Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Le but ultime de ce blog est de prédire le sentiment d'un texte donné en utilisant python, où nous utilisons NLTK, également connu sous le nom de boîte à outils de traitement du langage naturel, un package Python spécialement créé pour l'analyse textuelle. Ensuite, avec quelques lignes de code, nous pouvons facilement prédire si une phrase ou une critique (utilisé dans le blog) est-ce un avis positif ou négatif.
Avant de passer directement à la mise en œuvre, laissez-moi brièvement les étapes impliquées pour avoir une idée de l'approche analytique. Ce sont à savoir:
1. Importation des modules requis
2. Importation d'ensemble de données
3. Prétraitement et visualisation des données
4. Construction de maquettes
5. Prédiction
Concentrons-nous donc sur chaque étape en détail.
1. Importation des modules requis:
Ensuite, comme nous le savons tous, il faut importer tous les modules que l'on va utiliser dans un premier temps. Alors faisons-le comme la première étape de notre pratique.
importer numpy en tant que np #algèbre linéaire importer des pandas au format pd # traitement de l'information, E/S de fichier CSV (par exemple. pd.read_csv) importer matplotlib.pyplot en tant que plt #Pour la visualisation %matplotlib en ligne importer seaborn as sns #Pour une meilleure visualisation de bs4 import BeautifulSoup #Pour l'analyse de texte
Ici, nous importons tous les modules d'importation de base nécessaires, a savoir, numpy, pandas, matplotlib, Seaborn y belle soupe, chacun avec son propre cas d'utilisation. Bien que nous utiliserons d'autres modules, en les excluant, nous les comprendrons pendant que nous les utiliserons.
2. Importation d'ensemble de données:
En réalité, J'avais téléchargé le jeu de données Kaggle il y a quelque temps, donc je n'ai pas le lien vers le dataset. Ensuite, pour obtenir l'ensemble de données et le code, Je vais mettre le lien du dépôt Github pour que tout le monde y ait accès. À présent, pour importer l'ensemble de données, tenemos que usar el método pandas ‘lire_csv’ suivi du chemin du fichier.
données = pd.read_csv('Avis.csv')
Si nous imprimons l'ensemble de données, podríamos ver que hay ‘568454 filas × 10 Colonnes’, ce qui est assez gros.
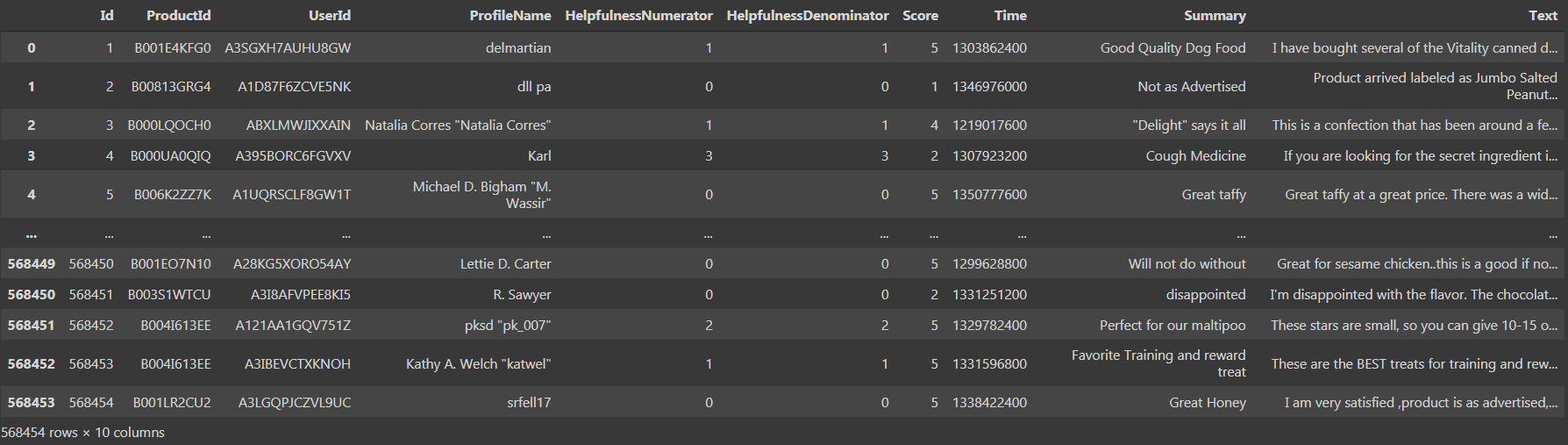
On voit qu'il y a 10 Colonnes, a savoir, ‘Identifiant’, ‘Numerador de utilidad’, ‘Denominador de utilidad’, ‘Puntaje’ Oui ‘Conditions météorologiques’ como tipo de datos int64 y ‘ProductId’, ‘UserId’, ‘ProfileName’, ‘résumé’, ‘Texte’ comme type de données d'objet. Passons maintenant à la troisième étape, c'est-à-dire, prétraitement et visualisation des données.
