introduction
Quand ça commence avec la science des données, commence simple. Vous passez par des projets simples comme Problème de prévision de prêt O Prévision des ventes Big Mart. Ces problèmes ont des données structurées soigneusement organisées dans un format tabulaire. En d'autres termes, Vous êtes nourri à la cuillère la partie la plus difficile du pipeline de la science des données.

Les ensembles de données dans la vie réelle sont beaucoup plus complexes.
Vous devez d'abord le comprendre, le recueillir auprès de diverses sources et l'organiser dans un format prêt à être traité. C'est encore plus difficile lorsque les données sont dans un format non structuré, sous forme d'image ou d'audio. C'est parce qu'il devrait représenter des données d'image / audio d'une manière standard pour être utile pour l'analyse.
L'abondance de données non structurées
avec curiosité, les données non structurées représentent une grande opportunité inexploitée. C'est plus proche de la façon dont nous communiquons et interagissons en tant qu'humains. Il contient également beaucoup d'informations utiles et puissantes. Par exemple, si une personne parle; tu ne comprends pas seulement ce qu'il dit, mais aussi quelles étaient les émotions de la personne à partir de la voix.
En outre, le langage corporel de la personne peut vous montrer beaucoup plus de caractéristiques sur une personne, Parce que les actions parlent plus que les mots! En résumé, les données non structurées sont complexes, mais les traiter peut rapporter des récompenses faciles.
Dans cet article, J'ai l'intention de couvrir un aperçu du traitement audio / voix avec une étude de cas afin que vous puissiez obtenir une introduction pratique au dépannage du traitement audio.
Allons-nous en!
Table des matières
- Qu'entendez-vous par données audio?
- Applications de traitement audio
- Traitement des données dans le domaine audio
- Résolvons le défi UrbanSound !!
- Intermédiaire: notre première présentation
- Résolvons le défi! Partie 2: Construire de meilleurs modèles
- Les prochaines étapes à explorer
Qu'entendez-vous par données audio?
Directement ou indirectement, vous êtes toujours en contact avec l'audio. Votre cerveau traite et comprend en permanence les données audio et vous fournit des informations sur l'environnement. Un exemple simple peut être vos conversations quotidiennes avec des personnes.. Ce discours est discerné par l'autre personne pour poursuivre les discussions. Même lorsque vous pensez que vous êtes dans un environnement calme, a tendance à capter des sons beaucoup plus subtils, comme le bruissement des feuilles ou l'éclaboussure de la pluie. C'est l'étendue de votre connexion à l'audio.
Ensuite, Pouvez-vous en quelque sorte attraper cet audio flottant autour de vous pour faire quelque chose de constructif? Oui, bien sûr! Il existe des dispositifs intégrés qui vous aident à capter ces sons et à les représenter dans un format lisible par ordinateur.. Des exemples de ces formats sont
- format wav (fichier audio de forme d'onde)
- format mp3 (Couche audio MPEG-1 3)
- Format WMA (Windows Media Audio)
Si vous pensez à quoi ressemble un audio, ce n'est rien de plus qu'un format de données de forme d'onde, où l'amplitude de l'audio change en fonction du temps. Cela peut être représenté graphiquement comme suit.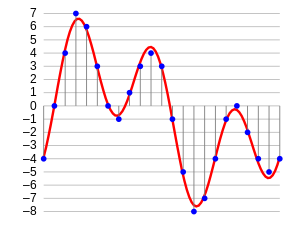
Applications de traitement audio
Bien que nous fassions remarquer que les données audio peuvent être utiles pour l'analyse. Mais, Quelles sont les applications possibles du traitement audio? Ici, j'en énumérerais quelques-uns.
- Indexation des collections de musique en fonction de leurs caractéristiques audio.
- Recommander de la musique pour les chaînes de radio
- Recherche de similitudes pour les fichiers audio (alias Shazam)
- Traitement et synthèse de la parole: génération de voix artificielle pour agents conversationnels
Voici un exercice; Pouvez-vous penser à une application de traitement audio qui peut potentiellement aider des milliers de vies?
Traitement des données dans le domaine audio
Comme pour tous les formats de données non structurés, les données audio ont quelques étapes de prétraitement qui doivent être suivies avant d'être présentées pour analyse. Nous aborderons cela en détail dans un prochain article., ici, nous aurons un aperçu de pourquoi cela est fait.
