Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Cet article fait partie d'une série de blogs en cours sur le traitement du langage naturel (PNL). Dans l'article précédent, nous discutons de l'analyse sémantique, qu'est-ce qu'un niveau de tâche PNL. Dans cet article, nous discutons des techniques d'analyse sémantique dans lesquelles nous discutons d'une technique appelée extraction d'entités, c'est très important à comprendre en PNL.
Donc, dans cet article, Nous allons approfondir la technique d'extraction d'entités appelée reconnaissance d'entités nommées, qui est un composant très utile dans le pipeline PNL.
C'est la partie 10 de la série de blogs sur le Guide étape par étape du traitement du langage naturel.
Table des matières
1. Qu'est-ce que la reconnaissance d'entité nommée (VERS LE BAS)?
2. Différents blocs présents dans un modèle NER typique
3. Compréhension approfondie de la reconnaissance d'entités nommées avec un exemple
4. Comment fonctionne la reconnaissance d'entité nommée?
5. Cas d'utilisation de la reconnaissance d'entités nommées
6. Comment puis-je utiliser NER?
Qu'est-ce que la reconnaissance d'entité nommée (VERS LE BAS)?
Analysons d'abord ce que signifient les entités.
Les entités sont les fragments les plus importants d'une phrase particulière, comme phrases nominales, phrases verbales ou les deux. Généralement, les algorithmes de détection d'entités sont des modèles conjoints de:
- Analyse basée sur des règles, Python
- Recherches dans le dictionnaire,
- Étiquetage PLV,
- Analyse de dépendance.
Par exemple,

Dans la phrase précédente, les entités sont:
Date: jeudi, Temps: nuit, Emplacement: Chateau Marmont, Personne: Cate Blanchett
À présent, nous pouvons commencer notre discussion sur la reconnaissance des entités nommées (VERS LE BAS),
1. La reconnaissance d'entités nommées est l'une des principales méthodes de détection d'entités en PNL.
2. La reconnaissance d'entités nommées est une technique de traitement du langage naturel qui permet de scanner automatiquement des articles entiers et d'extraire certaines entités fondamentales d'un texte et de les classer dans des catégories prédéfinies. Les entités peuvent être,
- Organisations,
- Quantités,
- Valeurs monétaires,
- Pourcentages et plus.
- Noms de personnes
- Noms d'entreprise
- Emplacements géographiques (à la fois physique et politique)
- Noms de produits
- Dates et heures
- Des sommes d'argent
- Noms des événements
3. En mots simples, la reconnaissance d'entité nommée est le processus de détection d'entités nommées, comme noms de personnes, noms de lieux, noms de sociétés, etc. du texte.
4. Également connu sous le nom d'identification d'entité ou d'extraction d'entité ou de fragmentation d'entité.
Par exemple,

5. Avec l'aide de la reconnaissance d'entité nommée, nous pouvons extraire des informations clés pour comprendre le texte, ou simplement l'utiliser pour extraire des informations importantes et les stocker dans une base de données.
6. L'applicabilité de la détection d'entité peut être vue dans de nombreuses applications, Quoi
- Chatbots automatisés,
- Analyseurs de contenu,
- La connaissance des consommateurs, etc.
Types d'entités nommées couramment utilisés:
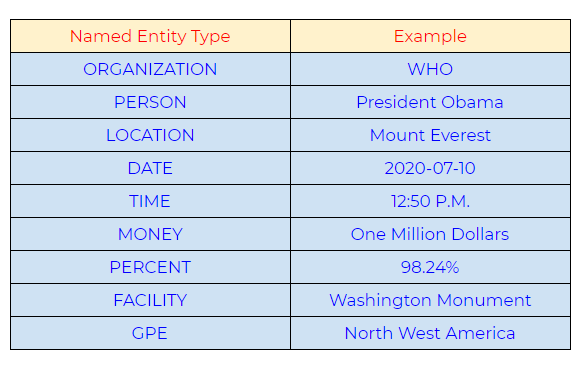
Source de l'image: Google images
Différents blocs présents dans un modèle de reconnaissance d'entité nommée typique
Un modèle NER typique se compose des trois blocs suivants:
Identification de l'expression nominale
Cette étape essaie d'extraire toutes les phrases nominales d'un texte à l'aide d'une analyse de dépendance et de l'étiquetage d'une partie du discours..
