introduction
Les ressources basées sur la science des données ne se développent pas comme prévu et la croissance n'est que de 14%.
Même à l'ère numérique d'aujourd'hui, la science des données nécessite encore beaucoup de travail manuel. Stocker les données générées, les nettoyer, analyse exploratoire, visualiser les données et enfin adapter un modèle pour permettre la prise de décision. Le travail manuel peut être automatisé dans une certaine mesure et, donc, le début de l'automatisation en science des données.
Le cycle de vie d'un ensemble de données dans le projet de science des données est le suivant
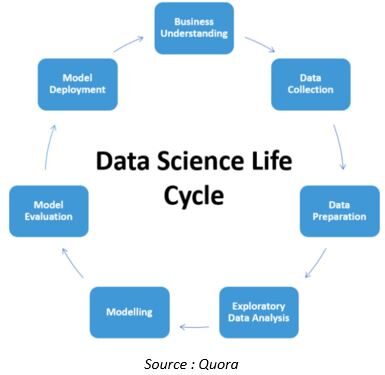
À l'exception de la compréhension commerciale et de la mise en œuvre du modèle, presque tous les aspects du pipeline de la science des données sont en cours d'automatisation. Voyons quelques développements dans ce domaine.
Collecte automatique des données
Puisque les données sont la pierre angulaire de toute analyse, nous devons passer un temps considérable à les comprendre. Des données incomplètes pourraient conduire à des modèles peu fiables ou biaisés et, si l'entreprise a pris des décisions sur ces modèles, Inutile de dire que cela conduirait à des catastrophes que l'on ne pourrait même pas imaginer.
Dataprep est une bibliothèque Python open source qui nous permet de préparer des données avec seulement quelques lignes de code. Dataprep nous permet de visualiser toutes les données manquantes dans notre ensemble de données, la découverte des données manquantes est obligatoire pendant que nous préparons les données afin que nous puissions les remplacer par des données utiles en conséquence.
Vous trouverez ci-dessous la syntaxe pour installer la bibliothèque Dataprep à l'aide de pip install
pip install -U dataprep
Le connecteur est un composant de DataPrep qui vise à simplifier la collecte de données à partir d'API Web en fournissant un ensemble standard d'opérations. Il s'agit d'un conteneur d'API open source qui accélère le développement en effectuant plusieurs appels d'API. Rationalise l'appel de plusieurs API via une bibliothèque intuitive.
Voici la syntaxe pour installer Dataprep.connector
à partir de l'importation de dataprep.connector *
Regardons un exemple d'utilisation de connect pour collecter des données. Connecteur con, vous pouvez collecter des données sur l'un des principaux sites de recommandation en ligne: Japper.
à partir de dataprep.connector importer connecter
# utiliser la fonction de connexion avec le "japper" chaîne et jeton d'accès Yelp, tous deux spécifiés en tant que paramètres. Cette action nous permet de créer un connecteur vers l'API Web Yelp:
yelp_connector = connecter("japper", _auth={"jeton d'accès":"<Votre jeton d'accès Yelp>"})
yelp_connector.info()# donne des informations sur l'utilisation de l'API Connector sur Web
Production

dans cet exemple, il n'y a qu'un seul point de terminaison disponible pour Yelp: Entreprise. Cependant, si vous souhaitez vous connecter à un autre point de terminaison Yelp, vous pouvez créer un nouveau fichier de configuration.
yelp_connector.show_schema (“Entreprise”) # explorer le schéma de point de terminaison “Entreprise” selon la définition de votre fichier de configuration
Nettoyage automatique des données
Le nettoyage des données est l'une des tâches les plus fastidieuses pour un data scientist, occupe votre temps précieux. Il fait l'objet de recherches exclusives depuis quelques années. Les startups et les grandes entreprises établies offrent une automatisation et des outils pour le nettoyage des données.
