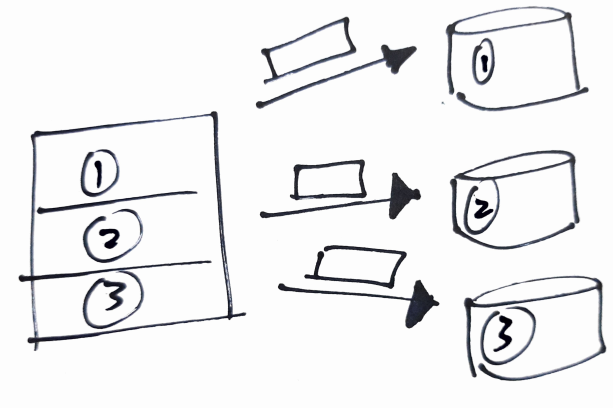
Zweitens, NoSQL-Datenbanken bieten horizontale Skala. Dies bedeutet, dass, wenn Ihnen die Kapazität ausgeht, Sie können dem Cluster einfach eine Maschine hinzufügen (eine Gruppe von Maschinen, die zusammenarbeiten). Diese Maschinen sind in der Regel viel billiger und bekannt als Basishardware. Diese Fähigkeit von NoSQL-Datenbanken hat neben dem kostengünstigeren Kapazitätsaufbau einen weiteren wichtigen Vorteil: Datenverteilung.

NoSQL-Datenbanken laufen im Allgemeinen auf mehreren miteinander verbundenen Maschinen, was als Cluster bekannt ist. Daten werden auf Maschinen innerhalb des Clusters verteilt. Jede Maschine speichert einen Teil der Daten.

Jetzt müssen Sie sich fragen, wie das von Vorteil ist.
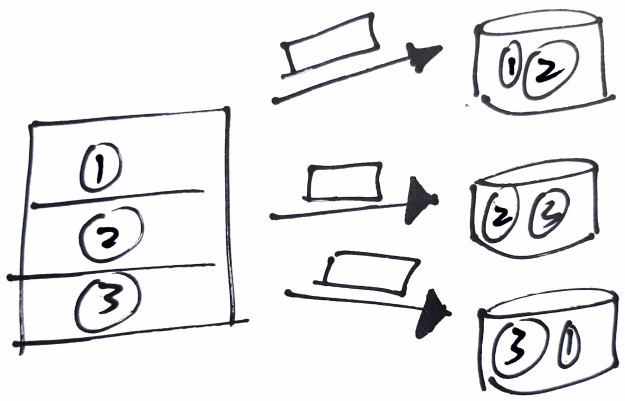
Gut, Die Verteilung von Daten bietet uns die Möglichkeit, Daten replizieren und bieten Fehlertoleranz. Nämlich, ein Teil der Daten kann repliziert und auf mehreren Maschinen gespeichert werden.

