Einführung
Lange Zeit, Ich habe das Vorhersagemodell mit linearer Regression erstellt und eine Variable gefunden, deren nicht standardisierter Regressionskoeffizient (Beta oder Schätzung) nahe null, aber nach einiger analyse, Ich finde es statistisch signifikant (bedeutet p-Wert <0.05 ). Sabemos que si una variable es significativa para un modelo en particular, significa que el valor de su coeficiente es significativo y distinto de cero. Entonces, la pregunta que ocurre es "¿Por qué el valor del coeficiente es cercano a cero pero esa variable es significativa para nuestro modelo predictivo?".
Die Lösung dieser Frage liegt in der Differenz zwischen standardisierten und nicht standardisierten Regressionskoeffizienten.. Dann, in diesem Beitrag, wir werden die grundlegenden Konzepte hinter diesen Koeffizienten sehen und wie sie sich mit ihren Vor- und Nachteilen voneinander unterscheiden.
Das Konzept der Standardisierung oder Standardkoeffizienten kommt ins Spiel, wenn die unabhängigen Variablen oder der Prädiktor eines bestimmten Modells in verschiedenen Einheiten ausgedrückt werden.. Als Beispiel, Sagen wir, wir haben drei unabhängige Eigenschaften, nämlich, Höhe, Alter und Gewicht. Ihre Größe ist in Zoll, Ihr Gewicht in Kilogramm und Ihr Alter in Jahren. Wenn wir diese Prädiktoren basierend auf dem nicht standardisierten Koeffizienten kategorisieren wollen (das kommt direkt, wenn wir ein Regressionsmodell trainieren), es wäre kein fairer Vergleich, da die Einheiten für alle Prädiktoren unterschiedlich sind.
Nicht standardisierte Regressionskoeffizienten
1. Was sind nicht standardisierte Regressionskoeffizienten??
Die nicht standardisierten Koeffizienten sind diejenigen, die vom linearen Regressionsmodell nach seinem Training unter Verwendung der unabhängigen Variablen erzeugt werden, die auf ihren ursprünglichen Skalen gemessen wurden., Mit anderen Worten, in denselben Einheiten, in denen der Datensatz aus der Quelle entnommen wird, um das Modell zu trainieren.
– Der nicht standardisierte Koeffizient sollte nicht verwendet werden, um Prädiktoren auszuschließen oder zu kategorisieren (auch als unabhängige Variablen bekannt), da es die Maßeinheit nicht eliminiert.
Als Beispiel, Nehmen wir ein hypothetisches Beispiel, bei dem wir den Umsatz vorhersagen wollen (in Rupien) einer Person aufgrund ihres Alters (in Jahren), Höhe (und cm) und Gewicht (in kg). Dann, hier sind die Eingaben für unser Regressionsmodell das Alter, Größe und Gewicht, und Produktion ist Einkommen. Anschließend,
Einkommen (Rupien) = A0 + a1 * Alter (Jahre) + a2 * Höhe (cm) + a3 * Last (kg) + e (eqn-1)
2. So interpretieren Sie nicht standardisierte Regressionskoeffizienten?
Sie werden verwendet, um die Auswirkung jeder unabhängigen Variablen auf das Ergebnis zu interpretieren. (Antworten / Ausgang). Seine Interpretation ist einfach und intuitiv.
– Alle anderen Variablen werden konstant gehalten, eine Änderung von 1 Einheit in Xi (Prädiktoren) impliziert, dass es eine durchschnittliche Änderung der Einheiten ai in Y . gibt (Ergebnis).
Im obigen Beispiel, und a1 = 0.3, a2 = 0.2 y a3 = 0.4 (und wir gehen davon aus, dass sie alle statistisch signifikant sind), dann interpretieren wir diese Koeffizienten als:
Haben 1 Jahr ist mit einem Anstieg der 0,3 im Einkommen, unter der Annahme, dass andere Variablen konstant sind (bedeutet, dass sich Größe und Gewicht nicht ändern).
