Fr Apprentissage automatique, nous utilisons divers types d'algorithmes pour permettre aux machines d'apprendre les relations au sein des données fournies et de faire des prédictions basées sur des modèles ou des règles identifiés dans l'ensemble de données. Ensuite, la régression est une technique d'apprentissage automatique où le modèle prédit la sortie sous forme de valeur numérique continue.
La source: https://www.hindish.com
L'analyse de régression est souvent utilisée en finance, investissements et autres, et découvrir la relation entre une seule variable dépendante (variable cible) qui dépend de plusieurs indépendants. Par exemple, prévoir les prix des maisons, la bourse ou le salaire d'un employé, etc. sont les plus courants
problèmes de régression.
Les algorithmes que nous allons couvrir sont:
1. Régression linéaire
2. Arbre de décision
3. Régression vectorielle de support
4. Régression de boucle
5. Forêt aléatoire
1. Régression linéaire
La régression linéaire est un algorithme d'apprentissage automatique utilisé pour l'apprentissage supervisé. La régression linéaire effectue la tâche de prédire une variable dépendante (objectif) en fonction des variables indépendantes données. Ensuite, cette technique de régression trouve une relation linéaire entre une variable dépendante et les autres variables indépendantes étant donné. Donc, le nom de cet algorithme est Régression Linéaire.
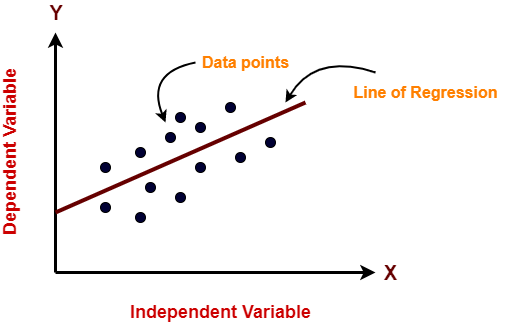
Dans la figure ci-dessus, sur l'axe X est la variable indépendante et sur l'axe Y est la sortie. La droite de régression est la droite qui correspond le mieux à un modèle. Et notre objectif principal dans cet algorithme est de trouver la ligne qui correspond le mieux.
Avantages:
- La régression linéaire est facile à mettre en œuvre.
- Moins de complexité par rapport aux autres algorithmes.
- La régression linéaire peut provoquer un surapprentissage, mais cela peut être évité en utilisant certaines techniques de réduction de dimensionnalité, techniques de régularisation et de validation croisée.
Les inconvénients:
- Les valeurs aberrantes affectent sérieusement cet algorithme.
- Il simplifie à l'excès les problèmes du monde réel en supposant une relation linéaire entre les variables, donc pas recommandé pour les cas d'utilisation pratiques.
Mise en œuvre
importer numpy en tant que np à partir de sklearn.linear_model importer LinearRegression X = np.tableau([[2, 1], [3, 2], [4, 2], [5, 3]]) # y = 1 * x_0 + 2 * x_1 + 3 y = np.dot(X, np.array([1, 2])) + 3 lr = régression linéaire().ajuster(X, Oui) lr.predict(np.array([[1, 5]])) Sortir déployer([14.])
2. Arbre de décision
Les modèles d'arbre de décision peuvent être appliqués à toutes les données qui contiennent des caractéristiques numériques et des caractéristiques catégorielles. Les arbres de décision sont bons pour capturer l'interaction non linéaire entre les caractéristiques et la variable cible.. Les arbres de décision coïncident en quelque sorte avec la pensée au niveau humain, il est donc très intuitif de comprendre les données.
