Cet article a été publié dans le cadre du Blogathon sur la science des données
Après avoir compris et travaillé avec ce tutoriel pratique, pourra:
- Comprendre ce qu'est l'analyse de cohorte et de cohorte.
- Gestion des valeurs manquantes
- Extraction du mois à partir de la date
- Asignar cohorte a cada transactionLa "transaction" fait référence au processus par lequel un échange de biens a lieu, services ou argent entre deux ou plusieurs parties. Ce concept est fondamental dans le domaine économique et juridique, puisqu’il implique un accord mutuel et la prise en compte de conditions spécifiques. Les transactions peuvent être formelles, sous forme de contrats, ou informel, et sont essentielles au fonctionnement des marchés et des entreprises....
- Asignar indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... de cohorte a cada transacción
- Calculer le nombre de clients uniques dans chaque groupe.
- Créer un tableau de cohorte pour le taux de rétention
- Visualice la tabla de cohortes usando el carte de chaleurUn "carte de chaleur" est une représentation graphique qui utilise des couleurs pour montrer la densité des données dans une zone spécifique. Couramment utilisé dans l’analyse de données, Etudes marketing et comportementales, Ce type de visualisation vous permet d’identifier rapidement les modèles et les tendances. Par des variations chromatiques, Les cartes thermiques facilitent l’interprétation de grands volumes d’informations, aider à prendre des décisions éclairées....
- Interpréter le taux de rétention
Qu'est-ce que l'analyse de cohorte et de cohorte?
Une cohorte est un ensemble d'utilisateurs qui ont quelque chose en commun. Une cohorte traditionnelle, par exemple, diviser les gens par la semaine ou le mois où ils ont été acquis pour la première fois. En se référant à des groupes non dépendants du temps, le terme segment est souvent utilisé au lieu de cohorte.
El análisis de cohortes es una técnica analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques.... descriptiva en el análisis de cohortes. Les clients sont divisés en cohortes mutuellement exclusives, qui sont ensuite suivis dans le temps. Les indicateurs de vanité n'offrent pas le même niveau de perspective que la recherche de cohorte. Aide à une interprétation plus approfondie des modèles de haut niveau en fournissant des mesures du cycle de vie des consommateurs et des produits.
Généralement, il existe trois principaux types de cohortes:
- Cohortes temporelles: les clients qui se sont inscrits pour un produit ou un service pendant une période donnée.
- Cohortes comportementales: les clients qui ont acheté un produit ou souscrit à un service dans le passé.
- Cohortes de taille: faire référence aux différentes tailles de clients qui achètent les produits ou services de l'entreprise.
Cependant, nous ferons Analyse de cohorte basée sur le temps. Les clients seront divisés en cohortes d'acquisition en fonction du mois de leur premier achat. Alors, l'indice de cohorte serait attribué à chacun des achats du client, qui représentera le nombre de mois depuis la première transaction.
Objectifs:
- Trouvez le pourcentage de clients actifs par rapport au nombre total de clients après chaque mois: Segmentation client
- Interpréter le taux de rétention
Voici le code complet de ce tutoriel. si desea seguir la información a mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que avanza en el tutorial.
Étape impliquée dans l'analyse du taux de rétention de la cohorte
1. Chargement et nettoyage des données
2. Attribuez la cohorte et calculez le
Paso 2.1
- Tronquer l'objet de données en un objet requis (ici nous avons besoin du mois, donc la date de la transaction)
- Créer un objet groupby avec une colonne cible (ici, N ° de client)
- Transformer avec une fonction min () pour attribuer la plus petite date de transaction dans la valeur du mois à chaque client.
Le résultat de ce processus est la cohorte du mois d'acquisition pour chaque client, c'est-à-dire, nous avons attribué la cohorte du mois d'acquisition à chaque client.
Paso 2.2
- Calculer la compensation de temps en extrayant des valeurs entières pour l'année, mois et jour d'un objet datetime ().
- Calculer le nombre de mois entre toute transaction et la première transaction pour chaque client. Nous utiliserons les valeurs TransactionMonth et CohortMonth pour ce faire.
Le résultat de ceci sera cohortIndex, c'est-à-dire, la différence entre « Mois de la transaction » Oui « CohorteMois » en termes de nombre de mois et appelez la colonne « cohorteIndex ».