Classement des phrases
Dans cette étape de classement, nous classons toutes les phrases nominales extraites de l'étape précédente dans leurs catégories respectives. Pour lever l'ambiguïté des emplacements, API de Google Maps peut fournir un très bon chemin. et d'identifier des noms de personnes ou des noms de sociétés, les bases de données ouvertes de DBpédia, Wikipédia peut être utilisé. A part ça, nous pouvons également créer des tables de recherche et des dictionnaires combinant des informations à l'aide de différentes sources.
Désambiguïsation d'entité
Parfois, ce qui se passe, c'est que les entités sont mal classées, donc créer une couche de validation sur les résultats devient utile. L'utilisation de tableaux de connaissances peut être mise à profit à cette fin. Certains des tableaux de connaissances les plus populaires sont:
Compréhension approfondie du NER avec un exemple
Considérez la phrase suivante:
![]()
Les cellules bleues représentent les noms. Certains de ces noms décrivent des choses réelles présentes dans le monde.
Par exemple, De ce qui précède, les noms suivants représentent des lieux physiques sur une carte.
"Londres", "Angleterre", "Royaume-Uni"
Ce serait formidable si nous pouvions détecter cela! Avec cette quantité d'informations, nous pourrions extraire automatiquement une liste de lieux du monde réel mentionnés dans un document avec l'aide de la PNL.
Donc, le but de NER est de détecter et d'étiqueter ces noms avec les concepts du monde réel qu'ils représentent.
Ensuite, lorsque nous exécutons chaque jeton présent dans la phrase via un modèle de marquage NER, notre prière ressemble à ceci,

Analysons ce que fait exactement le système NER.
Les systèmes NER ne font pas qu'une simple recherche dans le dictionnaire. En échange, ils utilisent le contexte de la façon dont un mot apparaît dans la phrase et utilisent un modèle statistique pour deviner quel genre de nom ce mot particulier représente.
Étant donné que NER facilite l'extraction de données structurées à partir de texte, il a de nombreuses utilisations. C'est l'une des méthodes les plus simples pour obtenir rapidement une valeur perspicace à partir d'un pipeline NLP..
Si vous voulez essayer NER vous-même, voir le Relier.
Comment fonctionne la reconnaissance d'entité nommée?
Comment pouvons-nous simplement observer, après avoir lu un texte particulier, nous pouvons naturellement reconnaître les entités nommées comme des personnes, valeurs, Emplacements, etc.
Par exemple, Considérez la phrase suivante:
Phrase: Sundar Pichai, le PDG de Google Inc. marche dans les rues de Californie.
De la phrase précédente, on peut identifier trois types d'entités: (Entités nommées)
- (“Personne”: “Sundar Pichai”),
- (“Organisation”: “Google Inc.”),
- (“Lieu”: “Californie”).
Mais faire la même chose avec l'aide d'ordinateurs, nous devons d'abord les aider à reconnaître les entités afin qu'ils puissent les catégoriser. Ensuite, pour le faire, nous pouvons compter sur l'aide de l'apprentissage automatique et du traitement du langage naturel (PNL).
Discutons du rôle des deux lors de la mise en œuvre de la NER à l'aide d'ordinateurs:
- PNL: Ce étudie la structure et les règles du langage et forme des systèmes intelligents capables de tirer un sens du texte et de la parole.
- Apprentissage automatique: Aider les machines à apprendre et à s'améliorer au fil du temps.
Pour savoir ce qu'est une entité, un modèle NER doit être capable de détecter un mot ou une chaîne de mots qui composent une entité (par exemple, Californie) et décider à quelle catégorie d'entité il appartient.
Ensuite, comme étape finale, nous pouvons dire que le cœur de tout modèle NER est un processus en deux étapes:
- Détecter une entité nommée
- Catégoriser l'entité
Ensuite, premier, nous devons créer des catégories d'entités, Comme nom, Lieu, Événement, Organisation, etc., et alimenter un modèle NER avec des données d'entraînement pertinentes.
Alors, en marquant des exemples de mots et d'expressions avec leurs entités correspondantes, éventuellement, nous apprendrons à notre modèle NER à détecter des entités et à les catégoriser.
