- s = état
- a = action
- r = récompense
- t = pas de temps
- γ = taux d'actualisation
- α = taux d'apprentissage
Le taux d'apprentissage et le taux d'actualisation se situent entre 0 Oui 1. Ce dernier détermine à quel point nous nous soucions de la récompense future. Le plus proche de 1, nous nous soucions plus.
L'inconvénient de Q-learning est qu'il a des problèmes avec d'énormes espaces d'action et d'état. Mémoriser chaque paire d'actions et d'états possibles prend beaucoup de mémoire. Pour cette raison, nous devons combiner le Q-learning avec les techniques de Deep Learning.
Apprentissage en profondeur Q
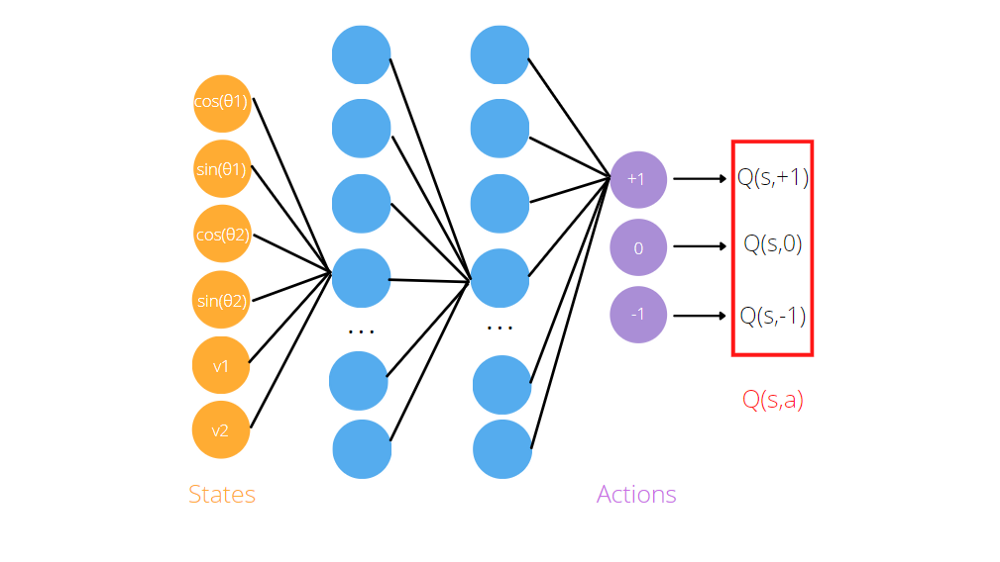
Comme nous l'avons vu, l'algorithme Q-learning a besoin d'approximations de fonction, comme réseaux de neurones artificiels, mémoriser des triplés (état, action, valeur Q). L'idée du Deep Q learning est d'utiliser des réseaux de neurones pour prédire les valeurs de Q pour chaque action compte tenu de l'état. Si on reconsidére le jeu Acrobot, lo pasamos a la neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. artificial como entrada la información es sobre el agente (sin et cos des angles communs, vitesses). Pour obtenir les pronostics, necesitamos entrenar la red antes y definir la Fonction de perteLa fonction de perte est un outil fondamental de l’apprentissage automatique qui quantifie l’écart entre les prédictions du modèle et les valeurs réelles. Son but est de guider le processus de formation en minimisant cette différence, permettant ainsi au modèle d’apprendre plus efficacement. Il existe différents types de fonctions de perte, tels que l’erreur quadratique moyenne et l’entropie croisée, chacun adapté à différentes tâches et..., qui est généralement la différence entre la valeur Q prédite et la valeur Q cible.
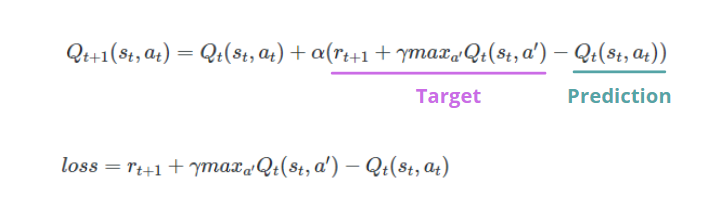
A diferencia del enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans..., nous n'avons aucune étiquette qui identifie la valeur Q correcte pour chaque paire état-action. En DQL, nous initialisons deux réseaux de neurones artificiels identiques, appels Réseau de destination Oui Réseau politique. Le premier sera utilisé pour calculer les valeurs cibles, tandis que le second pour déterminer la prédiction.