Äquivalent, wir können den Koeffizienten auch für andere unabhängige Variablen interpretieren.
Stellt den Betrag dar, um den sich die abhängige Variable ändert, wenn wir die unabhängige Variable um eine Einheit ändern und die anderen unabhängigen Variablen konstant halten..
3. Einschränkungen nicht standardisierter Regressionskoeffizienten
– Nicht standardisierte Koeffizienten eignen sich hervorragend zur Interpretation des Zusammenhangs zwischen einer unabhängigen Variablen X und einem Ergebnis Y. Trotz dieses, sind nicht nützlich, um den Effekt einer unabhängigen Variablen mit einer anderen im Modell zu vergleichen.
– Als Beispiel, Welche Variable hat den größten Einfluss auf das Einkommen?, Alter, Größe oder Gewicht?
Wir können versuchen, diese Frage zu beantworten, indem wir Gleichung-1 betrachten und wieder annehmen, dass a1 = 0.3, a2 = 0.2 y a3 = 0.4, Wir schließen daraus:
“Eine Zunahme von 20 cm Körpergröße hat den gleichen Effekt auf die Gewichtszunahme 10 mal”
Auch so, Dies beantwortet nicht die Frage, welche Variable das Einkommen am meisten beeinflusst.
Speziell, die Behauptung, dass „die Wirkung der Gewichtszunahme auf“ 10 mal = die Wirkung der Zunahme der Höhe von 20 cm „macht keinen Sinn, ohne anzugeben, wie schwierig es ist, die Höhe zu erhöhen 20 cm, speziell für jemanden, der mit dieser Skala nicht vertraut ist.
Dann, schließlich, wir schlussfolgern, dass ein direkter Vergleich der Regressionskoeffizienten für eine der beiden unabhängigen Variablen keinen Sinn macht oder nicht sinnvoll ist, da diese unabhängigen Variablen auf unterschiedlichen Skalen liegen (Alter in Jahren, Gewicht in kg und Körpergröße in cm).
Es stellt sich heraus, dass die Auswirkungen dieser Variablen mit der standardisierten Version ihrer Koeffizienten verglichen werden können. Und das werden wir als nächstes besprechen.
Standardisierte Regressionskoeffizienten
1. Was sind standardisierte Regressionskoeffizienten?
Die standardisierten Regressionskoeffizienten erhält man durch Training (oder laufen) ein lineares Regressionsmodell in standardisierter Form der Variablen.
Standardisierte Variablen werden berechnet, indem der Mittelwert abgezogen und durch die Standardabweichung jeder Beobachtung dividiert wird., Mit anderen Worten, Berechnung des Z-Scores. ich würde meinen 0 und Standardabweichung 1. Dann, sie stellen nicht ihre ursprünglichen Skalen dar, da sie keine Einheit haben.
Für jede Beobachtung “J” der Variablen X, Wir berechnen den Z-Score mit der Formel:
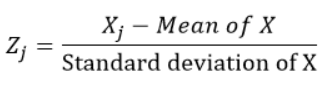
2. Welche Variablen müssen wir standardisieren, um die standardisierten Regressionskoeffizienten zu finden, Mit anderen Worten, sowohl der Prädiktor als auch die Lösung oder eine von ihnen?
Jawohl, wir standardisieren beide abhängigen Variablen (Antworten) wie die Unabhängigen (Prädiktoren) bevor Sie das lineare Regressionsmodell ausführen (da dies die allgemein akzeptierte Praxis ist, wenn wir die standardisierte Form der Variablen finden wollen).
3. So interpretieren Sie standardisierte Regressionskoeffizienten?
Die Interpretation der standardisierten Regressionskoeffizienten ist im Vergleich zu ihren nicht standardisierten Versionen nicht intuitiv:
Eine Änderung von 1 Standardabweichung in X ist mit einer Änderung der Standardabweichungen β von Y . verbunden.
