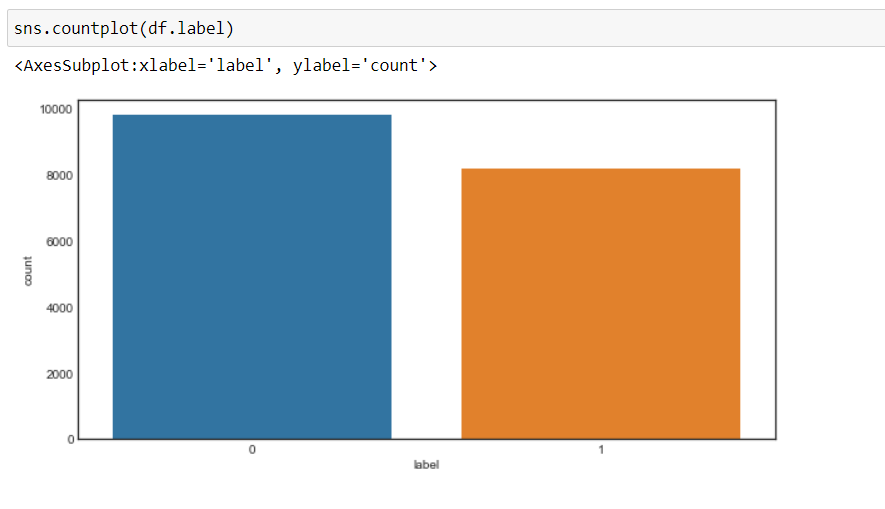
À présent, nous pouvons voir que notre objectif a changé pour 0 Oui 1, c'est-à-dire, 0 pour le négatif et 1 pour le positif, et les données sont plus ou moins dans un état équilibré.
Prétraitement des données
À présent, nous pré-traiterons les données avant de les convertir en vecteurs et de les transmettre au modèle d'apprentissage automatique.
Nous allons créer une fonction de prétraitement des données.
1. Premier, nous allons parcourir chaque enregistrement et utiliser un expression régulière, nous supprimerons tout caractère en dehors des alphabets.
2. Alors, nous allons convertir la chaîne en minuscule Quoi, mot « Bien » est différent du mot « bien ».
Parce que, non converti en minuscule, posera un problème lorsque nous créerons des vecteurs de ces mots, puisque deux vecteurs différents seront créés pour le même mot que nous ne voulons pas.
3. Alors, nous rechercherons les mots vides dans les données et les supprimerons. Pour les mots sont des mots couramment utilisés dans une phrase comme « les », « ongle », « une », etc. qui n'ajoute pas beaucoup de valeur.
4. Alors, nous allons effectuer lématisation dans chaque mot, c'est-à-dire, transformer les différentes formes d'un mot en un seul élément appelé slogan.
UNE devise est une forme de base d'un mot. Par exemple, « Cours », « courir » Oui « Cours » ce sont toutes des formes du même lexème, où « Cours » est la devise. Donc, nous convertissons toutes les occurrences du même lexème en leur devise respective.
5. Et ensuite retourner un corpus de données traitées.
Mais nous allons d'abord créer un objet WordNetLemmatizer puis nous allons faire la transformation.