3. Prétraitement et visualisation des données:
Maintenant, nous avons accès aux données, puis nous les nettoyons. Usando el método ‘est nul (). Somme ()’ nous pourrions facilement trouver le nombre total de valeurs manquantes dans l'ensemble de données.
data.isnull().somme()
Si nous exécutons le code ci-dessus en tant que cellule, nous avons trouvé qu'il y a 16 Oui 27 valores nulos en las columnas ‘ProfileName’ Oui ‘Summary’ respectivement. À présent, nous devons remplacer les valeurs nulles par la tendance centrale ou supprimer les lignes respectives contenant les valeurs nulles. Avec un si grand nombre de lignes, l'élimination du solo 43 les lignes contenant les valeurs nulles n'affecteraient pas la précision globale du modèle. Donc, il est conseillé d'éliminer 43 filas utilizando el método ‘tomber’.
données = données.dropna()
À présent, he actualizado el marco de datos antiguo en lugar de crear una nueva variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... y almacenar el nuevo marco de datos con los valores limpios. À présent, de nouveau, lorsque nous vérifions la trame de données, nous avons trouvé qu'il y a 568411 rangées et idem 10 Colonnes, ce qui signifie que 43 les lignes qui avaient les valeurs nulles ont été supprimées et maintenant notre ensemble de données est nettoyé. Continuer, nous devons prétraiter les données de manière à ce que le modèle puisse les utiliser directement.
Para préprocesseur, usamos la columna ‘Puntaje’ en el marco de datos para tener puntajes que van de ‘1’ une ‘5’, où ‘1’ significa una revisión negativa y ‘5’ signifie une critique positive. Mais il vaut mieux avoir le score initialement dans une fourchette de ‘0’ une ‘2’ où ‘0’ signifie un avis négatif, ‘1’ significa una revisión neutral y ‘2’ signifie une critique positive. C'est similaire au codage en Python, mais ici nous n'utilisons aucune fonction intégrée, pero ejecutamos explícitamente un bucle for où"OÙ" est un terme anglais qui se traduit par "où" en espagnol. Utilisé pour poser des questions sur l’emplacement des personnes, Objets ou événements. Dans des contextes grammaticaux, Il peut fonctionner comme un adverbe de lieu et est fondamental dans la formation des questions. Son application correcte est essentielle dans la communication quotidienne et dans l’enseignement des langues, faciliter la compréhension et l’échange d’informations sur les positions et les orientations.... y creamos una nueva lista y agregamos los valores a la lista.
a=[]
pour i dans les données['But']:
si je <3:
a.ajouter(0)
si je==3:
a.ajouter(1)
si je>3:
a.ajouter(2)
Suponiendo que la ‘Puntuación’ est de l'ordre de ‘0’ une ‘2’, Nous les considérons comme des critiques négatives et les ajoutons à la liste avec un score de ‘0’, que signifie avis négatif. À présent, si graficamos los valores de las puntuaciones presentes en la lista ‘une’ comme la nomenclature utilisée ci-dessus, nous avons trouvé qu'il y a 82007 avis négatifs, 42638 avis neutres et 443766 avis positifs. Nous pouvons clairement constater qu'approximativement la 85% des avis de l'ensemble de données ont des avis positifs et les autres sont des avis négatifs ou neutres. Cela pourrait être plus clairement visualisé et compris à l'aide d'un tracé de comptage dans la bibliothèque Seaborn.
