Einführung
Stacking ist eine festgelegte Lerntechnik, die Vorhersagen für mehrere Knoten verwendet (zum Beispiel, kNN, Entscheidungsbäume oder SVM) So erstellen Sie ein neues Modell. Dieses endgültige Modell wird verwendet, um Vorhersagen für das Testdataset zu treffen..
***Video***
Notiz: Wenn Sie mehr daran interessiert sind, Konzepte in einem audiovisuellen Format zu lernen, wir haben diesen vollständigen Artikel im Video unten erklärt. Wenn dies nicht der Fall ist, du kannst weiterlesen.
Dann, Beim Stapeln nehmen wir die Trainingsdaten und führen sie über mehrere Modelle hinweg aus., M1 bis Mn. Und all diese Modelle werden normalerweise als Basic Learner oder Basic Models bezeichnet.. Und wir generieren Vorhersagen aus diesen Modellen.
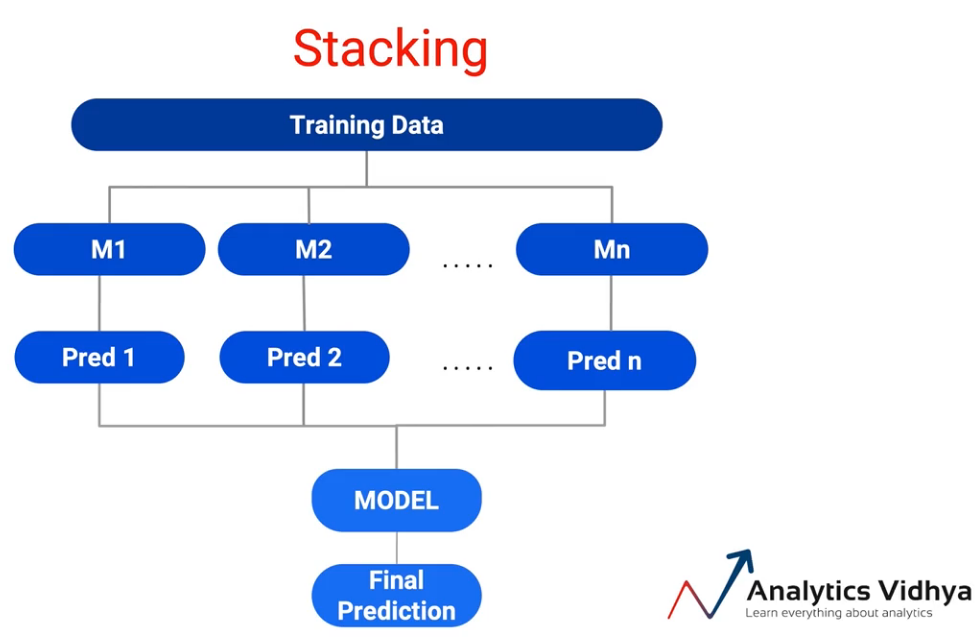
Deswegen, Pred 1 a Pred n sind die Vorhersagen, und diese Eingabe wird an das Modell gesendet, anstelle der maximalen oder durchschnittlichen Stimme. Und das Modell nimmt sie als Eingaben und gibt uns die endgültige Vorhersage.. Und je nachdem, ob es sich um ein Regressionsproblem oder ein Klassifizierungsproblem handelte, Ich kann wählen, welches das richtige Modell dafür ist. Dann, Das Stapelkonzept ist sehr interessant und eröffnet viele Möglichkeiten.
Aber das Stapeln auf diese Weise eröffnet eine große Gefahr von Übereinstellung Das Modell, weil ich alle meine Trainingsdaten verwende, um das Modell zu erstellen und auch Vorhersagen darauf zu erstellen.
Dann, die Frage ist, Kann ich schlauer werden und Trainings- und Testdaten auf andere Weise nutzen, um die Gefahr einer Überanpassung zu verringern?? Und das ist es, was wir in diesem speziellen Artikel diskutieren werden.. Dann, Was ich behandeln werde, ist eine der beliebtesten Arten des Stapelns..
