introduction
Si je devais choisir une plateforme qui me tient au courant des derniers développements en Science des données Oui apprentissage automatique – ce serait GitHub. La grande échelle de GitHub, combiné avec la puissance des super data scientists du monde entier, en fait une plateforme obligatoire pour toute personne intéressée par ce domaine.
Pouvez-vous imaginer un monde où les bibliothèques et les frameworks d'apprentissage automatique comme BERT, StanfordPNL, TensorFlow, PyTorche, etc. n'étaient pas open source? C'est impensable! GitHub a démocratisé l'apprentissage automatique pour les masses, exactement en accord avec ce que nous croyons en DataPeaker.
C'est l'une des principales raisons pour lesquelles nous avons lancé cette série GitHub couvrant les packages et bibliothèques d'apprentissage automatique les plus utiles en janvier. 2018.

Ainsi que, nous avons également couvert les discussions sur Reddit qui, selon nous, sont pertinentes pour tous les professionnels de la science des données. Ce mois-ci n'est pas différent. J'ai sélectionné les cinq meilleurs débats du mois de mai, qui se concentre sur deux choses: des techniques d'apprentissage automatique et des conseils professionnels de data scientists experts.
Vous pouvez également consulter les référentiels GitHub et les discussions Reddit que nous avons couvertes tout au long de cette année.:
Principaux dépôts GitHub (mai de 2019)


L'interprétabilité est une chose ÉNORME dans l'apprentissage automatique en ce moment. Être capable de comprendre comment un modèle a produit le résultat qu'il a produit, un aspect fondamental de tout projet de machine learning. En réalité, nous avons même fait un podcast avec Christoph Molar sur le ML interprétable que vous devriez vérifier.
InterpretML est un package open source de Microsoft pour former des modèles interprétables et expliquer les systèmes de boîte noire. Microsoft l'a mieux exprimé lorsqu'il a expliqué pourquoi l'interprétabilité est essentielle:
- Modèles de débogage: Pourquoi mon modèle a-t-il fait cette erreur?
- Détection des biais: Est-ce que mon modèle discrimine?
- Coopération homme-IA: Comment puis-je comprendre et faire confiance aux décisions du modèle?
- Conformité normative: Mon modèle répond-il aux exigences légales?
- Applications à haut risque: Sanitaire, financier, judiciaire, etc.
L'interprétation du fonctionnement interne d'un modèle d'apprentissage automatique devient plus difficile à mesure que la complexité augmente. Avez-vous déjà essayé de démonter et de comprendre un ensemble de plusieurs modèles? Il faut beaucoup de temps et d'efforts pour le faire.
Nous ne pouvons pas simplement aller voir notre client ou notre direction avec un modèle complexe sans pouvoir expliquer comment il a produit un bon score. / précision. C'est un aller simple retour à la planche à dessin pour nous.
Les gens de Microsoft Research ont développé l'algorithme Explainable Boosting Machine (EBM) pour aider à l'interprétation. Cette technique MBE a une haute précision et intelligibilité: Le Saint-Graal.
L'interprétation du ML ne se limite pas à l'utilisation d'EBM. Il prend également en charge des algorithmes comme LIME, modèles linéaires, arbres de décision, entre autres. Comparer les modèles et choisir celui qui convient le mieux à notre projet n'a jamais été aussi simple !!
Vous pouvez installer InterpretML en utilisant le code suivant:
pip installer numpy scipy pyscaffold pip install -U interprète
Google Research fait une autre apparition dans notre série mensuelle Github. Pas de surprises: ils ont la plus grande puissance de calcul de l'entreprise et l'utilisent dans l'apprentissage automatique.

Votre dernière version open source, appelé Tensor2Robot (T2R) c'est assez impressionnant. T2R est une bibliothèque de formation, évaluation et inférence de réseaux de neurones profonds à grande échelle. Mais attendez, a été développé avec un objectif précis en tête. Il est conçu pour les réseaux de neurones liés à la perception et au contrôle robotiques.
Aucun prix pour deviner le framework d'apprentissage en profondeur sur lequel Tensor2Robot est construit. C'est comme ca, TensorFlow. Tensor2Robot est utilisé dans Alphabet, L'organisation mère de Google.
Voici quelques projets mis en œuvre avec Tensor2Robot:
TensorFlow 2.0, la version TensorFlow (TF) le plus attendu cette année, officiellement lancé le mois dernier. Et j'avais hâte de mettre la main dessus !!