La première étape consiste à charger les données dans un format compréhensible par la machine. Pour ca, nous prenons juste des valeurs après chaque pas de temps spécifique. Par exemple; dans un fichier audio de 2 secondes, nous extrayons des valeurs à une demi-seconde. Il s'appelle échantillonnage de données audio, et le taux auquel il est échantillonné est appelé taux d'échantillonnage.
Une autre façon de représenter des données audio est de les convertir dans un domaine de représentation de données différent, c'est-à-dire, le domaine fréquentiel. Lorsque nous échantillonnons des données audio, nous avons besoin de beaucoup plus de points de données pour représenter toutes les données et, en outre, la fréquence d'échantillonnage doit être aussi élevée que possible.
D'un autre côté, si nous représentons des données audio dans domaine fréquentiel, beaucoup moins d'espace de calcul est requis. Avoir une intuition, regarde la photo ci-dessous.
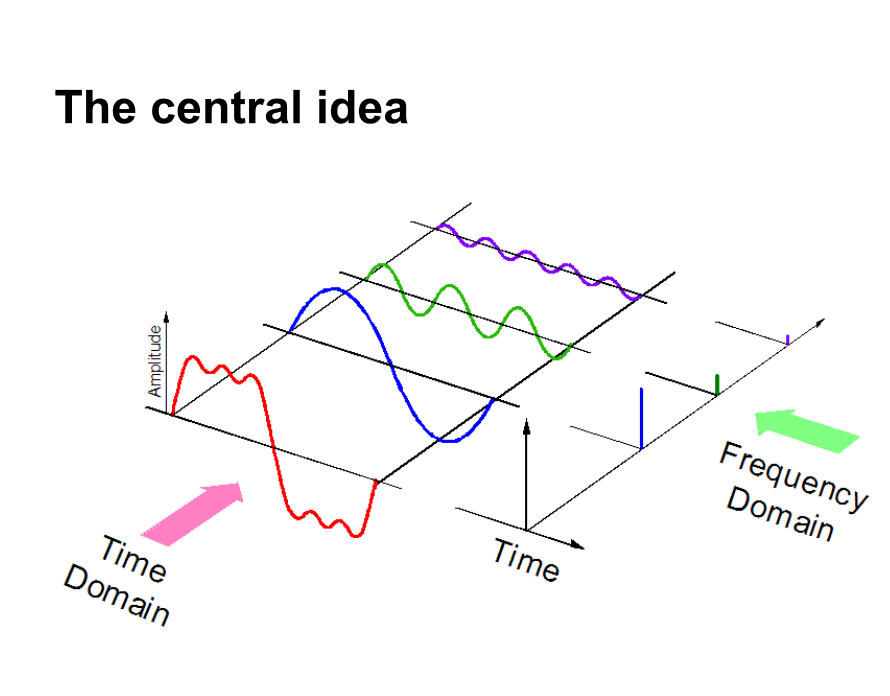
Ici, nous séparons un signal audio en 3 différents signaux purs, qui peut maintenant être représenté comme trois valeurs uniques dans le domaine fréquentiel.
Il existe plusieurs autres façons de représenter les données audio, par exemple. à l'aide de MFC (cepstres de fréquence de miel. PD: Nous couvrirons cela dans le prochain article.). Ce ne sont que différentes manières de représenter les données.
À présent, l'étape suivante consiste à extraire les caractéristiques de ces représentations audio, afin que notre algorithme puisse travailler sur ces caractéristiques et effectuer la tâche pour laquelle il est conçu. Ensuite, une représentation visuelle des catégories de fonctions audio pouvant être extraites est affichée.