Paso 2.3
- Créer un objet groupby avec CohortMonth et CohortIndex.
- Comptez le nombre de clients dans chaque groupe en appliquant la fonction pandas nunique ().
- Réinitialiser l'index et créer un pivot pandas avec CohortMonth sur les lignes, CohortIndex dans les colonnes et customer_id compte comme des valeurs.
Il en résultera le tableau qui servira de base au calcul du taux de rétention ainsi que d'autres matrices.
3. Calculer des matrices métier: Taux de rétention.
La rétention mesure le nombre de clients de chaque cohorte qui sont revenus au cours des mois suivants.
- Utilisation de l’infrastructure de données appelée cohort_counts, nous sélectionnerons les premières colonnes (égal au nombre total de clients dans les cohortes)
- Calculer la proportion du nombre de ces clients retournés au cours des mois suivants.
Le résultat donne un taux de rétention.
4. Affichage du taux de rétention
5. Interprétation du taux de rétention
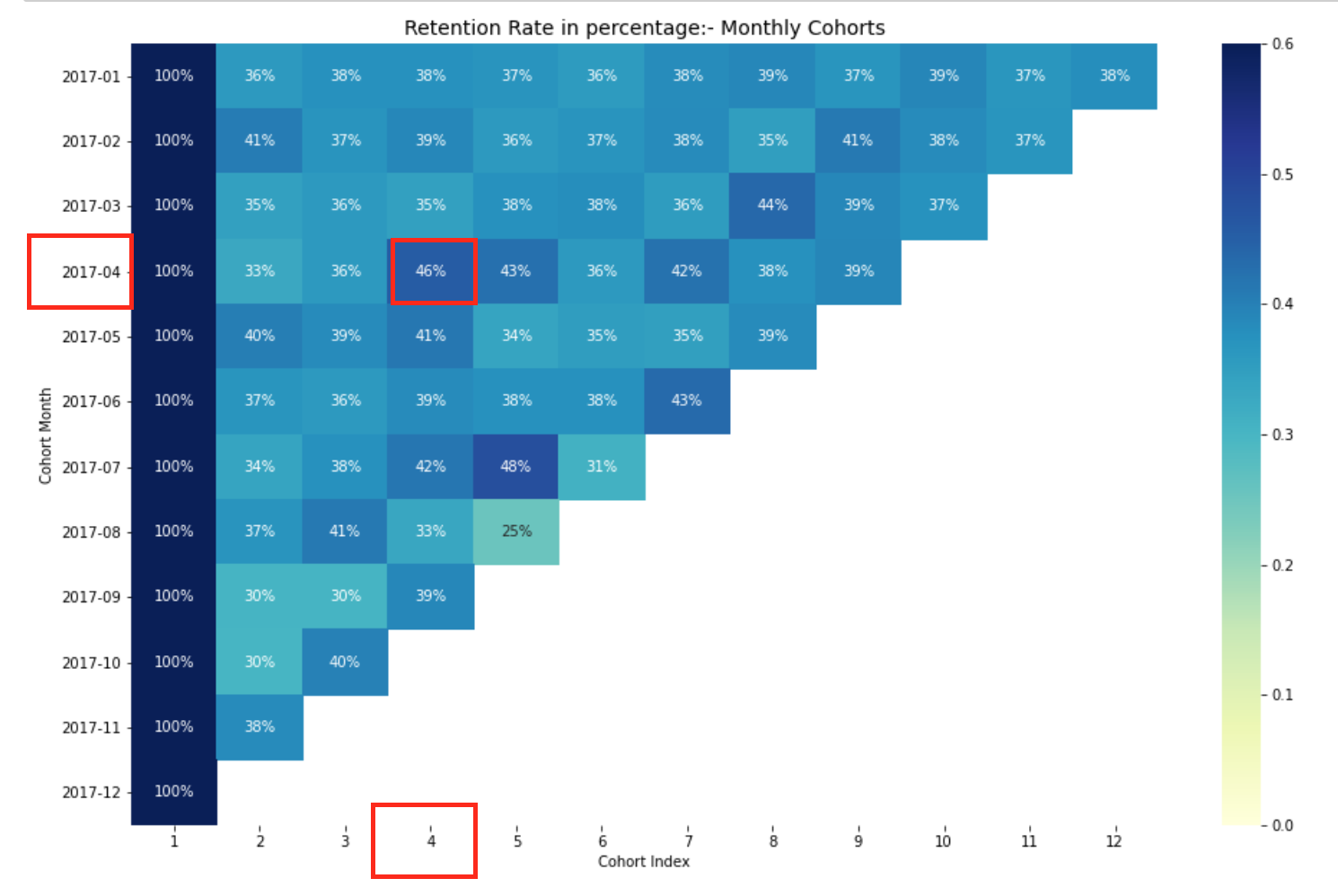
Taux mensuel de rétention des cohortes.