sns.countplot(une)
plt.xlabel('Commentaires', couleur="rouge")
plt.ylabel('Compter', couleur="rouge")
plt.xticks([0,1,2],['Négatif','Neutre','Positif'])
plt.titre('COMPTER LE PARCELLE', couleur="r")
plt.show()
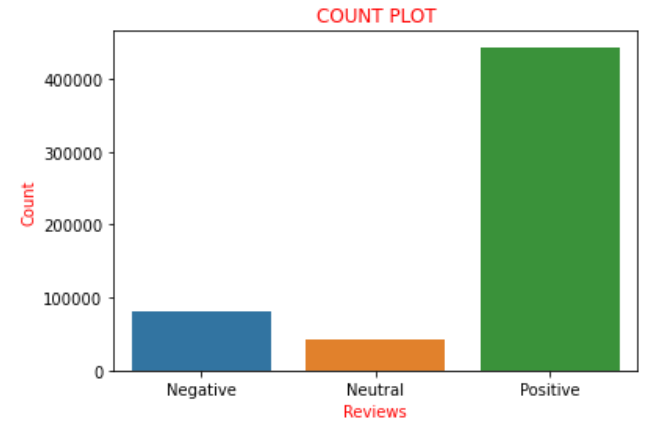
Donc, l'intrigue ci-dessus dépeint clairement toutes les phrases décrites ci-dessus sous forme d'images. Ahora convierto la lista ‘une’ que habíamos codificado anteriormente en una nueva columna llamada ‘sentiment’ au bloc de données, c'est-à-dire, ‘Les données’. Vient maintenant une torsion dans laquelle nous créons une nouvelle variable, Disons ‘ensemble_de_données_final’ donde considero solo la columna ‘Sentiment’ Oui ‘texte’ de la trame de données, quel est le nouveau bloc de données sur lequel nous allons travailler pour la prochaine partie. La raison en est que toutes les colonnes restantes sont considérées comme celles qui ne contribuent pas à l'analyse des sentiments., donc, sans les jeter, nous considérons que le bloc de données exclut ces colonnes. Donc, esa es la razón para elegir solo las columnas ‘Texte’ Oui ‘Sentiment’. Nous codons comme ci-dessous:
Les données['sentiment']= un final_dataset = données[['Texte','sentiment']] ensemble_de_données_final
À présent, si imprimimos el ‘ensemble_de_données_final’ et nous trouvons le chemin, on apprend qu'il y a 568411 lignes et seulement 2 Colonnes. À partir de l'ensemble de données final, si nous découvrons que le nombre de commentaires positifs est 443766 entrées et le nombre de commentaires négatifs est 82007. Donc, il y a une grande différence entre les commentaires positifs et négatifs. Donc, il y a plus de chance que les données s'ajustent trop si nous essayons de construire le modèle directement. Donc, nous devons choisir seulement quelques entrées du final_datset pour éviter le surapprentissage. Ensuite, de divers essais, J'ai trouvé que la valeur optimale pour le nombre de révisions à considérer est 5000. Donc, creo dos nuevas variables ‘données’ Oui ‘Les données’ et stocker au hasard 5000 avis positifs et négatifs sur les variables respectivement. Le code qui implémente la même chose est ci-dessous:
datap = data_p.iloc[np.random.randint(1,443766,5000), :] datan = data_n.iloc[np.random.randint(1, 82007,5000), :] longueur(Les données), longueur(données)
Ahora creo una nueva variable llamada datos y concateno los valores en ‘données’ Oui ‘Les données’.