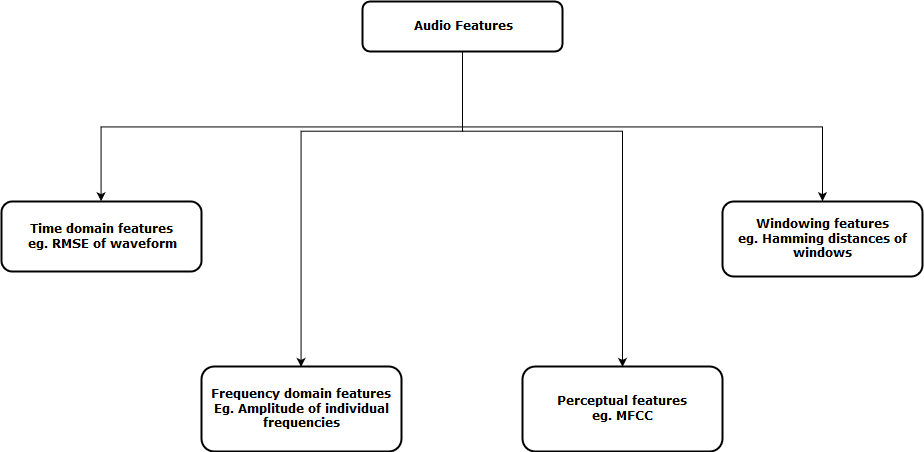
Après avoir extrait ces caractéristiques, envoyé au modèle d'apprentissage automatique pour une analyse plus approfondie.
Résolvons le défi UrbanSound !!
Ayons une meilleure vue d'ensemble pratique sur un projet de la vie réelle, les Défi sonore urbain. Ce problème pratique est destiné à vous présenter le traitement audio dans le scénario de classification typique.
L'ensemble de données contient 8732 extraits sonores (<= 4 s) de sons urbains de 10 cours, a savoir:
- air conditionné,
- Corne,
- enfants jouant,
- Aboiement de chien,
- forage,
- Moteur au ralenti,
- coup de feu
- marteau pneumatique,
- sirène et
- Musique de rue
Voici un extrait sonore du jeu de données. Pouvez-vous deviner à quelle classe il appartient?
Pour reproduire cela dans le cahier de jupyter, tu peux juste suivre le code.
importer IPython.display comme ipd
ipd.Audio('../data/Train/2022.wav')
Maintenant, chargeons cet audio dans notre ordinateur portable en tant que grande matrice. Pour cela nous utiliserons livres bibliothèque python. Pour installer des livres, il suffit de taper ceci dans la ligne de commande
pip install librosaNous pouvons maintenant exécuter le code suivant pour charger les données.
Les données, taux_échantillonnage = librosa.load('../data/Train/2022.wav')
Lorsque vous chargez les données, vous donne deux objets; un large éventail d'un fichier audio et la fréquence d'échantillonnage correspondante par laquelle il a été extrait. À présent, pour représenter cela comme une forme d'onde (qui est à l'origine), utilisez le code suivant
% pylab en ligne importer le système d'exploitation importer des pandas au format pd importer librosa importation globale plt.figure(taille de la figue=(12, 4)) librosa.display.waveplot(Les données, sr=taux_d'échantillonnage)
La sortie va comme suit
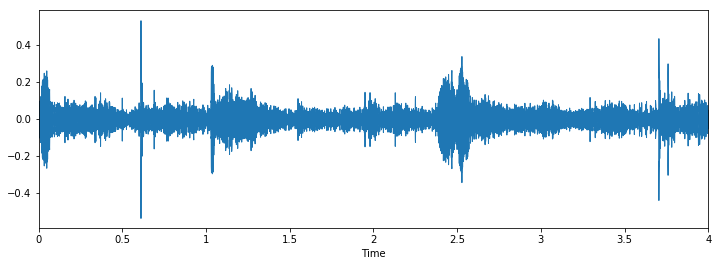
Inspectons maintenant visuellement nos données et voyons si nous pouvons trouver des modèles dans les données..
