Einführung
Eine gemeinsame Herausforderung, der ich währenddessen begegnet bin Erlernen der Verarbeitung natürlicher Sprache (PNL) – Können wir Modelle für andere Sprachen als Englisch erstellen?? Die Antwort lautet schon seit geraumer Zeit nein. Jede Sprache hat ihre eigenen grammatikalischen Muster und sprachlichen Nuancen. Und es gibt einfach nicht viele Datensätze in anderen Sprachen.
Hier kommt die neueste NLP-Bibliothek von Stanford ins Spiel.: StanfordNLP.
Ich konnte meine Aufregung kaum zurückhalten, als ich letzte Woche die Nachrichten las. Die Autoren stellten fest, dass StanfordNLP mehr als 53 menschliche Sprachen. Jawohl, Ich musste diese Nummer noch einmal überprüfen.
Ich habe beschlossen, es selbst zu überprüfen. Es gibt noch kein offizielles Tutorial für die Bibliothek, Also hatte ich die Chance zu experimentieren und damit zu spielen. Und ich habe herausgefunden, dass es eine Welt unendlicher Möglichkeiten eröffnet. StanfordNLP enthält vortrainierte Modelle für seltene asiatische Sprachen wie Hindi, Chinesisch und Japanisch in ihren Originalschriften.

Die Fähigkeit, mit mehreren Sprachen zu arbeiten, ist ein Wunder, nach dem sich alle NLP-Enthusiasten sehnen. In diesem Artikel, Wir werden analysieren, was StanfordNLP ist, Warum ist es so wichtig, und dann werden wir Python aktivieren, um es live in Aktion zu sehen. Wir werden auch eine Hindi-Fallstudie durchführen, um zu zeigen, wie StanfordNLP funktioniert, Das wirst du nicht verpassen wollen!
Inhaltsverzeichnis
- Was ist StanfordNLP und warum sollten Sie es verwenden??
- StanfordNLP-Konfiguration in Python
- Verwenden von StanfordNLP zum Ausführen grundlegender NLP-Aufgaben
- StanfordNLP-Implementierung in Hindi
- Verwenden der CoreNLP-API für die Textanalyse
Was ist StanfordNLP und warum sollten Sie es verwenden??
Hier ist die Beschreibung von StanfordNLP von den Autoren selbst:
StanfordNLP ist die Kombination des vom Stanford-Team verwendeten Softwarepakets in der gemeinsamen Aufgabe CoNLL 2018 über die universelle Abhängigkeitsanalyse und die offizielle Python-Schnittstelle der Gruppe für die Software Stanford CoreNLP.
Es sind zu viele Informationen auf einmal!! Lass es uns zerlegen:
- ConLL ist eine jährliche Konferenz zum Lernen natürlicher Sprachen. Teams aus Forschungsinstituten auf der ganzen Welt versuchen, ein Problem zu lösen. PNL aufgabenbasiert
- Eine der Aufgaben des letzten Jahres war “Mehrsprachige Analyse von Klartext zu universellen Abhängigkeiten”. In einfachen Worten, bedeutet das Parsen von unstrukturierten Textdaten aus mehreren Sprachen in hilfreiche Annotationen universeller Abhängigkeiten.
- Universelle Abhängigkeiten ist ein Framework, das die Konsistenz in Anmerkungen aufrechterhält. Diese Anmerkungen werden unabhängig von der analysierten Sprache für den Text generiert.
- Stanfords Präsentation belegte den ersten Platz in 2017. Sie verloren den ersten Platz in 2018 aufgrund eines Softwarefehlers (belegte den vierten Platz)
StanfordNLP ist eine Sammlung von vortrainierten State-of-the-Art-Modellen. Diese Modelle wurden von den Forschern in den CoNLL-Wettbewerben verwendet. 2017 Ja 2018. Alle Modelle basieren auf PyTorch und können mit eigenen annotierten Daten trainiert und ausgewertet werden. Beeindruckend!
 des Weiteren, StanfordNLP enthält auch einen offiziellen Container für die beliebte riesige NLP-Bibliothek: CoreNLP. Dies war bisher eher auf das Java-Ökosystem beschränkt. Sie sollten sich dieses Tutorial ansehen, um mehr über CoreNLP und seine Funktionsweise in Python zu erfahren.
des Weiteren, StanfordNLP enthält auch einen offiziellen Container für die beliebte riesige NLP-Bibliothek: CoreNLP. Dies war bisher eher auf das Java-Ökosystem beschränkt. Sie sollten sich dieses Tutorial ansehen, um mehr über CoreNLP und seine Funktionsweise in Python zu erfahren.
