“Vorhersage ist sehr schwierig, vor allem wenn es um die zukunft geht”.
irgendwelche Ideen, nachdem Sie das schöne Zitat oben gelesen haben. In meinen vorherigen Artikeln habe ich verschiedene automatisierte Bibliotheken zur Automatisierung von maschinellem Lernen und NLP-Aufgaben erklärt. Ähnlich, In diesem Artikel, Ich erkläre "So automatisieren Sie die Zeitreihenvorhersage mit Auto-TS".
Auto-TS ist Teil von AutoML, das einige der Komponenten des maschinellen Lernprozesses automatisieren wird. Dies automatisiert Bibliotheken und hilft Nicht-Experten, ein grundlegendes Modell des maschinellen Lernens zu trainieren, ohne viel Wissen auf diesem Gebiet zu haben. Hier In diesem Artikel, Ich werde diskutieren, wie man die Implementierung eines Zeitreihen-Prognosemodells mit der Auto-TS-Bibliothek automatisieren kann.
Was ist Auto-TS??
Es ist eine Open-Source-Python-Bibliothek, die im Wesentlichen verwendet wird, um Zeitreihenprognosen zu automatisieren. Es trainiert automatisch mehrere Zeitreihenmodelle mit einer einzigen Codezeile, was uns hilft, das beste für unsere Problemstellung auszuwählen.
In der Open-Source-Python-Bibliothek, Auto-TS, auto-ts.Auto_TimeSeries () ist die Hauptfunktion, die Sie mit Ihren Zugdaten aufrufen. Später, Wir können wählen, welche Art von Modellen Sie wünschen, als statistisch basierte Modelle, ml oder FB. Wir können auch die Parameter anpassen, die automatisch das beste Modell basierend auf dem Scoring-Parameter auswählen, auf dem es basieren soll.. Es wird das beste Modell und ein Wörterbuch mit Vorhersagen für die von Ihnen erwähnte Anzahl von Forecast_periods zurückgegeben (Standard = 2).
Funktionen der Auto-TS-Bibliothek:
- Finden Sie das optimale Zeitreihen-Vorhersagemodell durch Optimierung der genetischen Programmierung.
- Trainiere naive Modelle, Statistiken, Maschinelles Lernen und Deep Learning, mit allen möglichen Hyperparametereinstellungen und Kreuzvalidierung.
- Führen Sie Datentransformationen durch, um mit unordentlichen Daten umzugehen, indem Sie die optimale NaN-Imputation und die Entfernung von Ausreißern lernen.
- Wahl der Kombination von Metriken für die Modellauswahl.
Installation:
pip install autots ODER pip3 installiere auto-ts ODER pip installieren git+git://github.com/AutoViML/Auto_TS
Anforderungen:
dask scikit-lernen FB Prophet Statistikmodelle pmdarima XGBoost
Bibliothek importieren mit:
aus auto_ts importieren auto_timeseries
In auto_timeseries verfügbare Parameter:
model = auto_timeseries( score_type="rmse", time_interval="Monat", non_seasonal_pdq=Keine, Saisonalität=Falsch, saisonal_period=12, model_type=['Prophet'], ausführlich=2)
Sie können die Parameter optimieren und die Änderung der Modellleistung analysieren. Weitere Details zu den Parametern, klicke auf hier.
Verwendeter Datensatz:
Hier habe ich die verwendet Kurs der Amazon-Aktie Datensatz für Januar 2006 bis Januar 2018, welches von Kaggle heruntergeladen wird. Diese Bibliothek bietet nur Vorhersagemodelle für Zugzeitreihen. Der Datensatz muss eine Datums- oder Zeitformatspalte haben.
Anfänglich, Laden Sie das Zeitreihen-Dataset mit einer Datetime-Spalte:
df = pd.read_csv("Amazon_Stock_Price.csv", usecols =['Datum', 'Nah dran'])
df['Datum'] = pd.to_datetime(df['Datum'])
df = df.sort_values('Datum')
Jetzt, alle Daten in Test- und Trainingsdaten aufteilen:
train_df = df.iloc[:2800] test_df = df.iloc[2800:]
Jetzt, wir visualisieren die Testteilung des Zuges:
train_df.Close.plot(Feigengröße=(15,8), Titel="AMZN-Aktienkurs", Schriftgröße=14, Etikett="Bahn") test_df.Close.plot(Feigengröße=(15,8), Titel="AMZN-Aktienkurs", Schriftgröße=14, Etikett="Prüfen") plt.legende() plt.grid() plt.zeigen()
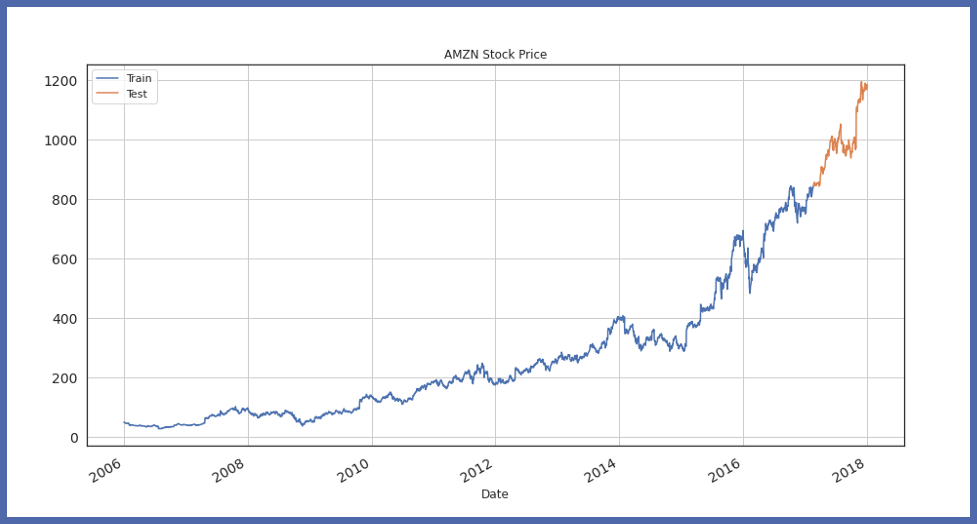
Jetzt, Lassen Sie uns das Auto-TS-Modellobjekt initialisieren und die Trainingsdaten anpassen:
model = auto_timeseries(Forecast_Periode=219, score_type="rmse", time_interval="D", model_type="Beste") model.fit(traindata= train_df, ts_column="Datum", Ziel="Nah dran")
Vergleichen wir nun die Genauigkeit verschiedener Modelle:
model.get_leaderboard() model.plot_cv_scores()
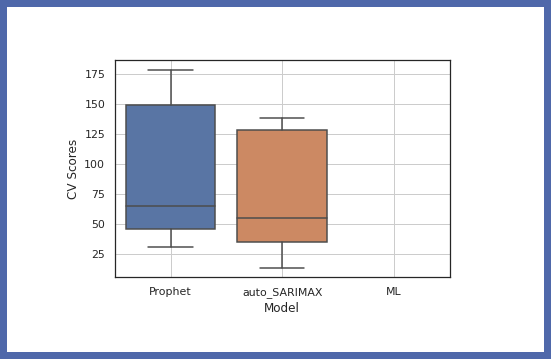
Jetzt testen wir unser Modell mit Testdaten:
future_predictions = model.predict(Testdaten=219)
Schließlich, Sehen Sie sich den Wert und die Vorhersage der Testdaten an:
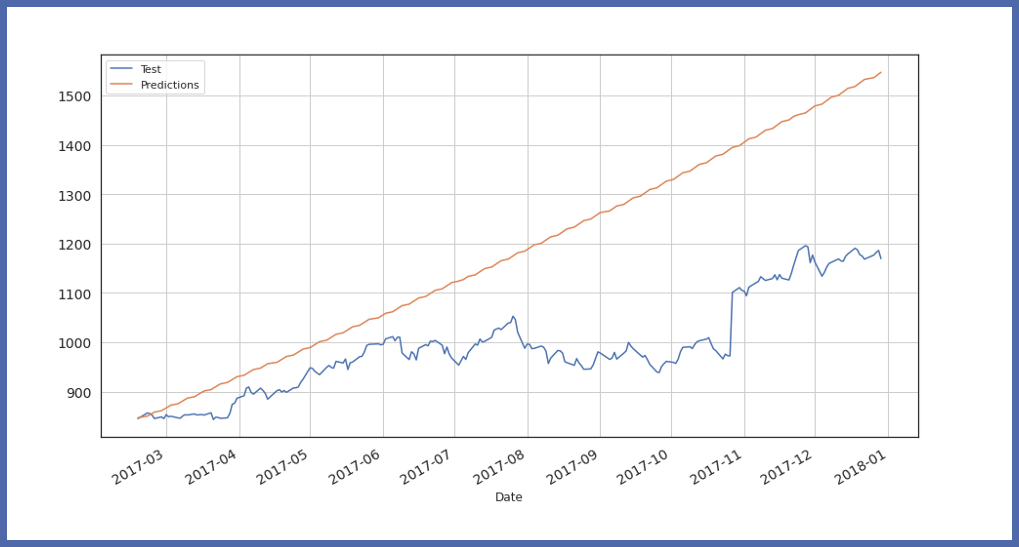
In auto_timeseries verfügbare Parameter:
model = auto_timeseries( score_type="rmse", time_interval="Monat", non_seasonal_pdq=Keine, Saisonalität=Falsch, saisonal_period=12, model_type=['Prophet'], ausführlich=2)
Parameter verfügbar in model.fit ():
model.fit( traindata=train_data, ts_column=ts_column, Ziel=Ziel, cv=5, sep="," )
In model.predict verfügbare Parameter ():
Vorhersagen = model.predict( testdata = kann entweder ein Datenrahmen oder eine ganze Zahl sein, die für den Prognosezeitraum steht, Modell="Beste" oder eine beliebige andere Zeichenfolge, die für das trainierte Modell steht )
Sie können mit all diesen Parametern spielen und die Leistung unseres Modells analysieren und dann das am besten geeignete Modell für Ihre Problemstellung auswählen.. Sie können alle diese Parameter im Detail überprüfen, indem Sie auf klicken hier.
Fazit:
In diesem Artikel, Ich habe besprochen, wie das Zeitreihenmodell in einer Zeile Python-Code automatisiert werden kann. Auto-TS führt Datenvorverarbeitung durch, da es Ausreißer aus Daten entfernt und unordentliche Daten verarbeitet, indem es die optimale NaN-Imputation lernt. Mit nur einer Codezeile, Initialisieren des Auto-TS-Objekts und Anpassen der Zugdaten, trainiert automatisch mehrere Zeitreihenmodelle wie ARIMA, SARIMAX, FB Prophet, WO, und generiert das leistungsstärkste Modell, das für unsere Problemstellung geeignet ist. Das Ergebnis des Modells scheint von der Größe des Datensatzes abzuhängen. Wenn wir versuchen, die Größe des Datensatzes zu erhöhen, das Ergebnis kann sich definitiv verbessern.
EndNote
Hoffe dir hat dieser Artikel gefallen. Irgendeine Frage? Habe ich was verpasst? Bitte, kontaktiere mich LinkedIn Oder hinterlasse unten einen Kommentar. Und schlussendlich, … Keine Notwendigkeit zu sagen,
Danke fürs Lesen!
Gesundheit!!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





