Classification de l'arbre de décision | Guide de classification des arbres de décision
Contenu
Vue d'ensemble
Qu'est-ce que l'algorithme d'arbre de classification de décision?
Comment construire un arbre de décision à partir de zéro
Terminologies de l'arbre de décision
Différence entre forêt aléatoire et arbre de décision
Implémentation du code Python des arbres de décision
Il existe plusieurs algorithmes en apprentissage automatique pour les problèmes de régression et de classification, mais en optant pour L'algorithme le meilleur et le plus efficace pour l'ensemble de données donné est le point principal à souligner lors du développement d'un bon modèle d'apprentissage automatique..
Un de ces algorithmes bon pour les problèmes de classification / catégorique et la régression est l'arbre de décision
Les arbres de décision mettent généralement en œuvre exactement la capacité de réflexion humaine lors de la prise de décision, donc c'est facile à comprendre.
La logique derrière l'arbre de décision peut être facilement comprise car il montre une structure de type organigramme / structure arborescente qui facilite la visualisation et l'extraction des informations du processus d'arrière-plan.
Table des matières
Qu'est-ce qu'un arbre de décision?
Éléments de l'arbre de décision
Comment prendre une décision à partir de zéro
Comment fonctionne l'algorithme de l'arbre de décision?
Connaissance de l'EDA (l'analyse exploratoire des données)
Arbres de décision et forêts aléatoires
Avantages de la forêt de décision
Inconvénients de la forêt de décision
Implémentation du code Python
1. Qu'est-ce qu'un arbre de décision?
Un arbre de décision est un algorithme d'apprentissage automatique supervisé. Utilisé dans les algorithmes de classification et de régression.. L'arbre de décision est comme un arbre avec des nœuds. Les branches dépendent de plusieurs facteurs. Divise les données en branches comme celles-ci jusqu'à ce qu'elles atteignent une valeur seuil. Un arbre de décision se compose des nœuds racines, nœuds enfants et nœuds feuilles.
Comprenons les méthodes de l'arbre de décision en prenant un scénario réel
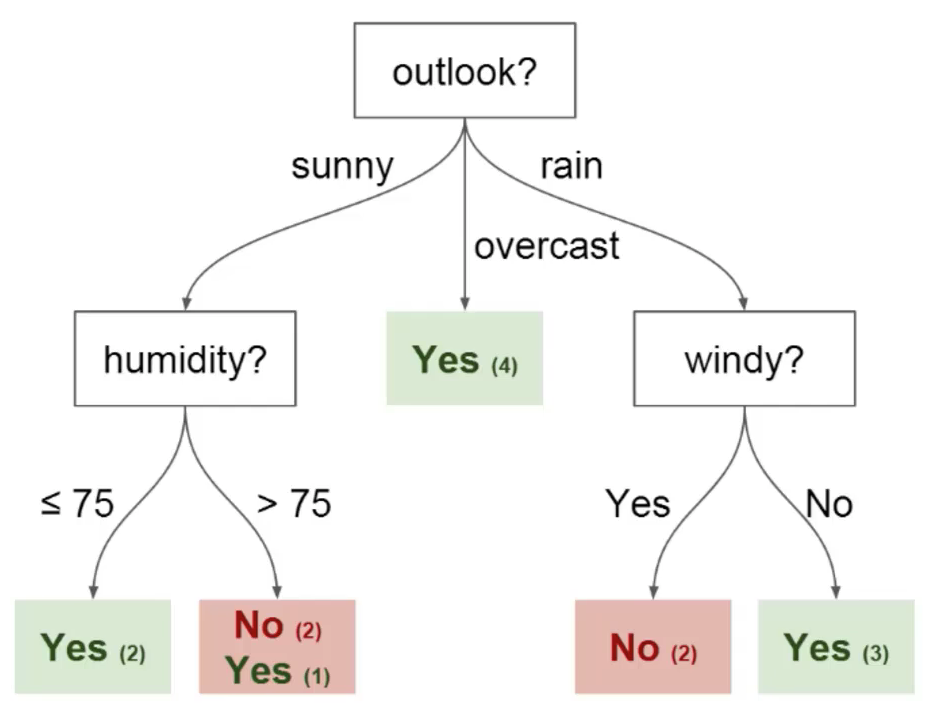
Imaginez que vous jouez au football tous les dimanches et que vous invitez toujours votre ami à jouer avec vous. Parfois, ton ami vient et les autres pas.