Hier sind ein paar weitere Gründe, warum Sie diese Bibliothek besuchen sollten:
- Native Python-Implementierung, die minimalen Konfigurationsaufwand erfordert
- Vollständige neuronale Netzwerk-Pipeline für robuste Textanalyse, was beinhaltet:
- Tokenización
- Mehrwort-Token-Erweiterung (MWT)
- Lematización
- Wortarten beschriften (POS) und morphologische Merkmale
- Abhängigkeitsanalyse
- Vortrainierte neuronale Modelle, die 53 Redewendungen (Menschen) vorgestellt in 73 Baumbänke
- Eine stabile und offiziell gewartete Python-Schnittstelle für CoreNLP
Was könnte ein NLP-Enthusiast mehr verlangen?? Jetzt haben wir eine Vorstellung davon, was diese Bibliothek tut, Lass uns eine Runde in Python drehen!
StanfordNLP-Konfiguration in Python
Es gibt einige skurrile Dinge an der Bibliothek, die mich zuerst verwirrt haben. Zum Beispiel, du brauchst Python 3.6.8 / 3.7.2 oder später, um StanfordNLP zu verwenden. Um sicher zu sein, Ich habe in Anaconda eine separate Umgebung eingerichtet, um Python 3.7.1. So kannst du es machen:
1. Öffnen Sie die Conda-Eingabeaufforderung und geben Sie dies ein:
conda create -n stanfordnlp python=3.7.1
2. Aktiviere jetzt die Umgebung:
Quelle aktivieren stanfordnlp
3. Installieren Sie die StanfordNLP-Bibliothek:
pip install stanfordnlp
4. Wir müssen das spezifische Modell einer Sprache herunterladen, um damit zu arbeiten. Starten Sie eine Python-Shell und importieren Sie StanfordNLP:
import stanfordnlp
dann lade das Sprachmodell für Englisch herunter (“In”):
stanfordnlp.download('An')
Dies kann je nach Internetverbindung eine Weile dauern.. Diese Sprachmodelle sind ziemlich groß (Englisch ist von 1,96 GB).
Ein paar wichtige Hinweise
- StanfordNLP basiert auf PyTorch 1.0.0. Könnte abstürzen, wenn Sie eine ältere Version haben. Dann, Wir zeigen Ihnen, wie Sie die auf Ihrem Rechner installierte Version überprüfen können:
pip einfrieren | grep fackel
was eine Ausgabe wie geben sollte torch==1.0.0
- Ich habe versucht, die Bibliothek ohne GPU auf meinem Lenovo Thinkpad E470 zu verwenden (8GB RAM, Intel-Grafik). Ich habe ziemlich schnell einen Speicherfehler in Python bekommen. Deswegen, Ich bin auf einen GPU-fähigen Computer umgestiegen und würde Ihnen raten, dasselbe zu tun. Du kannst es versuchen Google Colab das kommt mit kostenloser GPU-Unterstützung
Das ist alles! Lassen Sie uns gleich in einige grundlegende NLP-Prozesse eintauchen..
Verwenden von StanfordNLP zum Ausführen grundlegender NLP-Aufgaben
StanfordNLP verfügt über integrierte Prozessoren zur Ausführung von fünf grundlegenden NLP-Aufgaben:
- Tokenización
- Mehrwort-Token-Erweiterung
- Lematización
- Kennzeichnung von Wortarten
- Abhängigkeitsanalyse
Beginnen wir mit der Erstellung einer Textpipeline:
nlp = stanfordnlp.Pipeline(Prozessoren = "tokenisieren,mwt,Lemma,Pos")
doc = nlp("""Die Aussichten für den geordneten Austritt Großbritanniens aus der Europäischen Union im März 29 sind weiter zurückgegangen, selbst als die Abgeordneten sich versammelten, um ein No-Deal-Szenario zu stoppen. Eine Änderung des Gesetzesentwurfs zur Beendigung der Londoner Blockmitgliedschaft verpflichtet Premierministerin Theresa May, ihr Austrittsabkommen mit Brüssel neu zu verhandeln. Der Vorschlag eines Tory-Hinterbänklers fordert die Regierung auf, Alternativen zum irischen Backstop zu finden, ein zentraler Grundsatz des Abkommens, das Großbritannien mit dem Rest der EU vereinbart hat.""")
