Los datos se generan en grandes cantidades en todas partes. Twitter genera más de 12 TB de datos todos los días, Facebook genera más de 25 TB de datos todos los días y Google genera mucho más que estas cantidades todos los días. Dado que estos datos se producen todos los días, necesitamos crear herramientas para manejar datos con un alto
1. Le volume : En la actualidad se almacenan grandes volúmenes de datos para cualquier industria. Los modelos convencionales con datos tan grandes no son factibles.
2. La vitesse : Los datos llegan a alta velocidad y exigen algoritmos de aprendizaje más rápidos.
3. Variété : Las diferentes fuentes de datos disponen diferentes estructuras. Todos estos datos contribuyen a el pronóstico. Un buen algoritmo puede absorber tal variedad de datos.
Un algoritmo predictivo simple como Random Forest en aproximadamente 50 mil puntos de datos y 100 dimensiones tarda 10 minutos en ejecutarse en una máquina de 12 Go de RAM. Los problemas con cientos de millones de observaciones son simplemente imposibles de solucionar con este tipo de máquinas. Pour cela, nos quedan solo dos opciones: utilizar una máquina más fuerte o cambiar la forma en que funciona un algoritmo predictivo. La primera opción no siempre es viable. Dans ce billet, aprenderemos sobre los algoritmos de aprendizaje en línea que están destinados a manejar datos con un volumen y velocidad tan altos con máquinas de rendimiento limitado.
¿En qué se diferencia el aprendizaje en línea de los algoritmos de aprendizaje por lotes?
Si es un principiante en la industria de la analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques...., todo lo de lo que probablemente haya oído hablar se incluirá en la categoría de aprendizaje por lotes. Tratemos de visualizar en qué se diferencia el funcionamiento de los dos.
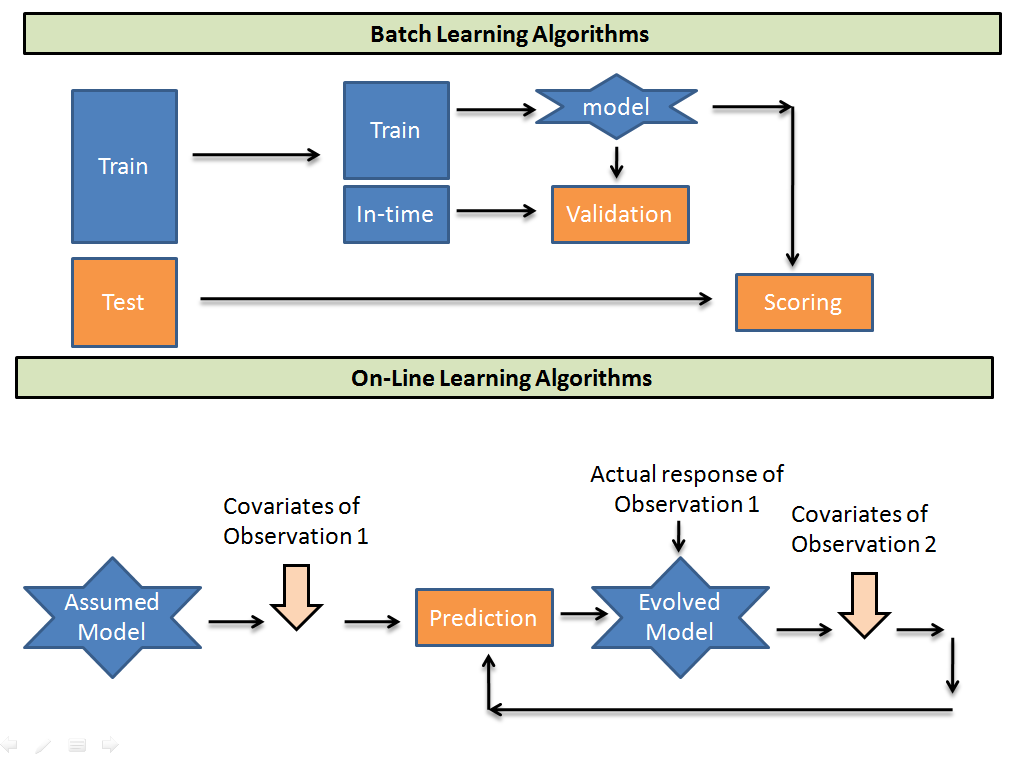
Los algoritmos de aprendizaje por lotes toman lotes de datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... para entrenar un modelo. Después predice la muestra de prueba usando la vinculación encontrada. Alors que, los algoritmos de aprendizaje en línea toman un modelo de conjetura inicial y después toman la observación uno a uno de la población de entrenamiento y recalibran los pesos en cada parámetro de entrada. Aquí hay algunas compensaciones al utilizar los dos algoritmos.
- Computacionalmente mucho más rápido y más eficiente en el espacio. En el modelo en línea, se le posibilita realizar exactamente una pasada de sus datos, por lo que estos algoritmos generalmente son mucho más rápidos que sus equivalentes de aprendizaje por lotes, puesto que la mayoría de los algoritmos de aprendizaje por lotes son de múltiples pasadas. En même temps, dado que no puede reconsiderar sus ejemplos anteriores, regularmente no los almacena para ingresar más adelante en el procedimiento de aprendizaje, lo que significa que tiende a usar una huella de memoria más pequeña.