Nous allons commencer:
Importer des bibliothèques
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import datetime as dt
import missingno as msno
from textwrap import wrap
Chargement et nettoyage des données
# Loading dataset transaction_df = pd.read_excel(« transcations.xlsx ») # View data transaction_df.head()

Comprobando y trabajando con valor faltante
# Inspect missing values in the dataset print(transaction_df.isnull().valeurs.somme()) # Replace the ' 's with NaN transaction_df = transaction_df.replace(" ",Np. Nan) # Impute the missing values with mean imputation transaction_df = transaction_df.fillna(transaction_df.mean()) # Count the number of NaNs in the dataset to verify print(transaction_df.isnull().valeurs.somme())
imprimer(transaction_df.info())
pour col dans transaction_df.columns:
# Check if the column is of object type
if transaction_df[col].dtypes == 'objet':
# Impute with the most frequent value
transaction_df[col] = transaction_df[col].remplir(transaction_df[col].value_counts().indice[0])
# Count the number of NaNs in the dataset and print the counts to verify
print(transaction_df.isnull().valeurs.somme())
Ici, podemos ver que tenemos 1542 valores nulos. Que tratamos con valores medios y más frecuentes según el tipo de datos. Ahora que hemos completado nuestra limpieza y comprensión de datos, comenzaremos el análisis de cohorte.
Asignó las cohortes y calculó la compensación mensual.
# Une fonction qui analysera la date Cohorte basée sur l’heure: 1 day of month def get_month(X): renvoyer dt.datetime(x.année, x.mois, 1) # Create transaction_date column based on month and store in TransactionMonth transaction_df['TransactionMonth'] = transaction_df[« transaction_date »].appliquer(get_month) # Grouping by customer_id and select the InvoiceMonth value grouping = transaction_df.groupby(« customer_id »)['TransactionMonth'] # Assigning a minimum InvoiceMonth value to the dataset transaction_df['CohortMonth'] = groupage.transformation('min') # haut d’impression 5 rows print(transaction_df.head())
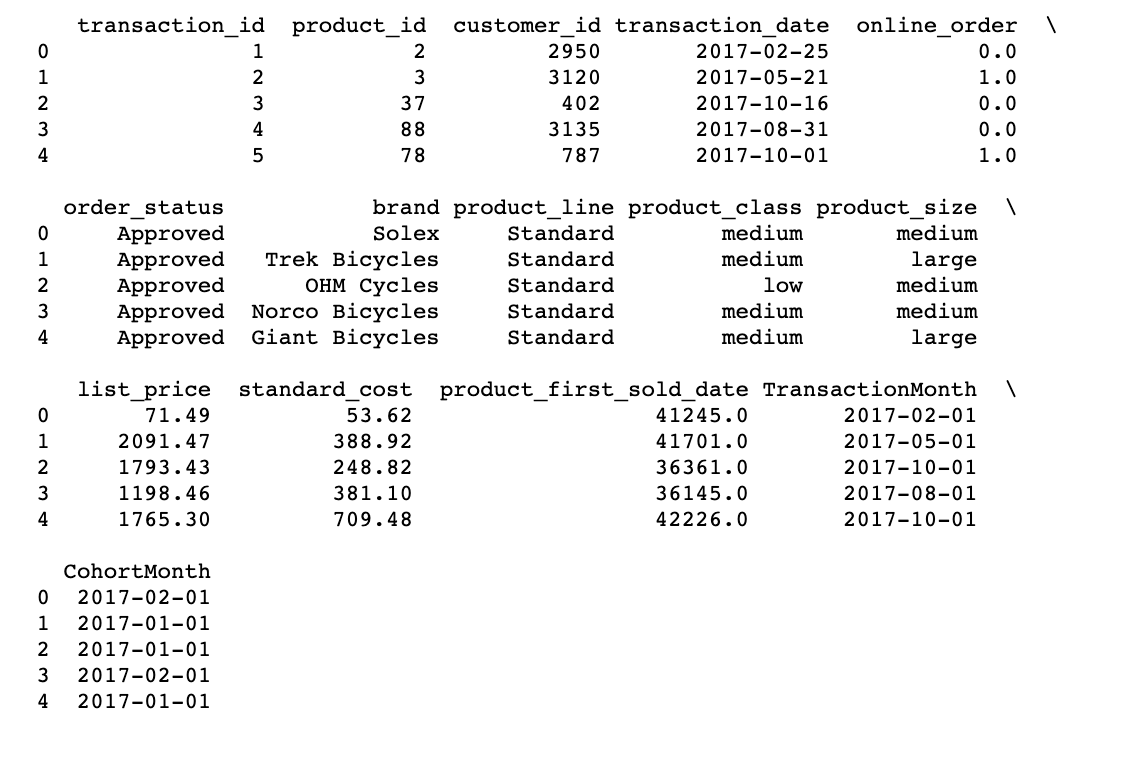