das Prozessoren = “” Das Argument wird verwendet, um die Aufgabe zu spezifizieren. Alle fünf Prozessoren werden standardmäßig verwendet, wenn keine Argumente übergeben werden. Hier ein kurzer Überblick über die Prozessoren und was sie können:

Lass uns jeden von ihnen in Aktion sehen.
Tokenización
Dieser Vorgang erfolgt implizit, sobald der Token-Prozessor läuft. Eigentlich, es ist ziemlich schnell. Sie können sich die Token ansehen mit print_tokens ():
doc.sätze[0].print_tokens()
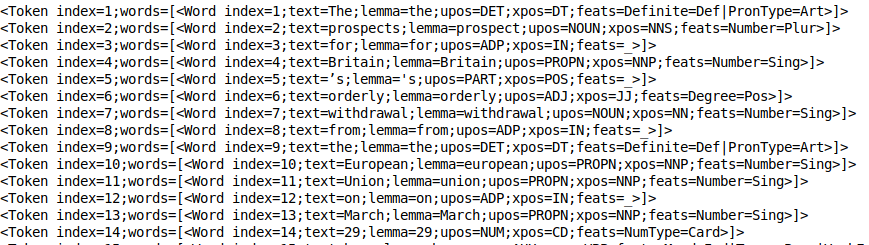
Das Token-Objekt enthält den Index des Tokens im Satz und eine Liste von Wortobjekten (bei einem Mehrwort-Token). Jedes Wortobjekt enthält nützliche Informationen, als Index des Wortes, das Motto des Textes, Post-Tag (Teile der Rede) und das feat tag (morphologische Merkmale).
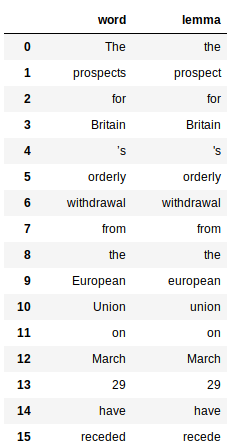
Lematización
Dies beinhaltet die Nutzung der Immobilie “Motto” der vom Slogan-Prozessor generierten Wörter. Hier ist der Code, um das Motto aller Wörter zu erhalten:
Dies gibt a . zurück Pandas Datenrahmen für jedes Wort und sein jeweiliges Motto:
Wortarten beschriften (PoS)
Der PoS-Tagger ist recht schnell und funktioniert in allen Sprachen hervorragend. Wie die Slogans, PoS-Tags sind auch leicht zu entfernen:
Beachten Sie das große Wörterbuch im obigen Code? Es ist nur eine Zuordnung zwischen PoS-Tags und ihrer Bedeutung. Dies hilft, die syntaktische Struktur unseres Dokuments besser zu verstehen.
Die Ausgabe wäre ein Datenrahmen mit drei Spalten: Wort, pos und exp (Erläuterung). Die Erklärungsspalte gibt uns die meisten Informationen über den Text (Ja, Daher, es ist ganz nützlich).
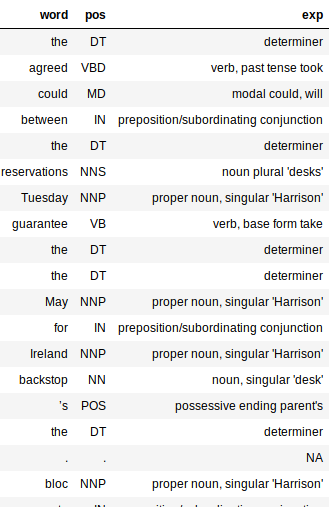
Durch das Hinzufügen der Spalte "Erklären" können Sie viel einfacher beurteilen, wie genau unser Prozessor ist.. Ich mag die Tatsache, dass der Tagger für die meisten Wörter genau ist. Es erfasst sogar die Zeit eines Wortes und ob es in der Grund- oder Pluralform vorliegt.