- Suele ser más fácil de poner en práctica. Dado que el modelo en línea hace que uno pase por encima de los datos, terminamos procesando un ejemplo al mismo tiempo, secuencialmente, a medida que ingresan desde el flujo. Esto de forma general simplifica el algoritmo, si lo hace desde cero.
- Más difícil de mantener en producción. La implementación de algoritmos en línea en producción de forma general necesita que tenga algo que pase constantemente puntos de datos a su algoritmo. Si sus datos cambian y sus selectores de funciones ya no producen resultados útiles, o si hay una latencia de red importante entre los servidores de sus selectores de funciones, o uno de esos servidores deja de funcionar, ou en fait, cualquier cantidad de otras cosas, su aprendiz se acumula y tu salida es basura. Asegurarse de que todo esto funcione correctamente puede ser una prueba.
- Más difícil de examinar en línea. En el aprendizaje en línea, no podemos ofrecer un conjunto de « essais » para la evaluación debido a que no hacemos suposiciones de distribución; si elegimos un conjunto para examinar, estaríamos asumiendo que el conjunto de pruebas es representativo de los datos que estamos operando, y eso es un supuesto distributivo. Étant donné que, en el caso más general, no hay forma de obtener un conjunto representativo que caracterice sus datos, su única opción (encore, en el caso más general) es simplemente observar qué tan bien ha estado funcionando el algoritmo recientemente.
- Comme d'habitude, es más difícil hacerlo « bien ». Como vimos en el último punto, la evaluación en línea del alumno es difícil. Por razones similares, puede resultar muy difícil obtener que el algoritmo se comporte « correctement » automáticamente. Puede ser difícil diagnosticar si su algoritmo o su infraestructura se están comportando mal.
En los casos en los que trabajamos con grandes cantidades de datos, no nos queda más remedio que usar algoritmos de aprendizaje en línea. La única otra alternativa es realizar un aprendizaje por lotes en una muestra más pequeña.
Caso de ejemplo para saber el concepto
Queremos predecir la probabilidad de que llueva hoy. Contamos con un panneauUn panel est un groupe d’experts qui se réunit pour discuter et analyser un sujet spécifique. Ces forums sont courants lors des conférences, Séminaires et débats publics, où les participants partagent leurs connaissances et leurs points de vue. Les panneaux peuvent aborder une variété de domaines, De la science à la politique, et son objectif est d’encourager l’échange d’idées et la réflexion critique entre les participants.... de 11 personas que predicen la clase: Lluvia y no lluvia en diferentes paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet..... Necesitamos diseñar un algoritmo para predecir la probabilidad. Primero inicialicemos algunas denotaciones.
soy predictores individuales
w (je) es el peso dado al i-ésimo predictor
Inicial w (je) para i en [1,11] son todos 1
Predeciremos que lloverá hoy si,
Somme (w (je) para todas las predicciones de lluvia)> Suma (w (je) para todas las predicciones sin lluvia)
Una vez que tenemos la solución real de la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... objectif, ahora enviamos una retroalimentación sobre los pesos de todos los parámetros. En esta circunstancia tomaremos un mecanismo de retroalimentación muy simple. Para cada predicción correcta, mantendremos el mismo peso del predictor. Mientras que para cada predicción incorrecta, dividimos el peso del predictor por 1,2 (taux d'apprentissage). Avec le temps, esperamos que el modelo converja con un conjunto correcto de parámetros. Creamos una simulación con 1000 predicciones hechas por cada uno de los 11 prédicteurs. Así es como salió nuestra curva de precisión,
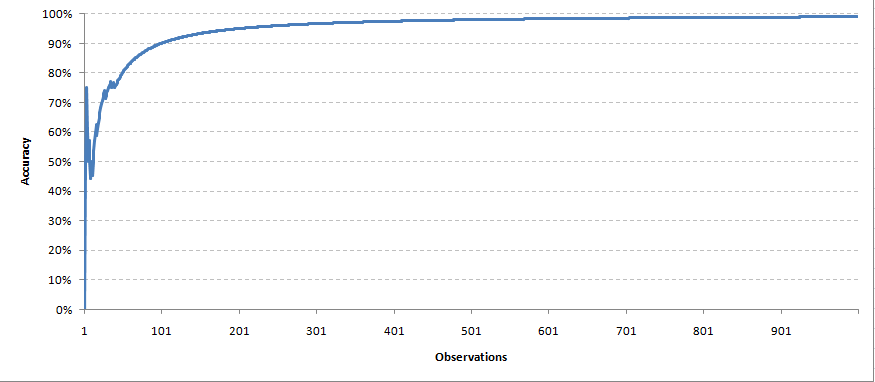
Cada observación se tomó al mismo tiempo para reajustar los pesos. De la même manière, haremos predicciones para los puntos de datos futuros.
Remarques finales
Los algoritmos de aprendizaje en línea son ampliamente utilizados por la industria del comercio electrónico y las redes sociales. No solo es rápido, sino que además tiene la capacidad de capturar cualquier nueva tendencia visible con el tiempo. En este momento se encuentran disponibles una gama de sistemas de retroalimentación y algoritmos convergentes que deben seleccionarse según los requerimientos. En algunos de los siguientes posts, además tomaremos algunos ejemplos prácticos de aplicaciones de algoritmos de aprendizaje en línea.
Le message a-t-il été utile? ¿Ha utilizado antes algoritmos de aprendizaje en línea? Comparta con nosotros esas experiencias. Faites-nous part de vos réflexions sur ce post dans la case ci-dessous..





