introduction:
Dans cet article, nous apprendrons tous les concepts statistiques importants requis pour les rôles en science des données.
Table des matières:
- Différence entre paramètre et statistique
- Les statistiques et leurs types
- Types de données et niveaux de mesure
- Moments de décision d'affaires
- Théorème central limite (CLT)
- Distributions de probabilité
- Représentations graphiques
- Tests d'hypothèses
1. Différence entre paramètre et statistique
Dans notre quotidien, nous continuons à parler de Population et de spectacles. Ensuite, il est très important de connaître la terminologie pour représenter la population et l'échantillon.
Un paramètre est un nombre qui décrit les données de population. Et une statistique est un nombre qui décrit les données d'un échantillon.
2. Les statistiques et leurs types
La définition Wikipédia des statistiques indique que “est une discipline qui traite de la compilation, organisation, une analyse, interprétation et présentation des données”.
Signifie que, dans le cadre de l'analyse statistique, nous collectons, organiser et extraire des informations significatives à partir des données, soit par des visualisations ou des explications mathématiques.
Les statistiques sont généralement classées en deux types:
- Statistiques descriptives
- Statistiques déductives
Statistiques descriptives:
Comme son nom l'indique dans les statistiques descriptives, Nous décrivons les données en utilisant les distributions moyennes, Écart-type, Graphiques ou probabilité.
Essentiellement, dans le cadre des statistiques descriptives, on mesure ce qui suit:
- La fréquence: non. nombre de fois qu'un point de données se produit
- Tendance centrale: la centralité des données: médias, moyen et mode.
- Dispersion: l'étendue des données: rang, variance et écart type
- La mesure du poste: percentiles et plages de quantiles
Statistiques déductives:
Dans les statistiques inférentielles, nous estimons les paramètres de population. Ou nous effectuons des tests d'hypothèses pour évaluer les hypothèses émises sur les paramètres de la population..
En termes simples, nous interprétons le sens des statistiques descriptives en les inférant à la population.
Par exemple, nous menons une enquête sur le nombre de deux-roues dans une ville. Supposons que la ville a une population totale de 5L personnes. Donc, nous avons pris un échantillon de 1000 gens, car il est impossible d'effectuer une analyse de l'ensemble des données de la population.
De l'enquête réalisée, on constate que 800 des gens de 1000 (800 de 1000 il est 80%) ce sont des deux-roues. Ensuite, nous pouvons inférer ces résultats à la population et conclure que les personnes 4L de la population 5L sont des deux-roues.
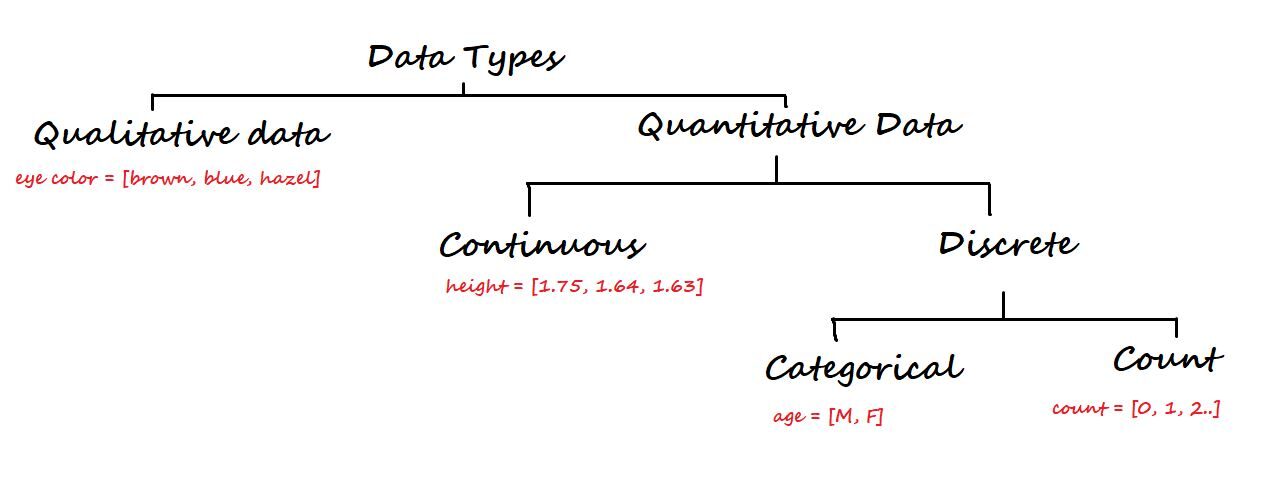
3. Types de données et niveau de mesure
A un niveau supérieur, les données sont classées en deux types: Qualitatif Oui Quantitatif.