DataPrep.Clean vise à fournir un grand nombre de fonctions avec une interface unifiée pour nettoyer et standardiser les données de différents types sémantiques dans Pandas.
DataPrep.Clean contient des fonctions simples conçues pour nettoyer et valider les données dans un DataFrame. Vous trouverez ci-dessous les points forts de la bibliothèque DataPrep.Clean.
Le code suivant montre comment utiliser DataPrep.Clean. Nous utiliserons le jeu de données waste_hauler du référentiel de jeux de données interne DataPrep.
à partir de l'importation dataprep.clean *
à partir de dataprep.datasets importer load_dataset
df = load_dataset('waste_hauler')
df.head()
Production

df = clean_headers(df)#convertit les en-têtes en cas de serpent imprimer(df.colonnes)
Il y a beaucoup plus de fonctions dans dataprep.clean comme indiqué ci-dessous
df = clean_phone(df, 'téléphone')#Pour standardiser leurs formats, nous pouvons utiliser la fonction clean_phone() df = adresse_propre(df, 'adresse locale')#normaliser les incohérences d'adresse
Exploration automatique des données:
L'exploration des données fait référence aux étapes préliminaires de l'analyse des données et de la construction de modèles au cours desquelles les analystes de données utilisent des techniques statistiques pour décrire les caractéristiques de l'ensemble de données., comme taille, qualité, quantité et précision, et la résumer pour mieux comprendre la nature des données.
DataPrep.EDA est l'outil EDA le plus rapide et le plus simple de Python. Permet aux data scientists de comprendre les pandas avec quelques lignes de code en quelques secondes.
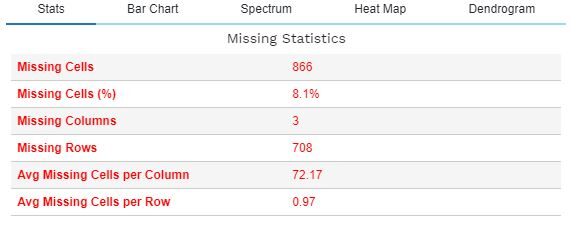
La fonction plot_missing () permet une analyse complète des valeurs manquantes et de leur impact sur l'ensemble de données. Ce qui suit décrit la fonctionnalité de plot_missing () pour une trame de données donnée df.
à partir de dataprep.eda importer plot_missing
à partir de dataprep.datasets importer load_dataset
df = load_dataset("titanesque")
intrigue_manquante(df)
Il y a beaucoup plus de fonctions dans dataprep.eda comme indiqué ci-dessous
intrigue_corrélation() #génère des matrices de corrélation et un coefficient de corrélation terrain(df) #trace un histogramme pour chaque colonne numérique, un graphique à barres pour chaque colonne catégorielle, et calcule les statistiques de l'ensemble de données.
Il nous permet de créer des rapports détaillés à partir d'un Pandas / Dask DataFrame avec fonction create_report. DataPrep.EDA est 100 fois plus rapide que les outils de profilage basés sur les pandas, génère des visualisations interactives dans un rapport qui rend le rapport plus attrayant et prend également en charge le Big Data avec des millions de lignes de travail, ce qui n'était pas facile avec la bibliothèque pandas traditionnelle.
Modélisation automatique ML:
L'étape suivante et la plus recherchée du cycle de vie de la science des données est l'ajustement du modèle. Apprentissage automatique automatisé (AutoML) est actuellement le sujet de conversation de la ville au sein de la communauté de la science des données. Auto ML nous fournit les outils qui nous aident à trouver le modèle d'apprentissage automatique approprié pour l'ensemble de données donné avec une implication minimale de l'utilisateur..
LightAutoML est l'une des bibliothèques Python conçues pour effectuer diverses tâches telles que la classification binaire et la régression / multiclasse dans des ensembles de données tabulaires, contenant différents types de données sous forme numérique, catégorique, les textes, etc.
