introduction
L'industrie de l'analytique consiste à obtenir les “information” des données. Avec l'augmentation de la quantité de données ces dernières années, qui sont pour la plupart non structurés, il est difficile d'obtenir les informations pertinentes et souhaitées. Mais, la technologie a développé des méthodes puissantes qui peuvent être utilisées pour extraire les données et obtenir les informations que nous recherchons.
Une de ces techniques dans le domaine de l'exploration de texte est la modélisation thématique.. Comme le nom le suggère, est une procédure pour identifier automatiquement les thèmes présents dans un objet texte et dériver des motifs cachés présentés par un corpus de texte. Pour cela, aider à une meilleure prise de décision.
La modélisation de sujet est distincte des approches d'exploration de texte basées sur des règles qui utilisent des expressions régulières ou des techniques de recherche par mot-clé basées sur un dictionnaire.. C'est une approche non supervisée qui est utilisée pour rechercher et observer l'ensemble des mots (appels “les sujets”) dans de grands groupes de textes.
Les thèmes peuvent être définis comme “un motif répétitif de termes concurrents dans un corpus”. Un bon modèle de thème devrait se traduire par: “Santé”, “médecin”, “patient”, “hôpital” pour un sujet – Soins médicaux et “cultiver”, “cultures”, “blé” pour un sujet – “agriculture”.
Les modèles de thèmes sont très utiles pour regrouper des documents, organisation de gros blocs de données textuelles, récupération d'informations textuelles non structurées et sélection de fonctionnalités. Par exemple, Le New York Times utilise des modèles de sujets pour booster ses moteurs de recommandation de publication d'utilisateurs. Divers professionnels utilisent des modèles thématiques pour les industries de recrutement, où votre objectif est d'extraire les caractéristiques latentes des descriptions de poste et de les attribuer aux bons candidats. Utilisé pour organiser de grands ensembles de données de courrier électronique, avis clients et profils d'utilisateurs sur les réseaux sociaux.
Ensuite, si vous n'êtes pas sûr de la procédure complète de modélisation du sujet, Ce guide vous présentera plusieurs concepts suivis de leur implémentation en Python.
Table des matières
- Affectation Dirichlet latente pour la modélisation thématique
- Implémentation Python
- Préparation des documents
- Nettoyage et prétraitement
- Préparation de la matrice des termes du document
- Exécution du modèle LDA
- Résultats
- Conseils pour générer des résultats de modélisation de sujet
- Filtre de fréquence
- Pièce de filtre d'étiquette vocale
- Lot Wise LDA
- Modélisation de thèmes pour la sélection de fonctionnalités
Affectation Dirichlet latente pour la modélisation thématique
Il existe de nombreuses approches pour obtenir des thèmes à partir d'un texte tels que: Fréquence des termes et fréquence des documents inversés. Techniques de factorisation matricielle non négative. La cartographie latente de Dirichlet est la technique de modélisation de sujet la plus populaire et dans cet article, nous discuterons de la même chose.
LDA suppose que les documents sont produits à partir d'une combinaison de sujets. Ensuite, ces sujets génèrent des mots en fonction de leur distribution de probabilité. Étant donné un ensemble de données de documents, LDA revient en arrière et essaie de déterminer quels sujets créeraient ces documents en premier lieu.
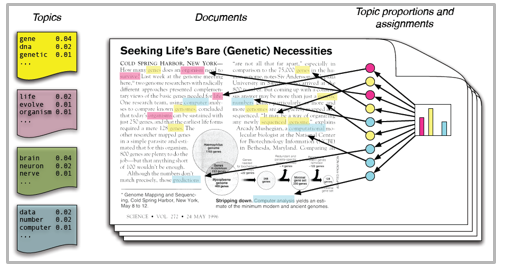
LDA est une technique de factorisation matricielle. Dans l'espace vectoriel, tout corpus (collection de documents) peut être représenté comme une matrice document-terme. La matrice suivante montre un corpus de N documents D1, D2, D3… Dn et la taille du vocabulaire des mots M W1, W2 .. Wn. La valeur de la cellule i, j donne le nombre de fréquences du mot Wj dans le document Di.
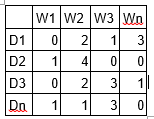
LDA convertit ce tableau de documents et de termes en deux tableaux de moindre dimension: M1 et M2.
M1 est une matrice de documents et de sujets et M2 est une matrice de sujets et de termes avec des dimensions (N, K) Oui (K, M) respectivement, où N est le nombre de documents, K est le nombre de sujets et M est la taille du vocabulaire .
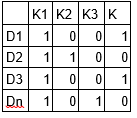
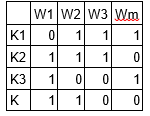
Notez que ces deux matrices fournissent déjà des distributions de sujets de mots et de documents. Malgré cela, ces distributions doivent être améliorées, qui est l'objectif principal de LDA. LDA utilise des techniques d'échantillonnage pour piloter ces matrices.