Les données qualitatives ne sont pas numériques. Certains des exemples sont la couleur des yeux, marque de voiture, la ville, etc.
D'un autre côté, les données quantitatives sont numériques et à nouveau divisées en données continues et discrètes.
Données continues: Peut être représenté au format décimal. Quelques exemples sont la hauteur, poids, conditions météorologiques, distance, etc.
Données discrètes: Ne peut pas être représenté au format décimal. Quelques exemples sont le nombre d'ordinateurs portables, le nombre d'élèves dans une classe.
Les données discrètes sont divisées en données catégorielles et de comptage.
Données catégorielles: représentent le type de données qui peuvent être divisées en groupes. Certains exemples sont l'âge, sexe, etc.
Compter les données: Ces données contiennent des entiers non négatifs. Exemple: nombre d'enfants qu'un partenaire a.
Niveau de mesure
Dans les statistiques, le niveau de mesure est une classification qui décrit la relation entre les valeurs d'une variable.
Nous avons quatre niveaux fondamentaux de mesure. Fils:
- Échelle nominale
- Échelle ordinaire
- Échelle d'intervalle
- Échelle de proportion
1. Échelle nominale: Cette échelle contient le moins d'informations puisque les données n'ont que des noms / Étiquettes. Peut être utilisé pour le classement. Nous ne pouvons pas effectuer d'opérations mathématiques sur des données nominales car il n'y a pas de valeur numérique pour les options (les numéros associés aux noms ne peuvent être utilisés que comme étiquettes).
Exemple: A quel pays appartenez-vous? Inde, Japon, Corée.
2. Échelle ordinaire: Par rapport à l'échelle nominale, l'échelle ordinale a plus d'informations car avec les étiquettes, a l'ordre / adresse.
Exemple: Le niveau de revenu: revenu élevé, revenu moyen, faibles revenus.
3. Échelle d'intervalle: C'est une échelle numérique. L'échelle d'intervalle a plus d'informations que les échelles ordinales nominales. Avec la commande, nous connaissons la différence entre les deux variables (l'intervalle indique la distance entre deux entités).
La moyenne peut être utilisée, la médiane et le mode pour décrire les données.
Exemple: Température, le revenu, etc.
4. Échelle de rapport: L'échelle de ratio contient le plus d'informations sur les données. Contrairement aux trois autres échelles, l'échelle de rapport peut accueillir un vrai point zéro. On dit simplement que l'échelle de ratio est la combinaison d'échelles Nominal, Ordinal et Intercal.
Exemple: vrai poids, la taille, etc.
4. Moments de décision d'affaires
Nous avons quatre moments de décision commerciale qui nous aident à comprendre les données.
4.1. Mesures de tendance centrale
(Aussi connu comme une décision d'affaires en premier lieu)
Parler de la centralité des données. pour le simplifier, fait partie de l'analyse statistique descriptive dans laquelle une seule valeur au centre représente l'ensemble des données.
La tendance centrale d'un ensemble de données peut être mesurée par:
Vouloir dire: C'est la somme de tous les points de données divisée par le nombre total de valeurs dans l'ensemble de données. On ne peut pas toujours se fier à la moyenne car elle est influencée par les valeurs aberrantes.
Médian: C'est la valeur intermédiaire d'un ensemble de données ordonné / organiser. Si la taille de l'ensemble de données est paire, la médiane est calculée en faisant la moyenne des deux valeurs moyennes.
Façon: C'est la valeur la plus répétée dans l'ensemble de données. Les données avec un seul mode sont appelées unimodales, les données avec deux modes sont appelées bimodales et les données avec plus de deux modes sont appelées multimodales.
4.2. Mesures de dispersion
(Aussi connu comme une deuxième décision d'affaires)
Parlez de la diffusion des données de votre centre.
La dispersion peut être mesurée en utilisant:
Différence: C'est la distance quadratique moyenne de tous les points de données à partir de sa moyenne. Le problème avec la variance est que les unités seront également au carré.