#objet de WordNetLemmatizer lm = WordNetLemmatizer()
def text_transformation(df_col):
corpus = []
pour l'élément dans df_col:
new_item = re.sub('[^ a-zA-Z]',' ',str(Objet))
new_item = new_item.lower()
new_item = new_item.split()
nouvel_élément = [lm.lemmatize(mot) pour le mot dans new_item si le mot n'est pas dans l'ensemble(mots.mots.mots('Anglais'))]
corpus.append(' '.rejoindre(str(X) pour x dans new_item))
retour corpus
corpus = text_transformation(df['texte'])
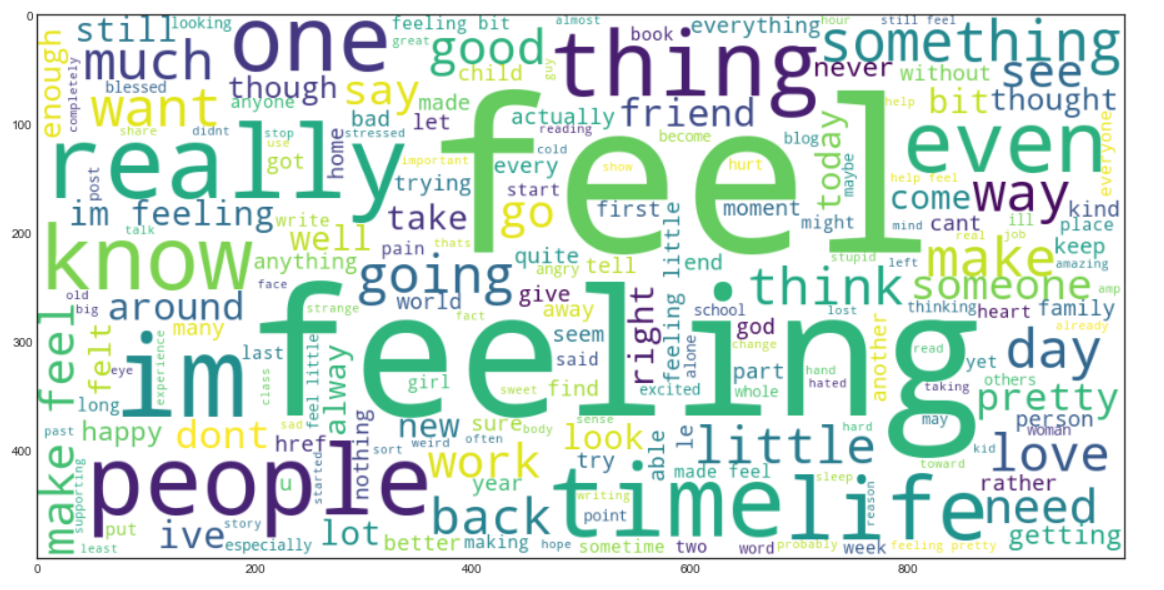
Nous allons maintenant créer un Mot nuage. C'est une technique de visualisation de données utilisée pour représenter le texte de telle manière que les mots les plus fréquents apparaissent agrandis par rapport aux mots moins fréquents. Cela nous donne une petite idée de l'apparence des données après avoir été traitées à travers toutes les étapes jusqu'à présent.
rcParams['figure.figsize'] = 20,8
word_cloud = ""
pour la ligne dans le corpus:
pour mot en ligne:
nuage_mot+=" ".rejoindre(mot)
nuage de mots = nuage de mots(largeur = 1000, hauteur = 500, background_color="blanche",min_font_size = 10).produire(mot nuage)
plt.imshow(mot nuage)
Production:
Sac de mots
À présent, nous utiliserons le modèle du sac de mots (ARC), qui sert à représenter le texte sous la forme d'un sac de mots, c'est-à-dire, la grammaire et l'ordre des mots dans une phrase n'ont pas d'importance, en échange, la multiplicité , c'est-à-dire (le nombre de fois qu'un mot apparaît dans un document) est la principale source d'inquiétude.
Essentiellement, décrit l'occurrence totale de mots dans un document.
Scikit-Apprendre fournit un moyen soigné d'effectuer la technique du sac de mots en utilisant CountVectorizer.
À présent, nous allons convertir les données de texte en vecteurs, ajuster et transformer le corpus que nous avons créé.
cv = CountVectorizer(ngram_range=(1,2)) traindata = cv.fit_transform(corpus) X = données de train y = df.label
Nous le prendrons ngram_range Quoi (1,2) que signifie un bigrama.
Ngram es una secuencia de ‘m’ mots d'affilée ou d'une phrase. ‘ngram_range’ est un paramètre, que nous utilisons pour donner de l'importance à la combinaison de mots, Quoi « des médias sociaux » a un sens différent de « social » Oui « médias » séparément.
Nous pouvons expérimenter avec la valeur de ngram_range paramètre et sélectionnez l'option qui donne les meilleurs résultats.
Vient maintenant la partie création de modèle d'apprentissage automatique et dans ce projet, je vais porter Classificateur de forêt aléatoire, et nous ajusterons les hyperparamètres en utilisant GridSearchCV.