Classer: marteau-piqueurClasser: forage
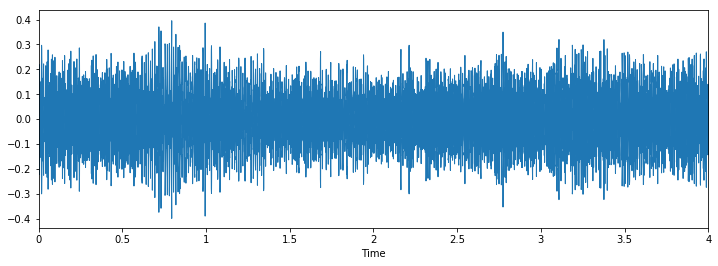 Classer: forage
Classer: forage
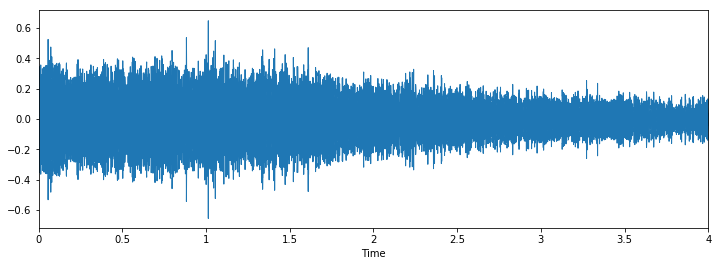 Classer: Aboiement de chien
Classer: Aboiement de chien
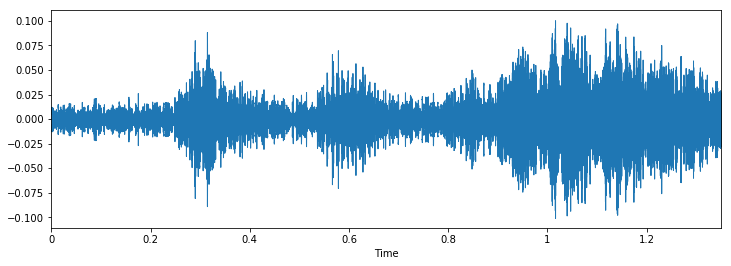
Nous pouvons voir qu'il peut être difficile de faire la différence entre le marteau pneumatique et le forage, mais il est toujours facile de faire la distinction entre l'aboiement du chien et le piercing. Pour voir plus d'exemples de ce type, tu peux utiliser ce code
i = choix.aléatoire(train.index)
nom_audio = train.ID[je]
chemin = os.chemin.join(rép_données, 'Former', str(nom_audio) + '.wav')
imprimer('Classer: ', train.Classe[je])
X, sr = librosa.load('../données/Train/' + str(train.ID[je]) + '.wav')
plt.figure(taille de la figue=(12, 4))
librosa.display.waveplot(X, sr=sr)
Intermédiaire: notre première présentation
Nous allons faire une approche similaire à celle que nous avons faite pour le problème de détection de l'âge, pour voir les distributions de classe et prédire uniquement l'occurrence maximale de tous les cas de test pour cette classe.
Regardons les distributions pour ce problème.
train.Class.value_counts()
Dehors[10]: marteau-piqueur 0.122907 moteur_ralenti 0.114811 sirène 0.111684 aboiement 0.110396 climatiseur 0.110396 children_playing 0.110396 street_music 0.110396 forage 0.110396 klaxon de voiture 0.056302 coup de feu 0.042318
On voit que la classe marteau pneumatique a plus de valeurs que toute autre classe. Créons donc notre première présentation avec cette idée.
test = pd.read_csv('../data/test.csv')
test['Classer'] = 'marteau-piqueur'
test.to_csv('sous01.csv', index=Faux)
Cela semble être une bonne idée comme référence pour tout défi, mais pour ce problème, semble un peu injuste. C'est parce que l'ensemble de données n'est pas très déséquilibré.
Résolvons le défi! Partie 2: Construire de meilleurs modèles
Voyons maintenant comment nous pouvons tirer parti des concepts que nous avons appris plus tôt pour résoudre le problème.. Nous allons suivre ces étapes pour résoudre le problème.