Ce référentiel contient des implémentations TF de plusieurs modèles génératifs, comprenant:
- Réseaux génératifs antagonistes (GAN)
- Codeur de voiture
- Encodeur variationnel (Hélas)
- VAE-GAN, entre autres.
Tous ces modèles sont implémentés dans deux ensembles de données que vous connaissez bien.: Mode MNIST et NSYNTH.
La meilleure partie? Toutes ces implémentations sont disponibles dans un Jupyter Notebook !! Vous pouvez donc le télécharger et l'exécuter sur votre propre ordinateur ou l'exporter vers Google Colab. Le choix vous appartient et TensorFlow 2.0 est là pour que vous compreniez et utilisiez.
![]()
Un référentiel de séries temporelles! Je n'ai pas rencontré de nouveau développement de série temporelle depuis un bon moment.
STUMPY est une bibliothèque puissante et évolutive qui nous aide à effectuer des tâches d'exploration de données de séries chronologiques. STUMPY est conçu pour calculer un profil matriciel. Je peux te voir te demander: Qu'est-ce que c'est qu'un profil matriciel? Bon, ce profil matriciel est un vecteur qui stocke la distance euclidienne normalisée z entre toute sous-séquence d'une série temporelle et son plus proche voisin.
Voici quelques tâches d'exploration de données de séries chronologiques que ce profil matriciel nous aide à effectuer:
- Découverte d'anomalie
- Segmentation sémantique
- Estimation de la densité
- Chaînes de séries temporelles (ensemble temporellement ordonné de motifs de sous-séquence)
- Découverte de motifs / raison (sous-séquences approximativement répétées dans une série temporelle plus longue)
Utilisez le code suivant pour l'installer directement via pépite:
pip installer trapu
MeshCNN est un réseau de neurones profonds à usage général pour les maillages triangulaires 3D. Ces maillages peuvent être utilisés pour des tâches telles que la classification ou la segmentation de formes 3D. Une excellente application de vision industrielle.
Le cadre MeshCNN comprend des couches de convolution, regroupement et évanouissement appliqués directement sur les bords du maillage:
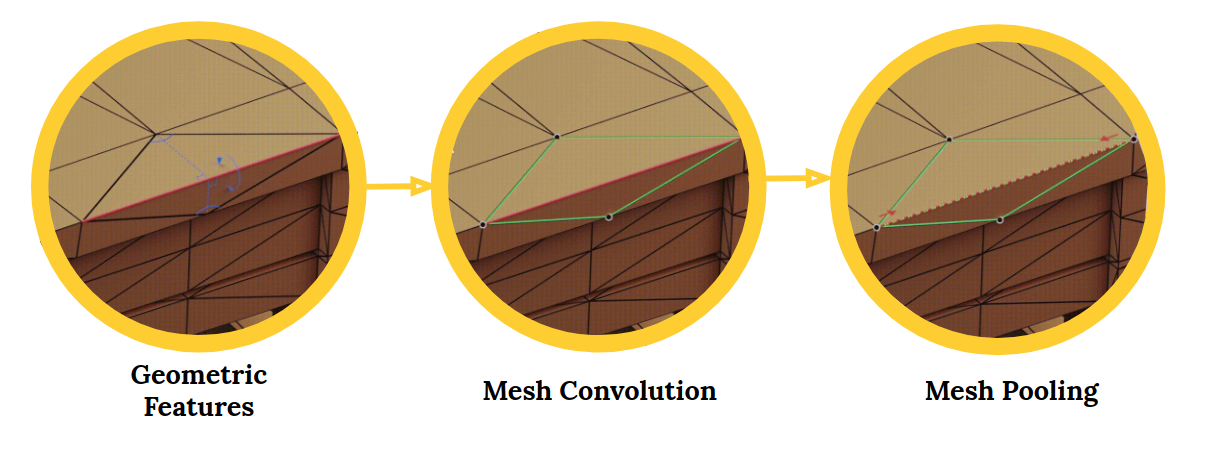
Réseaux de neurones convolutifs (CNN) sont parfaits pour travailler avec des images et des données visuelles. Les CNN sont devenus à la mode ces derniers temps avec un boom des tâches liées à l'image qui en découlent.. Détection d'objets, segmentation des images, classement d'images, etc., tout cela est possible grâce à l'avancée de CNN.
L'apprentissage profond en 3D suscite l'intérêt de l'industrie, y compris des domaines tels que la robotique et la conduite autonome. Le problème avec les formes 3D est qu'elles sont intrinsèquement irrégulières.. Cela rend les opérations telles que les convolutions difficiles et difficiles..
C'est là qu'intervient MeshCNN.. Depuis le référentiel:
Les maillages sont une liste de sommets, arêtes et faces, qui définissent ensemble la forme de l'objet 3D. Le problème est que chaque sommet a un nombre différent de voisins et il n'y a pas d'ordre.
Si vous êtes un fan de vision par ordinateur et que vous souhaitez apprendre ou appliquer CNN, c'est le référentiel parfait pour vous. Vous pouvez en savoir plus sur CNN à travers nos articles:

Les algorithmes d'arbre de décision sont parmi les premières techniques avancées que nous apprenons en apprentissage automatique. Franchement, J'apprécie beaucoup cette technique après régression logistique. Pourrait l'utiliser sur des ensembles de données plus volumineux, comprendre comment cela fonctionnait, comment les divisions se sont produites, etc.
Personnellement, j'adore ce référentiel. C'est un trésor pour les data scientists. Le référentiel contient une collection d'articles sur les algorithmes arborescents, y compris les arbres de décision, régression et classification. Le référentiel contient également la mise en œuvre de chaque article. Que pourrions-nous demander de plus?
Vous êtes-vous déjà demandé comment fonctionne le processus de formation de votre algorithme de machine learning ?? Nous écrivons le code, une complication se produit dans les coulisses (Le plaisir de programmer!), Et nous obtenons les résultats.
Microsoft Research a créé un outil appelé TensorWatch qui nous permet de voir des visualisations en temps réel du processus de formation de notre modèle d'apprentissage automatique.. Incroyable! Voir un extrait du fonctionnement de TensorWatch:

TensorWatch, en termes simples, est un outil de débogage et de visualisation pour l'apprentissage en profondeur et l'apprentissage par renforcement. Il fonctionne dans les notebooks Jupyter et nous permet de faire de nombreuses autres visualisations personnalisées de nos données et de nos modèles.
Discussions sur Reddit
![]()
Prenons quelques instants pour consulter les discussions Reddit les plus étonnantes liées à la science des données et à l'apprentissage automatique à partir de mai 2019. Voici quelque chose pour tout le monde, que vous soyez un passionné ou un praticien de la science des données. Alors creusons plus profondément!
C'est une noix difficile à casser. La première question est de savoir si vous devez opter pour un doctorat avant de prendre un poste dans l'industrie. Et après, si tu en choisis un, Quelles compétences devriez-vous acquérir pour faciliter la transition de votre industrie?
Je pense que cette discussion pourrait être utile pour déchiffrer l'une des plus grandes énigmes de notre carrière: Comment passer d'un domaine ou d'un métier à un autre? Ne regardez pas cela uniquement du point de vue d'un doctorant. Ceci est très pertinent pour la plupart d'entre nous qui souhaitent faire le premier pas dans l'apprentissage automatique..
Je vous recommande fortement de suivre ce fil, autant de data scientists chevronnés ont partagé leurs expériences personnelles et leur apprentissage.
Récemment, un article de recherche a été publié en élargissant le titre de ce fil. Le journal a expliqué l'hypothèse du billet de loterie dans laquelle un sous-réseau plus petit, également connu sous le nom de billet gagnant, pourrait s'entraîner plus rapidement par rapport à un réseau plus vaste.
Cette discussion porte sur ce document. Pour en savoir plus sur l'hypothèse du billet de loterie et son fonctionnement, vous pouvez vous référer à mon article où je discute de ce concept pour que même les débutants comprennent:
Décoder les meilleurs articles ICLR 2019: les réseaux de neurones sont là pour régner
J'ai choisi cette discussion parce que je peux totalement m'y rapporter. j'avais l'habitude de penser: j'ai beaucoup appris et, cependant, il en reste beaucoup plus. Vais-je jamais devenir un expert? J'ai fait l'erreur de ne regarder que la quantité et non la qualité de ce que j'apprenais.
Avec une technologie d'avance rapide et continue, il y aura toujours BEAUCOUP à apprendre. Ce fil contient des conseils solides sur la façon dont vous pouvez hiérarchiser, respectez-les et concentrez-vous sur la tâche à accomplir plutôt que d'essayer de devenir un expert dans tous les métiers.
Remarques finales
Je me suis amusé (et j'ai appris) lors de la création de la collection GitHub d'apprentissage automatique de ce mois-ci! Je recommande fortement de mettre en signet les deux plates-formes et de les vérifier régulièrement. C'est un excellent moyen de rester à jour avec les dernières nouveautés en matière d'apprentissage automatique..
Ou vous pouvez toujours revenir chaque mois et voir nos meilleures options. 🙂
Si vous pensez que j'ai raté un référentiel ou une discussion, commentaire ci-dessous et je serai heureux d'avoir une discussion à ce sujet.