données = pd.concat([données,Les données]) longueur(Les données)
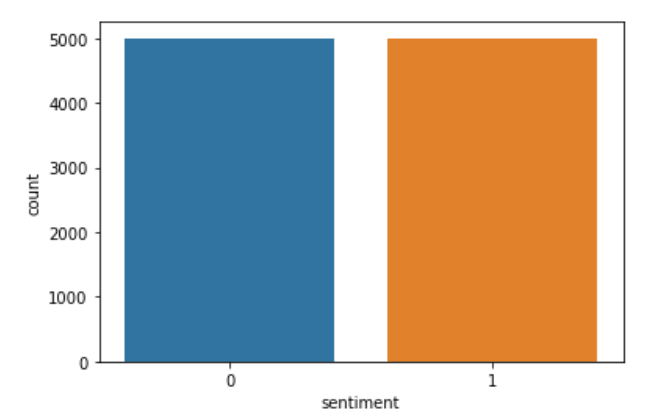
Ahora creo una nueva lista llamada ‘c’ et ce que je fais est similaire à l'encodage mais explicitement. je garde les avis négatifs « 0 » Quoi « 0 » et les avis positifs « 2 » avant comment « 1 » dans « c ». Alors, nuevamente reemplazo los valores del sentimiento almacenados en ‘c’ dans les données de colonne. Alors, pour voir si le code a été exécuté correctement, trazo la columna ‘sentiment’. Le code qui implémente la même chose est:
c=[]
pour i dans les données['sentiment']:
si je==0:
c.append(0)
si je==2:
c.append(1)
Les données['sentiment']=c
sns.countplot(Les données['sentiment'])
plt.show()
Si nous voyons les données, nous pouvons trouver qu'il y a des balises HTML, car les données provenaient à l'origine de sites de commerce électronique réels. Donc, nous pouvons constater qu'il y a des balises présentes qui doivent être supprimées, car ils ne sont pas nécessaires pour l'analyse des sentiments. Donc, usamos la función BeautifulSoup que usa el ‘html.parser’ et nous pouvons facilement supprimer les balises indésirables des avis. Pour effectuer la tâche, creo una nueva columna llamada ‘révision’ que almacena el texto analizado y dejo caer la columna llamada ‘sentiment’ pour éviter la redondance. He realizado la tarea anterior usando una función llamada ‘bande_html’. Le code pour faire la même chose est le suivant:
def bande_html(texte):
soupe = BelleSoupe(texte, "html.parser")
retour soupe.get_text()
Les données['revoir'] = données['Texte'].appliquer(bande_html)
données=données.drop('Texte',axe=1)
data.head()
Nous sommes maintenant arrivés à la fin d'un processus fastidieux de pré-traitement et de visualisation des données. Donc, maintenant nous pouvons passer à l'étape suivante, c'est-à-dire, construction de modèles.
4. Modèle de construction:
Avant de sauter directement pour construire le modèle dont nous avons besoin, faire un peu de devoirs. Nous savons que pour que les humains classent les sentiments, nous avons besoin d'articles, déterminants, conjonctions, signe de ponctuation, etc, comme nous pouvons clairement comprendre et ensuite noter l'avis. Mais ce n'est pas le cas des machines, donc ils n'en ont pas vraiment besoin pour classer le sentiment, mais ils sont littéralement confus s'ils sont présents. Ensuite, pour effectuer cette tâche comme n'importe quelle autre analyse des sentiments, necesitamos usar la biblioteca ‘nltk’. NLTK son las siglas de ‘Natural Language Processing Toolkit’. C'est l'une des meilleures bibliothèques pour effectuer une analyse des sentiments ou tout projet d'apprentissage automatique basé sur du texte.. Ensuite, avec l'aide de cette bibliothèque, Je vais d'abord supprimer les signes de ponctuation, puis supprimer les mots qui n'ajoutent pas de sentiment au texte. Primero utilizo una función llamada ‘punc_clean’ qui supprime les signes de ponctuation de chaque avis. Le code pour implémenter le même est le suivant:
importer nltk
def punc_clean(texte):
importer la chaîne en tant que st
a=[w pour w dans le texte si w pas dans st.ponctuation]
retour ''.rejoindre(une)
Les données['revoir'] = données['revoir'].appliquer(punc_clean)
data.head(2)
Donc, le code ci-dessus supprime les signes de ponctuation. À présent, ensuite, nous devons supprimer les mots qui n'ajoutent pas de sentiment à la phrase. Ces mots s'appellent « mots vides ». La liste de presque tous les mots vides peut être trouvée ici. Ensuite, si on vérifie la liste des mots vides, nous pouvons constater qu'il contient également le mot « non ». Donc, il faut que nous n'éliminions pas les « non » de « révision », car il ajoute de la valeur au sentiment car il contribue au sentiment négatif. Donc, nous devons écrire le code de telle manière que nous supprimions d'autres mots à l'exception du « non ». Le code pour implémenter la même chose est:
def remove_stopword(texte):
stopword=nltk.corpus.stopwords.words('Anglais')
mot d'arrêt.supprimer('ne pas')
a=[w pour w dans nltk.word_tokenize(texte) si w pas dans le mot vide]
retour ' '.rejoindre(une)
Les données['revoir'] = données['revoir'].appliquer(remove_stopword)
Donc, maintenant, nous n'avons qu'un pas en arrière dans la construction de modèles. La raison suivante est d'attribuer à chaque mot de chaque avis un score de sentiment. Ensuite, pour le mettre en œuvre, necesitamos usar otra biblioteca del módulo ‘apprendre’ quel est le ‘TfidVectorizer’ que está presente dentro de ‘feature_extraction.text’. Se recomienda encarecidamente pasar por el ‘TfidVectorizer’ documents pour bien comprendre la bibliothèque. Tiene muchos paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... en entrée, codage, min_df, max_df, ngram_range, binaire, dtype, use_idf et bien d'autres paramètres, chacun avec son propre cas d'utilisation. Donc, il est recommandé de passer par là Blog para obtener una comprensión clara del funcionamiento de ‘TfidVectorizer’. Le code qui implémente la même chose est:
de sklearn.feature_extraction.text importer TfidfVectorizer vectr = TfidfVectorizer(ngram_range=(1,2),min_df=1) vectr.fit(Les données['revoir']) vect_X = vectr.transformer(Les données['revoir'])
Il est maintenant temps de construire le modèle. Puisqu'il s'agit d'une analyse de sentiment de classification de classe binaire, c'est-à-dire, ‘1’ fait référence à un avis positif et ‘0’ fait référence à un avis négatif. Ensuite, il est clair que nous devons utiliser l'un des algorithmes de classification. Celle utilisée ici est la régression logistique. Donc, necesitamos importar ‘LogisticRegression’ l'utiliser comme modèle. Alors, nous devons adapter toutes les données en tant que telles car j'ai pensé qu'il était bon de tester les données à partir de toutes nouvelles données au lieu de l'ensemble de données disponible. J'ai donc ajusté l'ensemble des données. Luego uso la función ‘.But ()’ pour prédire le score du modèle. Le code qui implémente les tâches mentionnées ci-dessus est le suivant:
de sklearn.linear_model import LogisticRegression model = LogisticRegression() clf=modèle.fit(vect_X,Les données['sentiment']) clf.score(vect_X,Les données['sentiment'])*100
Si nous exécutons l'extrait de code ci-dessus et vérifions le score du modèle, nous obtenons entre 96 Oui 97%, puisque l'ensemble de données change à chaque fois que nous exécutons le code, puisque nous considérons les données au hasard. Donc, nous avons construit avec succès notre modèle qui également avec un bon score. Ensuite, Pourquoi attendre pour tester le fonctionnement de notre modèle dans le scénario du monde réel? Así que ahora pasamos al último y último paso de la ‘Prédiction’ pour tester les performances de notre modèle.
5. Prédiction:
Ensuite, clarifier les performances du modèle, J'ai utilisé deux phrases simples « J'aime la crème glacée » et « Je déteste la crème glacée » qui font clairement référence à des sentiments positifs et négatifs.. Le résultat est le suivant:

Ici le ‘1’ et le ‘0’ se référer respectivement au sentiment positif et négatif. Pourquoi certaines critiques du monde réel ne sont-elles pas testées? Je vous demande en tant que lecteurs de vérifier et de prouver la même chose. La plupart du temps, vous obtiendrez le résultat souhaité, mais si ça ne marche pas, le solicito que intente cambiar los parámetros del ‘TfidVectorizer’ y ajuste el modelo a ‘LogisticRegression’ pour obtenir la sortie requise. Ensuite, pour lequel j'ai joint le lien vers le code et le dataset ici.
Vous vous connectez avec moi à travers lié. J'espère que ce blog est utile pour comprendre comment l'analyse des sentiments est effectuée pratiquement à l'aide de codes Python. Merci d'avoir vu le blog.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