Cas d'utilisation de la reconnaissance d'entités nommées
Comme nous l'avons commenté dans la section précédente, la reconnaissance de l'entité nommée (VERS LE BAS) cela nous aidera à identifier facilement les composants clés d'un texte, comme noms de personnes, endroits, marques de commerce, valeurs monétaires et plus.
Et extraire les principales entités d'un texte nous aide à trier les données non structurées et à détecter les informations importantes, ce qui est crucial si vous devez traiter de grands ensembles de données.
Ensuite, Jetons un coup d'œil à certains des cas d'utilisation intéressants de la reconnaissance d'entité nommée:
Attention au client
Source de l'image: Google images
Analysons le cas d'utilisation des tickets de support client où nous traitons un nombre croissant de tickets, là, nous pouvons utiliser des techniques de reconnaissance d'entité nommée pour traiter les demandes des clients plus rapidement.
D'un point de vue commercial, si nous automatisons les tâches répétitives du service client, comment catégoriser les problèmes et les demandes des clients, vous fera gagner un temps précieux. Par conséquent, contribue à améliorer vos taux de résolution et augmente la satisfaction de vos clients.
Ici, nous pouvons également utiliser l'extraction d'entités pour extraire les informations pertinentes, tels que les noms de produits ou les numéros de série, facilitant l'envoi de tickets à l'agent ou à l'équipe la plus appropriée pour gérer ce problème.
Obtenez un aperçu des commentaires des clients

Source de l'image: Google images
Pour presque toutes les entreprises axées sur les produits, les avis en ligne sont une excellente source de commentaires des clients, car ils peuvent fournir des informations précieuses sur ce que les clients aiment et n'aiment pas à propos de vos produits et les aspects de votre entreprise qui doivent être améliorés pour la croissance de l'entreprise.
Ensuite, ici, nous pouvons utiliser les systèmes NER pour organiser tous les commentaires des clients et détecter les problèmes récurrents.
Par exemple, Nous pouvons utiliser le système NER pour détecter les emplacements les plus fréquemment mentionnés dans les avis clients négatifs, ce qui pourrait vous amener à vous concentrer sur une branche de bureau en particulier.
Système de recommandation
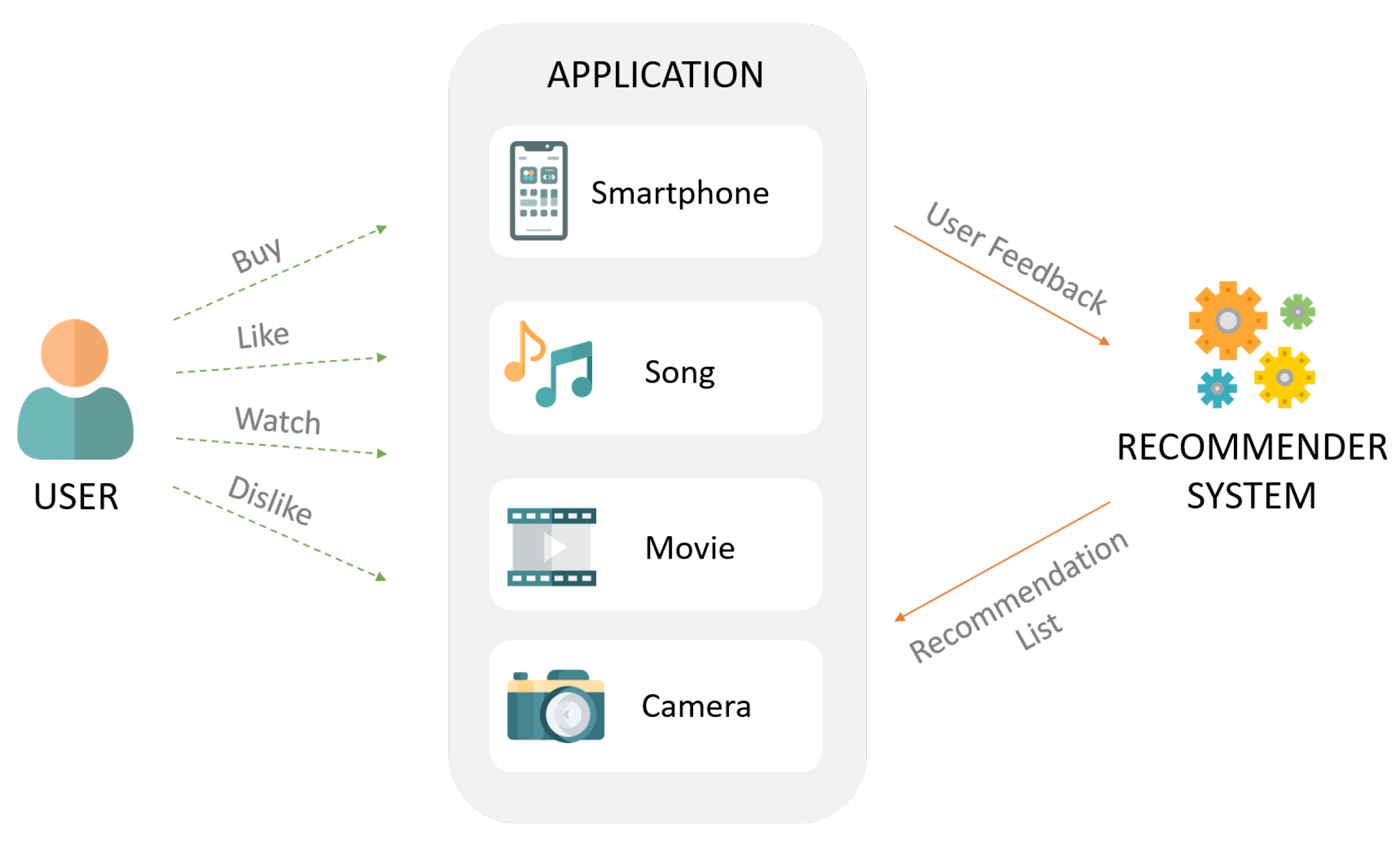
Source de l'image: Google images