Par exemple, le modèle du jeu Acrobat est un réseau de neurones artificiels qui prend en entrée des observations environnementales, le sin et le cos des deux angles articulaires de rotation et des deux vitesses angulaires. Renvoie trois sorties, Q (s, + 1), Q (s, -1), Q (s, 0), où s est l'état, passé comme entrée au réseau. En réalité, l'objectif du réseau de neurones est de prédire les performances attendues de chaque action en fonction de l'entrée actuelle.
Rejouer l'expérience
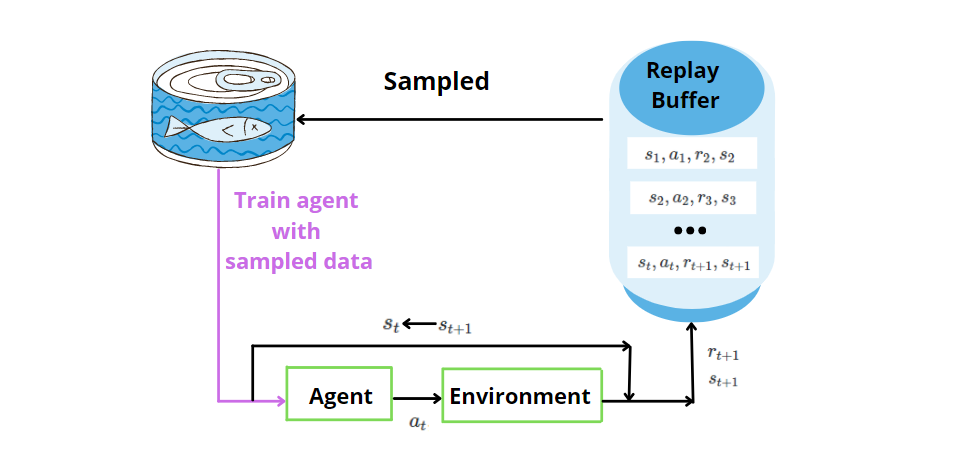
ANN ne suffit pas seul. L'expérience est une technique dans laquelle nous stockons les données passées découvertes par l'agent pour (état, action, récompense, état suivant) à chaque pas du temps. Plus tard, nous échantillonnons au hasard la mémoire pour un mini lot d'expérience et l'utilisons pour entraîner le réseau de neurones artificiels. Par échantillonnage aléatoire, nous permettons de fournir des données non corrélées au modèle de réseau de neurones et d'améliorer l'efficacité des données.
Exploration vs Exploitation
L'exploration et l'exploitation sont des concepts clés de l'algorithme Deep RL. Fait référence à la façon dont l'agent sélectionne les actions. Que sont l'exploration et l'exploitation? Supposons que nous voulions aller au restaurant. L'exploration, c'est quand vous voulez essayer un nouveau restaurant, tandis que l'exploitation c'est quand tu veux rester dans ta zone de confort, vous irez donc directement dans votre restaurant préféré. Idem pour l'agent. Au début, veut explorer l'environnement. En interagissant avec l'environnement, prendre des décisions plus fondées sur l'exploitation que sur l'exploration.
Il y a deux stratégies possibles:
- -gourmand, où l'agent effectue une action aléatoire avec une probabilité, puis explorez l'environnement et sélectionnez l'action gourmande avec probabilité 1-ε, alors on est en situation d'exploitation.
- suave-max, où l'agent sélectionne les actions optimales en fonction des valeurs Q renvoyées par le réseau de neurones artificiels.
Toutes nos félicitations! Vous comprenez maintenant les concepts de RL et DRL à travers l'exemple d'Acrobot qui vous a présenté ce nouveau monde. L'apprentissage Deep Q a attiré beaucoup d'attention après des applications dans les jeux Atari et Go. J'espère que ce guide ne vous fait pas peur et vous encourage à approfondir le sujet. Merci pour la lecture. Passez une bonne journée!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