Écart-type: C'est la racine carrée de la variance. Aide à récupérer les disques d'origine.
Distance: C'est la différence entre les valeurs maximales et minimales d'un ensemble de données.
La mesure |
Ville |
Spectacles |
| Vouloir dire | µ = (Xje)/NORD | x̄ = (xje)/Nord |
| Médian | La valeur moyenne des données | La valeur moyenne des données |
| Façon | Valeur la plus survenue | Valeur la plus survenue |
| Différence | ??2 = (Xje – µ)2/NORD | s2 = (xje – X )2/ (n-1) |
| Écart-type | = racine carrée ((Xje – µ)2/NORD) | s = racine carrée ((xje – X )2/ (n-1)) |
| Distance | Maximum minimum | Maximum minimum |
4.3. Obliquité
(Il est également connu comme une décision d'affaires dans le troisième moment)
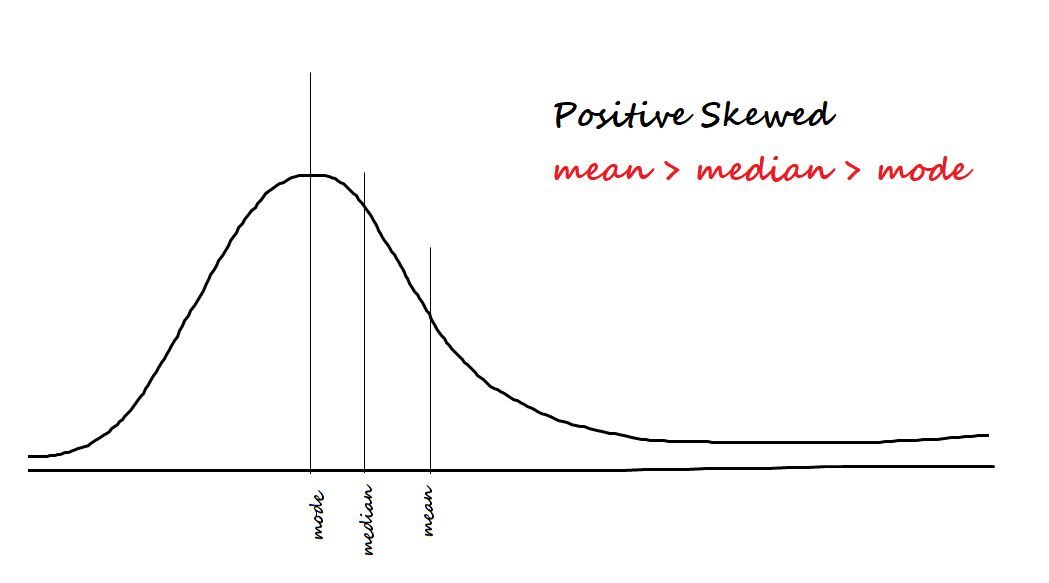
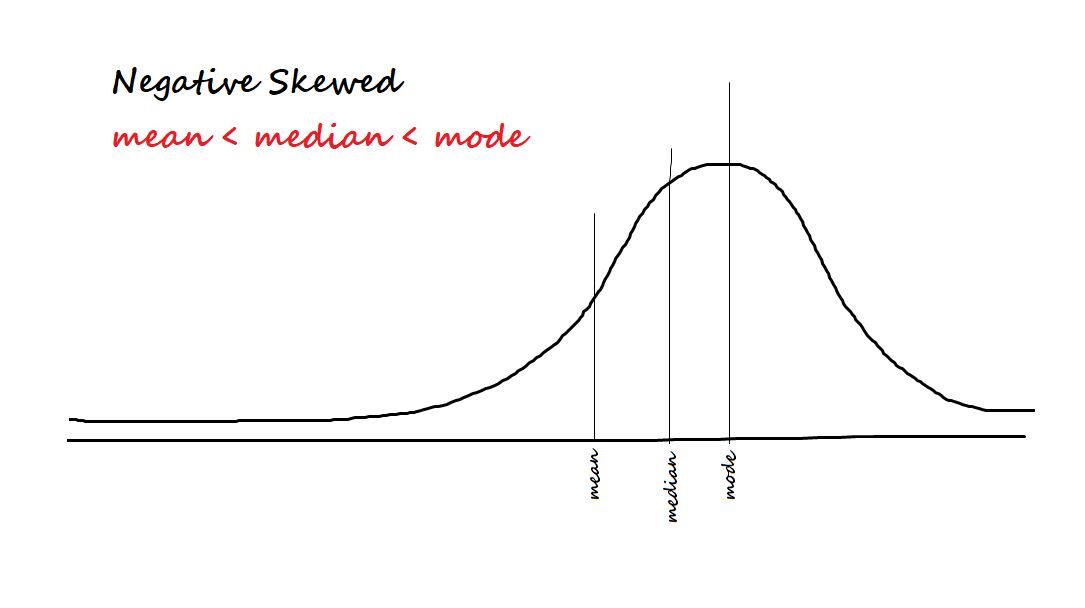
Mesurer l'asymétrie des données. Les deux types d'asymétrie sont:
Positif / incliné vers la droite: Les données sont dites biaisées positivement si la plupart des données sont concentrées sur le côté gauche et ont une queue à droite.