Cálculo de la compensación de tiempo en el mes como índice de cohorte
Le calcul de la compensation de temps pour chaque transaction vous permet d’évaluer les métriques pour chaque cohorte de manière comparable.
Premier, nous allons créer 6 variables qui capturent la valeur entière des années, mois et jours pour la date de transaction et la date de cohorte à l’aide de la fonction get_date_int ().
def get_date_int(df, colonne):
année = df[colonne].dt.year
month = df[colonne].dt.month
day = df[colonne].dt.day
return year, mois, journée
# Getting the integers for date parts from the `InvoiceDay` column
transcation_year, transaction_month, _ = get_date_int(transaction_df, 'TransactionMonth')
# Getting the integers for date parts from the `CohortDay` column
cohort_year, cohort_month, _ = get_date_int(transaction_df, 'CohortMonth')
Nous allons maintenant calculer la différence entre les dates de facturation et les dates de cohorte en années, mois séparément. puis calculer la différence totale de mois entre les deux. Ce sera la cohorte ou l’indice de rémunération de notre mois, que nous utiliserons dans la section suivante pour calculer le taux de rétention.
# Get the difference in years years_diff = transcation_year - cohort_year # Calculate difference in months months_diff = transaction_month - cohort_month """ Extraire la différence en mois de toutes les valeurs précédentes "+1" ajouté à la fin afin que le premier mois soit marqué comme 1 à la place de 0 pour une interprétation plus facile. """ transaction_df['CohortIndex'] = years_diff * 12 + months_diff + 1 imprimer(transaction_df.head(5))
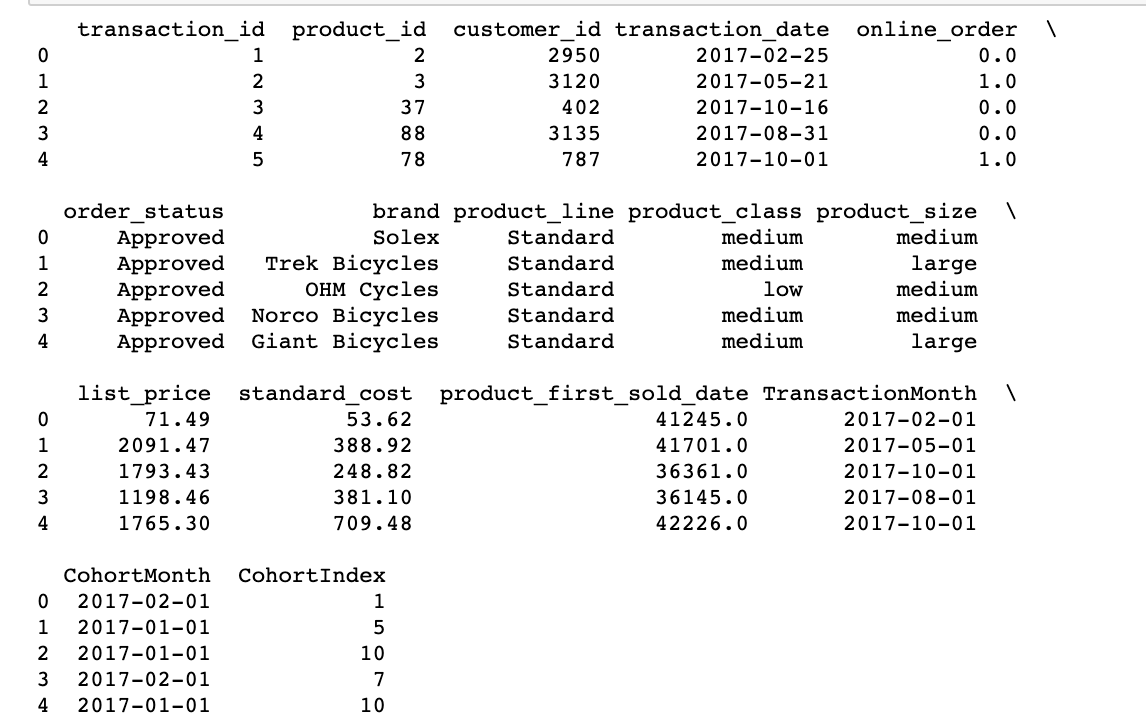
Ici, Au début, nous avons créé un grouper() objet avec CohortMonth et CohortIndex et enregistrez-le en tant que regroupement.
Alors, nous appelons cet objet, nous sélectionnons le Identification du client et calculer la moyenne.