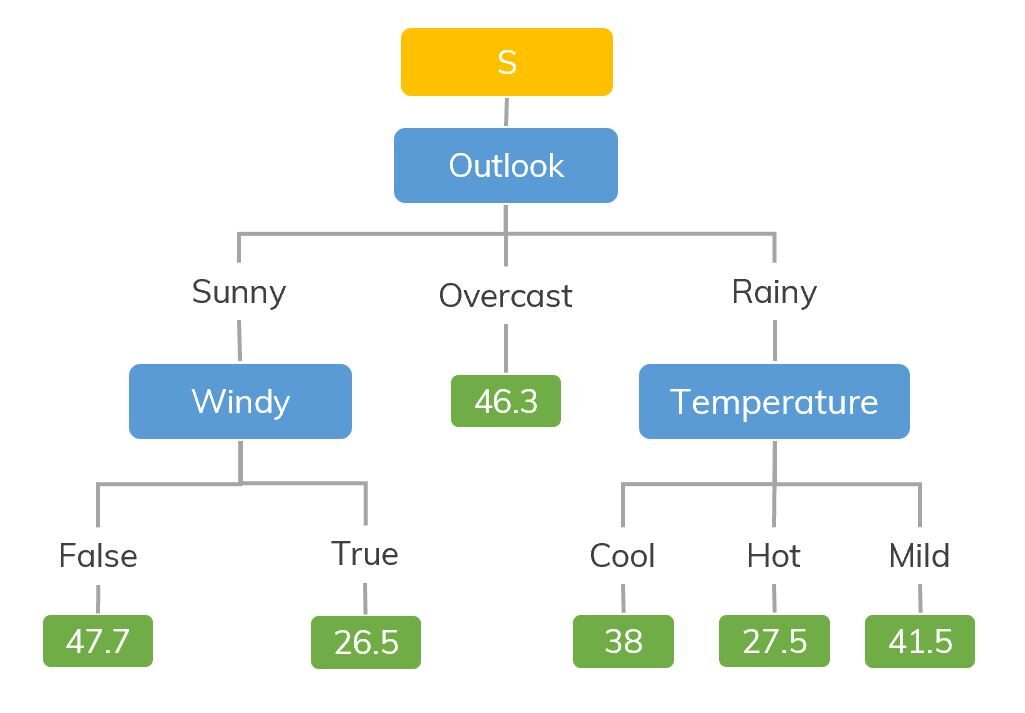
La source: https://dinhanhthi.com
Par exemple, si nous classons combien d'heures un enfant joue dans un climat particulier, l'arbre de décision ressemble un peu à ceci dans l'image.
Ensuite, en résumé, un arbre de décision est un arbre où chaque nœud représente une caractéristique, chaque branche représente une décision et chaque feuille représente un résultat (valeur numérique pour la régression).
Avantages:
- Facile à comprendre et à interpréter, visuellement intuitif.
- Peut travailler avec des caractéristiques numériques et catégorielles.
- Nécessite peu de pré-traitement des données: pas besoin d'encodage à chaud, variables muettes, etc.
Les inconvénients:
- A tendance à sur-ajuster.
- Un petit changement dans les données a tendance à faire une grande différence dans l'arborescence, ce qui cause l'instabilité.
Mise en œuvre
importer numpy en tant que np depuis sklearn.tree importer DecisionTreeRegressor rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axe=0) y = np.sin(X).effilochage() Oui[::5] += 3 * (0.5 - rng.rand(16)) # Ajuster le modèle de régression regr = DecisionTreeRegressor(profondeur_max=2) regr.fit(X, Oui) # Prédire X_test = np.arange(0.0, 5.0, 1)[:, par exemple, nouvel axe] result = regr.predict(X_test) imprimer(résultat) Sortir: [ 0.05236068 0.71382568 0.71382568 0.71382568 -0.86864256]
3. Régression vectorielle de support
Vous devez avoir entendu parler de SVM, c'est-à-dire, Machine à vecteur de soutien. SVR utilise également la même idée de SVM mais ici il essaie de prédire les valeurs réelles. Cet algorithme utilise des hyperplans pour séparer les données. Au cas où cette séparation n'est pas possible, utilisez donc l'astuce du noyau où la dimension augmente, puis les points de données deviennent séparables par hyperplan.
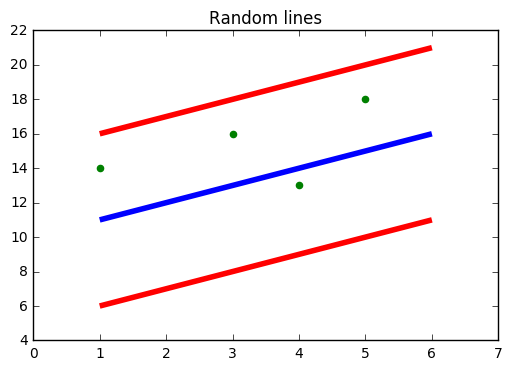
La source: https://www.moyen.com
Dans la figure ci-dessus, la ligne bleue est l'hyperplan; La ligne rouge est la ligne limite
Tous les points de données sont à l'intérieur de la ligne de délimitation (ligne rouge). L'objectif principal de SVR est essentiellement de considérer les points qui se trouvent dans la ligne de limite.
Avantages:
- Robuste aux valeurs aberrantes.
- Excellente généralisabilité
- Précision de prédiction élevée.
Les inconvénients:
- Ne convient pas aux grands ensembles de données.
- Ils ne fonctionnent pas très bien lorsque l'ensemble de données a plus de bruit.