Le facteur de venir ou non dépend de beaucoup de choses, comme le temps, la température, vent et fatigue. Nous avons commencé à prendre toutes ces fonctionnalités en considération et à les suivre en même temps que la décision de votre ami de venir jouer ou non..
Vous pouvez utiliser ces données pour prédire si votre ami viendra jouer au football ou non. La technique que vous pourriez utiliser est un arbre de décision. Voici à quoi ressemblerait l'arbre de décision après le déploiement:
2. Éléments d'un arbre de décision
Chaque arbre de décision se compose de la liste d'éléments suivante:
un nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs....
b Bords
c Racine
d Feuilles
une) Nœuds: C'est le point où l'arbre est divisé en fonction de la valeur d'un attribut / caractéristique de l'ensemble de données.
b) Bords:Dirige el resultado de una división al siguiente nodo que podemos ver en lachiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines....anterior que hay nodos para características como perspectiva, humidité et vent. Il y a un avantage pour chaque valeur potentielle de chacun de ces attributs / fonctionnalités.
c) Racine: C'est le nœud où a lieu la première division.
ré) Feuilles: Ce sont les nœuds terminaux qui prédisent le résultat de l'arbre de décision.
3. Comment construire des arbres de décision à partir de zéro?
Lors de la création d'un arbre de décision, l'essentiel est de sélectionner le meilleur attribut dans la liste des caractéristiques totales du jeu de données pour le nœud racine et pour les sous-nœuds. La selección de los mejores atributos se logra con la ayuda de una técnica conocida comomesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique....de selección de atributos (ASM).
Avec l'aide de l'ASM, nous pouvons facilement sélectionner les meilleures caractéristiques pour les nœuds respectifs de l'arbre de décision.
Il existe deux techniques pour l'ASM:
une) Gain d'informations
b) IndiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines....de Gini
une) Gain d'informations:
1Le gain d'information est la mesure des changements de valeur d'entropie après division / segmentationLa segmentation est une technique de marketing clé qui consiste à diviser un large marché en groupes plus petits et plus homogènes. Cette pratique permet aux entreprises d’adapter leurs stratégies et leurs messages aux spécificités de chaque segment, améliorant ainsi l’efficacité de vos campagnes. Le ciblage peut se faire sur des critères démographiques, Psychographique, géographique ou comportementale, Faciliter une communication plus pertinente et personnalisée avec le public cible....del conjunto de datos en función de un atributo.
2 Indique la quantité d'informations qu'une fonctionnalité nous fournit / attribut.
3 Suivre la valeur du gain d'information, la division des nœuds et la construction de l'arbre de décision sont en cours.
L'arbre de décision 4 essaie toujours de maximiser la valeur du gain d'information, et un nœud / l'attribut qui a la valeur la plus élevée du gain d'information est divisé en premier. Le gain d'information peut être calculé à l'aide de la formule suivante:
Gain d'information = Entropie (S) – [(Moyenne pondérée) *Entropie(chaque caractéristique)
Entropie: Entropy signifies the randomness in thebase de donnéesUn "base de données" ou ensemble de données est une collection structurée d’informations, qui peut être utilisé pour l’analyse statistique, Apprentissage automatique ou recherche. Les ensembles de données peuvent inclure des variables numériques, catégorique ou textuelle, Et leur qualité est cruciale pour des résultats fiables. Son utilisation s’étend à diverses disciplines, comme la médecine, Économie et sciences sociales, faciliter la prise de décision éclairée et l’élaboration de modèles prédictifs..... Il est défini comme une métrique pour mesurer l'impureté. L'entropie peut être calculée comme:
Entropie(s)= -P(Oui)log2P(Oui)- P(non) log2P(non)
Où"OÙ" est un terme anglais qui se traduit par "où" en espagnol. Utilisé pour poser des questions sur l’emplacement des personnes, Objets ou événements. Dans des contextes grammaticaux, Il peut fonctionner comme un adverbe de lieu et est fondamental dans la formation des questions. Son application correcte est essentielle dans la communication quotidienne et dans l’enseignement des langues, faciliter la compréhension et l’échange d’informations sur les positions et les orientations....,
S= Nombre total d'échantillons
P(Oui)= probabilité de oui
P(non)= probabilité de non.