Nous stockons ensuite les résultats sous forme cohort_data. Alors, réinitialiser l’index avant d’appeler la fonction pivot pour pouvoir accéder aux colonnes désormais stockées en tant qu’index.
Finalement, creamos una table dynamiqueLe tableau croisé dynamique est un outil puissant dans les tableurs, tels que Microsoft Excel et Google Sheets. Vous permet de résumer, Analysez et visualisez efficacement de grands volumes de données. Grâce à son interface intuitive, Les utilisateurs peuvent réorganiser les informations, Appliquez des filtres et créez des rapports personnalisés, faciliter la prise de décisions éclairées dans divers contextes, Du domaine de l’entreprise à la recherche académique.... omitiendo
- CohortMes au paramètre index,
- Indice de cohorte au paramètre column,
- Identification du client au paramètre values.
et arrondissez-le à 1 chiffrer et voir ce que nous obtenons.
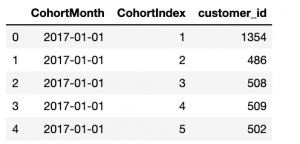
# Counting daily active user from each chort grouping = transaction_df.groupby(['CohortMonth', 'CohortIndex']) # Counting number of unique customer Id's falling in each group of CohortMonth and CohortIndex cohort_data = grouping[« customer_id »].appliquer(. Série.nunique) cohort_data = cohort_data.reset_index() # Assigning column names to the dataframe created above cohort_counts = cohort_data.pivot(index='CohortMonth', colonnes="CohorteIndex", valeurs="N ° de client") # Haut d’impression 5 rows of Dataframe cohort_data.head()
Calculer les métriques d’entreprise: taux de rétention
Le pourcentage de clients actifs par rapport au nombre total de clients après un intervalle de temps spécifié est appelé taux de rétention..
Dans cette section, nous calculerons le nombre de rétention pour chaque mois de cohorte apparié avec l'indice de cohorte
Maintenant que nous avons un décompte des clients retenus pour chaque cohorteMes Oui cohorteIndex. Nous calculerons le taux de rétention pour chaque cohorte.