Abhängigkeitsextraktion
Die Abhängigkeitsextraktion ist ein weiteres Out-of-the-Box-Feature von StanfordNLP. Du kannst einfach anrufen print_dependencies () in einem Satz, um die Abhängigkeitsverhältnisse für alle Ihre Wörter zu erhalten:
doc.sätze[0].print_dependencies()

Die Bibliothek berechnet all dies während eines einzigen Pipeline-Laufs. Dies dauert auf einem GPU-fähigen Computer nur wenige Minuten..
Jetzt haben wir eine Möglichkeit entdeckt, mit StanfordNLP eine grundlegende Textverarbeitung durchzuführen. Es ist an der Zeit, die Tatsache zu nutzen, dass wir dasselbe für andere tun können! 51 Sprachen!
StanfordNLP-Implementierung in Hindi
StanfordNLP zeichnet sich wirklich durch seine Leistung und Unterstützung bei der mehrsprachigen Textanalyse aus. Lassen Sie uns auf diesen letzten Aspekt eingehen.
Hindi-Textverarbeitung (Devanagari-Skript)
Zuerst, wir müssen das Hindi-Sprachmodell herunterladen (Vergleichsweise kleiner!):
stanfordnlp.download('Hi')
Jetzt, Nehmen Sie einen Ausschnitt aus Hindi-Text als unser Textdokument:
hindi_doc = nlp("""Die Modi-Regierung im Zentrum hat am Freitag ihren Zwischenhaushalt vorgestellt.. Der amtierende Finanzminister Piyush Goyal in seinem Haushalt, Arbeit, Steuerzahler, Stoßstangen für alle angekündigt, auch für Frauen. Obwohl, Auch nach dem Budget gab es viel Verwirrung um die Steuer.. Was war das Besondere an diesem Zwischenhaushalt der Zentralregierung und wer hat was bekommen, hier in leichter Sprache verstehen""")
Dies sollte ausreichen, um alle Labels zu generieren. Lassen Sie uns die Tags für Hindi . überprüfen:
Extract_pos(hindi_doc)
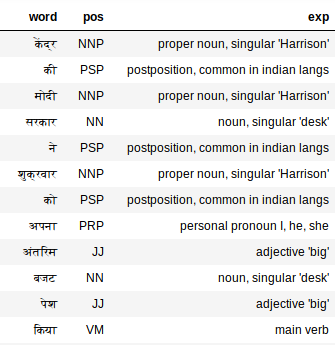
Der PoS-Tagger funktioniert auch bei Hindi-Text überraschend gut. Suchen “Mein”, zum Beispiel. Der PoS-Tagger bezeichnet es als Pronomen, mich, er, Sie, was ist genau.
Verwenden der CoreNLP-API für die Textanalyse
CoreNLP ist ein bewährtes NLP-Toolkit in Industriequalität, das für seine Leistung und Genauigkeit bekannt ist. StanfordNLP wurde als offizielle Python-Schnittstelle für CoreNLP deklariert. Das ist ein GROSSER Gewinn für diese Bibliothek.
Es gab bereits Bemühungen, Python-Wrapper-Pakete für CoreNLP zu erstellen, aber nichts geht über eine offizielle Umsetzung der Autoren selbst. Dies bedeutet, dass die Bibliothek regelmäßig aktualisiert und verbessert wird..
StanfordNLP benötigt drei Codezeilen, um die ausgeklügelte CoreNLP-API verwenden zu können. Buchstäblich, Nur drei Zeilen Code zum Einrichten!!
1. Laden Sie das CoreNLP-Paket herunter. Öffnen Sie Ihr Linux-Terminal und geben Sie den folgenden Befehl ein:
wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
2. Entpacken Sie das heruntergeladene Paket:
stanford-corenlp-full-2018-10-05.zip entpacken
3. Starten Sie den CoreNLP-Server:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -Auszeit 15000
Notiz: CoreNLP benötigt Java8 zum Ausführen. Stellen Sie sicher, dass JDK und JRE 1.8.x installiert sind.