Paso 1: télécharger des fichiers audio
Paso 2: extraire les fonctions de l'audio
Paso 3: convertir les données pour les transmettre à notre modèle d'apprentissage profond
Paso 4: Exécutez un modèle d'apprentissage en profondeur et obtenez des résultats
Ci-dessous est un code de la façon dont j'ai mis en œuvre ces étapes
Paso 1 Oui 2 combiné: charger des fichiers audio et extraire des fonctions
parseur par défaut(ligne): # function to load files and extract features file_name = os.path.join(os.path.abspath(rép_données), 'Former', str(ID de ligne) + '.wav') # handle exception to check if there isn't a file which is corrupted try: # here kaiser_fast is a technique used for faster extraction X, sample_rate = librosa.load(nom de fichier, res_type="kaiser_fast") # we extract mfcc feature from data mfccs = np.mean(librosa.feature.mfcc(y = X, sr=taux_échantillon, n_mfcc=40).T,axe=0) sauf exception comme e: imprimer("Erreur rencontrée lors de l'analyse du fichier: ", déposer) retour Aucun, None feature = mfccs label = row.Class return [caractéristique, étiqueter] temp = train.apply(analyseur, axe=1) temp.colonnes = ['caractéristique', 'étiqueter']
Paso 3: convertir les données pour les transmettre à notre modèle d'apprentissage profond
de sklearn.preprocessing importer LabelEncoder X = np.tableau(temp.feature.tolist()) y = np.tableau(temp.label.tolist()) lb = LabelEncoder() y = np_utils.to_categorical(lb.fit_transform(Oui))
Paso 4: Exécutez un modèle d'apprentissage en profondeur et obtenez des résultats
importer numpy en tant que np
à partir de keras.models Importation séquentielle
de keras.layers importer Dense, Abandonner, Activation, Aplatir
à partir de keras.layers importer Convolution2D, MaxPooling2D
de keras.optimizers importer Adam
de keras.utils importer np_utils
à partir des métriques d'importation sklearn
num_labels = y.forme[1]
taille_filtre = 2
# modèle de construction
modèle = Séquentiel()
model.ajouter(Dense(256, input_shape=(40,)))
model.ajouter(Activation('relu'))
model.ajouter(Abandonner(0.5))
model.ajouter(Dense(256))
model.ajouter(Activation('relu'))
model.ajouter(Abandonner(0.5))
model.ajouter(Dense(nombre_étiquettes))
model.ajouter(Activation('softmax'))
modèle.compile(perte ="catégorique_crossentropie", métriques=['précision'], optimiseur="Adam")
Entraînons maintenant notre modèle
model.fit(X, Oui, taille_lot=32, époques=5, validation_data=(val_x, val_y))
C'est le résultat que j'ai obtenu en m'entraînant pendant 5 époques
Entraînez-vous sur 5435 échantillons, valider sur 1359 échantillons Époque 1/10 5435/5435 [===============================] - 2s - perte: 12.0145 - acc: 0.1799 - perte_val: 8.3553 - val_acc: 0.2958 Époque 2/10 5435/5435 [===============================] - 0s - perte: 7.6847 - acc: 0.2925 - perte_val: 2.1265 - val_acc: 0.5026 Époque 3/10 5435/5435 [===============================] - 0s - perte: 2.5338 - acc: 0.3553 - perte_val: 1.7296 - val_acc: 0.5033 Époque 4/10 5435/5435 [===============================] - 0s - perte: 1.8101 - acc: 0.4039 - perte_val: 1.4127 - val_acc: 0.6144 Époque 5/10 5435/5435 [===============================] - 0s - perte: 1.5522 - acc: 0.4822 - perte_val: 1.2489 - val_acc: 0.6637
Ça a l'air d'être bien, mais évidemment vous pouvez augmenter le score. (PD: pourrait obtenir une précision de 80% dans mon jeu de données de validation). Maintenant c'est ton tour, Pouvez-vous augmenter ce score? Si c'est ainsi, Faites-le moi savoir dans les commentaires ci-dessous!!
Les prochaines étapes à explorer
Maintenant que nous avons vu des applications simples, nous pouvons proposer d'autres méthodes qui peuvent nous aider à améliorer notre score.
- Nous appliquons un modèle de réseau de neurones simple au problème. Notre prochaine étape immédiate devrait être comprendre où le modèle échoue et pourquoi. Avec ça, nous voulons conceptualiser notre compréhension des échecs d'algorithmes afin que la prochaine fois que nous construisons un modèle, ne fais pas les mêmes erreurs.
- Nous pouvons construire modèles plus efficaces que notre “meilleurs modèles”, tels que les réseaux de neurones convolutifs ou les réseaux de neurones récurrents. Il a été démontré que ces modèles résolvent ces types de problèmes plus facilement.
- Nous avons abordé le concept de augmentation des données, mais nous ne les appliquons pas ici. Vous pouvez l'essayer pour voir si cela fonctionne pour le problème.
Remarques finales
Dans cet article, J'ai fourni un bref aperçu du traitement audio avec une étude de cas sur le défi UrbanSound. J'ai également montré les étapes à suivre pour traiter des données audio en python avec les livres du package. Avec ça “shastra” Dans ta main, J'espère que vous pourrez tester vos propres algorithmes dans Urban Sound challenge, ou essayez de résoudre vos propres problèmes audio dans la vie quotidienne. Si vous avez des suggestions / idée, faites le moi savoir dans les commentaires ci-dessous.
Apprendre, engager , hacher et se faire embaucher!

Podcast: Jouer dans une nouvelle fenêtre | Descargar