Répéter chaque mot “w” pour chaque document “ré” et essayez d'ajuster le thème actuel – affectation de mots avec une nouvelle affectation. Un nouveau sujet est attribué “k” au mot “w” avec une probabilité P qui est le produit de deux probabilités p1 et p2.
Pour chaque sujet, deux probabilités p1 et p2 sont calculées. P1 – p (thème t / document d) = la proportion de mots dans le document d qui sont actuellement affectés au sujet t. P2 – p (palabre w / thème t) = la proportion de devoirs au sujet t sur tous les documents qui proviennent de ce mot w.
Le sujet actuel: l'affectation des mots est mise à jour avec un nouveau sujet avec la probabilité, produit de p1 et p2. Dans cette étape, le modèle suppose que toutes les affectations de mots et de sujets existants, sauf mot courant, ils ont raison. Il s'agit essentiellement de la probabilité que le sujet t génère le mot w, il est donc logique d'ajuster le sujet du mot actuel avec une nouvelle probabilité.
Après plusieurs itérations, un état stable est atteint dans lequel les distributions du sujet du document et des termes du sujet sont assez bonnes. C'est le point de convergence de LDA.
Paramètres LDA
Hyperparamètres alpha et bêta: Alpha représente la densité des documents et des sujets et Beta représente la densité des sujets et des mots. Plus la valeur alpha est élevée, les documents sont composés de plus de sujets et d'une valeur alpha inférieure, les documents contiennent moins de sujets. D'autre part, bêta plus élevé, les sujets sont constitués d'un grand nombre de mots dans le corpus, et avec une valeur bêta inférieure, se compose de quelques mots.
Nombre de sujets: nombre de thèmes à extraire du corpus. Les chercheurs ont développé des approches pour obtenir un nombre optimal de sujets en utilisant le score de divergence de Kullback Leibler.. Je ne discuterai pas cela en détail., car c'est trop mathématique. Pour comprendre, on peut s'y référer[1] papier original sur l'utilisation de la divergence KL.
Nombre de termes de sujet: nombre de termes composés dans un même sujet. Il est généralement décidé en fonction de l'exigence. Si l'énoncé du problème parle d'extraction de thèmes ou de concepts, il est recommandé de sélectionner un plus grand nombre, si l'énoncé du problème parle d'extraction de caractéristiques ou de termes, un petit nombre est recommandé.
Nombre d'itérations / passé: nombre maximal d'itérations autorisées à l'algorithme LDA pour la convergence.
Vous pouvez en apprendre davantage sur les thèmes de modélisation ici.
Exécution en Python
Préparation des documents
Voici les exemples de documents qui sont combinés pour former un corpus.
doc1 = "Sugar is bad to consume. My sister likes to have sugar, but not my father." doc2 = "My father spends a lot of time driving my sister around to dance practice." doc3 = "Doctors suggest that driving may cause increased stress and blood pressure." doc4 = "Sometimes I feel pressure to perform well at school, but my father never seems to drive my sister to do better." doc5 = "Health experts say that Sugar is not good for your lifestyle."
# compile documents doc_complete = [doc1, doc2, doc3, doc4, doc5]
Nettoyage et prétraitement
Le nettoyage est une étape importante avant toute tâche de text mining, dans cette étape, nous supprimerons les signes de ponctuation, mots vides et nous normaliserons le corpus.
``` from nltk.corpus import stopwords from nltk.stem.wordnet import WordNetLemmatizer import stringstop = set(stopwords.words('english')) exclude = set(string.punctuation) lemma = WordNetLemmatizer()def clean(doc): stop_free = " ".join([i for i in doc.lower().split() if i not in stop]) punc_free="".join(ch for ch in stop_free if ch not in exclude) normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split()) return normalized
doc_clean = [clean(doc).split() for doc in doc_complete] ```
Préparation de la matrice des délais du document
Tous les documents texte combinés sont appelés corpus. Pour exécuter n'importe quel modèle mathématique sur un corpus de texte, il est recommandé de le convertir en une représentation matricielle. Le modèle LDA recherche des modèles de termes répétitifs dans la matrice DT. Python fournit de nombreuses excellentes bibliothèques pour les pratiques d'exploration de texte, “gemme” c'est l'une de ces bibliothèques propres et belles pour gérer les données de texte. Est évolutif, robuste et efficace. Le code suivant montre comment convertir un corpus en un tableau de documents et de termes.
```# Importing Gensim
import gensim
from gensim import corpora
# Creating the term dictionary of our courpus, where every unique term is assigned an index. dictionary = corpora.Dictionary(doc_clean)
# Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above.