Négatif / incliné vers la gauche: Les données sont dites biaisées négativement si la plupart des données sont concentrées sur le côté droit et ont une queue vers la gauche.
La formule d'asymétrie est moi [(X - µ)/ ?? ]) 3 = Z3
4.4. Curtose
(Également connue sous le nom de décision commerciale au quatrième moment)
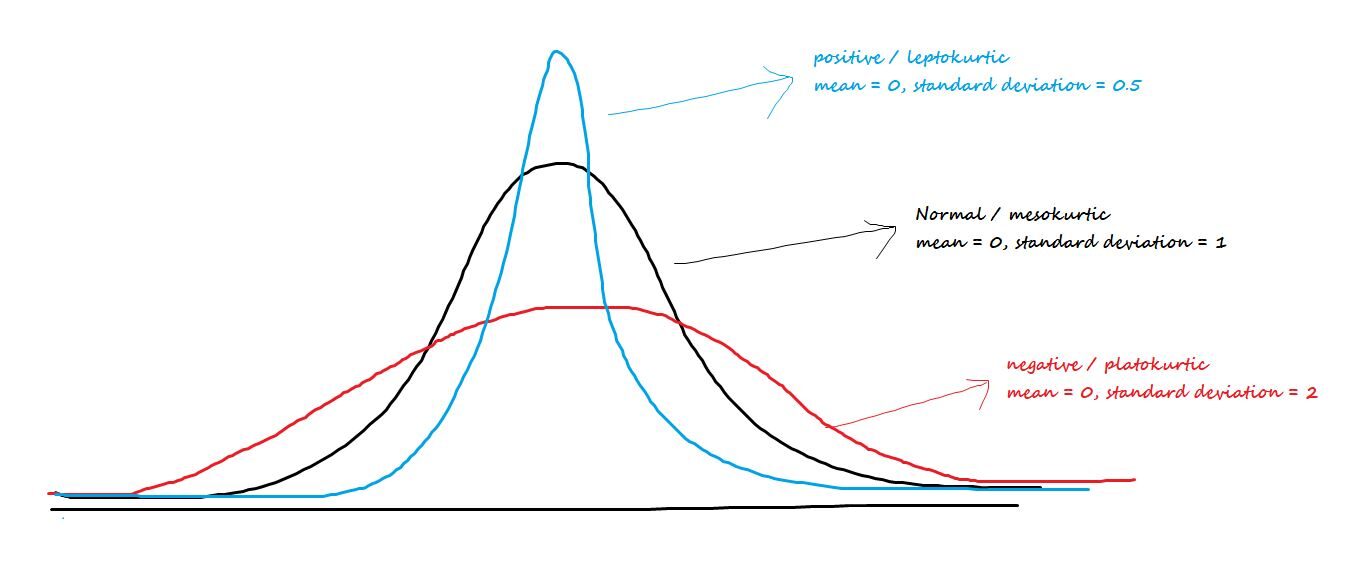
Parler du pic central ou de l'embonpoint des queues. Les trois types d'aplatissement sont:
Positif / leptocurtique: A des becs pointus et des queues plus légères.
Négatif / Platokurtico: A un bec large et une queue plus épaisse.
mésocurtique: Distribution normale
La formule d'aplatissement est moi [(X - µ)/ ?? ]) 4-3 = Z4– 3
Ensemble, l'asymétrie et l'aplatissement sont appelés statistiques de forme.