Un autre exemple est Auto-Sklearn. Il s'agit d'une bibliothèque Python utilisée pour découvrir automatiquement des modèles hautes performances pour les tâches de régression. Utilise des modèles d'apprentissage automatique de la bibliothèque d'apprentissage automatique scikit-learn.
L'avantage d'Auto-Sklearn est que, ainsi que découvrir la préparation des données et le modèle qui fonctionne pour un ensemble de données, vous pouvez également apprendre des modèles qui fonctionnent bien sur des ensembles de données similaires et créer automatiquement un ensemble de données hautes performances. modèles découverts dans le cadre du processus d'optimisation.
Dans l'exemple suivant, nous utiliserons Auto-Sklearn pour découvrir un modèle pour l'ensemble de données de la sonde. Les Classeur AutoSklearn est configuré pour fonctionner pendant 5 minutes avec 8 et limiter l'évaluation de chaque modèle à 30 secondes.
des pandas importer read_csv
de sklearn.model_selection importer train_test_split
de sklearn.preprocessing importer LabelEncoder
de sklearn.metrics importer precision_score
depuis autosklearn.classification importer AutoSklearnClassifier
URL="https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv"
cadre de données = read_csv(URL, header=Aucun)
# divisé en éléments d'entrée et de sortie
données = dataframe.values
X, y = données[:, :-1], Les données[:, -1]
# préparer au minimum l'ensemble de données
X = X.astype('float32')
y = LabelEncoder().fit_transformer(y.astype('str'))
# divisé en ensembles de train et de test
X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test=0.33, état_aléatoire=1)
# définir la recherche
modèle = AutoSklearnClassifier(time_left_for_this_task=5*60, per_run_time_limit=30, n_emplois=8)
model.fit(X_train, y_train)#effectuer la recherche
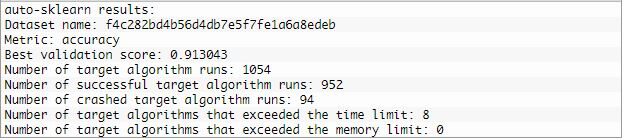
imprimer(model.sprint_statistics())#résumer
Production
Évaluation du modèle:
Une fois le modèle construit, il est temps de vérifier les performances du même ou plutôt la précision avec laquelle le modèle fonctionne. Si la précision n'est pas à la hauteur, le modèle n'est pas considéré comme le bon ajustement pour cet ensemble de données.

Comme dans le cas de l'exemple précédent, nous définissons une classe AutoSklearnClassifier pour contrôler la recherche et la configurer pour qu'elle s'exécute pendant une durée spécifique, Disons 2 minutes, et défaussez tout modèle qui prend plus de temps que 30 secondes pour évaluer. A la fin de ces 2 minutes, nous pouvons examiner les statistiques de recherche et évaluer le modèle le plus performant.
# évaluer le meilleur modèle
y_hat = model.predict(X_test)
acc = score_précision(y_test, y_hat)
imprimer("Précision: %.2F" % acc)
La précision de la classification des 81,2 pourcent, ce qui est raisonnablement habile.
Limites

Même si l'automatisation a augmenté ces derniers temps, il y a certainement des mises en garde / désavantages. Plus important encore, AutoML a besoin de plus de ressources, au contraire, il faudra plus de temps pour courir. Le traitement automatique par machine learning de données non structurées et semi-structurées est techniquement difficile.
Souvent, les problèmes réalistes sont une combinaison d'objectifs multiples, En tant que tel, il est nécessaire de faire des différences subtiles entre la prise de décision et le coût, qui nécessite l'intervention d'un data scientist. Il y aura toujours un besoin de points de contrôle manuels où les humains peuvent intervenir et signer des parties du processus automatisé. Cela peut ajouter la responsabilité nécessaire et aider à la réglementation et à la gouvernance. Donc, l'approbation finale sera toujours donnée par le data scientist.
Les références
https://machinelearningmastery.co
Les médias présentés dans cet article Automation in Data Science ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