Jetzt, Stellen Sie sicher, dass StanfordNLP weiß, wo CoreNLP präsent ist. Dafür, muss exportieren $ CORENLP_HOME als Speicherort für Ihren Ordner. In meinem Fall, Dieser Ordner war in Heimat an sich, damit mein Weg ist wie
export CORENLP_HOME=stanford-corenlp-full-2018-10-05/
Sobald die obigen Schritte ausgeführt wurden, Sie können den Server starten und Anfragen im Python-Code stellen. Unten ist ein vollständiges Beispiel für das Starten eines Servers, Anfragen stellen und auf die Daten des zurückgegebenen Objekts zugreifen.
ein. CoreNLPClient-Konfiguration
B. Abhängigkeitsanalyse und POS
C. Erkennung von benannten Entitäten und Co-Referenz-Strings
Die obigen Beispiele kratzen kaum an der Oberfläche dessen, was CoreNLP leisten kann und, aber trotzdem, es ist sehr interessant, Wir konnten alles erledigen, von grundlegenden NLP-Aufgaben wie der Kennzeichnung von Wortarten bis hin zu Dingen wie dem Erkennen von benannten Entitäten, Co-Referenz-Strings extrahieren und herausfinden, wer was geschrieben hat. in einem Satz in ein paar Zeilen Python-Code.
Was mir hier am besten gefällt, ist die Benutzerfreundlichkeit und die erhöhte Zugänglichkeit, die dies mit sich bringt, wenn es um die Verwendung von CoreNLP in Python geht.
Meine Gedanken zur Verwendung von StanfordNLP – Vor-und Nachteile
Die Erkundung einer neu gestarteten Bibliothek war sicherlich eine Herausforderung. Es gibt kaum Dokumentation zu StanfordNLP! Aber trotzdem, Es war eine sehr angenehme Lernerfahrung.
Einige Dinge, die mich im Hinblick auf die Zukunft von StanfordNLP begeistern:
- Ihre Out-of-the-Box-Unterstützung für mehrere Sprachen
- Die Tatsache, dass es eine offizielle Python-Schnittstelle für CoreNLP sein wird. Dies bedeutet, dass es in Zukunft nur die Funktionalität und die Benutzerfreundlichkeit verbessern wird..
- Es ist ziemlich schnell (außer dem riesigen Speicherbedarf)
- Einfache Konfiguration in Python
Aber trotzdem, es gibt einige risse zu lösen. Unten sind meine Gedanken zu Bereichen, in denen sich StanfordNLP verbessern könnte:
- Die Größe der Sprachmodelle ist zu groß (Englisch ist von 1,9 GB, Chinesisch ~ 1,8 GB)
- Die Bibliothek benötigt viel Code, um Funktionen zu erzeugen. Vergleiche das mit NLTK, wo man schnell einen Prototypen schreiben kann; dies ist für StanfordNLP möglicherweise nicht möglich
- Derzeit fehlende Anzeigefunktionen. Es ist nützlich, es für Funktionen wie die Abhängigkeitsanalyse zu haben. StanfordNLP greift hier im Vergleich zu Bibliotheken wie SpaCy . zu kurz
Unbedingt überprüfen Offizielle StanfordNLP-Dokumentation.
Abschließende Anmerkungen
Es gibt noch eine Funktion die ich noch nicht ausprobiert habe. StanfordNLP ermöglicht Ihnen das Trainieren von Modellen auf Ihren eigenen annotierten Daten mit Word2Vec-Einbettungen / FastText. Ich würde es gerne in Zukunft erkunden und sehen, wie effektiv diese Funktionalität ist.. Ich werde den Artikel aktualisieren, wenn die Bibliothek etwas ausgereift ist.
Deutlich, StanfordNLP befindet sich im Beta-Stadium. Ab hier wird es nur noch besser, Dies ist also ein guter Zeitpunkt, um es zu verwenden: einen Vorteil gegenüber allen anderen bekommen.
Zur Zeit, die Tatsache, dass diese erstaunlichen Toolkits (CoreNLP) erreichen das Python-Ökosystem und Forschungsgiganten wie Stanford bemühen sich, ihre Software Open Source zu öffnen, Ich blicke optimistisch in die Zukunft.