GrilleRechercheCV() tomará los siguientes paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet....,
1. EstimateurLe "Estimateur" est un outil statistique utilisé pour déduire les caractéristiques d’une population à partir d’un échantillon. Il s’appuie sur des méthodes mathématiques pour fournir des estimations précises et fiables. Il existe différents types d’estimateurs, tels que l’impartialité et la cohérence, qui sont choisis en fonction du contexte et de l’objectif de l’étude. Son utilisation correcte est essentielle dans la recherche scientifique, enquêtes et analyses de données.... le modèle – RandomForestClassifier dans notre cas
2. paramètres: dictionnaire des noms d'hyperparamètres et de leurs valeurs
3. CV: signifie les plis de validation croisée
4. return_train_score: devuelve las puntuaciones de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... de los distintos modelos
5. n_emplois – non. tâches à exécuter en parallèle (« -1 » signifie que tous les cœurs du processeur seront utilisés, ce qui réduit considérablement le temps de formation)
Premier, nous allons créer un dictionnaire, « paramètres » qui contiendra les valeurs des différents hyperparamètres.
Nous passerons cela en tant que paramètre à GridSearchCV pour former notre modèle de classificateur de forêt aléatoire en utilisant toutes les combinaisons possibles de ces paramètres pour trouver le meilleur modèle.
paramètres = {'max_caractéristiques': ('auto','sqrt'),
'n_estimateurs': [500, 1000, 1500],
'profondeur max': [5, 10, Rien],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 5, 10],
'amorcer': [Vrai, Faux]}
À présent, nous ajusterons les données dans la recherche de grille et verrons le meilleur paramètre en utilisant l'attribut « meilleurs_params_ » de GridSearchCV.
grid_search = GridSearchCV(RandomForestClassifier(),paramètres,cv=5,return_train_score=Vrai,n_emplois=-1) grid_search.fit(X,Oui) grid_search.best_params_
Production:

Et après, on peut voir tous les modèles et leurs paramètres respectifs, le score moyen du test et le classement, puisque GridSearchCV stocke tous les résultats dans le cv_results_ attribut.
pour moi à portée(432):
imprimer('Paramètres: ',grid_search.cv_results_['paramètres'][je])
imprimer('Score moyen au test: ',grid_search.cv_results_['mean_test_score'][je])
imprimer('Rang: ',grid_search.cv_results_['rank_test_score'][je])
Départ: (un échantillon de la sortie)

À présent, nous choisirons les meilleurs paramètres obtenus à partir de GridSearchCV et créerons un modèle final de classificateur de forêt aléatoire, puis entraînerons notre nouveau modèle.
rfc = RandomForestClassifier(max_features=grid_search.best_params_['max_caractéristiques'],
max_depth=grid_search.best_params_['profondeur max'],
n_estimators=grid_search.best_params_['n_estimateurs'],
min_samples_split=grid_search.best_params_['min_samples_split'],
min_samples_leaf=grid_search.best_params_['min_samples_leaf'],
bootstrap=grid_search.best_params_['amorcer'])
rfc.fit(X,Oui)
Tester la transformation des données
À présent, nous allons lire les données de test et effectuer les mêmes transformations que nous avons faites sur les données d'entraînement et enfin évaluer le modèle sur ses prédictions.
test_df = pd.read_csv('test.txt',délimiteur=";",noms=['texte','étiqueter'])
X_test,y_test = test_df.text,test_df.label #encoder les étiquettes en deux classes , 0 et 1 test_df = custom_encoder(y_test) #pré-traitement de texte test_corpus = text_transformation(X_test) #convertir des données de texte en vecteurs testdata = cv.transform(test_corpus) #prévoir la cible prédictions = rfc.predict(données de test)
Évaluation du modèle
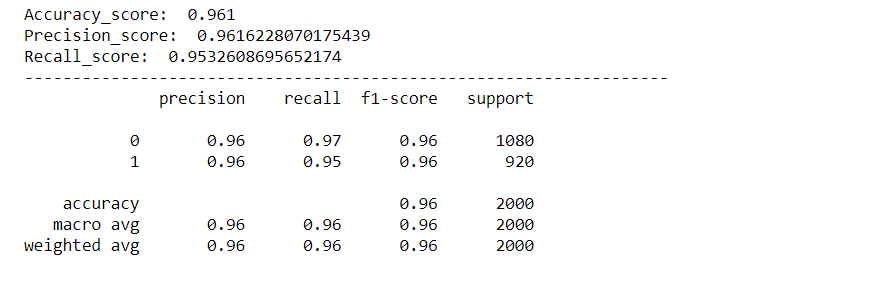
Nous évaluerons notre modèle à l'aide de diverses métriques telles que le score de précision, Score de précision, Score de rappel, Matrice de confusion et nous créerons une courbe roc pour visualiser les performances de notre modèle.