Wenn eine Maschine ausfällt, die darin enthaltenen Daten sind auf einem anderen Computer im Cluster vorhanden und können ohne Wissen des Benutzers verwendet werden, bietet somit Fehlertoleranz. Offensichtlich, dies ist bei SQL-Datenbanken nicht möglich, da die Speicherung aller Daten auf derselben Maschine erfolgt.
-
Hauptadresse, Hauptführer
Ein großer Vorteil von SQL-Datenbanken ist seine Fähigkeit zu handhaben Transaktionsverarbeitung. Diese Prozesse ändern den Inhalt einer Datenbank. Die ACID-Eigenschaften von SQL-Datenbanken bestimmen:
- Atomicidad – Transaktionen finden einzeln oder gar nicht statt.
- Konsistenz – Dadurch wird sichergestellt, dass die Datenbank nicht mitten in einem vollen Zustand verbleibt. Wenn ein Fehler auftritt, stellt sicher, dass Rollback-Änderungen auftreten.
- Isolation – Transaktionen erfolgen unabhängig. Keine Transaktion hat Zugriff auf eine andere Transaktion.
- Haltbarkeit – Änderungen an der Datenbank durch Transaktionen nach Abschluss werden in die Datenbank übernommen und Aktualisierungen gehen nicht verloren.
NoSQL-Datenbanken Zweitens, Bieten Sie die ACID-Eigenschaften nicht vollständig an. jedoch, das CAP-Theorem regelt sie:
- Konsistenz – Dies bedeutet, dass der Benutzer Sie sollten in der Lage sein, die gleichen Daten zu sehen, egal auf welchem Knoten / Maschine sind im System eingebunden / Cluster. Dann, wenn Daten auf einen Knoten geschrieben wurden, muss auf allen Replikaten repliziert werden.
- Verfügbarkeit – Dies bedeutet, dass jede Benutzeranfrage sollte eine Antwort vom System erhalten. Ob der Benutzer lesen oder schreiben möchte, der Benutzer sollte eine Antwort erhalten, auch wenn der Vorgang nicht erfolgreich war.
- Partitionstoleranz – Eine Partitionierung tritt auf, wenn ein Knoten keine Nachrichten von einem anderen Knoten im System empfangen kann. Es könnte an einem Netzwerkfehler gelegen haben, Serverausfall oder andere Gründe. Deswegen, Partitionstoleranz stellt sicher, dass das System auch dann noch funktionieren kann, wenn es eine Partition im System gibt.
Aber trotzdem, NoSQL-Datenbanken müssen bei der Partitionierung einen Kompromiss zwischen Konsistenz und Verfügbarkeit eingehen. Das ist weil, in einem realen Weltsystem, die Partition tritt wahrscheinlich aufgrund eines Netzwerkfehlers oder aus anderen Gründen auf. Deswegen, wenn eine Partition auftritt, eine NoSQL-Datenbank muss Kompromisse bei Konsistenz oder Verfügbarkeit eingehen. Deswegen, eine verteilte NoSQL-Datenbank wird als CP oder AP bezeichnet.

Notiz: NoSQL-Datenbanken sind nicht so starr, wenn es um CAP geht. Die meisten bieten Optionen zum Ausgleich von Konsistenz und Verfügbarkeit. Deswegen, die auswahl ist nicht immer so schwarz-weiß.
-
Verwenden
Die ACID-Eigenschaft macht SQL-Datenbanken in Bereichen extrem wichtig, in denen Transaktionen extrem wichtig sind. Bankgeschäfte sind ein Beispiel, wo Geldtransaktionen korrekt abgewickelt werden müssen, insbesondere bei fehlgeschlagener Überweisung, dessen Scheitern ein Vermögen kosten kann.
Was ist mehr, ob Ihre Daten strukturiert sind und sich nicht ändern, kein Grund, NoSQL-Datenbanken zu verwenden. Sie können jederzeit die Möglichkeiten Ihrer SQL-Datenbanken nutzen und, Natürlich, seine herausragenden Kenntnisse in SQL!
Aber trotzdem, wenn Sie mit großen Datenmengen ohne etablierte Struktur arbeiten möchten, NoSQL-Datenbanken sind die beste Option. Aber auch NoSQL-Datenbanken können je nach inhärenter Struktur und Ihrer Präferenz für die Eigenschaften des CAP-Theorems einen weitreichenden Anwendungsfall haben..
Während, einerseits, ElasticSearch speichert Protokolldaten, Kassandra, Zweitens, wird von vielen Social-Media-Websites verwendet. Aber trotzdem, All dies hilft am Ende des Tages, das Volumen zu verwalten, die Geschwindigkeit und Vielfalt von Big Data!

Abschließende Anmerkungen
In diesem Artikel, diskutieren wir die Hauptunterschiede zwischen SQL- und NoSQL-Datenbanken. Dies ist keineswegs eine vollständige Liste der Unterschiede zwischen den beiden Datenbanken. Aber hoffentlich, Du hast eine gute Beschreibung von beiden!
In die Zukunft schauen, Ich empfehle dir, es auszuprobieren Kurs SQL für Data Science und die folgenden Artikel zu SQL und NoSQL:





