introduction
Dépôts GitHub et discussions Reddit: les deux plates-formes ont joué un rôle clé dans mon apprentissage automatique voyage. Ils m'ont aidé à développer mes connaissances et ma compréhension des techniques d'apprentissage automatique et mon sens des affaires.
GitHub et Reddit me tiennent également au courant des derniers développements en matière d'apprentissage automatique., Un must pour quiconque travaille dans ce domaine!!
Et si vous êtes programmeur, bon, GitHub est comme un temple pour vous. Vous pouvez facilement télécharger le code et le reproduire sur votre machine. Cela rend encore plus facile l'apprentissage de nouvelles idées et la construction d'un ensemble de compétences diversifié..

Je suis ravi de choisir les meilleurs dépôts GitHub et les discussions Reddit de ce mois-ci. Les fils de discussion Reddit que j'ai présentés concernent à la fois le côté technique de apprentissage automatique ainsi que celui lié à la course. Cette capacité à combiner les deux est ce qui sépare les experts en apprentissage automatique des amateurs..
Vous trouverez ci-dessous les articles mensuels que nous avons couverts jusqu'à présent dans cette série:
Alors, Au travail pour mars!
Dépôts GitHub

Si je devais choisir une des raisons de ma fascination pour vision par ordinateur, seraient des GAN (Réseaux accusatoires génératifs). Ils ont été inventés par Ian Goodfellow il y a quelques années à peine et sont devenus tout un corpus de recherche.. Art d'IA récent que vous avez vu dans les nouvelles? Tout fonctionne avec GAN.

DeepMind a proposé le concept BigGAN l'année dernière, mais nous avons attendu un certain temps pour une implémentation PyTorch. Ce référentiel comprend également des modèles préalablement formés (128 × 128, 256 × 256 Oui 512 × 512). Vous pouvez l'installer en une seule ligne de code:
pip installer pytorch-pretrained-biggan
Et si vous souhaitez lire l'intégralité de l'article de recherche BigGAN, visite ici.
La capacité de travailler avec des données d'image devient un trait déterminant pour toute personne intéressée par l'apprentissage en profondeur. L'avènement et l'essor rapide des algorithmes de vision par ordinateur ont joué un rôle important dans cette transformation.. Vous ne serez pas surpris d'apprendre que NVIDIA est l'un des leaders dans ce domaine..
Jetez un œil à leurs développements depuis 2018:
Et maintenant, les gens de NVIDIA ont créé une autre version incroyable: la capacité de synthétiser des images photoréalistes avec une conception sémantique d'entrée. Qu'est-ce que c'est bon? La comparaison suivante fournit une bonne illustration:

SPADE a surpassé les méthodes existantes dans le populaire jeu de données COCO. Le référentiel que nous avons lié ci-dessus abritera l'implémentation PyTorch et les modèles préalablement formés pour cette technique (assurez-vous de le mettre en signet).
Cette vidéo montre à quel point SPADE fonctionne bien dans 40.000 images prises sur Flickr:
Ce référentiel est basé sur le ‘Suivi et segmentation rapides des objets en ligne: une approche fédératrice‘ papier. Voici un exemple de résultat utilisant cette technique:

Impressionnant! La technique, appelé SiamMask, c'est assez simple, polyvalent et extrêmement rapide. Oh, Ai-je mentionné que le suivi des objets se fait en temps réel? Cela a certainement attiré mon attention. Ce référentiel contient également des modèles pré-entraînés afin que vous puissiez commencer.
Le travail sera présenté lors de la prestigieuse conférence CVPR 2019 (Vision par ordinateur et reconnaissance de formes) en juin. Les auteurs ont démontré leur approche dans la vidéo suivante:
Avez-vous déjà travaillé sur un projet de détection de pose? Je l'ai fait et laisse moi te dire que c'est excellent. C'est un témoignage des progrès que nous avons réalisés en tant que communauté en matière d'apprentissage en profondeur.. Qui aurait pensé il y a 10 années que nous serions en mesure de prédire le prochain mouvement corporel d'une personne?
Ce référentiel GitHub est un PyTorche implémentation de ‘Apprentissage auto-supervisé de la pose humaine 3D à l'aide de la géométrie multi-vues‘ papier. Les auteurs ont mis au point une nouvelle technique appelée EpipolairePose, une méthode d'apprentissage auto-supervisé pour estimer la pose d'un être humain en 3D.

La technique EpipolarPose estime les poses 2D à partir d'images multi-vues pendant la phase d'entraînement. Utilisez ensuite la géométrie épipolaire pour générer une pose 3D. Ce, en même temps, utilisé pour entraîner l'estimateur de pose 3D. Ce processus est illustré dans l'image ci-dessus.
Cet article a également été accepté à la conférence CVPR 2019. Formez-vous pour être une excellente gamme!!
Il s'agit d'un référentiel unique à bien des égards. C'est un modèle d'apprentissage en profondeur open source pour protéger votre vie privée. L'ensemble du concept de DeepCamera est basé sur l'apprentissage automatique automatisé (AutoML). Donc, vous n'avez même pas besoin d'expérience en programmation pour former un nouveau modèle.

DeepCamera fonctionne sur les appareils Android. Vous pouvez également intégrer le code avec des caméras de surveillance. Il y a BEAUCOUP que vous pouvez faire avec le code DeepCamera, qui inclus:
- La reconnaissance faciale
- Détection facial
- Contrôle depuis l'application mobile
- Détection d'objets
- Détection de mouvement
Et plein d'autres choses. Construire votre propre modèle basé sur l'IA n'a jamais été aussi simple !!
Discussions sur Reddit

J'ai divisé les discussions Reddit de ce mois-ci en deux catégories:
- Le côté technique de l'apprentissage automatique
- Discussions liées à la carrière en apprentissage automatique (rôles et emplois)
Commençons par l'aspect technique.
Les data scientists sont fascinés par les travaux de recherche. Nous voulons les lire, les coder et peut-être même en écrire un à partir de zéro. Ne serait-il pas cool de présenter votre propre document de recherche lors d'une conférence ML de premier plan ??

J'appartiens certainement à la catégorie des “Je veux écrire un article de recherche”. Ce débat, lancé par un chercheur chevronné, se penche sur les meilleures pratiques à suivre lors de la rédaction d'un article de recherche. Voici beaucoup d'informations et d'expérience, A lire absolument pour nous tous!
Voici la Dépôt GitHub avec les meilleurs conseils, conseils et idées en un seul endroit. Traitez ces conseils comme un ensemble de lignes directrices et non comme des règles gravées dans le marbre.
Comment mettre en production vos modèles d'apprentissage automatique entraînés? Comment les implémentez-vous? Ce sont des questions TRÈS courantes auxquelles vous serez confronté lors de votre entretien en science des données (et le travail, bien sûr). Si vous n'êtes pas sûr de ce que c'est, Je vous suggère de le lire MAINTENANT.
Ce fil de discussion concerne une bibliothèque open source qui convertit vos modèles d'apprentissage automatique en code natif (C, Python, Java) pas de dépendances. Il faut faire défiler le fil, car il y a des questions courantes que l'auteur a abordées en détail.
Vous pouvez trouver le code complet dans ce référentiel GitHub. Vous trouverez ci-dessous la liste des modèles actuellement pris en charge par cette bibliothèque:
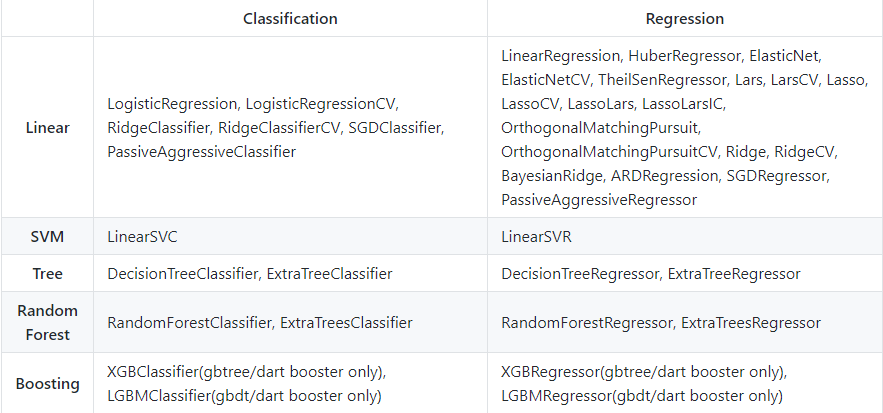
Déplaçons-nous maintenant et voyons quelques discussions sur la carrière de l'apprentissage automatique. Ceux-ci sont applicables à TOUS les professionnels de l'apprentissage automatique, à la fois aspirant et établi.
L'émergence du machine learning automatisé sera-t-elle un inconvénient pour le domaine lui-même ?? C'est une question que la plupart d'entre nous se posent.. La plupart des articles que je rencontre prédisent tout pessimisme. Certains prétendent même que les data scientists ne seront pas nécessaires dans 5 ans!

La source: Thémocratie
L'auteur de ce fil fait un excellent argument contre le consensus général. La science des données est très peu susceptible de disparaître en raison de l'automatisation.
La discussion soutient à juste titre que la science des données ne concerne pas seulement la modélisation des données. C'est juste le 10% de l'ensemble du processus. Une partie importante du cycle de vie de la science des données est l'intuition humaine derrière les modèles. Nettoyage des données, la visualisation des données et une touche de logique sont ce qui motive tout ce processus.
Voici un bijou et un argument solide qui a attiré mon attention:
Nous développons toutes sortes de logiciels de statistiques au cours du siècle dernier et, cependant, n'a pas remplacé les statisticiens.
Voulez-vous décrocher votre premier poste en science des données? Trouvez-vous que c'est un processus accablant? J'ai été là. C'est l'un des plus grands obstacles à surmonter lors de nos voyages respectifs en science des données..
Je voulais donc souligner ce fil particulier. C'est une discussion vraiment révélatrice, où les professionnels de la science des données et les débutants discutent de la façon d'entrer dans ce domaine. L'auteur de l'article propose des réflexions approfondies sur le processus de recherche d'emploi en science des données ainsi que des conseils pour effacer chaque série d'entretiens..

Une phrase qui s'est vraiment démarquée de cette discussion:
Rappelles toi, l'augmentation des demandes d'entretien et l'augmentation des connaissances ne sont pas seulement une corrélation, c'est une causalité. En postulant, Apprendre quelque chose de nouveau chaque jour.
Un DataPeaker, notre objectif est de vous aider à décrocher votre premier poste en science des données. Consultez les ressources incroyables ci-dessous pour vous aider à démarrer:
Connaissance du domaine: cet ingrédient clé dans la recette globale du data scientist. Souvent, les aspirants scientifiques des données l'ignorent ou l'interprètent mal. Et cela se traduit souvent par des rejets dans les entretiens.. Ensuite, Comment pouvez-vous développer votre sens des affaires pour compléter vos compétences existantes en science des données techniques?
Cette discussion Reddit offre des informations utiles. La capacité à traduire vos idées et vos résultats en termes commerciaux est VITALE. La plupart des acteurs auxquels vous serez confronté dans votre carrière ne comprendront pas le jargon technique..
Voici mon choix préféré de la discussion:
Vous devez mieux connaître vos partenaires commerciaux. Découvrez ce qu'ils font au quotidien, quels sont vos processus, comment ils génèrent les données que vous allez utiliser. Si vous comprenez comment X et Y voient, vous serez mieux en mesure de les aider lorsqu'ils viennent vous voir avec des problèmes.
Chez DataPeaker, nous croyons fermement à la construction d'un état d'esprit structuré. Nous avons rassemblé notre expérience et nos connaissances sur ce sujet dans le cours complet ci-dessous:
Ce cours contient plusieurs études de cas qui vous aideront également à vous faire une idée de la façon dont les entreprises fonctionnent et pensent..
Remarques finales
J'ai particulièrement apprécié les discussions sur Reddit du mois dernier. Je vous invite à en savoir plus sur le fonctionnement de l'environnement de production dans un projet de machine learning. Maintenant considéré comme presque obligatoire pour un data scientist, donc tu ne peux pas t'éloigner de lui.
Vous devriez également participer à ces discussions Reddit. Le défilement passif est bon pour acquérir des connaissances, mais ajouter votre propre point de vue aidera également les autres candidats. C'est un sentiment intangible, mais vous apprécierez et apprécierez plus vous aurez d'expérience.
Quelle discussion avez-vous trouvé la plus révélatrice? Et quel référentiel GitHub s'est démarqué pour vous? Laissez-moi savoir dans la section commentaire ci-dessous!!