Mise en œuvre
de sklearn.svm importer SVR importer numpy en tant que np rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axe=0) y = np.sin(X).effilochage() Oui[::5] += 3 * (0.5 - rng.rand(16)) # Ajuster le modèle de régression svr = SVR().ajuster(X, Oui) # Prédire X_test = np.arange(0.0, 5.0, 1)[:, par exemple, nouvel axe] svr.predict(X_test)
Sortir: déployer([-0.07840308, 0.78077042, 0.81326895, 0.08638149, -0.6928019 ])
4. Régression de boucle
- LASSO signifie Absolute Minimum Selection Shrinkage Operator. Le retrait est essentiellement défini comme un attribut ou une contrainte de paramètre.
- L'algorithme fonctionne en trouvant et en appliquant une contrainte aux attributs du modèle qui entraîne la réduction à zéro des coefficients de régression de certaines variables..
- Les variables avec un coefficient de régression de zéro sont exclues du modèle.
- Donc, l'analyse de régression en boucle est essentiellement une méthode de sélection et de contraction de variables et aide à déterminer quels prédicteurs sont les plus importants.
Avantages:
Les inconvénients:
- LASSO sélectionnera une seule entité parmi un groupe d'entités corrélées
- Les caractéristiques sélectionnées peuvent être fortement asymétriques.
Mise en œuvre
de sklearn importer linear_model importer numpy en tant que np rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axe=0) y = np.sin(X).effilochage() Oui[::5] += 3 * (0.5 - rng.rand(16)) # Ajuster le modèle de régression lassoReg = modèle_linéaire.Lasso(alpha=0.1) lassoReg.fit(X,Oui) # Prédire X_test = np.arange(0.0, 5.0, 1)[:, par exemple, nouvel axe] lassoReg.predict(X_test)
Sortir: déployer([ 0.78305084, 0.49957596, 0.21610108, -0.0673738 , -0.35084868])
5. Retourneur de forêt aléatoire
Les forêts aléatoires sont un ensemble (combinaison) arbres de décision. C'est un algorithme d'apprentissage supervisé qui est utilisé pour la classification et la régression. Les données d'entrée sont transmises à travers plusieurs arbres de décision. Il est exécuté en construisant un nombre différent d'arbres de décision au moment de la formation et en générant la classe qui est le mode des classes (pour le classement) ou prédiction moyenne (pour la régression) d'arbres individuels.
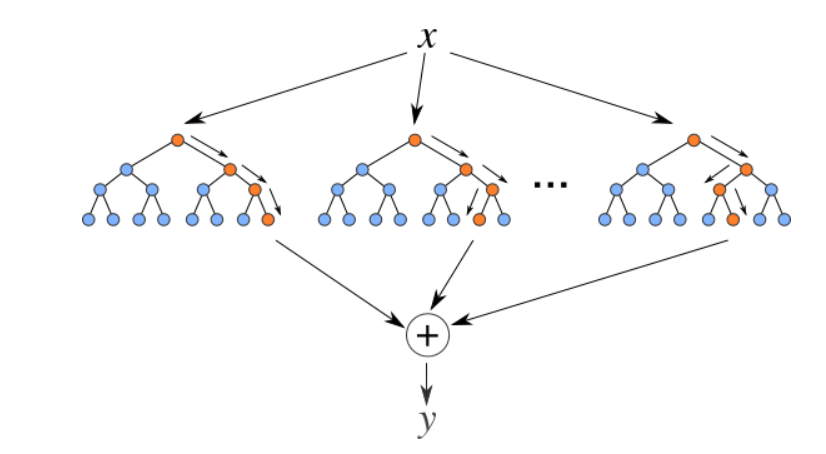
La source: https://levelup.gitconnected.com
Avantages:
- Bon pour apprendre des relations complexes et non linéaires
- Très facile à interpréter et à comprendre.
Les inconvénients:
- Ils ont tendance à sur-ajuster
- L'utilisation de pools de forêts aléatoires plus grands pour des performances plus élevées ralentit leur vitesse et nécessite également plus de mémoire.
Mise en œuvre
de sklearn.ensemble importer RandomForestRegressor à partir de sklearn.datasets importer make_regression X, y = make_regression(n_caractéristiques=4, n_informatif=2, état_aléatoire=0, shuffle=Faux) rfr = RandomForestRegressor(max_profondeur=3) rfr.fit(X, Oui) imprimer(rfr.predict([[0, 1, 0, 1]])) Sortir: [33.2470716]
Remarques finales
Voici quelques algorithmes de régression populaires, il y a beaucoup plus et aussi des algorithmes avancés. Explorez-les aussi. Vous pouvez également suivre ces algorithmes de classification pour augmenter vos connaissances en apprentissage automatique.
Merci d'avoir lu si vous êtes arrivé ici
Connectons-nous LinkedIn
Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..