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean] ```
Exécution du modèle LDA
L'étape suivante consiste à créer un objet pour le modèle LDA et à l'entraîner dans la matrice Document-Terme. La formation a également besoin de certains paramètres comme entrée qui sont expliqués dans la section précédente. Le module gensim permet à la fois l'estimation du modèle LDA à partir d'un corpus d'apprentissage et l'inférence de la répartition des sujets dans des documents nouveaux et inédits.
```# Creating the object for LDA model using gensim library
Lda = gensim.models.ldamodel.LdaModel
# Running and Trainign LDA model on the document term matrix.ldamodel = Lda(doc_term_matrix, num_topics=3, id2word = dictionary, passes=50)
```
Résultats
``` print(ldamodel.print_topics(num_topics=3, num_words=3)) ['0.168*health + 0.083*sugar + 0.072*bad,
'0.061*consume + 0.050*drive + 0.050*sister,
'0.049*pressur + 0.049*father + 0.049*sister] ```
Chaque ligne est un sujet avec des termes et des poids individuels. Le sujet 1 peut être appelé mauvaise santé et le sujet 3 peut être appelé famille.
Conseils pour générer des résultats de modélisation de sujet
Les résultats des modèles thématiques dépendent totalement des caractéristiques (termes) présent dans le corpus. Le corpus est représenté comme une matrice de termes du document, ce qui est généralement très rare dans la nature. La réduction de la dimensionnalité du tableau peut améliorer les résultats de la modélisation thématique. D'après mon expérience pratique, il y a peu d'approches qui fonctionnent.
1. Filtre de fréquence – Organiser chaque terme selon sa fréquence. Les termes avec des fréquences plus élevées sont plus susceptibles d'apparaître dans les résultats par rapport à ceux avec des fréquences basses. Les termes de basse fréquence sont essentiellement des caractéristiques faibles du corpus, c'est donc une bonne pratique de se débarrasser de toutes ces caractéristiques faibles. Une analyse exploratoire des termes et de leur fréquence peut aider à choisir quelle valeur de fréquence doit être considérée comme un seuil..
2. Pièce de filtre d'étiquette vocale: Le filtre de balise POS a plus à voir avec le contexte des fonctions qu'avec la fréquence de la même. La modélisation de sujet tente de tracer les modèles récurrents de termes dans les sujets. Malgré cela, tous les termes peuvent ne pas avoir la même importance contextuelle. Par exemple, la balise POS IN contient des termes tels que – “dans”, “sur”, “sauf”. “CD” contient – “un”, “De”, “cent”, etc. “MARYLAND” contient “il peut”, “devrait”, etc. Ces termes sont les mots de support d'une langue et peuvent être supprimés en étudiant ses balises de publication..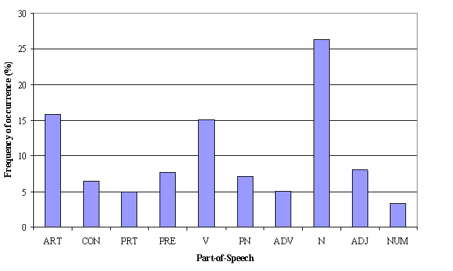
3. Lot Wise LDA –Pour récupérer les termes les plus importants du sujet, un corpus peut être divisé en lots de tailles fixes. L'exécution de LDA plusieurs fois sur ces lots donnera des résultats différents; malgré cela, les meilleurs termes de sujet seront l'intersection de tous les lots.
Noter: Si vous voulez apprendre la modélisation de sujet en détail et aussi faire un projet en l'utilisant, nous avons donc une cours en vidéo et PNL, couvrant la modélisation de thèmes et son implémentation en Python.
Modélisation de thèmes pour la sélection de fonctionnalités
Parfois, LDA peut également être utilisé comme technique de sélection de caractéristiques. Prenons un exemple d'obstacle de classification de texte où les données d'entraînement contiennent des documents par catégories. Si LDA s'exécute sur des ensembles de documents de catégorie. Suivi de la suppression des termes de sujet communs dans les résultats de différentes catégories, les meilleures caractéristiques pour une catégorie seront obtenues.
Remarques finales
Avec ça, nous arrivons à la fin du tutoriel sur la modélisation de thèmes. J'espère que cela vous aidera à améliorer vos connaissances sur le travail avec des données textuelles. Pour profiter au maximum de ce tutoriel, Je vous propose de pratiquer les codes côte à côte et de vérifier les résultats.
Le message a-t-il été utile? Veuillez partager avec nous si vous avez déjà effectué un type d'analyse similaire. Faites-nous part de vos réflexions sur ce post dans la case ci-dessous..
Les références
- http://link.springer.com/chapter/10.1007/978-3-642-13657-3_43