Notiz:
– Wenn es in unserer Analyse eine kategoriale Variable anstelle einer numerischen Variable gibt, dann kann sein standardisierter Koeffizient nicht interpretiert werden, da es keinen Sinn macht, X in umzuwandeln 1 Standardabweichung. Allgemein, das ist kein hindernis für unser modell, da diese Koeffizienten nicht einzeln interpretiert werden sollen, sondern miteinander verglichen werden, um eine Vorstellung von der Relevanz jeder Variablen im linearen Regressionsmodell zu bekommen.
Der standardisierte Koeffizient wird in Einheiten der Standardabweichung gemessen. Ein Beta-Wert von 2.25 gibt an, dass eine Änderung der unabhängigen Variablen um eine Standardabweichung zu einer Erhöhung um . führt 2.25 Standardabweichungen der abhängigen Variablen.
4. Was ist die tatsächliche Verwendung von standardisierten Koeffizienten?
Sie werden hauptsächlich verwendet, um Prädiktoren zu kategorisieren (o unabhängige oder erklärende Variablen) da sie die Maßeinheiten der unabhängigen und abhängigen Variablen eliminieren). Wir können die unabhängigen Variablen mit einem absoluten Wert von standardisierten Koeffizienten kategorisieren. Die wichtigste Variable hat den maximalen absoluten Wert des standardisierten Koeffizienten.
Als Beispiel:
Y = β0 + B1 x1 + B2 x2 + e
Wenn die standardisierten Koeffizienten β1 = 0.5 y β2 = 1, können wir schließen, dass:
x2 ist doppelt so wichtig wie X1 in der Prognose von Y, unter der Annahme, dass beide X1 und X2 folgen ungefähr der gleichen Verteilung und ihre Standardabweichungen sind nicht so unterschiedlich.
5. Einschränkungen der standardisierten Regressionskoeffizienten
Standardisierte Koeffizienten sind irreführend, wenn die Variablen im Modell unterschiedliche Standardabweichungen aufweisen, dh alle Variablen haben unterschiedliche Verteilungen.
Schauen Sie sich die nächste lineare Regressionsgleichung an:
Einkommen ($) = β0 + B1 Alter (Jahre) + B2 Erfahrung (Jahre) + e
Weil unsere unabhängigen Variablen Alter und Erfahrung auf derselben Skala liegen (Jahre) und wenn vernünftigerweise davon auszugehen ist, dass sich ihre Standardabweichungen stark unterscheiden, dann für diesen Fall:
– Seine nicht standardisierten Koeffizienten sollten verwendet werden, um seine Relevanz zu vergleichen / Einfluss auf das Modell.
– Eine Standardisierung dieser Variablen würde ausreichen, in Wirklichkeit, die waren in einem anderen maßstab (unterschiedliche Standardabweichungen oder folgt einer anderen Verteilung)
Berechnung standardisierter Koeffizienten
1. Für lineare Regression (Ein anderer Ansatz, da wir im vorherigen Teil des Beitrags einen Schwerpunkt sehen)
Der standardisierte Koeffizient wird durch Multiplikation des nicht standardisierten Koeffizienten mit dem Verhältnis der Standardabweichungen der unabhängigen Variablen und der abhängigen Variablen erhalten..

2. Für logistische Regression

Abschließende Anmerkungen
In diesem Beitrag wurden einige grundlegende, aber notwendige Konzepte für die Arbeit an einem realen Projekt im Bereich maschinelles Lernen und künstliche Intelligenz behandelt.. Ich hoffe, Sie haben die in diesem Beitrag erläuterten Konzepte sehr gut verstanden. In diesem Beitrag im letzten Teil, Wir sehen nur die Formulierung in Bezug auf die Konzepte, aber wir vertiefen uns nicht viel in die Mathematik dahinter, Wir werden diesen Teil in einem anderen Beitrag besprechen.
Wenn Sie irgendwelche Fragen haben, Lass es mich im Kommentarbereich wissen!
Die in diesem Beitrag gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