b) Indice de Gini:
L'indice de Gini est également défini comme une mesure d'impureté/pureté utilisée lors de la création d'un arbre de décision dans le CART(connu sous le nom d'arbre de classification et de régression) algorithme.
An attributehavingEl verbo "haber" en español es un auxiliar fundamental que se utiliza para formar tiempos compuestos. Su conjugación varía según el tiempo y el sujeto, étant "he", "has", "ha", "on a", "habéis" Oui "han" las formas del presente. En outre, en algunas regiones, se usa "haber" como un verbo impersonal para indicar existencia, comme dans "il y a" à "there is/are". Su correcta utilización es esencial para una comunicación efectiva en español....a low Gini index value should be preferred in contrast to the high Gini index value.
Il ne crée que des divisions binaires, et l'algorithme CART utilise l'index de Gini pour créer des divisions binaires.
L'indice de Gini peut être calculé en utilisant la formule ci-dessous:
Indice de Gini= 1- ??jPj2
Où pj représente la probabilité
4. Comment fonctionne l'algorithme d'arbre de décision?
L'idée de base derrière tout algorithme d'arbre de décision est la suivante:
1. SélectionnerLa commande "SÉLECTIONNER" es fundamental en SQL, utilizado para consultar y recuperar datos de una base de datos. Permite especificar columnas y tablas, filtrando resultados mediante cláusulas como "OÙ" y ordenando con "COMMANDÉ PAR". Su versatilidad lo convierte en una herramienta esencial para la manipulación y análisis de datos, facilitando la obtención de información específica de manera eficiente....the best Feature using Attribute Selection Measures(ASM) diviser les records.
2. Faire de cet attribut/caractéristique un nœud de décision et diviser l'ensemble de données en sous-ensembles plus petits.
3 Démarrez le processus de construction de l'arbre en répétant ce processus de manière récursive pour chaque enfant jusqu'à ce que l'une des conditions suivantes soit atteinte :
une) Tous les tuples appartenant à la même valeur d'attribut.
b) Il ne reste plus d'attributs.
c ) Il n'y a plus d'instances restantes.
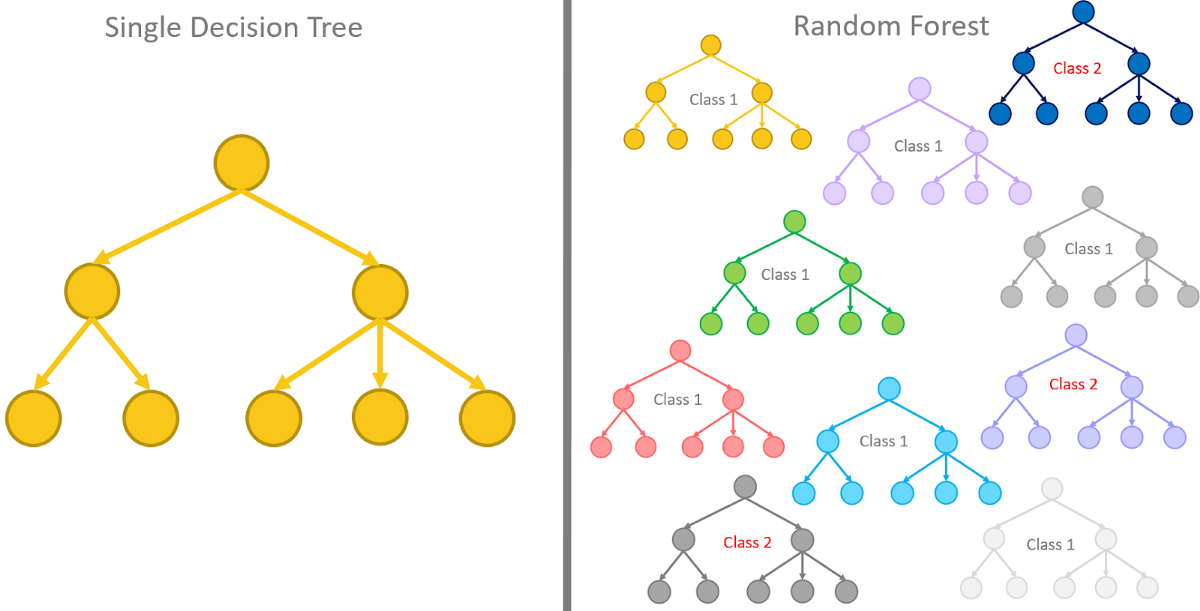
5. Arbres de décision et forêts aléatoires
Les arbres de décision et la forêt aléatoire sont les deux méthodes d'arbre utilisées dans l'apprentissage automatique..
Les arbres de décision sont les modèles d'apprentissage automatique utilisés pour faire des prédictions en parcourant chaque caractéristique de l'ensemble de données, un par un.
Les forêts aléatoires, quant à elles, sont une collection d'arbres de décision regroupés et entraînés ensemble qui utilisent des ordres aléatoires des caractéristiques dans les ensembles de données donnés..
Au lieu de s'appuyer sur un seul arbre de décision, la forêt aléatoire prend la prédiction de chaque arbre et basée sur la majorité des votes des prédictions, et il donne le résultat final. En d'autres termes, la forêt aléatoire peut être définie comme une collection de plusieurs arbres de décision.
6. Avantages de l'arbre de décision
1 Il est simple à mettre en œuvre et suit une structure de type organigramme qui ressemble à une prise de décision humaine.
2 Il s'avère très utile pour les problèmes liés à la décision.
3 Il aide à trouver tous les résultats possibles pour un problème donné.
4 Il y a très peu de besoin de nettoyage des données dans les arbres de décision par rapport aux autres algorithmes d'apprentissage automatique.
5 Gère à la fois les valeurs numériques et les valeurs catégorielles
7. Inconvénients de l'arbre de décision
1 Trop de couches d'arbre de décision le rendent parfois extrêmement complexe.
2 It may result inoverfittingEl sobreajuste, o overfitting, es un fenómeno en el aprendizaje automático donde un modelo se ajusta demasiado a los datos de entrenamiento, capturando ruido y patrones irrelevantes. Esto resulta en un rendimiento deficiente en datos no vistos, ya que el modelo pierde capacidad de generalización. Para mitigar el sobreajuste, se pueden emplear técnicas como la regularización, la validación cruzada y la reducción de la complejidad del modelo.... ( qui peut être résolu à l'aide de la Algorithme de forêt aléatoire)
3 Pour le plus grand nombre d'étiquettes de classe, la complexité de calcul de l'arbre de décision augmente.
8. Implémentation du code Python
#Bibliothèques de calcul numérique
importer des pandas au format pd
importer numpy en tant que np
importer matplotlib.pyplot en tant que plt
importer seaborn comme sns
# Divida el conjunto de datos en datos deentraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines....y datos de prueba
de sklearn.model_selection importer train_test_split
x = raw_data.drop('Cyphose', axe = 1)
y = raw_data['Cyphose']
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(X, Oui, taille_test = 0.3)
# Mesurer les performances du modèle d'arbre de décision
à partir de sklearn.metrics importer classification_report
à partir de sklearn.metrics importer confusion_matrix
imprimer(classement_rapport(y_test_data, prédictions))
imprimer(confusion_matrice(y_test_data, prédictions))
Sur ce je termine ce blog. Bonjour à tous, Namaste Je m'appelle Pranshu Sharma et je suis un passionné de science des données
Merci beaucoup d'avoir pris votre temps précieux pour lire ce blog.. N'hésitez pas à signaler d'éventuelles erreurs (après tout, je suis apprenti) et fournir les commentaires correspondants ou laisser un commentaire.