De nombreuses applications modernes comme Netflix, Youtube, Facebook, etc. s'appuyer sur des systèmes de recommandation pour produire des expériences client optimales. Beaucoup de ces systèmes sont basés sur la reconnaissance d'entités nommées, qui peut fournir des suggestions basées sur l'historique de recherche de l'utilisateur.
Par exemple, Si vous regardez beaucoup de vidéos éducatives sur YouTube, vous obtiendrez plus de recommandations qui ont été classées comme éducation d'entité.
Résumé des CV

Source de l'image: Google images
Lors du recrutement de nouvelles personnes, les recruteurs passent de nombreuses heures de leur journée à examiner des CV et à rechercher le bon candidat. Chaque CV contient presque le même type d'informations, mais sa forme organisée et son format sont différents, cela devient donc un exemple classique de données non structurées.
Ensuite, ici à l'aide d'un extracteur d'entité, les équipes de recrutement peuvent extraire instantanément les informations les plus pertinentes sur les candidats, à partir d'informations personnelles comme le nom, adresse, numéro de téléphone, date de naissance et email, etc., aux informations relatives à leur formation et à leur expérience telles que les certifications, Titres, noms de sociétés, compétences, etc.
D'autres cas d'utilisation de NER sont:
- Optimisation des algorithmes des moteurs de recherche,
- Classification du contenu pour les chaînes d'information, etc.
Comment puis-je utiliser NER?
Si vous travaillez sur un énoncé de problème commercial et pensez que votre entreprise pourrait bénéficier du NER, vous pouvez l'utiliser assez facilement à l'aide des excellentes bibliothèques open source suivantes:
Chacun a ses avantages et ses inconvénients, que vous pouvez explorer en vous référant aux liens mentionnés ci-dessus.
Ceci termine notre partie 10 de la série de blogs sur le traitement du langage naturel!
D'autres articles de mon blog
Vous pouvez également consulter mes précédents articles de blog.
Anciens articles de blog sur la science des données.
C'est ici mon profil Linkedin au cas où vous voudriez me joindre. Je serai heureux d'être connecté avec vous.
Courrier électronique
Pour toute requête, vous pouvez m'envoyer un email à Gmail.
Remarques finales
Merci pour la lecture!
j'espère que l'article vous a plu. Si ça te plaît, partagez-le avec vos amis aussi. Tout ce qui n'est pas mentionné ou voulez-vous partager vos pensées? N'hésitez pas à commenter ci-dessous et je vous répondrai. ??