Nehmen wir an, wir haben diese Trainings- und Testdatensätze.:
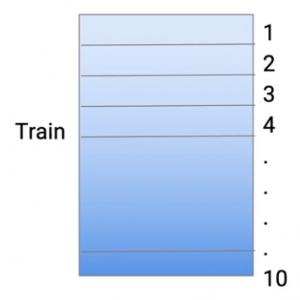
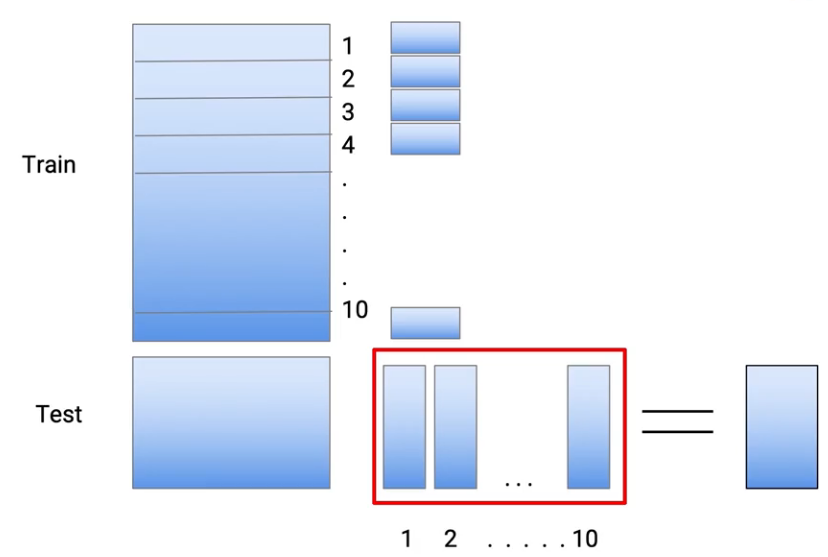
Und um Überanpassungen zu reduzieren, Ich nehme meine Zugdaten und teile sie auf in 10 Teile. Dies geschieht also zufällig.. Also nehme ich den gesamten Datensatz aus dem Zug und verwandle ihn in 10 Kleinere Datensätze.
Und nun, um die Überanpassung zu reduzieren, Was ich tue, ist, mein Modell in 9 davon 10 Teile und ich mache meine Vorhersagen im zehnten Teil. Dann, In diesem speziellen Fall, Ich mache meinen Teil zum Training 2 zum Teil 10. Und nehmen wir an, ich verwende den Entscheidungsbaum als meine Modellierungstechniken., Also trainiere ich mein Modell und mache meine Vorhersagefälle., die in der Rolle waren 1-
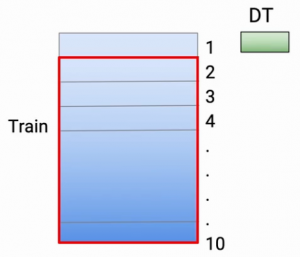
Dann, Das Teil 1 Es ist im Grunde eine Vorhersage. Dann, Die grüne Farbe stellt die Vorhersage dar, was ich in den Punkten gemacht habe, die sich im Dataset befanden 1, Ich mache die gleiche Übung für jeden dieser Teile. Dann, für das Teil 2, Ich trainiere mein Modell mit dem Teil neu 1 der Daten und des Teils 3 zum Teil 10 von Dateien. Und ich mache meine Vorhersagen im zweiten Teil.
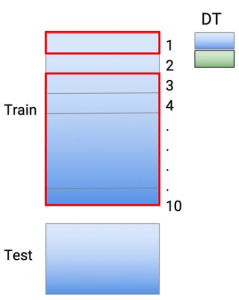
Dann, Hier entlang, Ich mache meine Vorhersagen für all diese 10 Teile. Dann, Zusammenfassend, Jede dieser Vorhersagen stammt aus einem Modell, das nicht die gleichen Zugdatenpunkte gesehen hat.. Und um ein Testdataset zu erstellen, Ich nutze alle Zugdaten. So, nochmal, Ich trainiere das Modell, die für den gesamten Zugdatensatz durchgeführt wird, und ich mache Vorhersagen im Test.
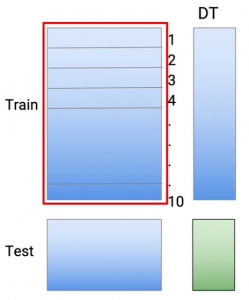
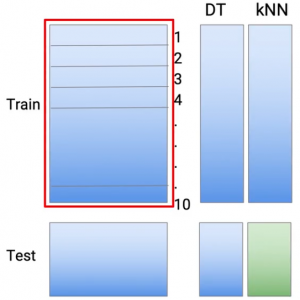
Dann, wenn Sie darüber nachdenken, Wir erstellen 10 Modelle zum Abrufen von Vorhersagen zu Zugdaten und elftes Modell, um Vorhersagen zu Testdaten zu erhalten. Und das sind alles Modelle von Entscheidungsbäumen.. Dann, Dies gibt mir eine Reihe von Vorhersagen oder das Äquivalent der Vorhersagen, die aus dem M1-Modell stammen..
Ich mache das gleiche mit einer zweiten Modellierungstechnik. Sagen wir KNN. Dann, nochmal, Das gleiche Konzept, dass ich Vorhersagen Teil für Teil der Partei mache 1 zum Teil 10. Und wieder, So rufen Sie Vorhersagen im Testdataset ab, Ausführung des elften Modells KNN.
Ich mache dasselbe mit dem dritten Teil, was eine lineare oder logistische Regression sein kann, abhängig von der Art des Problems, das Sie behandeln.
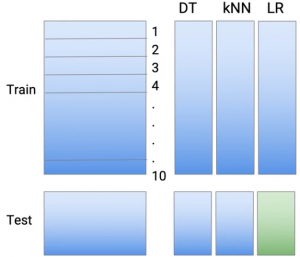
Dann, Dies sind in gewisser Weise meine neuen Grundlerner. Ich habe jetzt Vorhersagen von drei verschiedenen Arten von Modellierungstechniken., Aber ich habe die Gefahr einer Überanpassung vermieden.
Jetzt könnte ich fragen, Warum verwende ich 10? Und was ist sakrosankt an dieser Zahl? 10? Es gibt also nichts Unantastbares an der Zahl 10. Es basiert auf der Tatsache, dass, wenn ich etwas weniger als zwei oder drei verwende,, Es bringt mir nicht so viel Nutzen. Und wenn ich etwas anderes nehme, sagen wir 15 Ö 20, Dann erhöht sich meine Anzahl der Berechnungen. Also nur ein Kompromiss zwischen der Reduzierung der Überanpassung und der geringen Erhöhung meiner Komplexität.. Sie können auch fortfahren mit 7 du 8, Es gibt nichts Spezifisches, das mit 10.
Wählen Sie also gerne Ihre eigene Nummer. Es könnten sieben sein, könnte acht sein, Aber ich sehe normalerweise Leute, die zwischen fünf und vielleicht 11, 12, je nach Situation. Und Sie werden das immer wieder zusammen sehen, dass es Richtlinien gibt., Aber am Ende des Tages, Sie müssen Entscheidungen treffen, die darauf basieren, wie viele Ressourcen Sie haben, wie viel Komplexität es gibt und was sind Ihre Produktionsmuster und Was können Sie sich in der Produktion leisten?
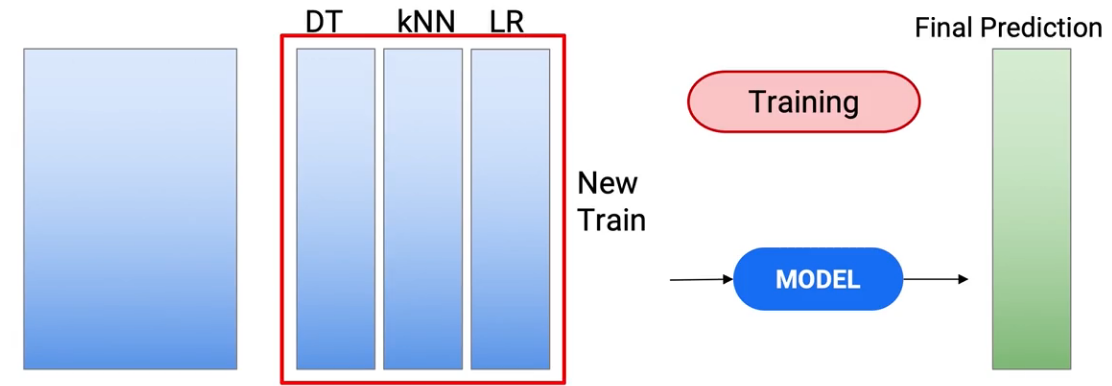
Also habe ich genommen 10 als Beispiel, Sie können aber auch jede andere Nummer verwenden. Umstapeln. Wir hatten also diese Vorhersagen von drei verschiedenen Arten von Modellen.. Dies wird also mein neuer Zugdatensatz.
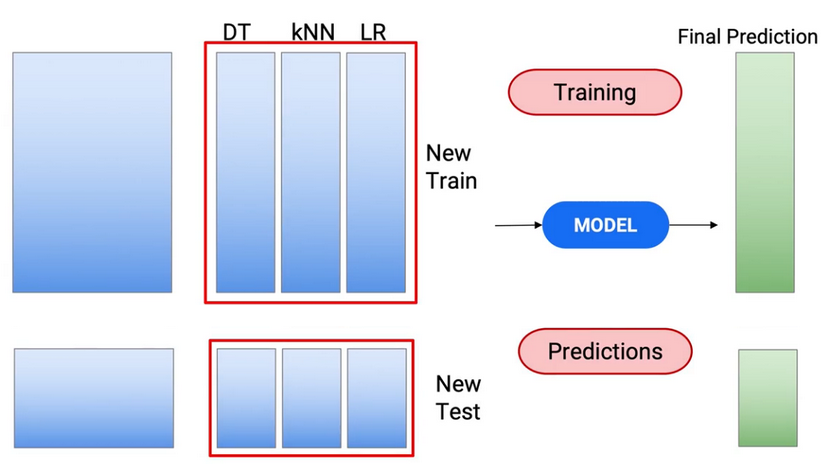
und die Vorhersagen, die ich in meinem Test hatte, werden zu meinem neuen Testdatensatz.. Und jetzt erstelle ich ein Modell in diesen Test- und Trainingsdatensätzen, um zu meinen endgültigen Vorhersagen zu gelangen..

Also haben wir diesen neuen Zug verwendet, um das Zugmodell zu erstellen und Vorhersagen in meinem Test zu treffen, um meine endgültigen Testvorhersagen zu erhalten..

Dann, Dies ist die beliebteste Variante des Stapelns, Einsatz in der Industrie. Schauen wir uns einige weitere Variationen an, die verwendet werden können:
1. Verwenden Sie die Funktionen, die zusammen mit den neuen Vorhersagen bereitgestellt werden.
So aktuell, wenn Sie darüber nachdenken, Wir haben die neuen Vorhersagen nur als Merkmale unseres endgültigen Modells verwendet.. Was ich auch tun kann, ist, die ursprünglichen Funktionen zusammen mit der neuen Funktion aufzunehmen.. Dann, Anstatt diese rote Box zum Trainieren und Testen zu verwenden,
Ich kann die volle Funktion nutzen, um mein Modell zu trainieren, Die Funktionen, die ursprünglich vorhanden waren und die Vorhersagen, die herauskamen. Also öffne ich mein Zug-Dataset, um weitere Features aufzunehmen..
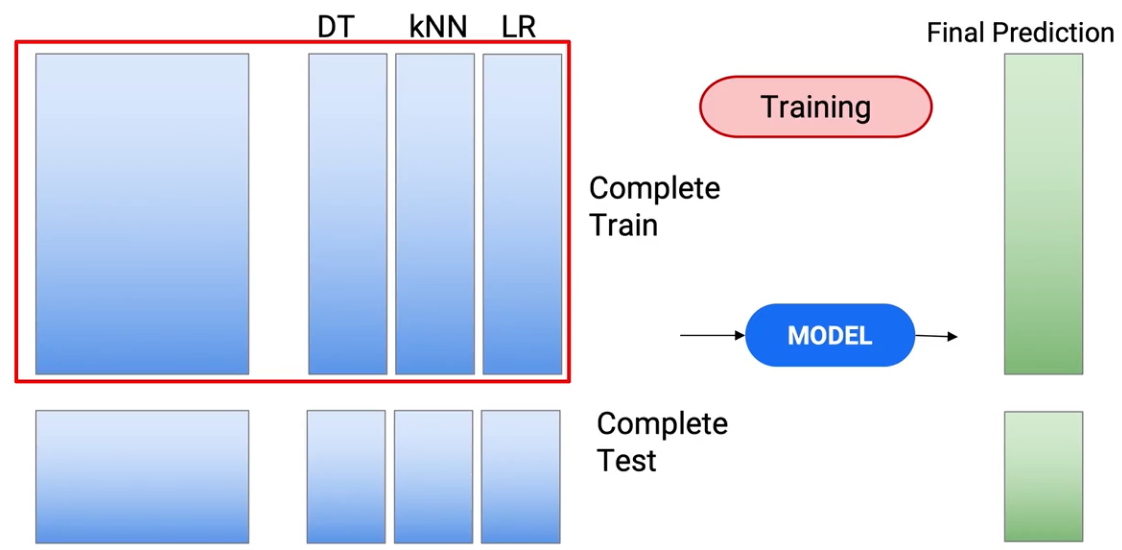
Und ich mache dasselbe mit Tests.. Und das gibt mir eine neue Reihe von Vorhersagen..

Das ist also eine Möglichkeit, wie auch Stacking implementiert wird..
2. Generieren Sie mehrere Vorhersagen zum Testen und Hinzufügen
Die zweite Möglichkeit, Stacking zu implementieren, besteht darin, mehrere Vorhersagen im Testdataset zu treffen und diese zu aggregieren.. Nochmal, Wenn Sie sich erinnern, was wir getan haben, Wir erstellen diese 10 Vorhersagen für jede dieser Zugdateien und wir verwenden eines der vollständigen Modelle, um die Vorhersagen für das Testdataset zu erstellen. Jetzt, Was Sie auch tun könnten, ist dies zu tun, um 10, Jeder dieser 10 Modelle, die geschaffen wurden, und fügen Sie sie dann anstelle des gesamten Modells hinzu.
Dann, nochmal, die gleichen Modelle, die ich verwendet habe, um die Vorhersagen für 1, 2 und jedes dieser Datensätze, Ich verwende dasselbe Modell, um meine Vorhersagen für den Test zu erstellen. Und dann habe ich sie gemittelt, um zu meinem letzten Test zu kommen., Was ich für das endgültige Modell verwenden werde.
Nochmal, Wie gesagt, Dies sind alles verschiedene Modelle und verschiedene Möglichkeiten, Stapeln und Montieren zu implementieren.. Sie haben völlige Freiheit, kreativ zu sein und neue Wege zu finden, um Überanpassungen zu reduzieren. Deswegen, Die übergeordneten Ziele bestehen darin, sicherzustellen, dass:
- Unsere Genauigkeit steigt
- Komplexität bleibt so gering wie möglich
- Und wir vermeiden Überanpassung
Wann immer Sie etwas tun, um diese drei Ziele zu erreichen, Es wäre eine gültige Strategie, Wahrheit?
3. Erhöhen Sie die Anzahl der Ebenen für das Stapeln von Modellen.
Dann, Die dritte Stapelvariante ist, wobei, Anstatt ein einzelnes Modell in allen Vorhersagen beizubehalten, Am Ende habe ich Modellebenen erstellt. Dann, zum Beispiel, In diesem speziellen Fall-
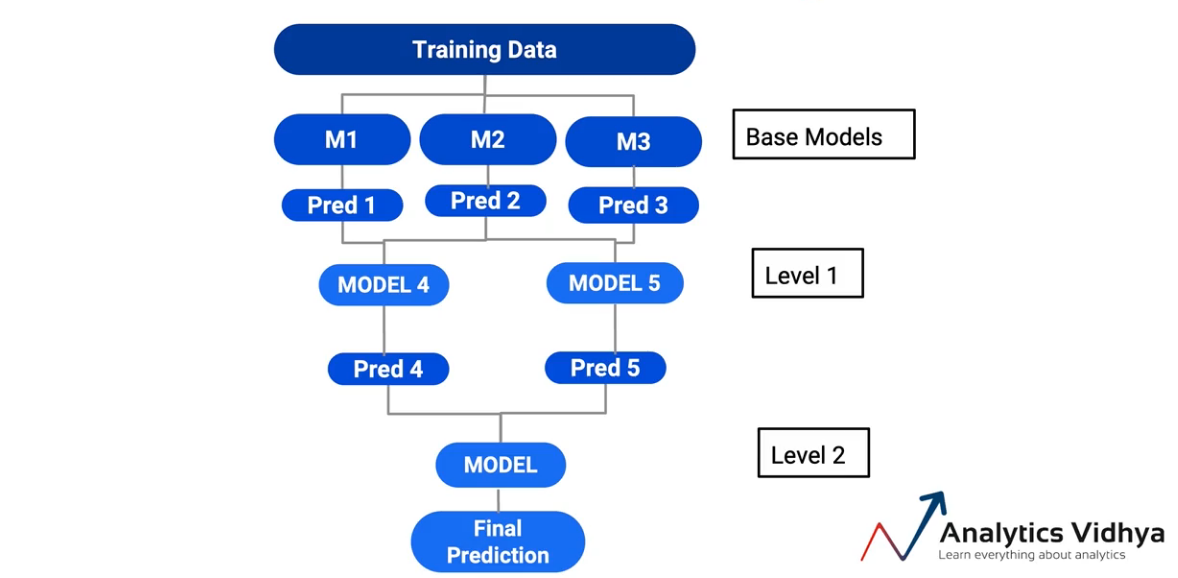
Ich nahm Vorhersagen von M1 und M2 und übergab sie an ein anderes Modell., M4. Ähnlich, Vorhersagen aus dem Modell übernommen 2 und das Modell 3 und fütterte sie dem Modell 5. Und das endgültige Modell war tatsächlich ein Modell im Modell 4 und das Modell 5. Also habe ich zwei Ebenen von Modellen in meinen Basismodellen erstellt.. Und wieder, ist eine gültige Methode zum Stapeln. Und je nach Situation, Sie können diese auswählen.
Das waren also die Stapelvarianten, Wie gesagt, solange Sie sicherstellen, dass alle drei Montageanforderungen erfüllt sind, die wir: Stellen Sie sicher, dass Sie Ihre Modelle nicht überpassen, Stellen Sie sicher, dass die Modelle so einfach wie möglich gehalten werden, und erhöht Ihre Genauigkeit. Denken Sie daran, dass Sie beim Stapeln oder einer anderen Set-Modellierung so kreativ wie möglich sein können, wenn Sie nur diese drei Punkte berücksichtigen..
Abschließende Anmerkungen
Ich habe einige Varianten zum Stapeln abgedeckt. Fühlen Sie sich also frei, sie zu verwenden. Und mit diesen drei Einschränkungen oder mit diesen Gedanken., Jede Variation, die Sie sich vorstellen können, wäre eine gültige Variation.
Wenn Sie Ihre Data Science-Reise beginnen möchten und alle Themen unter einem Dach haben möchten, deine Suche endet hier. Werfen Sie einen Blick auf den zertifizierten KI- und ML-BlackBelt von DataPeaker Plus Programm
Wenn du irgendeine Frage hast, lass es mich im Kommentarbereich wissen!