rcParams['figure.figsize'] = 10,5
plot_confusion_matrix(y_test,prédictions)
acc_score = precision_score(y_test,prédictions)
pre_score = precision_score(y_test,prédictions)
rec_score = rappel_score(y_test,prédictions)
imprimer('Accuracy_score: ',acc_score)
imprimer('Precision_score: ',pre_score)
imprimer('Recall_score: ',rec_score)
imprimer("-"*50)
cr = classement_rapport(y_test,prédictions)
imprimer(cr)
Production:
Matrice de confusion:
Courbe de Roc:
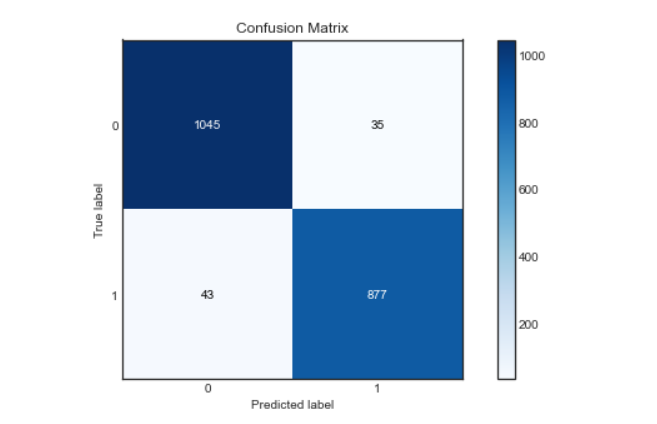
On va trouver la probabilité de la classe en utilisant la méthode predict_proba () de Random Forest Classifier, puis nous tracerons la courbe roc.
prédictions_probabilité = rfc.predict_proba(données de test)
fpr,tpr,seuils = roc_curve(y_test,prédictions_probabilité[:,1])
plt.plot(fpr,tpr)
plt.plot([0,1])
plt.titre('Courbe ROC')
plt.xlabel(« Taux de faux positifs »)
plt.ylabel(« Taux Vraiment Positif »)
plt.show()
Comme nous pouvons le voir, notre modèle a très bien fonctionné pour classer les sentiments, avec un score de précision, précision et récupération d'environ. 96%. Et la courbe roc et la matrice de confusion sont également excellentes, ce qui signifie que notre modèle peut classer les étiquettes avec précision, avec moins de risque d'erreur.
À présent, nous allons également vérifier l'entrée personnalisée et laisser notre modèle identifier le sentiment de la déclaration d'entrée.
Prédire pour une entrée personnalisée:
def expression_check(prédiction_entrée):
si prédiction_entrée == 0:
imprimer("L'instruction d'entrée a un sentiment négatif.")
elif prédiction_input == 1:
imprimer("L'instruction d'entrée a un sentiment positif.")
autre:
imprimer("Déclaration invalide.")
# fonction pour prendre l'instruction d'entrée et effectuer les mêmes transformations que nous avons faites plus tôt
def sentiment_predictor(saisir):
input = text_transformation(saisir)
entrée_transformée = cv.transformer(saisir)
prédiction = rfc.predict(entrée_transformée)
expression_check(prédiction)
entrée1 = ["Parfois, j'ai juste envie de frapper quelqu'un au visage."] entrée2 = ["J'ai acheté un nouveau téléphone et c'est tellement bon."]
sentiment_predictor(entrée1) sentiment_predictor(entrée2)
Production:
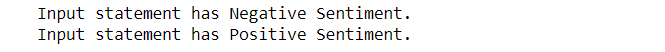
Hourra, puisque nous pouvons voir que notre modèle a classé avec précision les sentiments derrière les deux phrases.
Si vous aimez cet article, Suivez-moi sur LinkedIn.
Et vous pouvez obtenir le code complet et la sortie de ici.
Les images de sortie sont conservées ici pour référence.
La fin?
Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..