Nous allons créer un tableau croisé dynamique à cet effet.
cohort_sizes = cohort_counts.iloc[:,0] rétention = cohort_counts.divide(cohorte_tailles, axe=0) # Couvrir le taux de rétention en pourcentage et arrondir. rétention.rond(3)*100
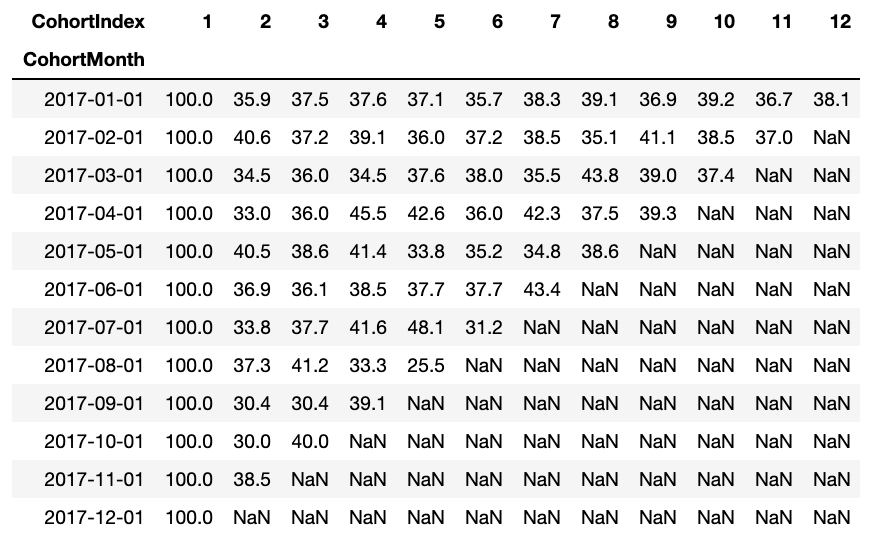
La trame de données du taux de rétention représente le client retenu dans toutes les cohortes. Nous pouvons le lire comme suit:
- La valeur de l'indice représente la cohorte
- Les colonnes représentent le nombre de mois depuis la cohorte actuelle
Par exemple: La valeur dans CohortMonth 2017-01-01, CohorteIndex 3 il est 35,9 et représente 35,9% des clients de la cohorte 2017-01 ont eu lieu dans le 3c'est moi.
En outre, vous pouvez voir dans le DataFrame pour le taux de rétention:
- Taux de rétention Le premier indice, c'est-à-dire, le premier mois est de 100%, puisque tous les clients de ce client particulier se sont inscrits au cours du premier mois
- Le taux de rétention peut augmenter ou diminuer dans les indices suivants.
- Les valeurs vers le bas à droite ont de nombreuses valeurs NaN.
Visualiser le taux de rétention
Avant de commencer à dessiner notre carte thermique, définissons l'index de notre trame de données de taux de rétention sur un format de chaîne plus lisible.
average_standard_cost.index = average_standard_cost.index.strftime('%Y-%m')
# Initialize the figure
plt.figure(taille de la figue=(16, 10))
# Adding a title
plt.title(« Coût standard moyen: Cohortes mensuelles, fontsize = 14)
# Creating the heatmap
sns.heatmap(average_standard_cost, annot = vrai,vmin = 0.0, vmax =20,cmap="YlGnBu", fmt="g")
plt.ylabel(« Mois de la cohorte »)
plt.xlabel(« Indice de cohorte »)
plt.yticks( rotation='360')