5. Théorème central limite (CLT)
Au lieu d'analyser les données de l'ensemble de la population, nous prenons toujours un échantillon pour analyse. Le problème avec l'échantillonnage est que « la moyenne de l'échantillon est une variable aléatoire, varie pour différents échantillons ". Et l'échantillon aléatoire que nous tirons ne peut jamais être une représentation exacte de la population. Ce phénomène est appelé variation d'échantillon.
Pour annuler la variation de l'échantillon, on utilise le théorème central limite. Et d'après le théorème central limite:
1. La distribution des moyennes de l'échantillon suit une distribution normale si la population est normale.
2. la distribution des moyennes de l'échantillon suit une distribution normale même si la population n'est pas normale. Mais la taille de l'échantillon doit être suffisamment grande.
3. La moyenne générale de toutes les valeurs moyennes de l'échantillon nous donne la moyenne de la population.
4. Théoriquement, la taille de l'échantillon doit être 30. Et pratiquement, la condition sur la taille de l'échantillon (m) il est:
m> 10 (k3)2, où k3 est l'asymétrie de l'échantillon.
m> 10 (k4), où K4 est l'échantillon d'aplatissement.
6. Distributions de probabilité
En termes statistiques, une fonction de distribution est une expression mathématique qui décrit la probabilité de différents résultats possibles pour une expérience.
S'il vous plait, lisez cet article sur les différents types de distributions de probabilité.
7. Représentations graphiques
La représentation graphique fait référence à l'utilisation de tableaux ou de graphiques pour visualiser, analyser et interpréter des données numériques.
Pour une seule variable (analyse univariée), nous avons un graphique à barres, un schéma de ligne, un diagramme de fréquence, un tracé de points, une boîte à moustaches et le tracé QQ normal.
Nous discuterons de la boîte à moustaches et du graphique QQ normal.
7.1. Box plot
Une boîte à moustaches est un moyen de visualiser la distribution des données sur la base d'un résumé à cinq chiffres. Utilisé pour identifier les valeurs aberrantes dans les données.
Les cinq nombres sont au minimum, premier quartile (T1), médian (T2), troisième quartile (T3) et maxi.
La zone de la boîte contiendra le 50% des données. Le 25% le bas de la région de données s'appelle la moustache du bas et le bas 25% le haut de la région de données est appelé Top Whisker.
La région interquartile (IQR) est la différence entre le troisième et le premier quartile. IQR = Q3 – T1.
Les valeurs aberrantes sont les points de données sous la moustache inférieure et au-delà de la moustache supérieure.
La formule pour trouver les valeurs aberrantes est Valeur aberrante = Q ± 1,5 * (IQR)
Les valeurs aberrantes au-dessous de la moustache inférieure sont données comme T1 – 1,5 * (IQR)
Les valeurs aberrantes au-delà de la moustache supérieure sont données comme T3 + 1.5 * (IQR)
Voir mon article sur la détection des valeurs aberrantes à l'aide d'une boîte à moustaches.
7.2. Graphique QQ normal
Un diagramme QQ normal est une sorte de diagramme de dispersion qui est dessiné en créant deux ensembles de quantiles.. Il est utilisé pour vérifier si les données sont normales ou non.
Sur l'axe des x, nous avons les scores Z et sur l'axe des y, nous avons les quantiles réels de l'échantillon. Si le nuage de points forme une ligne droite, les données sont dites normales.
8. Tests d'hypothèses
Le test d'hypothèse dans les statistiques est un moyen de tester les hypothèses faites sur les paramètres de la population.
Voir mon article sur les tests d'hypothèses pour le lire en détail.
Remarques finales:
Merci d'avoir lu jusqu'au bout. A la fin de cet article, nous connaissons les concepts statistiques importants.
j'espère que cet article est instructif. N'hésitez pas à le partager avec vos camarades.
D'autres articles de mon blog
N'hésitez pas à consulter mes autres articles de blog depuis mon profil DataPeaker.
Vous pouvez me trouver dans LinkedIn, Twitter au cas où vous voudriez vous connecter. j'aimerai me connecter avec toi.
Pour un échange d'idées immédiat, écris moi [email protégé].
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