plt.show()
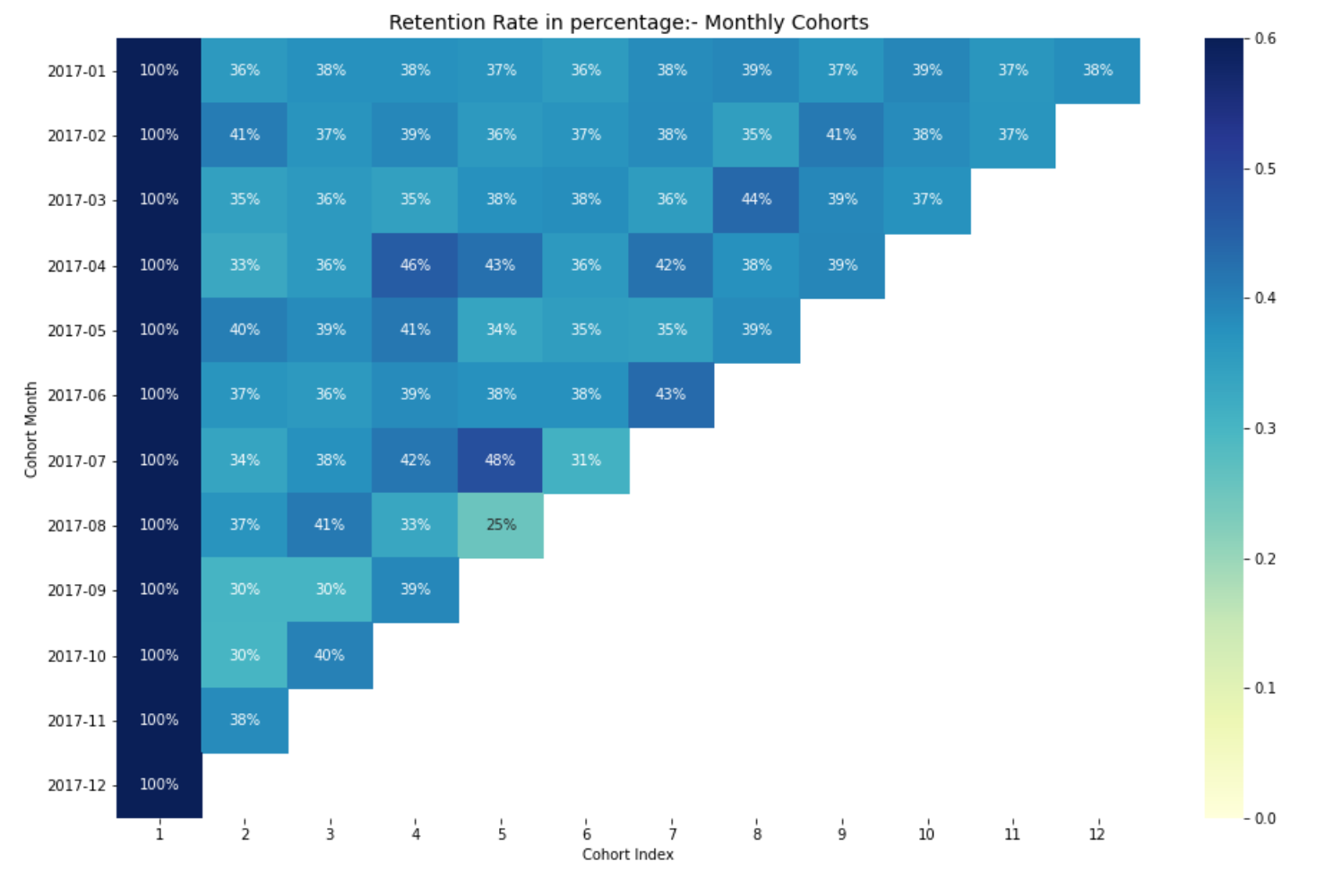
Interprétation du taux de rétention
Le moyen le plus efficace de visualiser et d’analyser les données d’analyse de cohorte consiste à utiliser une carte thermique., comme nous l’avons fait précédemment. Fournit à la fois des valeurs métriques réelles et un code couleur pour voir visuellement les différences de nombres.
Si vous n’avez pas de connaissances de base sur les cartes thermiques, vous pouvez consulter mon blog. Analyse exploratoire des données pour les débutants avec Python, où j'ai parlé des cartes thermiques pour les débutants.
Ici, avoir 12 cohortes pour chaque mois et 12 indices de cohorte. Plus les nuances de bleu sont foncées, plus les valeurs sont élevées. A) Oui, si on voit au mois de la cohorte 2017-07 dans le 5e indice de cohorte, nous voyons le ton bleu foncé avec un 48% ce qui signifie que le 48% des cohortes qui ont signé en juillet 2017 ils étaient actifs 5 mois après.
Ceci conclut notre analyse de cohorte pour le taux de rétention.. de la même manière, nous pouvons effectuer une analyse de cohorte pour d'autres matrices commerciales.
Cliquez ici pour en savoir plus sur l'analyse de cohorte pour les entreprises gratuit avec DataCamp.(Lien d'affiliation)
Donc, nous avons terminé notre analyse de cohorte, où vous avez appris les analyses de base et de cohorte, mener des cohortes temporelles, travailler avec le pivot des pandas et créer une table d'attente avec la visualisation. Nous avons également appris à explorer d'autres matrices.
À présent, vous pouvez commencer à créer et à explorer vous-même les métriques qui sont importantes pour votre entreprise.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





